通用爬虫编写思路
通用爬虫编写思路

Web爬虫需要解决的问题:
一、是否为公开网站/站点?(=是否需要登录?)
- 不需要登录是如何标记各个用户的:1、session 2、cookies 3、IP地址。
- 登录的目的是什么?(=是否一定需要登录?=是否每次都需要登录?)
- 每次都要登录、如何登录(=验证码)
二、页面是如何加载的?(=动态加载问题)
- 所需的数据在什么地方可以找到:1、html内 2、json内。
- 如果是动态记载Ajax怎么办?
三、可以直接请求的页面怎么请求?(=请求头怎么构造?=请求头的内容是否必要?)
优雅的爬虫是怎样的?
- 精准:请求到的每个字节都是我们想要的数据,不会请求到多余的垃圾。
- 速度:拥有最优数据解析策略、查重策略、存储策略等。
- 稳定:完善的异常处理机制,程序崩溃后断点重启。
- 素质:绝不影响目标站点正常运行。
一整套爬虫思路流程
- 首先,爬虫适合使用‘自底向上’思维:
假设一个网站是由 主页-->登录页面-->搜索页面-->信息页面 组成,而我们的数据是在 信息页面 中

- 关于提取数据,也就是上图中的第一层,策略如下:
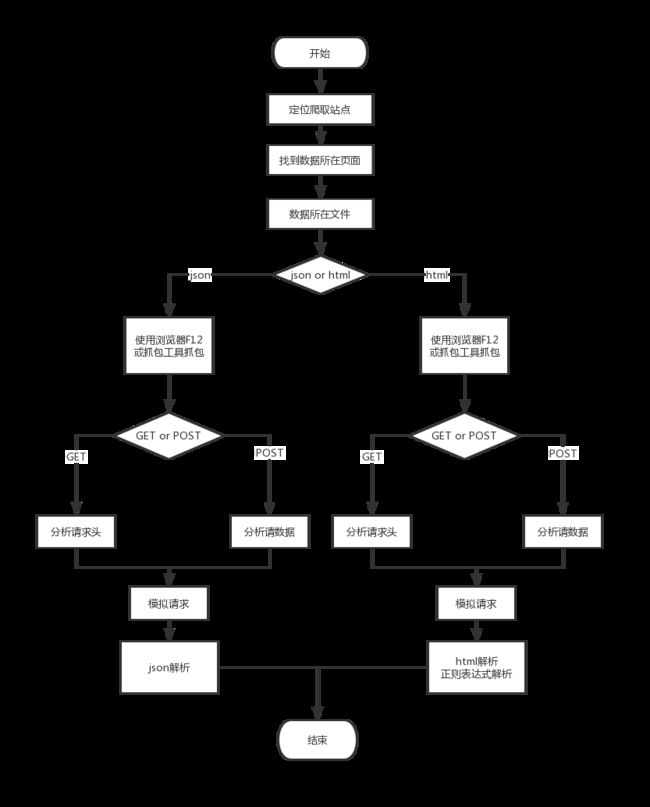
- 登录分析:
登录的目的分为两种
- 第一种是为了确保数据安全性,也就是网页中的数据访问权限并不是均等的,不同的用户有不同的权限,每个用户上传的数据可以选择共享,或者私密,类似于QQ空间。
- 第二种是为了取保用户安全性,这种网页一般属于‘Web个人主页’,每个用户都享用网站的功能,但各自的数据是不会外泄,类似于支付宝。
虽然说各个网站的登录操作各有不同,各大网站为了防止爬虫可谓是无所不用其极,但是在Web系统中,能维持登录状态只有两种:Cookies和Session(这里如果你有过web开发经验就很好理解),那么我们只要模拟出服务器想要识别出的Cookie和对应的值就可以给服务器一种已经登录的‘错觉’。但是总是需要登录一次才能获得登录过后产生的Cookies。所以接下来的问题就是如何登录。
- 登录策略:
让各位望而却步的无非不就是登录时的验证码。其实网上有很多公开的策略,例如识别图片验证码、自动滑动验证码。最难的不过是手机验证码。
但是我要说的并不是这些方法。
现如今在国内网络环境下,BAT就像是一个大的生态圈,他们手中攥着大量的用户,所有很多网站为了降低网站门槛,常与他们合作,就像我们常常可以看到使用QQ登录,或者微信登录、淘宝登录,诸如此类。所以我们完全可以通过直接访问这些接口登录,并且网上针对这些网站的自动登录策略可谓非常成熟。
- 构造请求:
'Host': 'search.originoo.cn',
'User-Agent':' Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:65.0) Gecko/20100101 Firefox/65.0',
'Accept':' application/json, text/javascript, */*; q=0.01',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Accept-Encoding': 'gzip, deflate',
'Referer':' http://www.originoo.com/ws/p.topiclist.php?cGljX2tleXdvcmRzPeW3peS6uiZtZWRpdW1fdHlwZT1waWMtdmVjdG9y',
'Content-Type':' application/x-www-form-urlencoded; charset=UTF-8',
'Content-Length':' 213',
'Origin': 'http://www.originoo.com',
'Connection': 'keep-alive',
'Cache-Control':' max-age=0',
'pic_keywords':'%E5%B7%A5%E4%BA%BA',
'medium_type':'pic-vector',
'pic_quality':'all',
'sort_type':'4',
'pic_orientation':'',
'pic_quantity':'',
'pic_gender':'',
'pic_age':'',
'pic_race':'',
'pic_color':'',
'pic_url':'',
'user_id':'0',
'company_id':'0',
'page_index':str(i),
'page_size':'40'这是一个典型的POST的请求头,POST的请求特点就是后面带上参数以表明本次请求的数据是什么。
并不是所有的请求都很长,请求的内容是根据服务器决定的,服务器设计的复杂,那么请求就很相应变得很复杂,反之亦然:
data = { "keyword":"工人",
"color":"0",
"type":"6"
}以上就是某网站的POST请求data部分。
其实复杂一点也就是请求中有大量服务器生成的校验参数,例如:
headers = {
'Host': 'dpapi.dispatch.paixin.com',
'User-Agent':'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:65.0) Gecko/20100101 Firefox/65.0',
'Accept':'application/json, text/plain, */*',
'Accept-Language':'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Accept-Encoding': 'gzip, deflate, br',
'Referer': 'https://v.paixin.com/media/photo/standard/%E5%B7%A5%E4%BA%BA/1',
'Content-Type': 'application/json;charset=utf-8',
'Content-Length': '43',
'Origin': 'https://v.paixin.com',
'Connection': 'keep-alive',
'Cookie': 'Hm_lvt_8a9ebc00eda51ba9f665488c37a93f41=1552048374; Hm_lpvt_8a9ebc00eda51ba9f665488c37a93f41=1552048386; Qs_lvt_169722=1552048378; Qs_pv_169722=4547593134179576000%2C332112608763589300; Hm_lvt_f72440517129ff03cc6f22668c61aef3=1552048378; Hm_lpvt_f72440517129ff03cc6f22668c61aef3=1552048386; _ga=GA1.2.1067225704.1552048380; _gid=GA1.2.1727359604.1552048380; _gat=1',
'Cache-Control':'max-age=0',
}这个请求头中的Cookie值显然不是人看的,其实我们在抓包时看到一些莫名奇妙的参数不要觉得恐惧,因为这是别的程序员写的,他们有他们自己的命名方法和策略,我们只要确认这个值是否必须就可以了。方法很简单,每次请求就删除一部分参数,看看是否可以正常请求,如果可以,那么就继续删,再请求,直到无法访问未知,如果无法访问,就说明你刚才删掉的参数是非常重要的,这个时候再去寻找这个参数的来源。