流控神器Sentinel指南:深入分析流控原理(上)
文章目录
- 1. 加载规则
- 2. 访问资源
- 2.1 创建Conext
- 2.2 创建SlotChain
- 2.3 构造Entry
- 3. NodeSelectorSlot
- 4. ClusterBuilderSlot
- 5. 流控核心 FlowSlot
1. 加载规则
上一篇文章中 https://blog.csdn.net/TheLudlows/article/details/84992863 ,我们队Sentinel的抽象概念进行粗略的描述,这篇文章在此基础上对Sentinel的原理进行更深一步的认识。
在Sentinel中要对资源进行保护需要先配置规则,规则包括流量控制规则、熔断降级规则、系统保护规则 以及授权规则。每一种规则
都有对应的xxxRuleManager工具类来加载生效。以FlowRule为例,一般设置规则的代码如下:
private static void initFlowQpsRule() {
List<FlowRule> rules = new ArrayList<FlowRule>();
FlowRule rule1 = new FlowRule();
rule1.setResource(KEY);
// set limit qps to 20
rule1.setCount(20);
rule1.setGrade(RuleConstant.FLOW_GRADE_QPS);// 依据QPS限流
//rule1.setLimitApp("default");
rule1.setControlBehavior(CONTROL_BEHAVIOR_DEFAULT); // 流控模式,默认为直接拒绝
rules.add(rule1);
FlowRuleManager.loadRules(rules);
}
通过一个List来保存一些多个流控规则,可以是一个资源的多个流控规则,也可以是多个资源的多个流控规则。下面我们进入FlowRuleManage类,认识一下它的部分重要属性
private static final Map<String, List<FlowRule>> flowRules = new ConcurrentHashMap<String, List<FlowRule>>();
private final static ScheduledExecutorService scheduler = Executors.newScheduledThreadPool(1,
new NamedThreadFactory("sentinel-metrics-record-task", true));
private final static FlowPropertyListener listener = new FlowPropertyListener();
private static SentinelProperty<List<FlowRule>> currentProperty = new DynamicSentinelProperty<List<FlowRule>>();
static {
currentProperty.addListener(listener);
scheduler.scheduleAtFixedRate(new MetricTimerListener(), 0, 1, TimeUnit.SECONDS);
}
Map是用来保存所有的流控规则,key为资源名称,value为一个list对象。因为是
全局共享的,使用的是ConcurrentHashMap。一个资源可以有多个流控规则,它们是通过链表保存,比如一个规则通过QPS控制,一个是通过线程数控制。- ScheduledExecutorService scheduler
FlowPropertyListener listener是一个监听器,当规则变化,进行相应的操作SentinelProperty此类包含配置的当前值,并负责在更新配置时通知所有属性监听器。
静态代码块中添加属性监听器,启动计划线程
我们继续看loadRules的实现:
public static void loadRules(List<FlowRule> rules) {
currentProperty.updateValue(rules);
}
调用属性类的更新操作,将新的规则赋值给currentProperty的成员变量。
@Override
public void updateValue(T newValue) {
if (isEqual(value, newValue)) {
return;
}
value = newValue;
for (PropertyListener<T> listener : listeners) {
listener.configUpdate(newValue);
}
}
然后通知监听器,即调用所有监听器的configUpdate方法:
@Override
public void configUpdate(List<FlowRule> value) {
Map<String, List<FlowRule>> rules = FlowRuleUtil.buildFlowRuleMap(value);
if (rules != null) {
flowRules.clear();
flowRules.putAll(rules);
}
RecordLog.info("[FlowRuleManager] Flow rules received: " + flowRules);
}
监听器的作用是把新的规则放入flowRules中。buildFlowRuleMap方法实现较长,但是逻辑不复杂,此处就不展开。该方法的作用是将旧规则和新规则合并,并且根据设置生成具体的Controller对相关,1.5版本之后更改为TrafficShapingController,大体的逻辑基本一样。
2. 访问资源
规则生效了之后,就可以保护资源了,一般访问资源的代码如下:
try{
Entry entry = SphU.entry(name);
// biz code
} catch (BlockException e1) {
} catch (Exception e2) {
// biz exception
} finally {
if (entry != null) {
entry.exit();
}
}
如果能够申请成功,则说明没有被限流,否则会抛出BlockException,表面已经被限流了。SphU和SphO是暴露给用户的API,它的内部没有真正意义上的逻辑,相当于Env的代理对象,Env即Environment的缩写,正如其含义,它是全局环境的抽象,进行一些初始化的操作:
public class Env {
// 初始化Node构造器,用于构建Node tree。Node tree是用来对调用链进行限流
public static final NodeBuilder nodeBuilder = new DefaultNodeBuilder();
// 真正的访问资源入口
public static final Sph sph = new CtSph();
static {
InitExecutor.doInit(); // 对实时数据传输的底层通信,规则数据持久化等进行初始化。
}
}
doInit不是本文的重点,将会放在Sentinel传输实时数据的文章中介绍。我们继续看访问资源的主线。刚才讲到Sph才是资源的入口,它的实现类CtSph内部才是访问资源的具体逻辑。SphU中entry方法内部实现如下:
public static Entry entry(String name) throws BlockException {
return Env.sph.entry(name, EntryType.OUT, 1, OBJECTS0);
}
跟进CtSph的entry实现方法:
@Override
public Entry entry(String name, EntryType type, int count, Object... args) throws BlockException {
StringResourceWrapper resource = new StringResourceWrapper(name, type);
return entry(resource, count, args);
}
这里创建了资源的包装类,传递给entry的重载方法,这里其实有一个困惑了很久的疑问,访问的次数肯定远大于资源的数量,资源就那么固定的几个。没有必要每一个访问请求都创建一个新的ResourceWrapper对象,为什么不用不放入缓存中呢?这仅仅是个人理解不了的地方。
回到主线跟进:
public Entry entryWithPriority(ResourceWrapper resourceWrapper, int count, Object... args) throws BlockException {
Context context = ContextUtil.getContext();
if (context instanceof NullContext) {
return new CtEntry(resourceWrapper, null, context);
}
if (context == null) {
// Using default context.
context = MyContextUtil.myEnter(Constants.CONTEXT_DEFAULT_NAME, "", resourceWrapper.getType());
}
// Global switch is close, no rule checking will do.
if (!Constants.ON) {
return new CtEntry(resourceWrapper, null, context);
}
ProcessorSlot<Object> chain = lookProcessChain(resourceWrapper);
/*
* Means amount of resources (slot chain) exceeds {@link Constants.MAX_SLOT_CHAIN_SIZE},
* so no rule checking will be done.
*/
if (chain == null) {
return new CtEntry(resourceWrapper, null, context);
}
Entry e = new CtEntry(resourceWrapper, chain, context);
try {
chain.entry(context, resourceWrapper, null, count, args);
} catch (BlockException e1) {
e.exit(count, args);
throw e1;
} catch (Throwable e1) {
// This should not happen, unless there are errors existing in Sentinel internal.
RecordLog.info("Sentinel unexpected exception", e1);
}
return e;
}
内部逻辑可以划分为一下几步:
- 获取当前访问资源的上下文
- 全局保护是否开启
- 根据包装过的资源对象获取对应的SlotChain
- SlotChain的entry方法,真正让执行规则的地方,如果SlotChain的entry方法抛出了BlockException,则将该异常继续向上抛出,如果SlotChain的entry方法正常执行了,则最后会将该entry对象返回。
2.1 创建Conext
上一篇文章中提到了Context,它是一次访问资源的过程。保存于ThreadLocal中,ContextUtil.getContext()就是从ThreadLocal中取出Context。那么NullContext是个什么?暂时我们先不用管它,到目前为止整个流程没有创建Context,取出来的肯定是null。ContextUtil有个非常重要的初始化代码块
static {
// Cache the entrance node for default context.
initDefaultContext();
}
private static void initDefaultContext() {
String defaultContextName = Constants.CONTEXT_DEFAULT_NAME;
// 构建第一个EntranceNode
EntranceNode node = new EntranceNode(new StringResourceWrapper(defaultContextName, EntryType.IN), null);
// 添加至ROOT下
Constants.ROOT.addChild(node);
// 放置缓存,这个是全局共享的缓存,key为ContextName,value为EntranceNode
contextNameNodeMap.put(defaultContextName, node);
}
这里添加了默认的EntranceNode,并且一个defaultContextName为key。继续回到主线
进入MyContextUtil.myEnter方法去创建Context:
/**
* This class is used for skip context name checking.
*/
private final static class MyContextUtil extends ContextUtil {
static Context myEnter(String name, String origin, EntryType type) {
return trueEnter(name, origin);
}
}
入参为Constants.CONTEXT_DEFAULT_NAME, "", resourceWrapper.getType(),第一个参数为Conext名称,此处使用常量。第二个是来源为空,第三个是访问资源的类型。
跟进trueEnter:
protected static Context trueEnter(String name, String origin) {
// contextHolder为保存Conext的ThreadLocal对象
Context context = contextHolder.get();
if (context == null) {
Map<String, DefaultNode> localCacheNameMap = contextNameNodeMap;
// 从myEnter方法进来的,获取的node一定不为空,上面的初始化操作已经添加进去默认的entrancenode
// 那什么情况下可能为空呢? 外部显示是调用Context.enter方法,输入的key不允许为CONTEXT_DEFAULT_NAME的值,其他值得话第一次调用肯定为null
DefaultNode node = localCacheNameMap.get(name);
if (node == null) {
if (localCacheNameMap.size() > Constants.MAX_CONTEXT_NAME_SIZE) {
setNullContext();
return NULL_CONTEXT;
} else {
try {
LOCK.lock();
node = contextNameNodeMap.get(name);
if (node == null) {
if (contextNameNodeMap.size() > Constants.MAX_CONTEXT_NAME_SIZE) {
setNullContext();
return NULL_CONTEXT;
} else {
node = new EntranceNode(new StringResourceWrapper(name, EntryType.IN), null);
// Add entrance node.
Constants.ROOT.addChild(node);
Map<String, DefaultNode> newMap = new HashMap<String, DefaultNode>(
contextNameNodeMap.size() + 1);
newMap.putAll(contextNameNodeMap);
newMap.put(name, node);
contextNameNodeMap = newMap;
}
}
} finally {
LOCK.unlock();
}
}
}
// 将获取到的entrancenode用来构造一个Conext
context = new Context(node, name);
context.setOrigin(origin);
contextHolder.set(context);
}
return context;
}
别看代码这么长,其实就是创建一个Context,并且关联一个entrancenode,然后放入threadlocal中。至此Context创建完毕。下图表示目前Context和EntranceNode、Root的关系
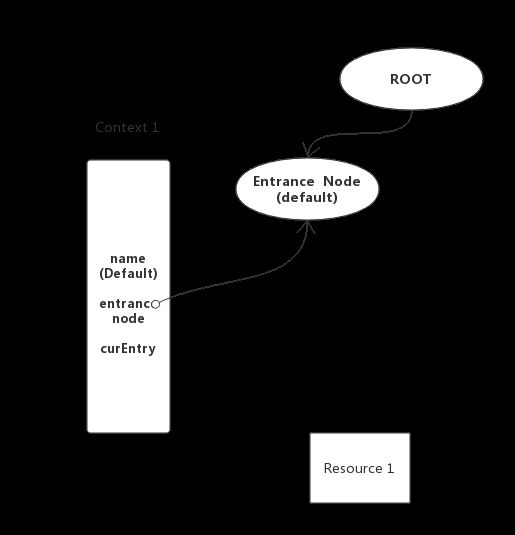
2.2 创建SlotChain
Sentinel中有各种规则,每类规则对应一个slot,多个slot连接起来成为ProcessorSlotChain,
lookProcessChain方法如下:
ProcessorSlot<Object> lookProcessChain(ResourceWrapper resourceWrapper) {
// ProcessorSlot缓存,key为resource
ProcessorSlotChain chain = chainMap.get(resourceWrapper);
if (chain == null) {
synchronized (LOCK) {
chain = chainMap.get(resourceWrapper);
if (chain == null) {
// Entry size limit.
if (chainMap.size() >= Constants.MAX_SLOT_CHAIN_SIZE) {
return null;
}
// 构建一个新的SlotChain
chain = SlotChainProvider.newSlotChain();
Map<ResourceWrapper, ProcessorSlotChain> newMap = new HashMap<ResourceWrapper, ProcessorSlotChain>(
chainMap.size() + 1);
newMap.putAll(chainMap);
newMap.put(resourceWrapper, chain);
chainMap = newMap;
}
}
}
return chain;
}
每个资源都对应一个slotchain,newSlotChain方法就是性构建一个DefaultProcessorSlotChain。下面我们看下slot类关系。
SlotChan和Netty中的Pipeline有些类似,而Slot像是Handler。DefaultProcessorSlotChain是如何添加Solt?它有一个默认的first和end 节点,在上篇中提到过,最终过调用此方法添加slot。
public ProcessorSlotChain build() {
ProcessorSlotChain chain = new DefaultProcessorSlotChain();
chain.addLast(new NodeSelectorSlot());
chain.addLast(new ClusterBuilderSlot());
chain.addLast(new LogSlot());
chain.addLast(new StatisticSlot());
chain.addLast(new SystemSlot());
chain.addLast(new AuthoritySlot());
chain.addLast(new FlowSlot());
chain.addLast(new DegradeSlot());
return chain;
}
2.3 构造Entry
回到主线,当slotchain创建完毕,下面Entry e = new CtEntry(resourceWrapper, chain, context);开始构造Entry.
CtEntry(ResourceWrapper resourceWrapper, ProcessorSlot<Object> chain, Context context) {
super(resourceWrapper);
this.chain = chain;
this.context = context;
setUpEntryFor(context);
}
// 父类Entry
public Entry(ResourceWrapper resourceWrapper) {
this.resourceWrapper = resourceWrapper;
// 创建时间,用于计算RT
this.createTime = TimeUtil.currentTimeMillis();
}
构造方法中主要是对resourceWrapper,chain,context进行赋值,setUpEntryFor是用来构造Entry调用链。
private void setUpEntryFor(Context context) {
// The entry should not be associated to NullContext.
if (context instanceof NullContext) {
return;
}
this.parent = context.getCurEntry();
if (parent != null) {
((CtEntry)parent).child = this;
}
context.setCurEntry(this); //
}
回顾Context的构造过程,curEntry属性在第一次构造并没有给它赋值,因此为null。然后属性curEntry为当前Entry对象。
中各个对象关系如下:
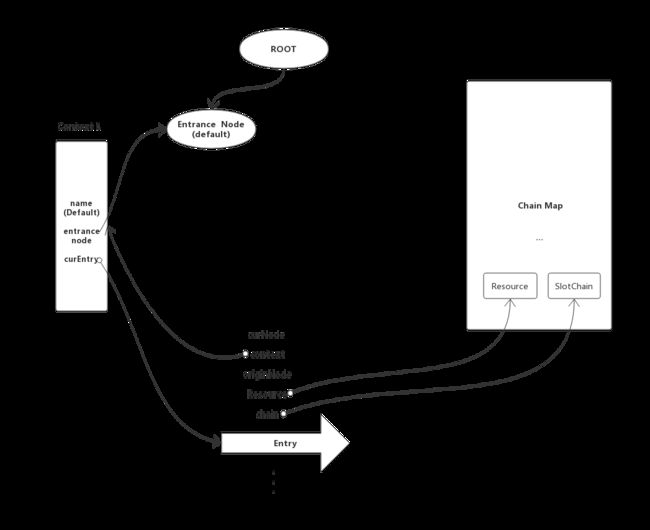
3. NodeSelectorSlot
敲黑板!重点来了,当Entry构造完毕,开始了entry调用链,即通过SlotChain检测这个Entry是否能访问此资源。first节点后是NodeSelectorSlot, 它负责收集资源的路径,并将这些资源的调用路径,以树状结构存储起来,说白了就是构建resource的DefaultNode节点,DefaultNode是用来保存某个资源实时流量数据的,一个资源可以有多个DefaultNode,比如下面代码:
Entry entry1 = SphU.entry(KEY);
//....
entry1.exit();
ContextUtil.enter("entrance1", "appA"); //创建Entrance Node
Entry entry2 = SphU.entry(KEY);
//....
entry2.exit();
代码中两次请求同一个资源,使用了上下文不同,EntranceNode 也不同,同样DefaultNode也是不同。
NodeSelectorSlot的entry方法实现如下:
public class NodeSelectorSlot extends AbstractLinkedProcessorSlot<Object> {
// 以Context name 作为key保存DefaultNode
private volatile Map<String, DefaultNode> map = new HashMap<String, DefaultNode>(10);
public void entry(Context context, ResourceWrapper resourceWrapper, Object obj, int count, Object... args)
throws Throwable {
// 第一次获取为空
DefaultNode node = map.get(context.getName());
if (node == null) {
synchronized (this) {
node = map.get(context.getName());
if (node == null) {
// 新创建一个DefaultNode
node = Env.nodeBuilder.buildTreeNode(resourceWrapper, null);
HashMap<String, DefaultNode> cacheMap = new HashMap<String, DefaultNode>(map.size());
cacheMap.putAll(map);
cacheMap.put(context.getName(), node);
map = cacheMap;
}
// Build invocation tree
((DefaultNode)context.getLastNode()).addChild(node);
}
}
// 设置Entry当前节点
context.setCurNode(node);
// 触发下一个slot
fireEntry(context, resourceWrapper, node, count, args);
}
}
// Context#setCurNode
public Context setCurNode(Node node) {
this.curEntry.setCurNode(node);
return this;
}
NodeSelectorSlot 的entry方法主要流程为
- 获取当前上下文对应的DefaultNode,如果没有的话会为当前的调用新生成一个DefaultNode节点,它的作用是对资源进行各种统计度量以便进行流控;
- 将新创建的DefaultNode节点,添加到context中,作为curNode(entrance node / default node)的子节点;
- 将DefaultNode节点,添加到Entry中,作为curNode
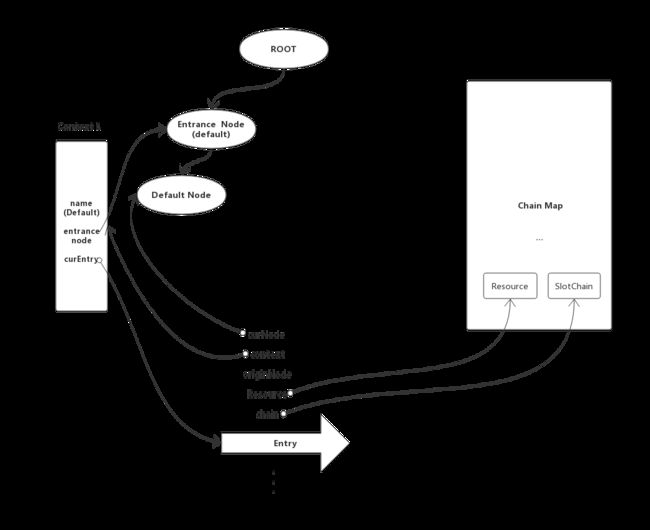
注意一点,这里使用的是ContextName作为key来保存DefaultNode,开始笔者非常感到很困惑,回想一下ContextName决定EntranceNode,每个资源独享SlotChain,因此该NodeSelectorSlot也是属于某个资源,这里通过ResourceName保存,只是为了决定生成的DefaultNode挂在那个EntranceNode下。
不同的资源独享Slotchain,但是调用树是共享的。不同资源对应的DefaultNode也是独享的。这里确实有点绕。
4. ClusterBuilderSlot
NodeSelectorSlot的entry方法执行完之后,会调用fireEntry方法,此时会触发ClusterBuilderSlot的entry方法。
先看NodeSelectorSlot中的两个重要变量:
// 该静态变量 用来缓存所有的ClusterNode
private static volatile Map<ResourceWrapper, ClusterNode> clusterNodeMap
= new HashMap<ResourceWrapper, ClusterNode>();
// 每一个资源对应一个ClusterNode
private ClusterNode clusterNode = null;
注意clusterNode 为成员变量,那么如何为每一个资源都生成一个ClusterNode 呢? 答案是每一个资源都专享一个SlotChain,自然ClusterBuilderSlot也是资源专享的,因此它的成员变量也是资源专享的。
继续看它的entry实现:
@Override
public void entry(Context context, ResourceWrapper resourceWrapper, DefaultNode node, int count, Object... args)
throws Throwable {
if (clusterNode == null) {
synchronized (lock) {
if (clusterNode == null) {
// Create the cluster node.
clusterNode = Env.nodeBuilder.buildClusterNode();
HashMap<ResourceWrapper, ClusterNode> newMap = new HashMap<ResourceWrapper, ClusterNode>(16);
newMap.putAll(clusterNodeMap);
newMap.put(node.getId(), clusterNode);
clusterNodeMap = newMap;
}
}
}
//上面构建一个ClusterNode,添加至map中
// 将ClusterNode和DefaultNode关联
node.setClusterNode(clusterNode);
// 构建OriginNode
if (!"".equals(context.getOrigin())) {
Node originNode = node.getClusterNode().getOriginNode(context.getOrigin());
context.getCurEntry().setOriginNode(originNode);
}
fireEntry(context, resourceWrapper, node, count, args);
}
DefaultNode 的目的很明确,它是用来保存实时资源请求数据的,但是一个资源可能存在多个DefaultNode,那么如何统计该资源的全部实时数据呢?通过ClusterNode关联了一个资源的所有DefaultNode。一个资源只有一个ClusterNode,clusterNodeMap保存了所有资源的ClusterNode,因此很快的就能定位到ClusterNode。
前面分析到创建Context时origin属性是"",即空字符串。因此这里不会进入分支。那么什么情况下回进入呢?
当在入口有ContextUtil.enter(contextName, originName)这行代码,在此处会为当前Entry 对象设置来源节点。并且ClusterNode内部有一个originCountMap用来保存资源的所有来源。key为originName,value为StatisticNode。
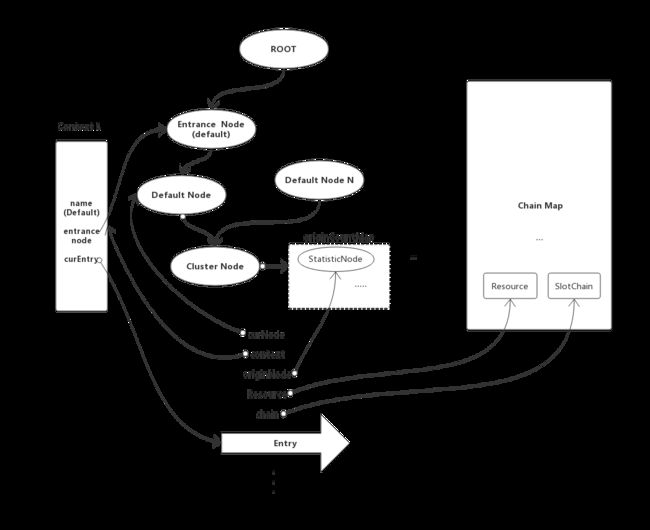
5. 流控核心 FlowSlot
ClusterBuilderSlot之后是StatisticSlot,但是StatisticSlot是统计资源实时数据的,它内部直接调用下一个slot,然后根据返回值进行数据统计。
我们直接看流控相关的FlowSlot的entry方法。
@Override
public void entry(Context context, ResourceWrapper resourceWrapper, DefaultNode node, int count, Object... args)
throws Throwable {
FlowRuleManager.checkFlow(resourceWrapper, context, node, count);
fireEntry(context, resourceWrapper, node, count, args);
}
回忆第一节的内容,FlowRuleManager类中flowRules中保存了所有资源的规则。一个resource作为key。跟进checkFlow
public static void checkFlow(ResourceWrapper resource, Context context, DefaultNode node, int count)
throws BlockException {
List<FlowRule> rules = flowRules.get(resource.getName());
if (rules != null) {
for (FlowRule rule : rules) {
if (!rule.passCheck(context, node, count)) {
throw new FlowException(rule.getLimitApp());
}
}
}
}
这里遍历所有的规则,如果不能通过跑出FlowException,继续跟进passCheck
public boolean passCheck(Context context, DefaultNode node, int acquireCount, Object... args) {
// limitApp 默认是一个 “default”
String limitApp = this.getLimitApp();
if (limitApp == null) {
return true;
}
// origin默认为空字符串
String origin = context.getOrigin();
//根据调用方和上下文以及FlowRule所配置的Strategy来获取应该用于限流的统计Node,默认获取的是前面构造的ClusterNode
Node selectedNode = selectNodeByRequesterAndStrategy(origin, context, node);
// 如果没有合乎规则的Node,则直接返回true,表示通过
if (selectedNode == null) {
return true;
}
// 如果存在统计Node,则通过controller来判断是否需要限流
// 这个controller通过设置FlowRule的controllerBehavior来区分
// 默认的实现有:0. default, 1. warm up, 2. rate limiter
return controller.canPass(selectedNode, acquireCount);
}
正的限流逻辑藏在了FlowRule的controller里面,而这个controller有三种实现.
见下文-> https://blog.csdn.net/TheLudlows/article/details/85055032