体验百度云智能自然语言处理
当前,像百度、腾讯、阿里巴巴等厂商在云服务的基础上,提供了包括图像处理、音频处理、自然语言处理等一系列功能甚至各种相关解决方案,这也是大厂的标志之一,所以即使百度市值可能已经低于一些后期之秀,但仍是中国互联网的重要一极,因为提供这些技术是衡量一家公司技术积累的重要标志。
作者主要做自然语言处理相关的工作,因此主要关注了BAT三家厂商关于nlp的一些服务,其中百度的相关服务更全面一些,除分词、词性标注、命名实体识别等基础功能外,还包括语言处理应用技术服务,主要包含:观点抽取、情感倾向分析、新闻摘要接口等;另外还提供了理解与交互技术UNIT,主要用于提供智能对话功能。而腾讯和阿里的功能则没有百度这么全面。具体的对比,大家可以参考相关介绍:
- 阿里云:https://ai.aliyun.com/nlp?spm=5176.8142029.388261.324.4c7d6d3e7u1CCr
- 腾讯云:https://cloud.tencent.com/product/nlp#wiki
- 百度云:http://ai.baidu.com/docs#/UNIT-v2-guide/top
其中百度公司的服务最为良心,均可以免费调用,只要QPS不超过5即可,使用方式也很简单,注册百度账号后,根据操作说明创建应用即可。创建应用示例,只需要填写相关说明即可:
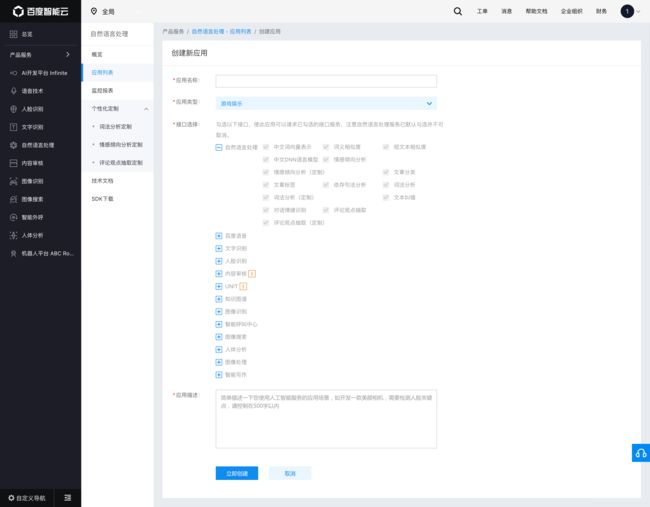
应用创建成功后,可以在管理界面查看应用,看到如下信息,记下其中的API Key以及Secret key,在后面申请access_token时将会用到:

所有可以免费调用的API如图所示: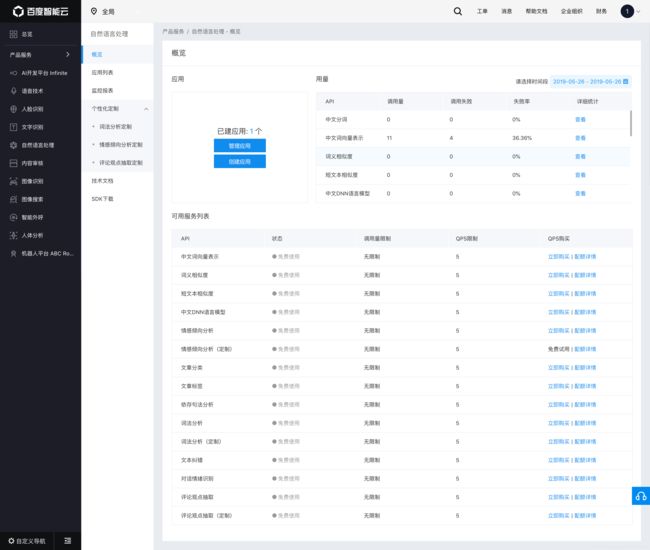
接下来我们以分词、句法分析、词向量为例测试调用百度云服务,主要利用python以http的方式进行调用,百度提供了两种调用方式,我们采用基于access_token的方式进行调用。所以首先需要获取一个access_token,注意在获取access_token之前,需要申请百度云账号并且在上面创建一个基础nlp应用。
获取access_token
import requests
# client_id 为创建应用后获取的AppKey, client_secret 为创建应用后获取的Secret key
host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=YOUR_CLIENT_ID&client_secret=YOUR_CLIENT_SECRET'
response = requests.get(host)
content = response.content
print(content)
返回结果:

记下access_token的值,再请求服务时我们将会用到,作为验证token。
PYTHON调用示例
# -*- coding:utf-8 -*-
import time
import json
import requests
class BaiduExamples(object):
def __init__(self):
self.charset = "UTF-8"
self.access_token = YOUR_ACCESS_TOKEN
self.word_analysis_url = "https://aip.baidubce.com/rpc/2.0/nlp/v1/lexer"
self.dependency_parser_url = "https://aip.baidubce.com/rpc/2.0/nlp/v1/depparser"
self.embedding_url = "https://aip.baidubce.com/rpc/2.0/nlp/v2/word_emb_vec"
def build_url(self, base_url):
return base_url + "?charset=" + self.charset + "&access_token=" + self.access_token
def word_analysis(self, text):
self.word_analysis_url = self.build_url(self.word_analysis_url)
datas = json.dumps({
"text": text
})
res = requests.post(self.word_analysis_url, data=datas)
print(json.loads(res.content.decode()))
def dependency_parse(self, text, mode):
self.dependency_parser_url = self.build_url(self.dependency_parser_url)
datas = json.dumps({
"text": text,
"mode": mode
})
res = requests.post(self.dependency_parser_url, data=datas)
print(json.loads(res.content.decode()))
def embedding(self, text, dem):
self.embedding_url = self.build_url(self.embedding_url)
datas = json.dumps({
"word": text,
"dem": dem
})
res = requests.post(self.embedding_url, data=datas)
print(json.loads(res.content.decode()))
if __name__ == "__main__":
be = BaiduExamples()
be.word_analysis(text="百度是一家高科技公司")
# be.dependency_parse(text="谁是姚明的妻子", mode=0)
# be.embedding("百度", 0)
示例结果
上述API返回的结果为JSON格式,并且包含了较多的信息,为了方便的查看结果,我这里利用postman调用展示结果:
词法分析
从结果来看,词法分析功能返回了分词结果、词性分析结果及命名实体识别结果。

句法分析
结果中,items为切词后每个token的分析结果,其中postag为词性分析结果,head为当前词的父节点,deprel为词语父节点的句法分析结果,以“姚明”为例,其父节点为id:2,即“的”字,“姚明”与“的”的关系为“DE”即“的字结构”。

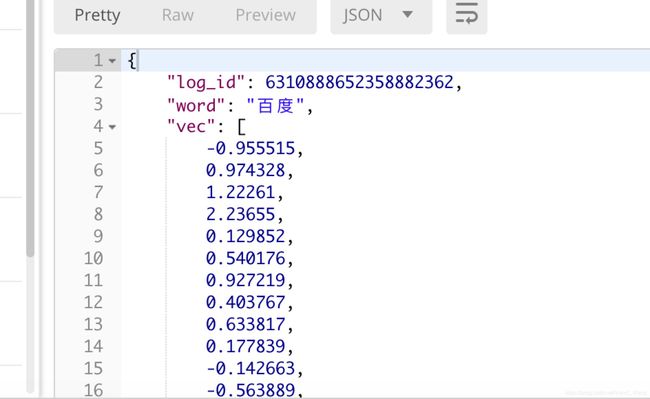
词向量结果
当前百度仅提供1024维的词embedding功能,结果示例如下:
结论
本文探索了百度云提供的几个基本自然语言处理功能,仅仅提供了几个演示示例,更细节的调用方式及功能使用可以详细参考百度云技术文档