Linux网络——应用层
认识到网络后,从每个层来介绍网络,主要说的是每个层著名的协议。首先是离我们最近的应用层。
目录
认识应用层
概念
协议
DNS协议
介绍
域名的分层
DNS解析过程
HTTP协议
URL
HTTP
认识应用层
-
概念
负责应⽤程序间沟通,如超文本传输(HTTP)、简单电⼦邮件传输(SMTP)、⽂件传输协议(FTP)、网络远程访问协议(Telnet)等.,它是在我们整个网络结构体系的最上层,所以传输上来的数据已经是我们需要的数据了,而传送下去的数据,一定是我们最初始的数据。而网络编程也就是主要针对应⽤层,因为我们写的程序本质上就是进程。
-
协议
DNS、HTTP、FTP等,下面主要介绍DNS和HTTP协议。
DNS协议
-
介绍
域名系统(DomainNameSystem)是互联网的一项服务。我们知道IP地址,是一个四字节的点分十进制的数。每个点之间是一个字节,(192.168.138.135)所以最大能表示的数就是255。但是ip地址在我们人的角度来说,不好记。所以就有了域名。例如www.baidu.com。一看,就知道是百度。所以它就是它将域名和IP地址相互映射,能够使人更方便地访问互联网。
当前,对于每一级域名长度的限制是63个字符,包括www.和.com或者其他的扩展名,域名总长度则不能超过253个字符。
DNS最早于1983由保罗.莫卡派乔斯(Paul Mockapetris)发明;原始的技术规范在882号因特网标准草案(RFC 882)中发布。1987年发布的第1034和1035号草案修正了DNS技术规范,并废除了之前的第882和883号草案。在此之后对因特网标准草案的修改基本上没有涉及到DNS技术规范部分的改动。
早期的域名必须以英文句号“.”结尾,,这样DNS才能够进行域名解析。如今DNS服务器已经可以自动补上结尾的句号。
-
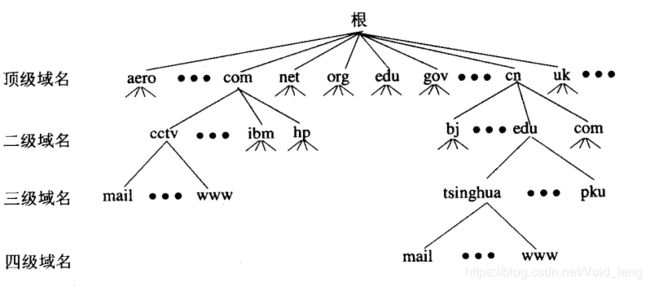
域名的分层
在认识网络阶段说过分层的好处,所以域名和域名服务器也有分层。
域名的分层:

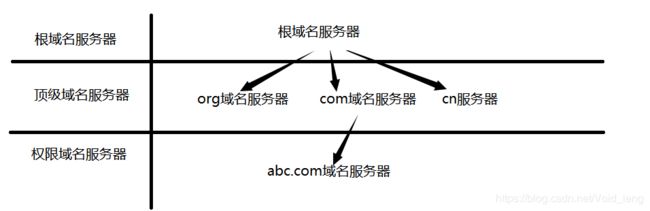
服务器的分层:
-
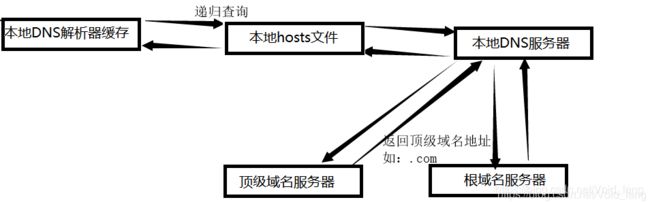
DNS解析过程
首先本地的hosts文件里面找映射关系,没有就去本地DNS解析器缓存找,再没有就去本地DNS服务器,周边肯定是有运营商的服务器的。这里没有就要去根域名服务器了,在根域名服务器还没有,它就会把顶级域名服务器告诉你,然后就会去顶级域名服务器找。
这是本地hosts文件。
HTTP协议
-
URL
在说HTTP协议之前,先说一下URL,什么是URL?其实平常我们所说的网址就是URL。那么URL这么长,里面代表着什么呢?下面来解析一条URL。

其实一条URL不止这么简单,
协议名称://用户名:密码@服务器地址:服务器端口/请求资源路径?查询字符串#片段标识。
查询字符串,即query_string由键值对组成,键值对之间用&分割,键和值之间用=分割。(键值对就像钥匙和锁,一个键对应一个值)。
像+这种字符在query_string当做特殊意义理解了。因此这些字符不能随意出现. ⽐如, 某个参数中需要带有这些特殊字符, 就必须先对特殊字符进⾏转义。
转义的规则如下:
将需要转码的字符转为16进制,然后从右到左,取4位(不⾜4位直接处理),每2位做⼀位,前⾯加上%,编码 成%XY格式

结合上面的DNS,就有这样一个面试问题:浏览器输入URL后发生了哪些事情?
先进行域名解析--->组织HTTP请求---->发送HTTP请求---->服务恢复301响应--->浏览器跟踪重定向地址---->服务器处理请求---->服务器发回一个HTML响应---->浏览器开始显示HTML
-
HTTP
现在主要来说一下HTTP协议。
HTTP叫做超文本传输协议(,HyperText Transfer Protocol)是互联网上应用最为广泛的一种网络协议。设计HTTP最初的目的是为了提供一种发布和接收HTML页面的方法。
在上面的面试问题中,有一个HTTP请求和HTTP响应。现在分开看一下。
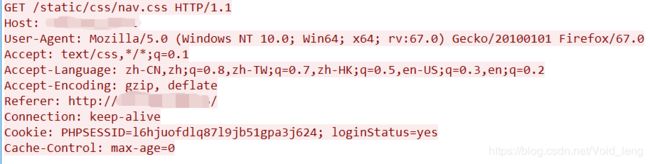
简单抓取一个HTTP请求。(wireshark抓取)
1)⾸⾏: [⽅法] + [url] + [版本]
方法有:GET(获取资源)/POST(传输实体主体)/HEAD(获得报文头部)/PUT(传输文件)/DELETE(删除文件)等
URL:就是网址
GET没有正文,但是POST是有正文的。其实GET的正文在query_string中,有的URL就是很长,即正文在里面。
2)协议头:请求的属性, 冒号分割的键值对;每组属性之间使⽤\n分隔;遇到空⾏(\r\n)表⽰Header部分结束
3)正文:当头部结束后就是正文,这里截取的是GET,所以没有正文。正文也是由键值对组成,和URL里的键值对存在方式是一样的。
目前最常见的方法是GET和POST。
简单抓取的HTTP响应。

后面还有很长的正文,没有截取而已。
1)⾸⾏:[版本号] + [状态码] + [状态码解释]
| 类别 | 原因短语 | |
| 1XX | Informational(信息性状态码) | 接受的请求正在处理 |
| 2XX | Success(成功状态码) | 请求正常处理完毕 |
| 3XX | Redirection(重定向状态码) | 需要进行附加操作以完成请求 |
| 4XX | Client Error(客户端错误状态码) | 服务器无法处理请求 |
| 5XX | Server Error(服务器错误状态码) | 服务器处理请求出错 |
最常⻅的状态码, ⽐如 200(OK), 404(Not Found), 403(Forbidden), 302(Redirect, 重定向), 504(Bad Gateway)。详细了解请点击状态码。
2)协议头: 请求的属性,冒号分割的键值对;每组属性之间使⽤\n分隔;遇到空⾏(\r\n)表⽰Header部分结束
3)正文:空⾏后⾯的内容都是正文。正文允许为空字符串。如果正文存在。则在头部中会有⼀个 Content-Length属性来标识正文的⻓度,如果服务器返回了⼀个html⻚⾯,那么html⻚⾯内容就是在正文中。
HTTP协议头属性:
- Content-Type: 数据类型(text/html等) ;
- Content-Length: Body的⻓度 ;
- Host: 客户端告知服务器, 所请求的资源是在哪个主机的哪个端⼝上;
- User-Agent: 声明⽤户的操作系统和浏览器版本信息;
- referer: 当来前⻚⾯是从哪个⻚⾯跳转过的;
- location: 搭配3xx状态码使⽤, 告诉客户端接下来要去哪⾥访问;
- Cookie: ⽤于在客户端存储少量信息。通常⽤于实现会话(session)的功能;