在强化学习领域最受欢迎的A3C算法,DDPG算法,PPO算法等都是AC框架
AC算法框架被广泛应用于实际强化学习算法中,该框架集成了值函数估计算法和策略搜索算法,是解决实际问题时最常考虑的框架。大家众所周知的alphago便用了AC框架。而且在强化学习领域最受欢迎的A3C算法,DDPG算法,PPO算法等都是AC框架。我们这一讲便总结下AC算法的发展并介绍目前最受关注的A3C算法和PPO算法。
本讲的内容包括:
1.1 策略梯度的直观解释
1.2 Actor-Critic框架引出
1.3 GAE算法
1.4 PPO算法
1.5 DDPG算法
1.6 A3C算法
AC算法起源于策略梯度算法,因此在介绍AC算法时,我们先从策略梯度入手。
1.1 策略梯度的直观解释:
随机策略梯度的计算公式为:(具体推导请参看强化学习进阶 第六讲 策略梯度方法)
(1.1)
利用经验平均估计策略的梯度:
(1.2)
下面对上式进行直观上的解释: 是两项的乘积,我们一项项看:
第一项: ,这是一个方向向量,而且其方向是 对于参数 变化最快的方向,参数在这个方向上更新可以增大或者降低 ,也就是能增大或者降低轨迹 的概率 。
第二项: ,这是一个标量,在策略梯度中扮演着向量 的幅值的角色, 越大,向量的幅值越大,轨迹 出现的概率 在参数更新后会更大。因此,策略梯度的直观含义是增大高回报轨迹的概率,降低低回报轨迹的概率。
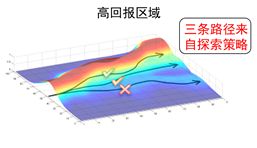
图1 策略梯度的直观解释
1.2 Actor-Critic框架引出
从策略梯度的直观解释我们可以看到,轨迹回报 就像是一个评价器(Critic),该评价器(Critic)评价参数更新后,该轨迹出现的概率应该变大还是变小。如果变大,应该变大多少;如果减小,应该减小多少。也就是说,策略的参数调整幅度由轨迹回报 进行评价。可以将 进行推广而不影响策略梯度大小的计算。根据Shulman的博士论文,在保持策略梯度不变的情况下,策略梯度可写为:
(1.3)
可以是下列任何一个:
轨迹的总回报,
动作后的回报
加入基线的形式
状态-行为值函数
,优势函数
我们分析一下这六个可选的评价函数。
1--3:直接应用轨迹的回报累积回报,由此计算出来的策略梯度不存在偏差,但是由于需要累积多步的回报,因此方差会很大。
4—6: 利用动作值函数,优势函数和TD偏差代替累积回报,其优点是方差小,但是这三种方法中都用到了逼近方法,因此计算出来的策略梯度都存在偏差。这三种方法以牺牲偏差来换取小的方差。当 取4—6时,为经典的AC方法。
在式(1.3)中, 为Actor, 称为Critic,因此(1.3)式是一个广义的AC框架。
Actor为策略函数,经常用神经网络来表示,因此称为策略网络。
Critic为评价函数,对于大部分问题, 也常常用神经网络进行逼近, 它的参数常用表示,因此Critic又称为评价网络。
当 取TD残差,并且值函数 由参数为 的神经网络进行逼近时。AC算法的更新步骤为:
值函数网络的更新:
策略网络部分的更新:
为了充分利用ac方法可以减小策略梯度的方差,同时弥补普通的ac算法中策略梯度存在较大偏差的缺点,Shulman在博士论文中提出一种GAE的方法。
2017.9.19日更新
废话不说了,继续更新
1.3 GAE算法
GAE的方法是对优势函数进行估计。
上一节中,我们已经介绍了 可以取六种形式,其中有一种是 可取优势函数 。优势函数的定义为:
一般来说, 取优势函数时,比取值函数 时计算得到的策略梯度,方差要小,收敛速度要快。
对于这个结论,我们可以从两个方面去理解:
第一: 可以将值函数看成是策略梯度算法中的最优基线函数。基线函数的引入可以减小策略梯度的方差。
第二:从更直观的角度去理解。在本讲的1.1小节,我们已经给出了策略梯度的直观解释。在直观解释中,“ 增大高回报轨迹的概率,降低低回报轨迹的概率。”,当采用优势函数时,这里的优势函数 相当于 ,优势函数是动作值函数相对于值函数的优势,若动作值函数比值函数大,那么优势函数为正;若动作值函数比值函数小,那么优势函数为负。
对于策略梯度而言,优势函数为正时,其幅值为正,则参数沿着使得该轨迹概率增大的方向更新;优势函数为负时,策略梯度的幅值为负,则参数沿着使得该轨迹减小的方向更新。因此,采用优势函数时,算法的收敛速度更快。
然而,根据优势函数定义 ,优势函数中的值函数常常利用逼近算法近似计算,因此往往会引入偏差。
优势函数的一步估计可写为:
从优势函数的一步估计中我们看到, 和 的真实值都是未知的,而是用到了估计值,因此优势函数存在偏差。
GAE的方法是改进对优势函数的估计,将偏差控制到一定的范围内。其方法是对优势函数进行多步估计,并将这些多步估计利用衰减因子进行组合。具体是这样做的:
优势函数的2步估计及无穷步估计分别为:
从上面的公式我们看到,k越大,产生偏差的项 越小,因此优势函数的估计偏差越小。但,相应的方差也会变大。
Shulman 提出广义优势函数估计 ,利用指数加权平均从1步到无穷步的优势函数估计,即:
GAE算法可以从回报shapping的角度进行理解和解释。
在回报shapping中,定义转换回报函数为:
令 ,则转换回报函数的累积回报可写为:
也就是说,广义优势函数可以看成是回报为转换回报,折扣因子为 的折扣累积回报。因此, 很好地平衡了偏差和方差。讲了那么多,其实是为了说明,利用代替AC方法中的Critic会产生更好的效果。
今天暂时更新到这里吧,明天继续更新,2017.9.20更新
1.4 PPO算法及发展
PPO算法是今年谷歌deepmind: https://deepmind.com/blog/producing-flexible-behaviours-simulated-environments/ 和openai:https://blog.openai.com/openai-baselines-ppo/于七月份争先推出的可以做出很炫效果的算法。
PPO也是一个AC的框架,在本讲1.3节中GAE通过利用广义优势函数来平衡Critic的偏差和方差;而PPO则是改进Actor部分,也就是在策略参数更新上进行改善。
PPO算法来源于TRPO算法,我们已经在本专栏给出了TRPO算法的详细推导过程。强化学习进阶 第七讲 TRPO
TRPO算法是Shulman博士为了解决普通的策略梯度算法无法保证性能单调非递减而提出来的方法。也就是说,普通的策略梯度算法无法解决更新步长的问题,对于普通的策略梯度方法,如果更新步长太大,则容易发散;如果更新步长太小,即使收敛,收敛速度也很慢。
Shulman并不从策略梯度的更新步长下手,而是换了一个思路:更换优化函数。通过理论推导和分析,Shulman找到一个替代损失函数(Surrogate loss),最终将强化学习策略更新步转化为如下优化问题:
TRPO的标准解法是将目标函数进行一阶近似,约束条件利用泰勒进行二阶展开,然后利用共轭梯度的方法求解最优的更新参数。
然而当策略选用深层神经网络表示时,TRPO的标准解法计算量会非常大。因为共轭梯度法需要将约束条件进行二阶展开,二阶矩阵的计算量非常大。
PPO是TRPO的一阶近似,可以应用到大规模的策略更新中。Openai的科学家在2016年的NIPS提出利用一阶梯度的方法求解TRPO即PPO的方法。其伪代码如图2所示。

图2 2016NIPS PPO算法
从伪代码我们很清楚地看到,PPO利用了TRPO推导出来的损失函数,并用随机梯度下降的方法更新参数,其中正则项是为了控制更新的策略参数离当前的策略参数不要太远。
Deepmind的DPPO算法:
Google的科学家在NIPS听了报告后,发现PPO确实是个好东西,他们结合自身强大的并行计算能力推出了DPPO,也就是分布式PPO算法。
DPPO的伪代码如图3所示为deepmind的PPO主程序,在主程序中,一个开设了W个线程,每个线程独立与环境交互,采集数据,并计算相应的梯度,当W-D个线程完成梯度计算后就可以更新全局的参数了。

图3 deepmind DPPO主程序
谷歌在发出他们的DPPO算法后,作为PPO算法原创的OpenAi的科学家不甘落后,两周后发出了它们新的PPO算法。
Openai新的PPO算法:
Deepmind将原来的PPO算法加了并行计算然后发了一篇论文,说实话创新性并不是太大。但效果惊人地好,影响力也很巨大。OpenAI将它们的最新的PPO算法也公开了。新的PPO算法对替代目标函数进行了进一步的改进,让优化过程变得更加简洁。新的替代损失函数为:
其中:
在论文中,Shulman等人发现利用这个更简单的目标函数,效果会更好。相比于deepmind, 从创新性来说,还是原创更强。
PPO算法的局限及最新的发展ACKTR算法
PPO算法来自于TRPO,而TRPO是为了解决策略梯度算法中步长难以选择的问题。所以,从本质上来说PPO算法还是策略梯度算法。因此PPO拥有策略梯度算法的局限性。策略梯度算法的局限性在哪呢?
其局限性在:参数是沿着策略梯度的方向进行更新的。
然而,参数本身有自己的空间结构,策略梯度的方向没有考虑参数本身的空间结构,因此更新速度会慢。那么,如何加快训练呢?
答案是计算参数的自然策略梯度。
然而,计算自然策略梯度的时候需要计算Fisher矩阵,这个矩阵的计算及其复杂,尤其是对于大型的深度神经网络来说,这个计算更复杂了。
那么怎么办呢?
上矩阵分解。
于是就出现了2017年8月份的ACKTR算法。该算法是多伦多大学和纽约大学联合提出来的。ACKTR算法已经集成到了Openai的baseline软件中,它会激剧加快PPO算法的收敛速度。
今天先更新到这里,明天继续更新,如果对你有帮助,请赞赏。2017.9.21
1.5 DDPG算法
尽管PPO的算法学习效率比较高,但PPO算法所使用的策略还是随机策略。随机策略本身就存在一些难以逾越的问题,比如动作空间维数很大时,利用随机策略就需要采集很多样本才能对该策略进行评估。对于像机器人等动作空间维数很高的系统,随机策略并不是一个很好的选择。Silver等提出利用确定性策略代替随机策略。
在本专栏的 https://zhuanlan.zhihu.com/p/26441204 对确定性策略进行了比较详细的讲解。在这里只对其进行更宏观上的总结。
1. DDPG或DPG是异策略的方法,行为策略为随机策略,评估策略为确定性策略。随机策略可以探索和产生多样的行为数据,确定性策略利用这些数据进行策略的改善。
2. 确定性策略梯度的计算公式为:
上面1.2节中我们已经讲了对于随机策略AC的方法,其中Critic部分可取多种形式,如:行为值函数,TD残差,优势函数甚至是GAE。然而,对于确定性策略梯度方法,Critic只能取行为值函数。确定性策略梯度的网络结构为:
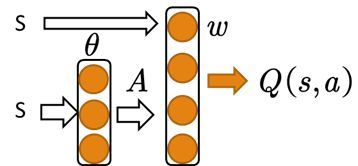
图4 DDPG结构图
异策略确定性策略梯度的更新公式为:
需要注意的是,在进行Critic的参数更新时,即上面更新公式的前两行时,动作a为输入,权重w连接的是输入状态s和动作a。
在进行Actor更新的时候,需要更新的参数是 ,也就是说确定性策略计算中 与参数 无关
1.6 A3C算法
众所周知,当利用神经网络逼近行为值函数的时候,神经网络往往不稳定。这是因为在监督学习中,对神经网络进行训练时,假设数据都是独立同分布的。而直接利用强化学习的数据对利用神经网络进行逼近的值函数进行训练时,数据之间存在着很强的时间相关性,这是导致神经网络训练不稳定的最主要原因。
为了打破数据之间的相关性,DQN和DDPG的方法都利用了经验回放的技巧。然而,打破数据的相关性,经验回放并非是唯一的方法。另外一种方法是异步的方法。
所谓异步的方法是指数据并非同时产生,A3C的方法便是其中表现非常优异的异步强化学习算法。
A3C全称为 Asynchronous
advantage actor-critic ,中文名字是异步优势动作评价算法。因为该算法的前三个单词的首字母都是A,所以简写为A3C。
A3C的基本框架还是AC框架,只是它不在利用单个线程,而是利用多个线程。每个线程相当于一个智能体在随机探索,多个智能体共同探索,并行计算策略梯度,维持一个总的更新量。A3C的并行机制与谷歌的DPPO是一致的。
A3C的伪代码如图所示:

图5 A3C伪代码
本小节到此结束,希望对大家有帮助。2017.9.27更新
参考文献:
谷歌 dppo:
Heess N, Dhruva T B, Sriram S, et al. Emergence of Locomotion Behaviours in Rich Environments[J]. 2017.
openai ppo:
Schulman J, Wolski F, Dhariwal P, et al. Proximal Policy Optimization Algorithms[J]. 2017.
最新ACKTR:
Wu Y, Mansimov E, Liao S, et al. Scalable trust-region method for deep reinforcement learning using Kronecker-factored approximation[J]. 2017.