深度学习在CV领域的进展以及一些由深度学习演变的新技术
CV领域

1.进展:如上图所述,当前CV领域主要包括两个大的方向,”低层次的感知” 和 “高层次的认知”。
2.主要的应用领域:视频监控、人脸识别、医学图像分析、自动驾驶、 机器人、AR、VR
3.主要的技术:分类、目标检测(识别)、分割、目标追踪、边缘检测、姿势评估、理解CNN、超分辨率重建、序列学习、特征检测与匹配、图像标定,视频标定、问答系统、图片生成(文本生成图像)、视觉关注性和显著性(质量评价)、人脸识别、3D重建、推荐系统、细粒度图像分析、图像压缩
分类主要需要解决的问题是“我是谁?”
目标检测主要需要解决的问题是“我是谁? 我在哪里?”
分割主要需要解决的问题是“我是谁? 我在哪里?你是否能够正确分割我?”
目标追踪主要需要解决的问题是“你能不能跟上我的步伐,尽快找到我?”
边缘检测主要需要解决的问题是:“如何准确的检测到目标的边缘?”
人体姿势评估主要需要解决的问题是:“你需要通过我的姿势判断我在干什么?”
理解CNN主要需要解决的问题是:“从理论上深层次的去理解CNN的原理?”
超分辨率重建主要需要解决的问题是:“你如何从低质量图片获得高质量的图片?”
序列学习主要解决的问题是“你知道我的下一幅图像或者下一帧视频是什么吗?”
特征检测与匹配主要需要解决的问题是“检测图像的特征,判断相似程度?”
图像标定主要需要解决的问题是“你能说出图像中有什么东西?他们在干什么呢?”
视频标定主要需要解决的问题是“你知道我这几帧视频说明了什么吗?”
问答系统主要需要解决的问题是:“你能根据图像正确回答我提问的问题吗?”
图片生成主要需要解决的问题是:“我能通过你给的信息准确的生成对应的图片?”
视觉关注性和显著性主要需要解决的问题是:“如何提出模拟人类视觉注意机制的模型?”
人脸识别主要需要解决的问题是:“机器如何准确的识别出同一个人在不同情况下的脸?”
3D重建主要需要解决的问题是“你能通过我给你的图片生成对应的高质量3D点云吗?”
推荐系统主要需要解决的问题是“你能根据我的输入给出准确的输出吗?”
细粒度图像分析主要需要解决的问题是“你能辨别出我是哪一种狗吗?等这些更精细的任务”
图像压缩主要需要解决的问题是“如何以较少的比特有损或者无损的表示原来的图像?”
注:
1. 以下我主要从CV领域中的各个小的领域入手,总结该领域中一些网络模型,基本上覆盖到了各个领域,力求完整的收集各种经典的模型,顺序基本上是按照时间的先后,一般最后是该领域最新提出来的方案,我主要的目的是做一个整理,方便自己和他人的使用,你不再需要去网上收集大把的资料,需要的是仔细分析这些模型,并提出自己新的模型。这里面收集的论文质量都比较高,主要来自于ECCV、ICCV、CVPR、PAM、arxiv、ICLR、ACM等顶尖国际会议。并且为每篇论文都添加了链接。可以大大地节约你的时间。同时,我挑选出论文比较重要的网络模型或者整体架构,可以方便你去进行对比。有一个更好的全局观。具体 细节需要你去仔细的阅读论文。由于个人的精力有限,我只能做成这样,希望大家能够理解。谢谢。
2. 我会利用自己的业余时间来更新新的模型,但是由于时间和精力有限,可能并不完整,我希望大家都能贡献的一份力量,如果你发现新的模型,可以联系我,我会及时回复大家,期待着的加入,让我们一起服务大家!
如下图所示:
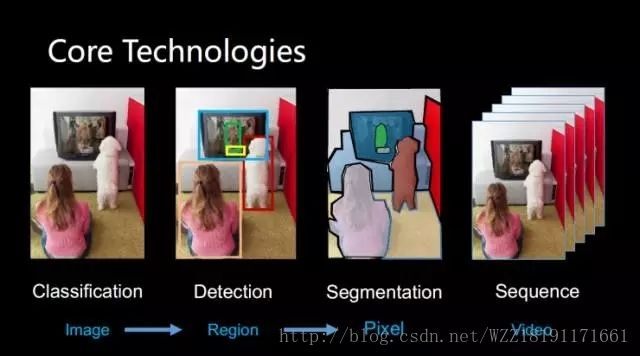
分类:这是一个基础的研究课题,已经获得了很高的准确率,在一些场合上面已经远远地超过啦人类啦!
典型的网络模型
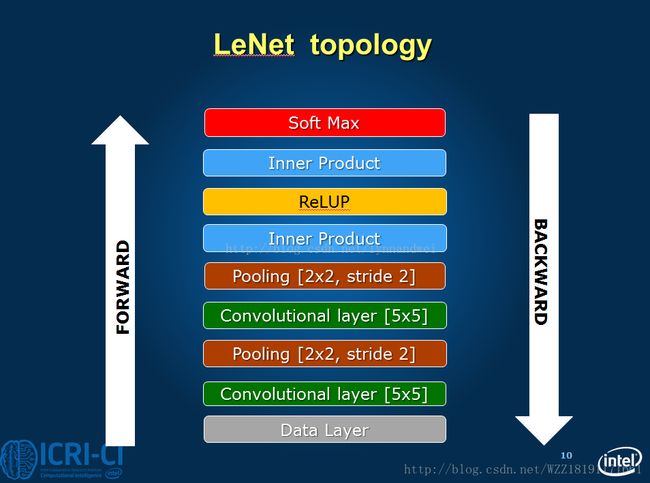
LeNet
http://yann.lecun.com/exdb/lenet/index.htmlAlexNet
http://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdfDelving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification
https://arxiv.org/pdf/1502.01852.pdfBatch Normalization
https://arxiv.org/pdf/1502.03167.pdfGoogLeNet
http://www.cv-foundation.org/openaccess/content_cvpr_2015/papers/Szegedy_Going_Deeper_With_2015_CVPR_paper.pdfVGGNet
https://arxiv.org/pdf/1409.1556.pdfResNet
https://arxiv.org/pdf/1512.03385.pdfInceptionV4(Inception-ResNet)
https://arxiv.org/pdf/1602.07261.pdf
LeNet网络1:
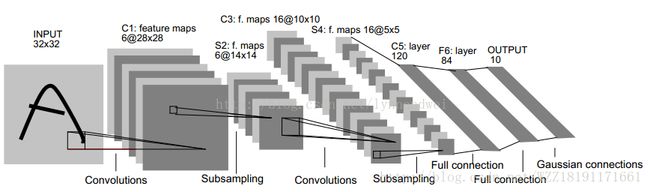
LeNet网络2:
AlexNet网络1:
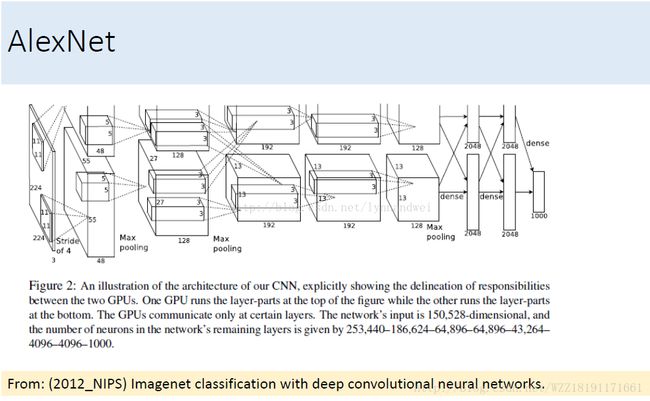
AlexNet网络2:
Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification网络:
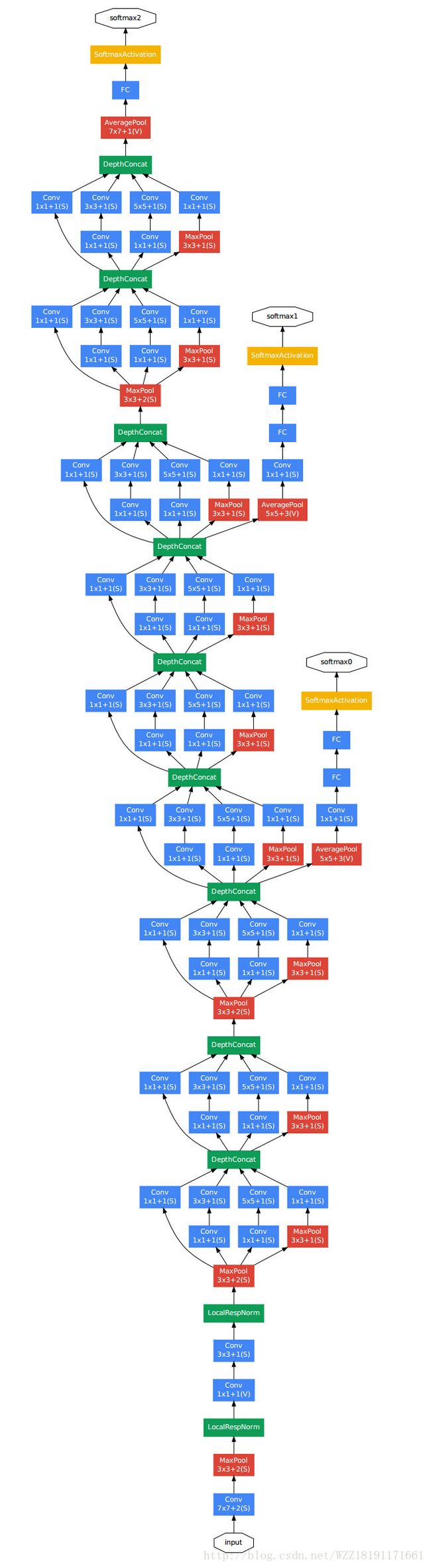
GoogLeNet网络1:
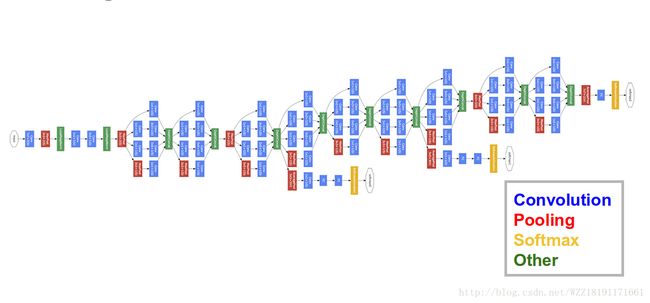
GoogLeNet网络2:
Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification网络:
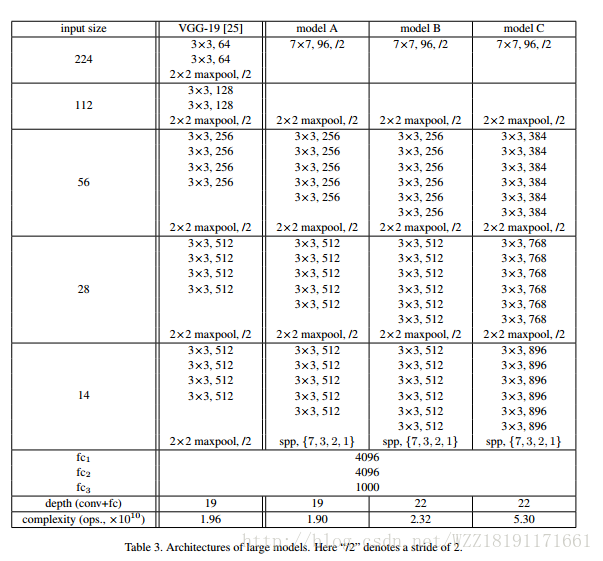
Batch Normalization:
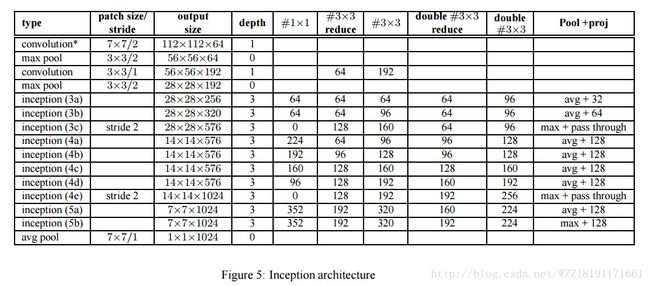
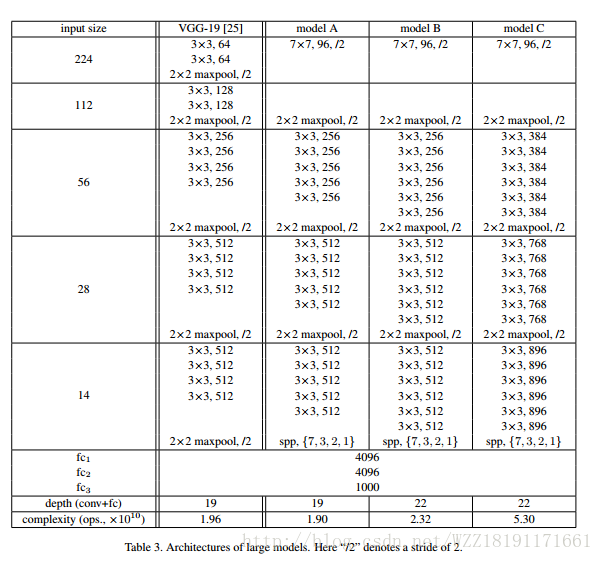
VGGNet网络1:
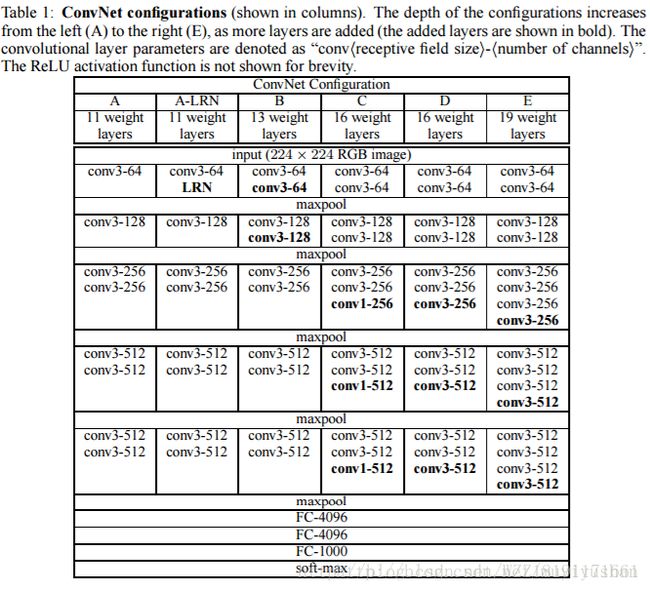
VGGNet网络2:
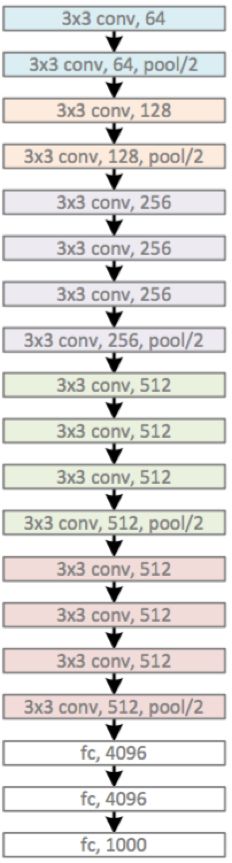
ResNet网络:
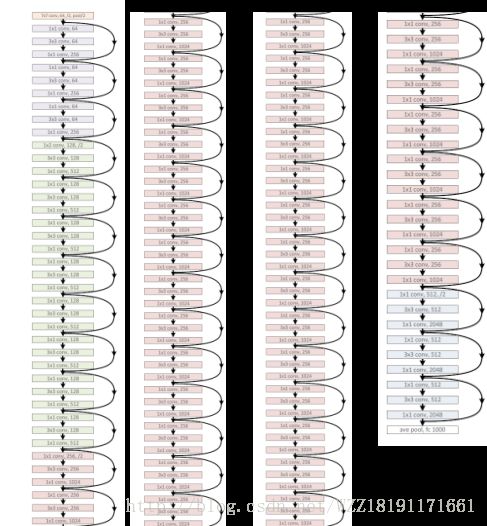
InceptionV4网络:
图像检测:这是基于图像分类的基础上所做的一些研究,即分类+定位。
典型网络
OVerfeat
https://arxiv.org/pdf/1312.6229.pdfRNN
https://arxiv.org/pdf/1311.2524.pdfSPP-Net
https://arxiv.org/pdf/1406.4729.pdfDeepID-Net
https://arxiv.org/pdf/1409.3505.pdfFast R-CNN
https://arxiv.org/pdf/1504.08083.pdfR-CNN minus R
https://arxiv.org/pdf/1506.06981.pdfEnd-to-end people detection in crowded scenes
https://arxiv.org/pdf/1506.04878.pdfDeepBox
https://arxiv.org/pdf/1505.02146.pdfMR-CNN
http://www.cv-foundation.org/openaccess/content_iccv_2015/papers/Gidaris_Object_Detection_via_ICCV_2015_paper.pdfFaster R-CNN
https://arxiv.org/pdf/1506.01497.pdfYOLO
https://arxiv.org/pdf/1506.02640.pdfDenseBox
https://arxiv.org/pdf/1509.04874.pdfWeakly Supervised Object Localization with Multi-fold Multiple Instance Learning
https://arxiv.org/pdf/1503.00949.pdfR-FCN
https://arxiv.org/pdf/1605.06409.pdfSSD
https://arxiv.org/pdf/1512.02325v2.pdfInside-Outside Net
https://arxiv.org/pdf/1512.04143.pdfG-CNN
https://arxiv.org/pdf/1512.07729.pdfPVANET
https://arxiv.org/pdf/1608.08021.pdfSpeed/accuracy trade-offs for modern convolutional object detectors
https://arxiv.org/pdf/1611.10012v1.pdf
OVerfeat网络:
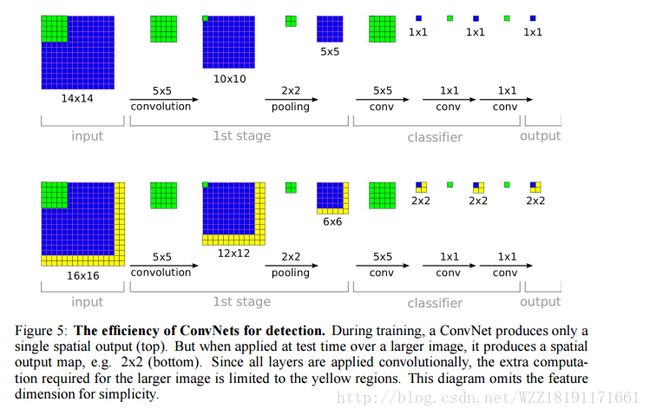

R-CNN网络:

SPP-Net网络:
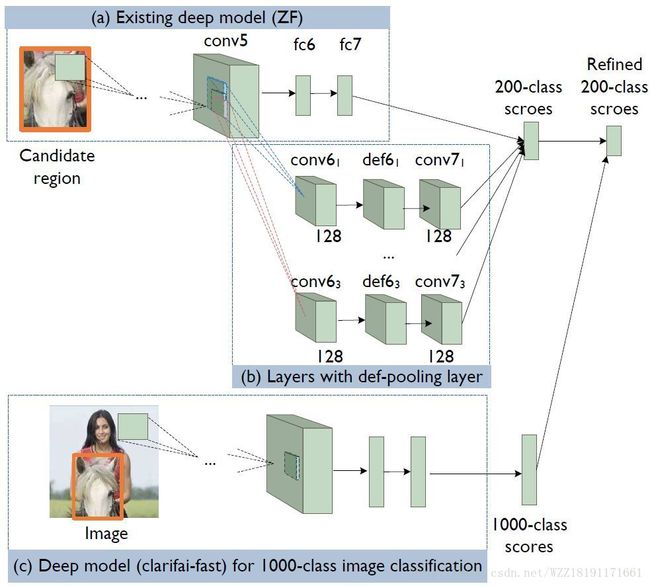
DeepID-Net网络:
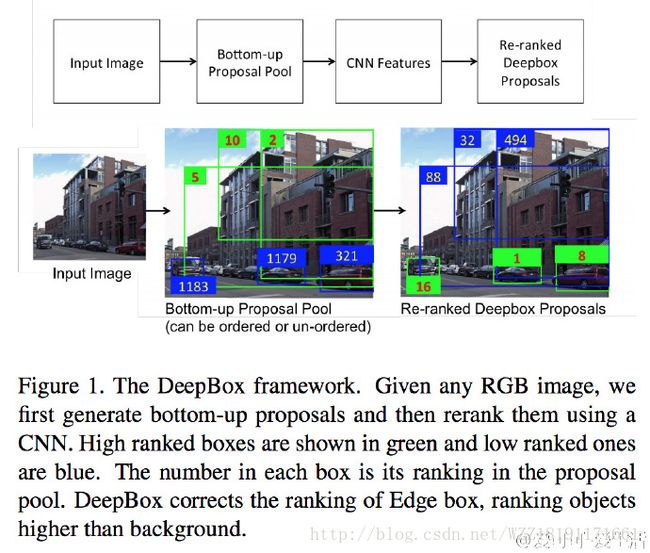
DeepBox网络:
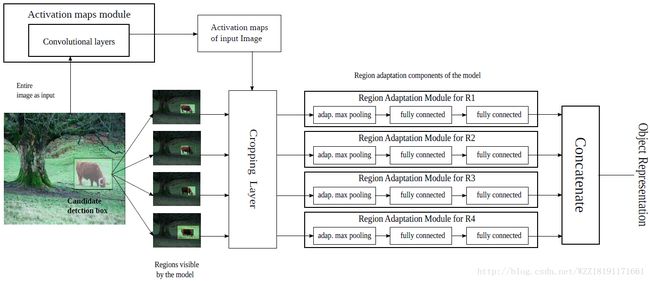
MR-CNN网络:
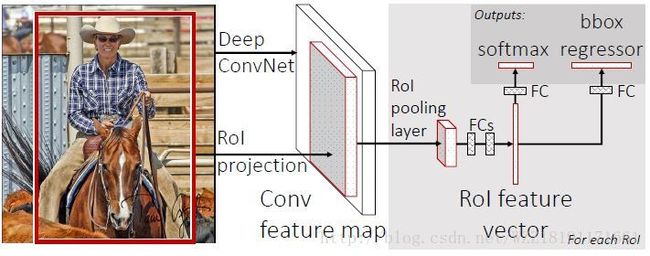
Fast-RCNN网络:
R-CNN minus R网络:

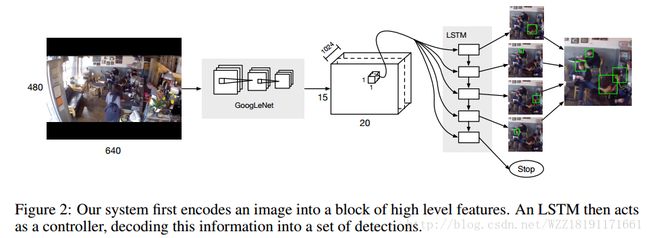
End-to-end people detection in crowded scenes网络:
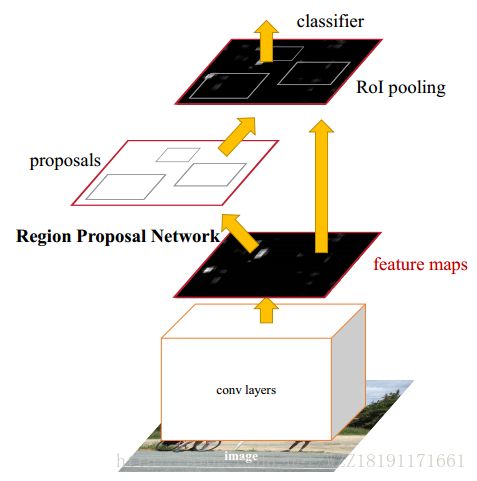
Faster-RCNN网络:
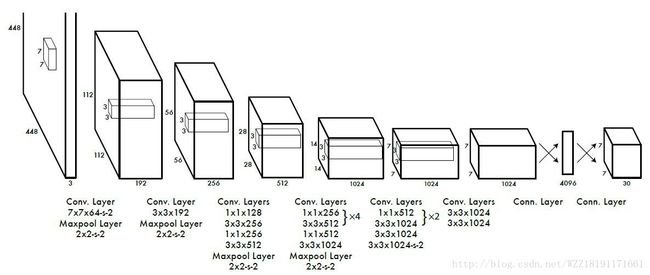
DenseBox网络:
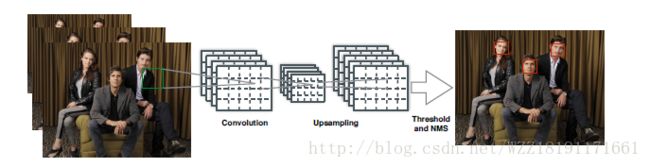
Weakly Supervised Object Localization with Multi-fold Multiple Instance Learning网络:

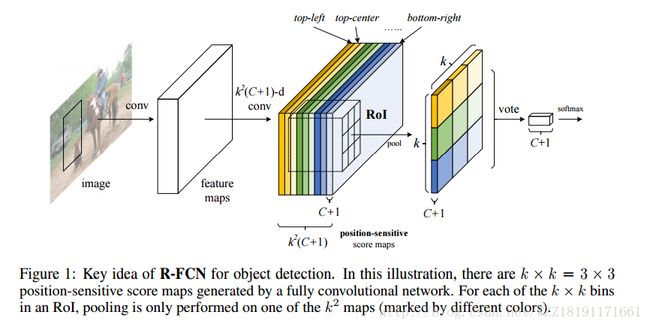
R-FCN网络:
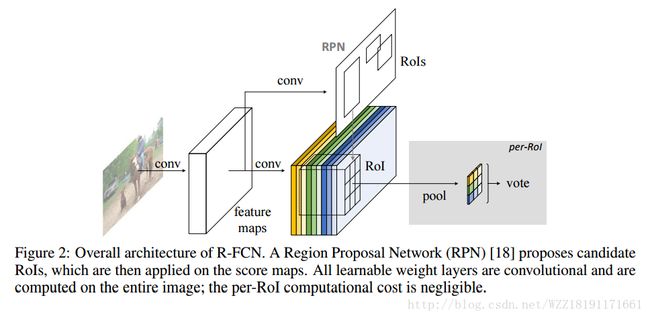
YOLO和SDD网络:

Inside-Outside Net网络:
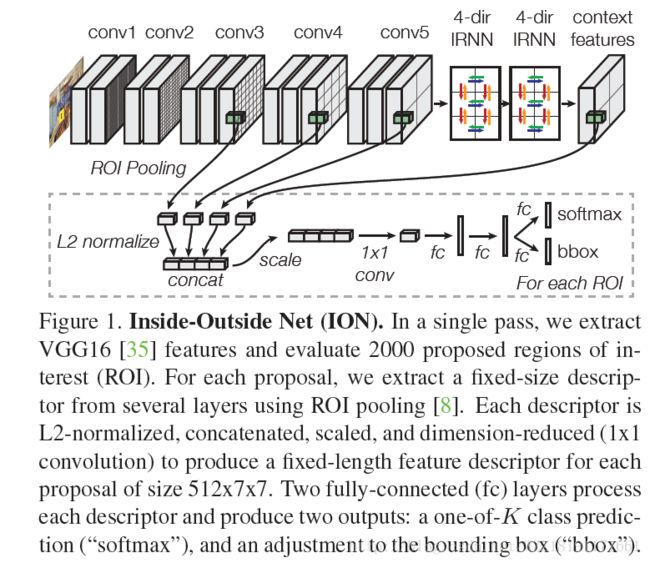
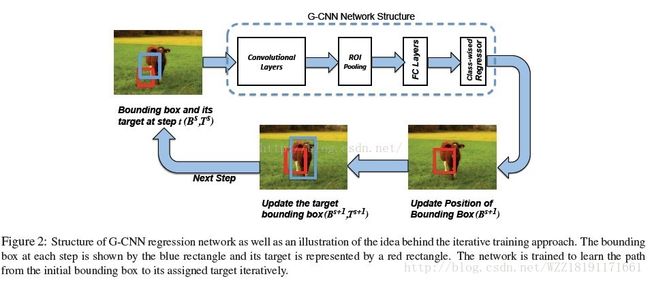
G-CNN网络:
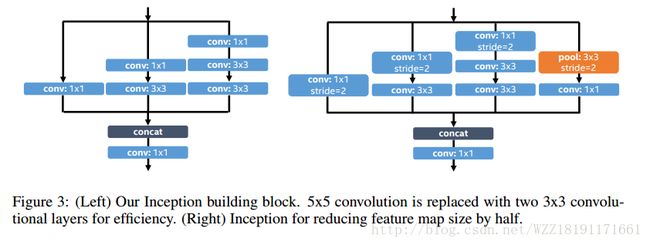
PVANET网络:
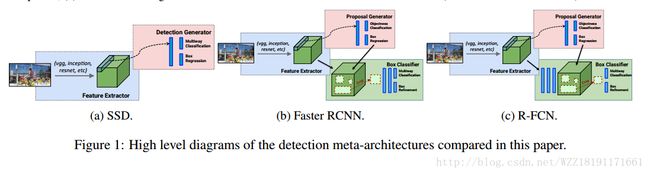
Speed/accuracy trade-offs for modern convolutional object detectors:
图像分割
经典网络模型:
FCN
https://people.eecs.berkeley.edu/~jonlong/long_shelhamer_fcn.pdfsegNet
https://arxiv.org/pdf/1511.00561.pdfDeeplab
https://arxiv.org/pdf/1606.00915.pdfdeconvNet
https://arxiv.org/pdf/1505.04366.pdfConditional Random Fields as Recurrent Neural Networks
http://www.robots.ox.ac.uk/~szheng/papers/CRFasRNN.pdfSemantic Segmentation using Adversarial Networks
https://arxiv.org/pdf/1611.08408.pdfSEC: Seed, Expand and Constrain:
http://pub.ist.ac.at/~akolesnikov/files/ECCV2016/main.pdfEfficient piecewise training of deep structured models for semantic segmentation
https://arxiv.org/pdf/1504.01013.pdfSemantic Image Segmentation via Deep Parsing Network
https://arxiv.org/pdf/1509.02634.pdfBoxSup: Exploiting Bounding Boxes to Supervise Convolutional Networks for Semantic Segmentation
https://arxiv.org/pdf/1503.01640.pdfLearning Deconvolution Network for Semantic Segmentation
https://arxiv.org/pdf/1505.04366.pdfDecoupled Deep Neural Network for Semi-supervised Semantic Segmentation
https://arxiv.org/pdf/1506.04924.pdfPUSHING THE BOUNDARIES OF BOUNDARY DETECTION USING DEEP LEARNING
https://arxiv.org/pdf/1511.07386.pdfLearning Transferrable Knowledge for Semantic Segmentation with Deep Convolutional Neural Network
https://arxiv.org/pdf/1512.07928.pdfFeedforward Semantic Segmentation With Zoom-Out Features
http://www.cv-foundation.org/openaccess/content_cvpr_2015/papers/Mostajabi_Feedforward_Semantic_Segmentation_2015_CVPR_paper.pdfJoint Calibration for Semantic Segmentation
https://arxiv.org/pdf/1507.01581.pdfHypercolumns for Object Segmentation and Fine-Grained Localization
http://www.cv-foundation.org/openaccess/content_cvpr_2015/papers/Hariharan_Hypercolumns_for_Object_2015_CVPR_paper.pdfScene Parsing with Multiscale Feature Learning
http://yann.lecun.com/exdb/publis/pdf/farabet-icml-12.pdfLearning Hierarchical Features for Scene Labeling
http://yann.lecun.com/exdb/publis/pdf/farabet-pami-13.pdfSegment-Phrase Table for Semantic Segmentation, Visual Entailment and Paraphrasing
http://www.cv-foundation.org/openaccess/content_iccv_2015/papers/Izadinia_Segment-Phrase_Table_for_ICCV_2015_paper.pdfMULTI-SCALE CONTEXT AGGREGATION BY DILATED CONVOLUTIONS
https://arxiv.org/pdf/1511.07122v2.pdfWeakly supervised graph based semantic segmentation by learning communities of image-parts
http://www.cv-foundation.org/openaccess/content_iccv_2015/papers/Pourian_Weakly_Supervised_Graph_ICCV_2015_paper.pdf
FCN网络1:

FCN网络2:
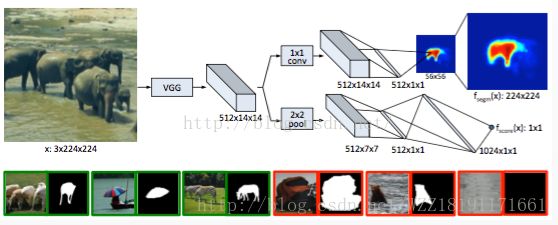
segNet网络:
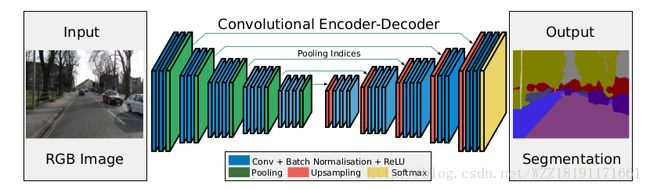
Deeplab网络:
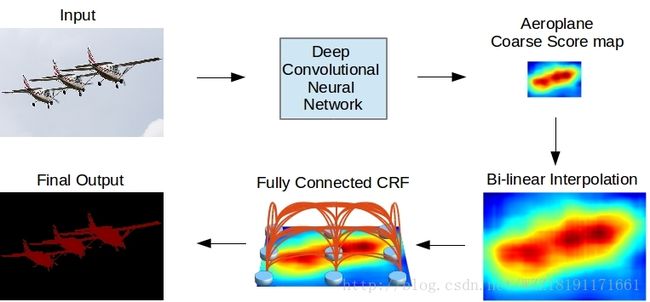
deconvNet网络:
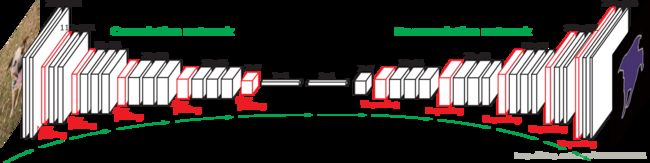
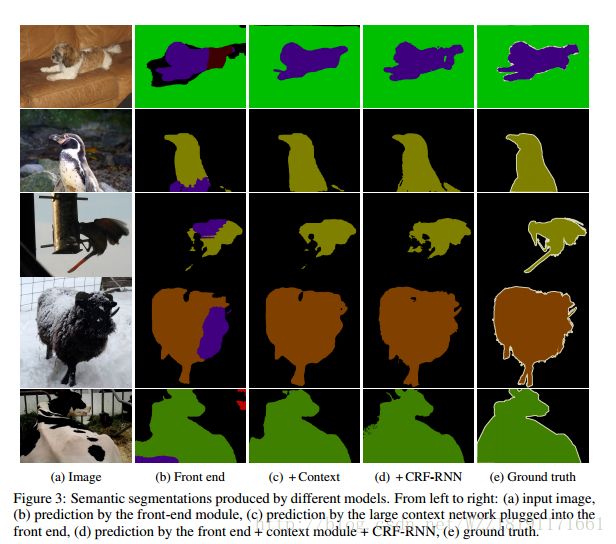
Conditional Random Fields as Recurrent Neural Networks网络:

Semantic Segmentation using Adversarial Networks网络:

SEC: Seed, Expand and Constrain网络:
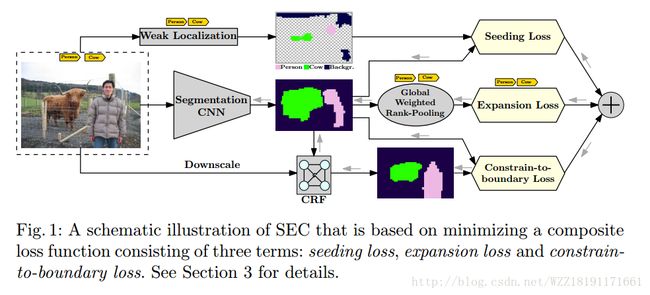
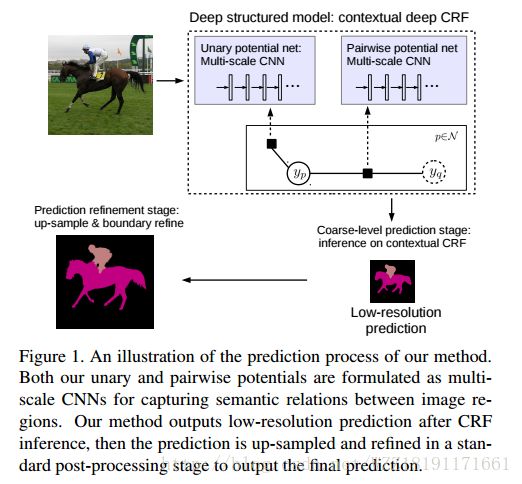
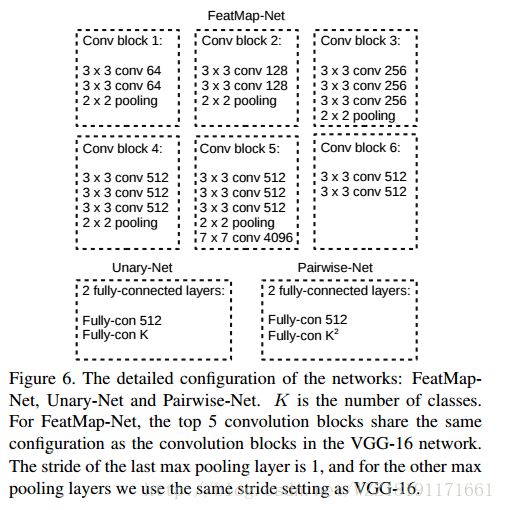
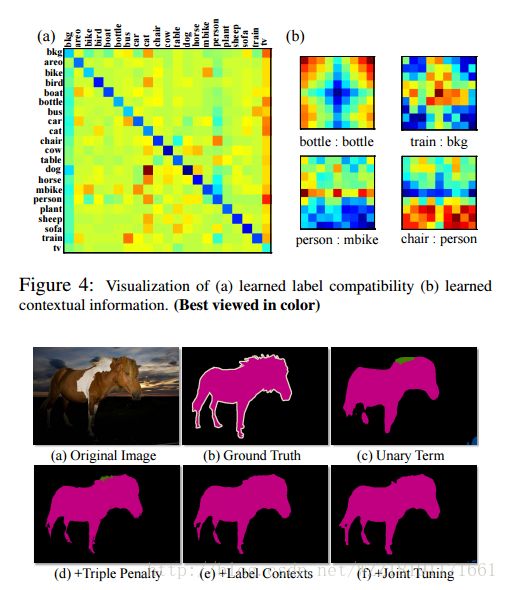
Efficient piecewise training of deep structured models for semantic segmentation网络:

Semantic Image Segmentation via Deep Parsing Network网络:
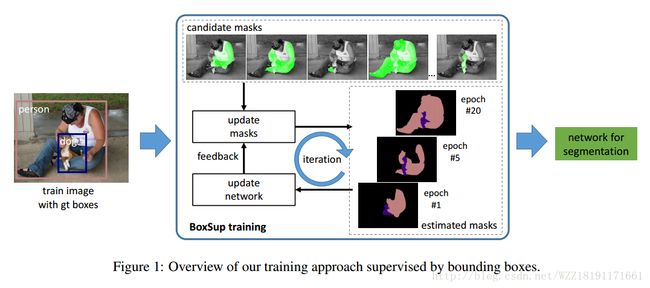
BoxSup: Exploiting Bounding Boxes to Supervise Convolutional Networks for Semantic Segmentation:
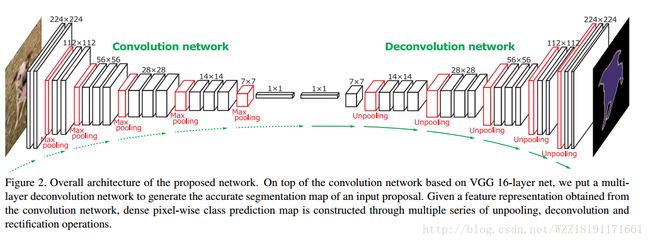
Learning Deconvolution Network for Semantic Segmentation:

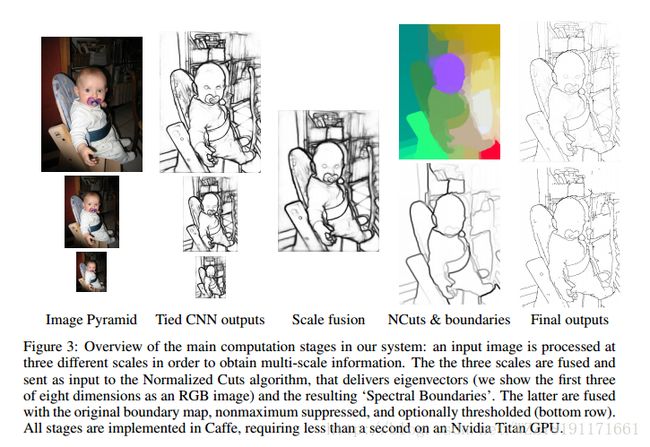
PUSHING THE BOUNDARIES OF BOUNDARY DETECTION USING DEEP LEARNING:
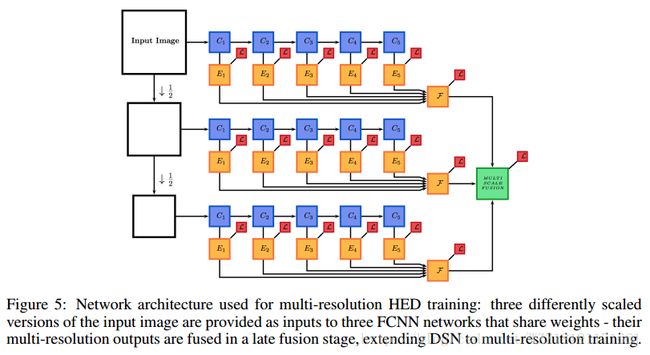
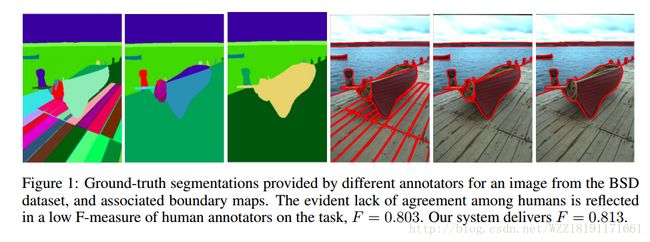
Decoupled Deep Neural Network for Semi-supervised Semantic Segmentation:
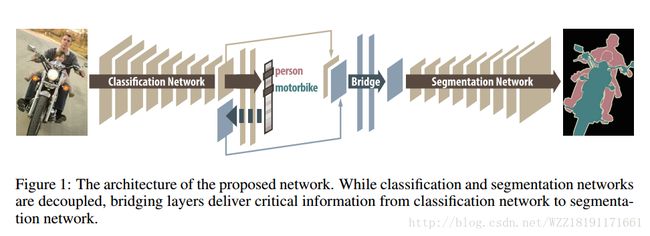
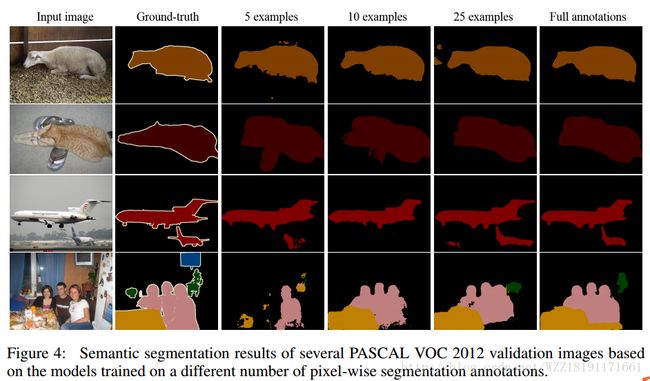
Learning Transferrable Knowledge for Semantic Segmentation with Deep Convolutional Neural Network:
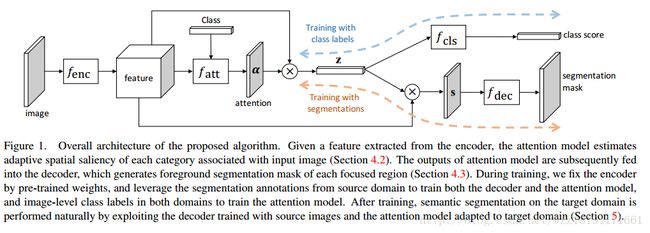
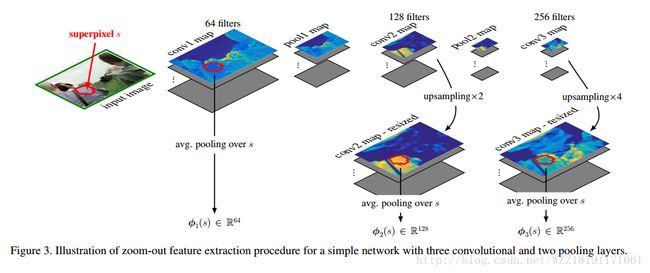
Feedforward Semantic Segmentation With Zoom-Out Features网络:
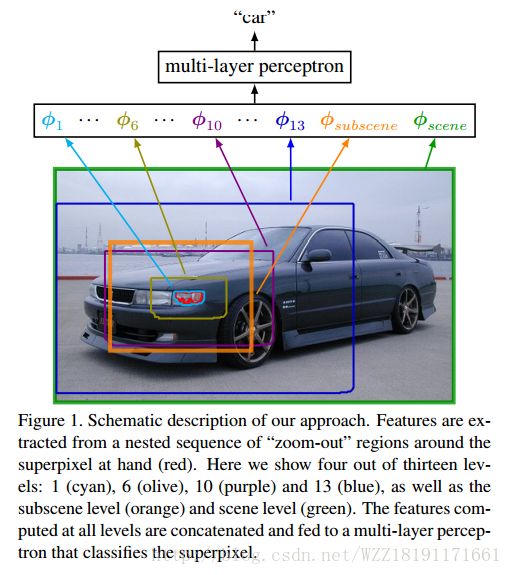

Joint Calibration for Semantic Segmentation:
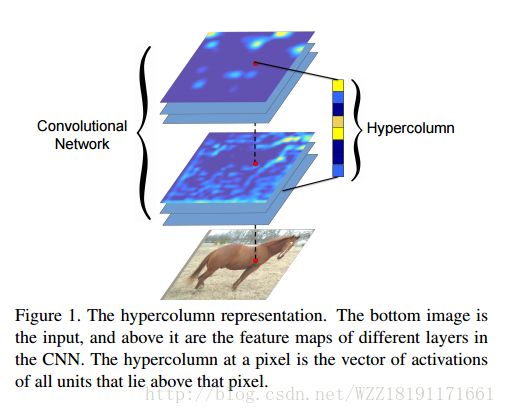
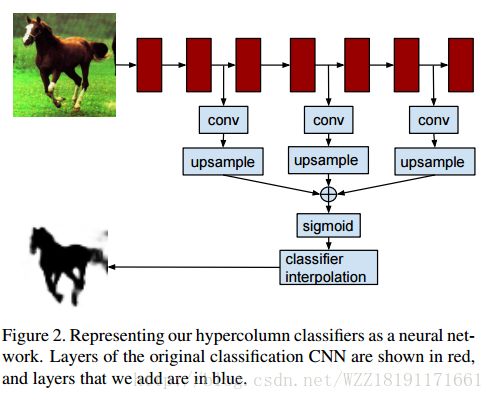
Hypercolumns for Object Segmentation and Fine-Grained Localization:
Learning Hierarchical Features for Scene Labeling:
MULTI-SCALE CONTEXT AGGREGATION BY DILATED CONVOLUTIONS:
Segment-Phrase Table for Semantic Segmentation, Visual Entailment and Paraphrasing:
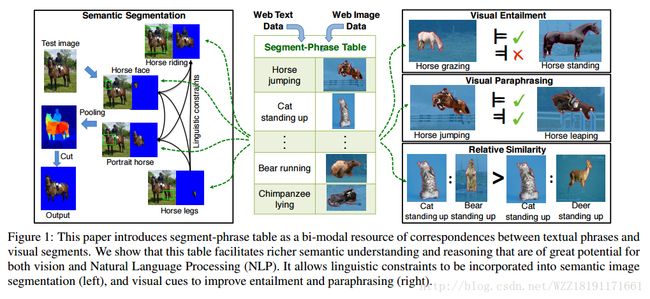
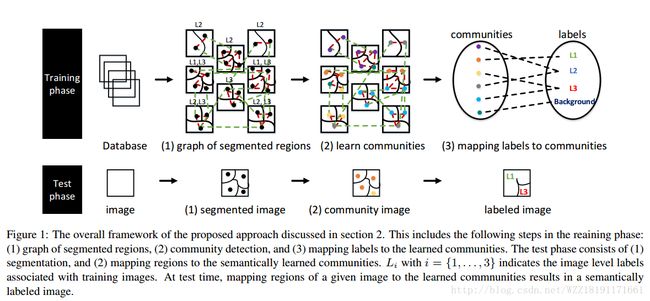
Weakly supervised graph based semantic segmentation by learning communities of image-parts:
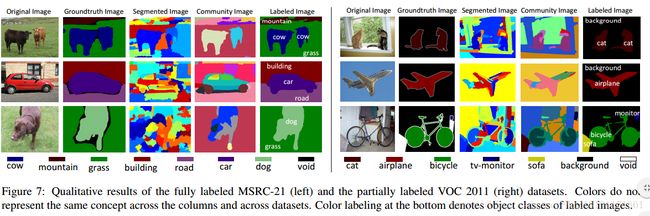
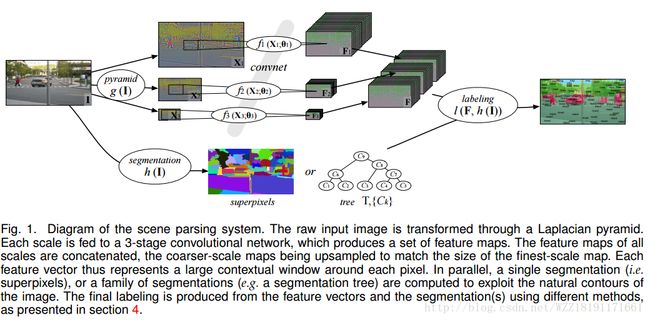
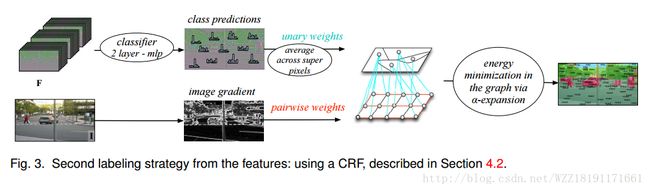
Scene Parsing with Multiscale Feature Learning:
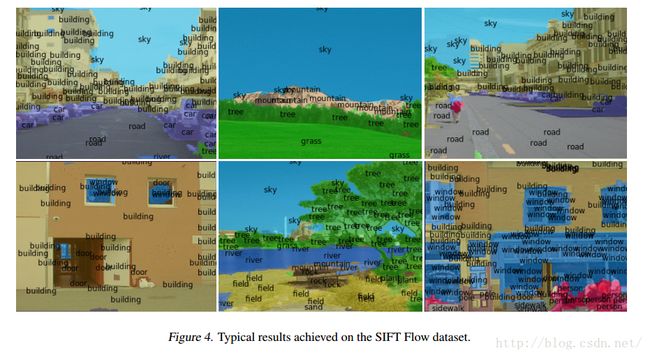
目标追踪
经典网络:
DLT
https://pdfs.semanticscholar.org/b218/0fc4f5cb46b5b5394487842399c501381d67.pdfTransferring Rich Feature Hierarchies for Robust Visual Tracking
https://arxiv.org/pdf/1501.04587.pdfFCNT
http://202.118.75.4/lu/Paper/ICCV2015/iccv15_lijun.pdfHierarchical Convolutional Features for Visual Tracking
http://www.cv-foundation.org/openaccess/content_iccv_2015/papers/Ma_Hierarchical_Convolutional_Features_ICCV_2015_paper.pdfMDNet
https://arxiv.org/pdf/1510.07945.pdfRecurrently Target-Attending Tracking
http://www.cv-foundation.org/openaccess/content_cvpr_2016/papers/Cui_Recurrently_Target-Attending_Tracking_CVPR_2016_paper.pdfDeepTracking
http://www.bmva.org/bmvc/2014/files/paper028.pdfDeepTrack
http://www.bmva.org/bmvc/2014/files/paper028.pdfOnline Tracking by Learning Discriminative Saliency Map
with Convolutional Neural Network
https://arxiv.org/pdf/1502.06796.pdfTransferring Rich Feature Hierarchies for Robust Visual Tracking
https://arxiv.org/pdf/1501.04587.pdf
DLT网络:
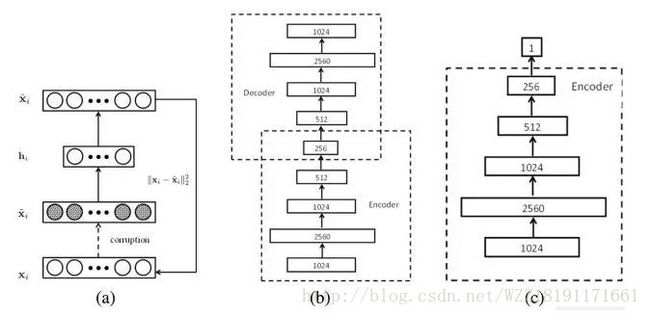
Transferring Rich Feature Hierarchies for Robust Visual Tracking网络:

FCNT网络:
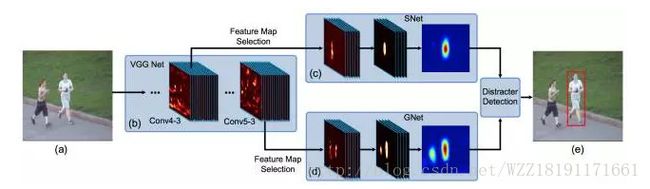
Hierarchical Convolutional Features for Visual Tracking网络:
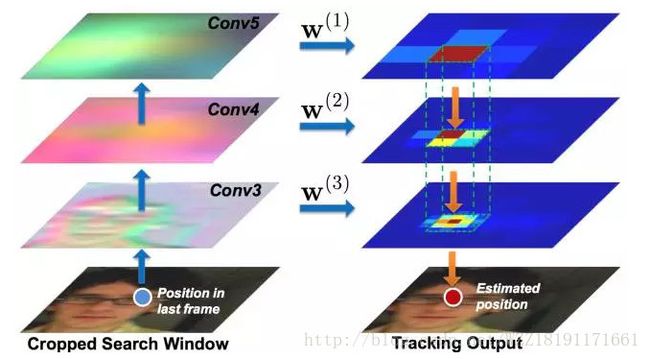
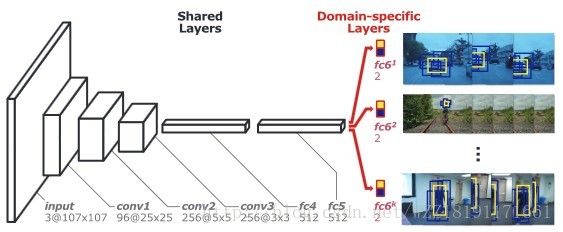
MDNet网络:
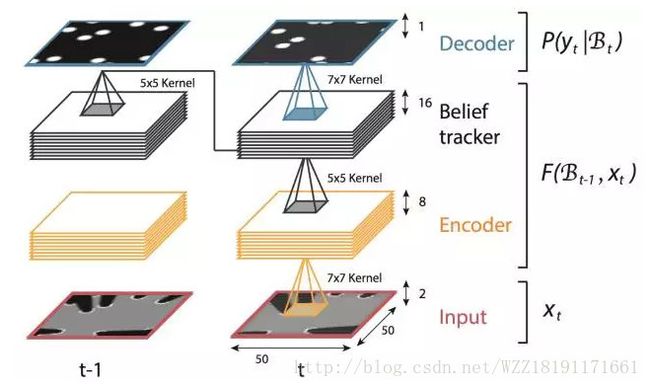
DeepTracking网络:
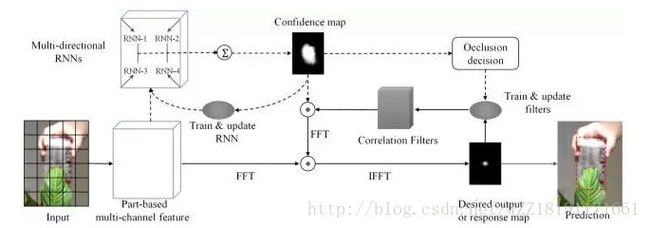
ecurrently Target-Attending Tracking网络:
DeepTrack网络:
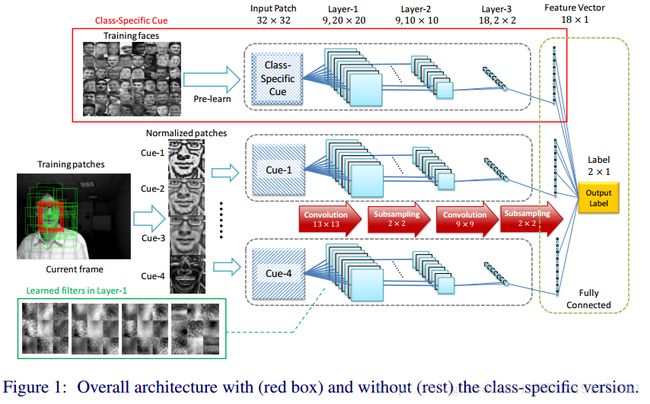
Online Tracking by Learning Discriminative Saliency Map
with Convolutional Neural Network:
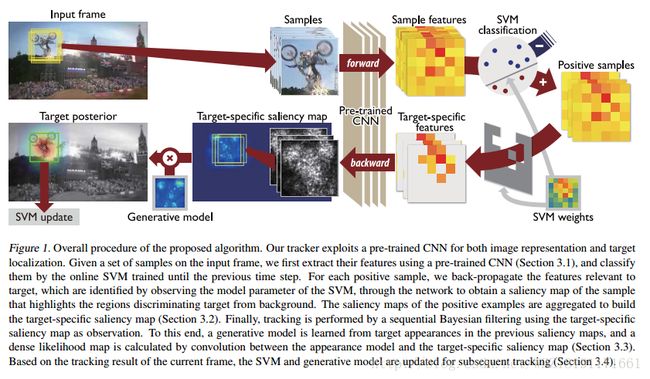
边缘检测
经典模型:
HED
https://arxiv.org/pdf/1504.06375.pdfDeepEdge
https://arxiv.org/pdf/1412.1123.pdfDeepConto
http://mc.eistar.net/UpLoadFiles/Papers/DeepContour_cvpr15.pdf
HED网络:
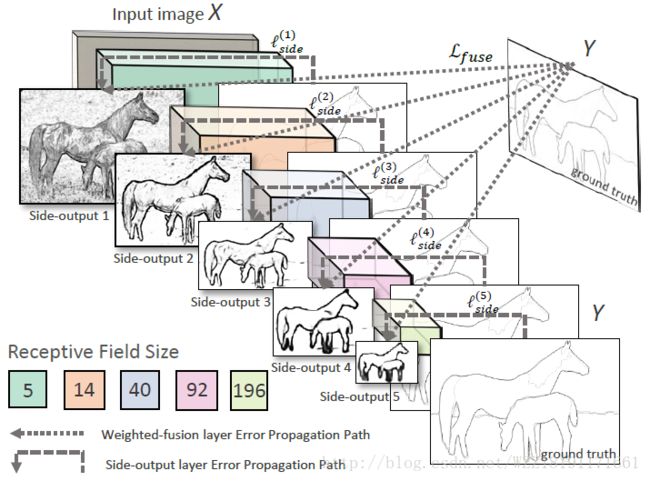
DeepEdge网络:
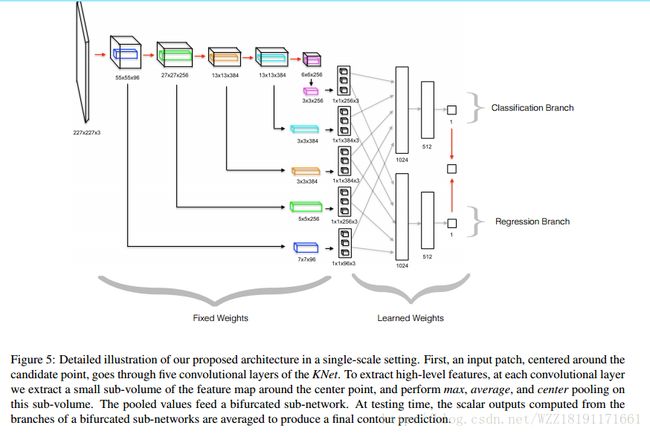

DeepContour网络:
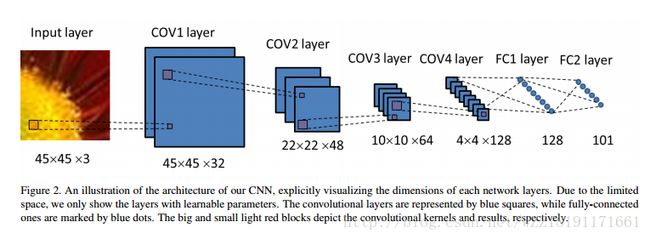
人体姿势评估
经典模型:
DeepPose
https://arxiv.org/pdf/1312.4659.pdfJTCN
https://www.robots.ox.ac.uk/~vgg/rg/papers/tompson2014.pdfFlowing convnets for human pose estimation in videos
https://arxiv.org/pdf/1506.02897.pdfStacked hourglass networks for human pose estimation
https://arxiv.org/pdf/1603.06937.pdfConvolutional pose machines
https://arxiv.org/pdf/1602.00134.pdfDeepcut
https://arxiv.org/pdf/1605.03170.pdfRealtime Multi-Person 2D Pose Estimation using Part Affinity Fields
https://arxiv.org/pdf/1611.08050.pdf
DeepPose网络:

JTCN网络:
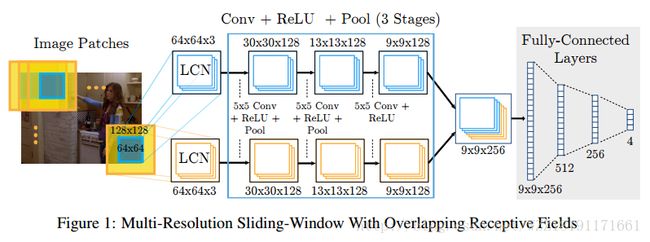
Flowing convnets for human pose estimation in videos网络:
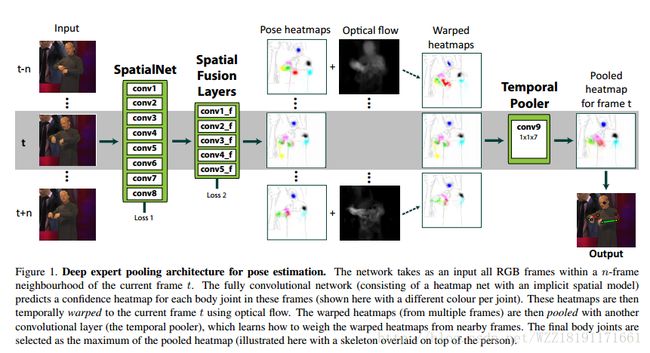
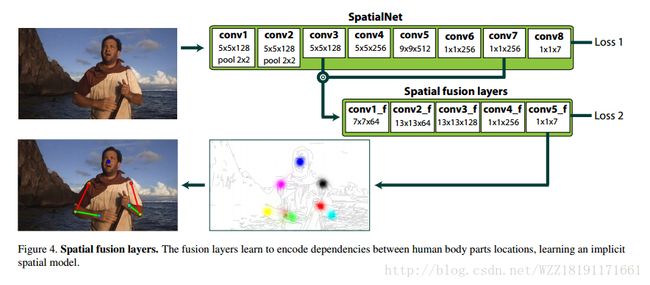
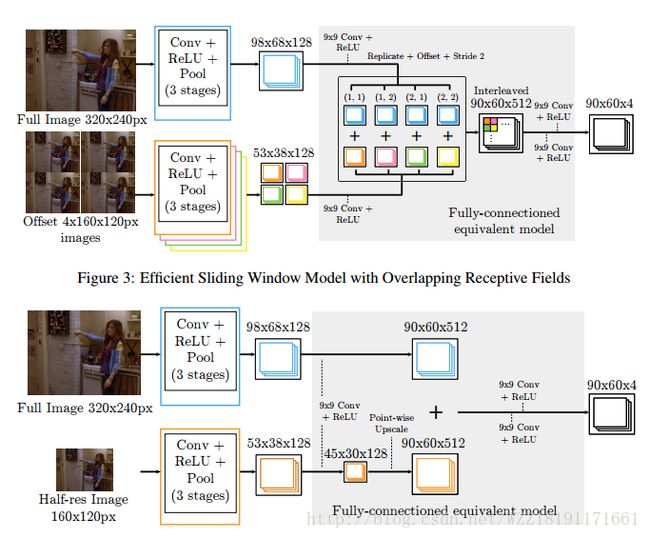
Stacked hourglass networks for human pose estimation网络:
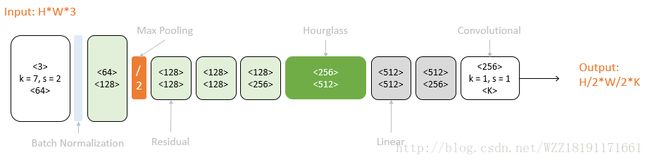
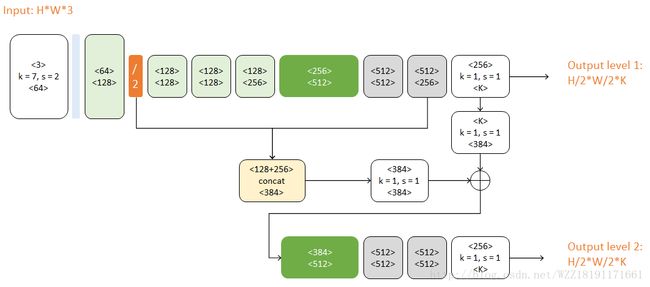
Convolutional pose machines网络:
Deepcut网络:

Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields网络:
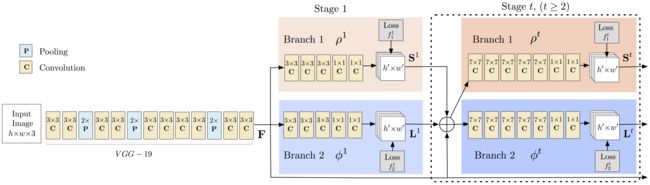
理解CNN
经典网络:
Visualizing and Understanding Convolutional Networks
https://www.cs.nyu.edu/~fergus/papers/zeilerECCV2014.pdfInverting Visual Representations with Convolutional Networks
https://arxiv.org/pdf/1506.02753.pdfObject Detectors Emerge in Deep Scene CNNs
https://arxiv.org/pdf/1412.6856.pdfUnderstanding Deep Image Representations by Inverting Them
http://www.cv-foundation.org/openaccess/content_cvpr_2015/papers/Mahendran_Understanding_Deep_Image_2015_CVPR_paper.pdfDeep Neural Networks are Easily Fooled:High Confidence Predictions for Unrecognizable Images
http://www.cv-foundation.org/openaccess/content_cvpr_2015/papers/Nguyen_Deep_Neural_Networks_2015_CVPR_paper.pdfUnderstanding image representations by measuring their equivariance and equivalence
http://www.cv-foundation.org/openaccess/content_cvpr_2015/papers/Lenc_Understanding_Image_Representations_2015_CVPR_paper.pdf
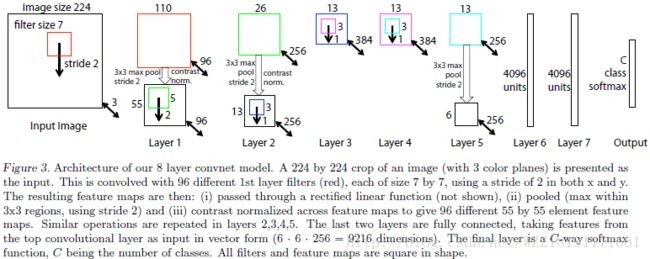
Visualizing and Understanding Convolutional Networks网络:
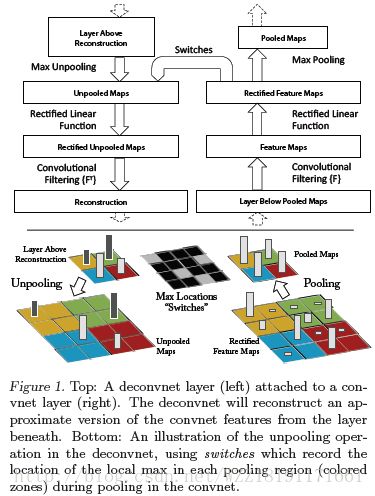
Inverting Visual Representations with Convolutional Networks:

Object Detectors Emerge in Deep Scene CNNs:

Understanding Deep Image Representations by Inverting Them:

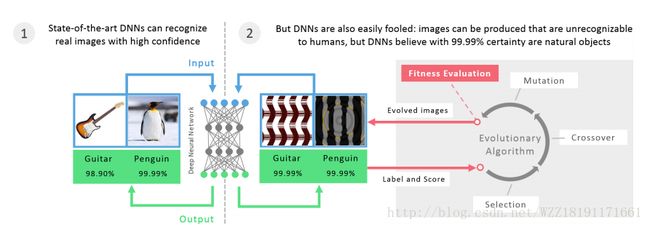
Deep Neural Networks are Easily Fooled:High Confidence Predictions for Unrecognizable Images:
Understanding image representations by measuring their equivariance and equivalence:

超分辨率重建
经典模型:
Learning Iterative Image Reconstruction
http://www.ais.uni-bonn.de/behnke/papers/ijcai01.pdfLearning Iterative Image Reconstruction in the Neural Abstraction Pyramid
http://www.ais.uni-bonn.de/behnke/papers/ijcia01.pdfLearning a Deep Convolutional Network for Image Super-Resolution
http://personal.ie.cuhk.edu.hk/~ccloy/files/eccv_2014_deepresolution.pdfImage Super-Resolution Using Deep Convolutional Networks
https://arxiv.org/pdf/1501.00092.pdfAccurate Image Super-Resolution Using Very Deep Convolutional Networks
https://arxiv.org/pdf/1511.04587.pdfDeeply-Recursive Convolutional Network for Image Super-Resolution
https://arxiv.org/pdf/1511.04491.pdfDeep Networks for Image Super-Resolution with Sparse Prior
http://www.ifp.illinois.edu/~dingliu2/iccv15/iccv15.pdfPerceptual Losses for Real-Time Style Transfer and Super-Resolution
https://arxiv.org/pdf/1603.08155.pdfPhoto-Realistic Single Image Super-Resolution Using a Generative Adversarial Network
https://arxiv.org/pdf/1609.04802v3.pdf
Learning Iterative Image Reconstruction网络:
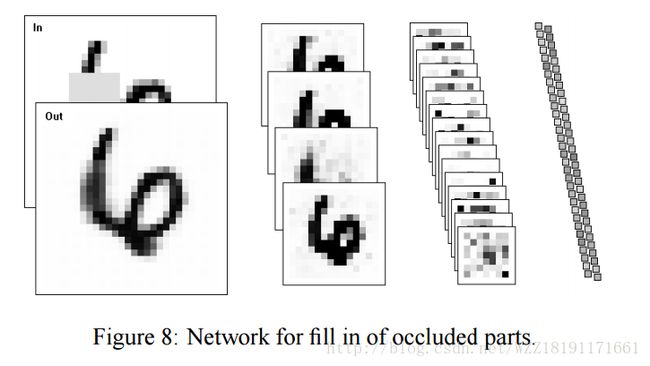
Learning Iterative Image Reconstruction in the Neural Abstraction Pyramid:

Learning a Deep Convolutional Network for Image Super-Resolution:
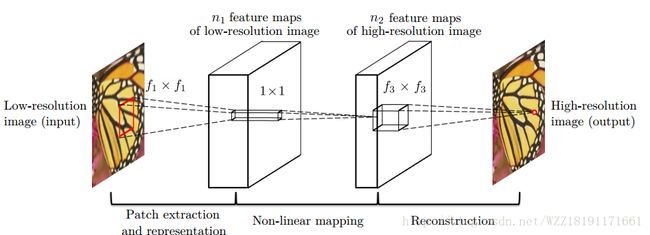
Image Super-Resolution Using Deep Convolutional Networks:
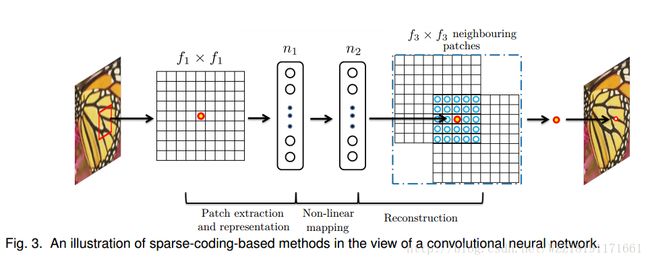
Accurate Image Super-Resolution Using Very Deep Convolutional Networks:
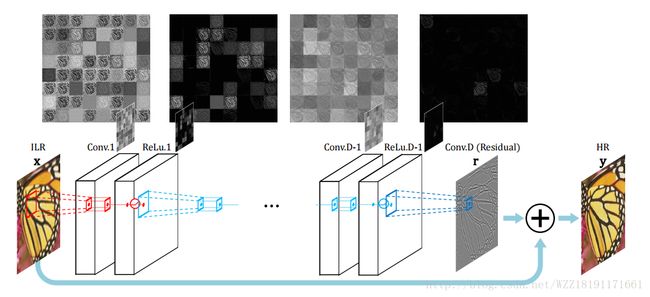
Deeply-Recursive Convolutional Network for Image Super-Resolution:
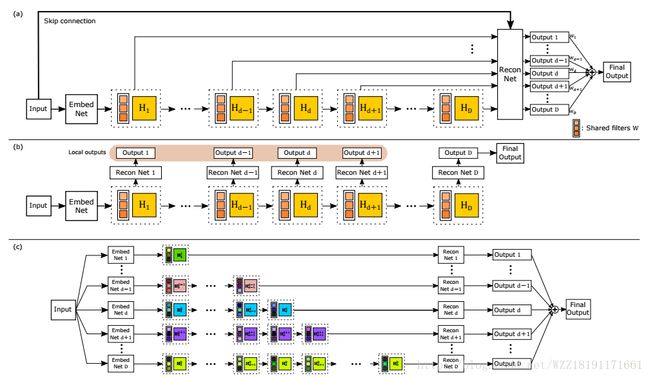
Deep Networks for Image Super-Resolution with Sparse Prior:
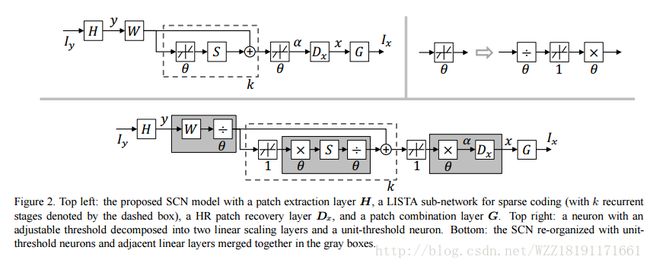
Perceptual Losses for Real-Time Style Transfer and Super-Resolution:
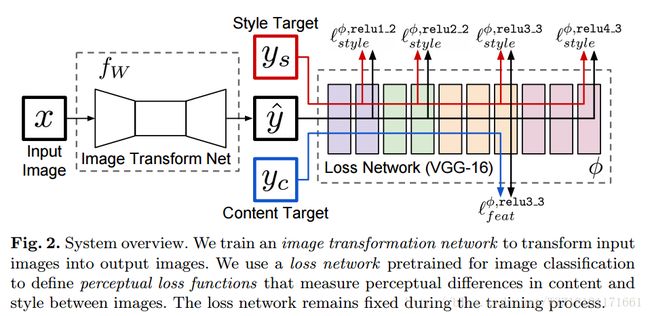
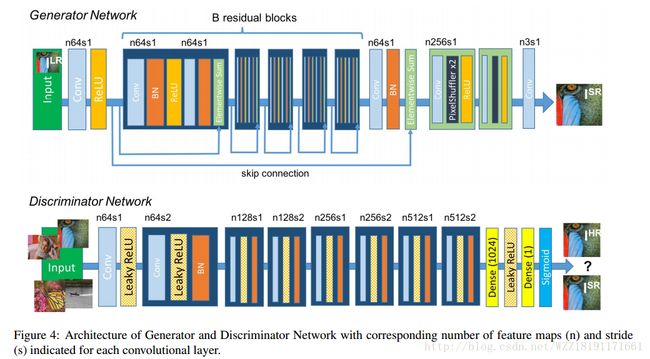
Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network:
图像标定
经典模型:
Explain Images with Multimodal Recurrent Neural Networks
https://arxiv.org/pdf/1410.1090.pdfUnifying Visual-Semantic Embeddings with Multimodal Neural Language Models
https://arxiv.org/pdf/1411.2539.pdfLong-term Recurrent Convolutional Networks for Visual Recognition and Description
https://arxiv.org/pdf/1411.4389.pdfA Neural Image Caption Generator
https://arxiv.org/pdf/1411.4555.pdfDeep Visual-Semantic Alignments for Generating Image Description
http://cs.stanford.edu/people/karpathy/cvpr2015.pdfTranslating Videos to Natural Language Using Deep Recurrent Neural Networks
https://arxiv.org/pdf/1412.4729.pdfLearning a Recurrent Visual Representation for Image Caption Generation
https://arxiv.org/pdf/1411.5654.pdfFrom Captions to Visual Concepts and Back
https://arxiv.org/pdf/1411.4952.pdfShow, Attend, and Tell: Neural Image Caption Generation with Visual Attention
http://www.cs.toronto.edu/~zemel/documents/captionAttn.pdfPhrase-based Image Captioning
https://arxiv.org/pdf/1502.03671.pdfLearning like a Child: Fast Novel Visual Concept Learning from Sentence Descriptions of Images
https://arxiv.org/pdf/1504.06692.pdfExploring Nearest Neighbor Approaches for Image Captioning
https://arxiv.org/pdf/1505.04467.pdfImage Captioning with an Intermediate Attributes Layer
https://arxiv.org/pdf/1506.01144.pdfLearning language through pictures
https://arxiv.org/pdf/1506.03694.pdfDescribing Multimedia Content using Attention-based Encoder-Decoder Networks
https://arxiv.org/pdf/1507.01053.pdfImage Representations and New Domains in Neural Image Captioning
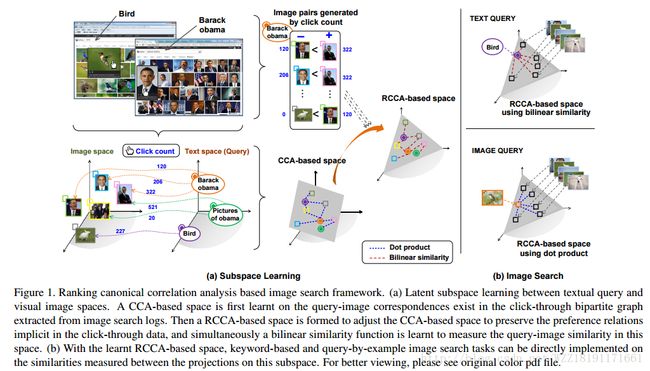
https://arxiv.org/pdf/1508.02091.pdfLearning Query and Image Similarities with Ranking Canonical Correlation Analysis
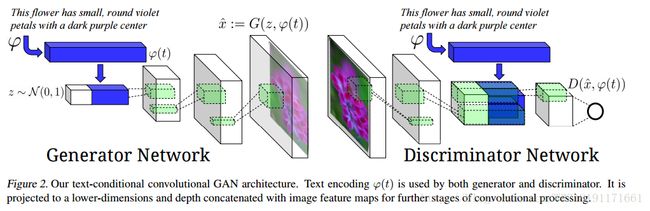
http://www.cv-foundation.org/openaccess/content_iccv_2015/papers/Yao_Learning_Query_and_ICCV_2015_paper.pdfGenerative Adversarial Text to Image Synthesis
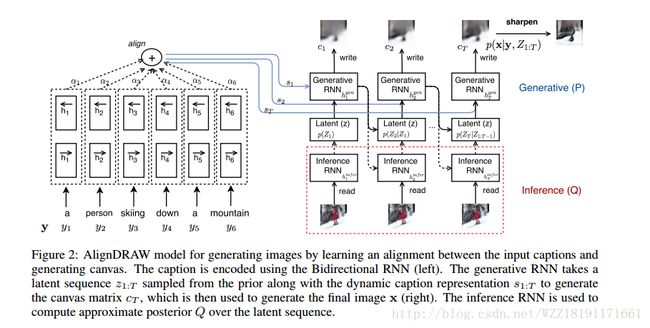
https://arxiv.org/pdf/1605.05396.pdfGENERATING IMAGES FROM CAPTIONS WITH ATTENTION
https://arxiv.org/pdf/1511.02793.pdf
Explain Images with Multimodal Recurrent Neural Networks:
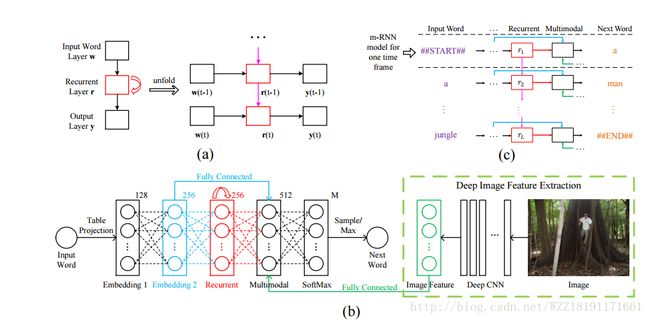
Unifying Visual-Semantic Embeddings with Multimodal Neural Language Models:
Long-term Recurrent Convolutional Networks for Visual Recognition and Description:

A Neural Image Caption Generator:
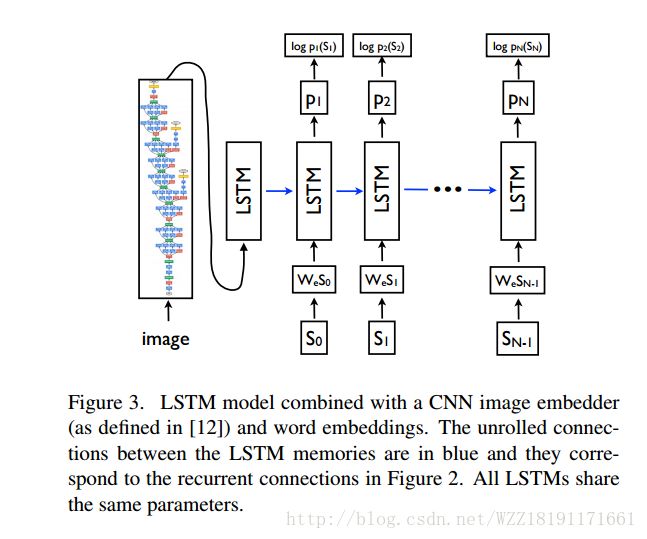
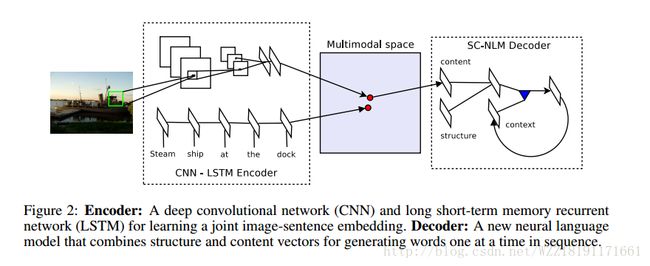
Deep Visual-Semantic Alignments for Generating Image Description:

Translating Videos to Natural Language Using Deep Recurrent Neural Networks:
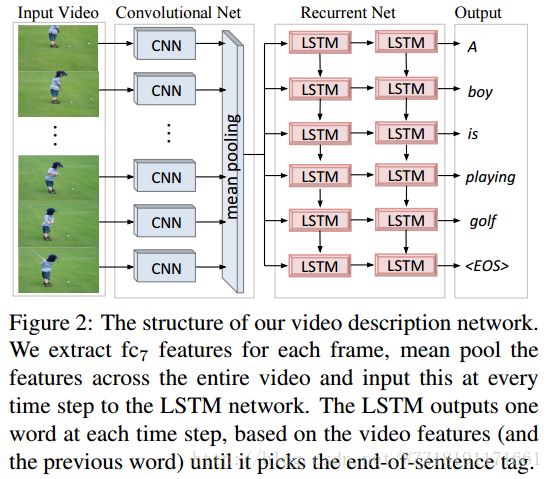
Learning a Recurrent Visual Representation for Image Caption Generation:

From Captions to Visual Concepts and Back:
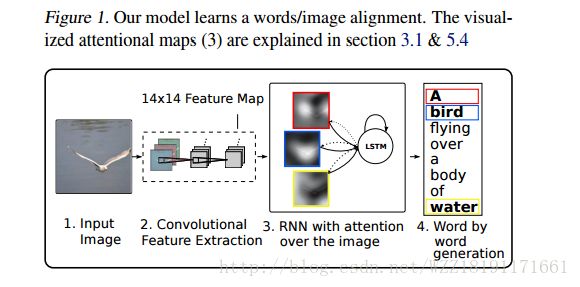
Show, Attend, and Tell: Neural Image Caption Generation with Visual Attention:
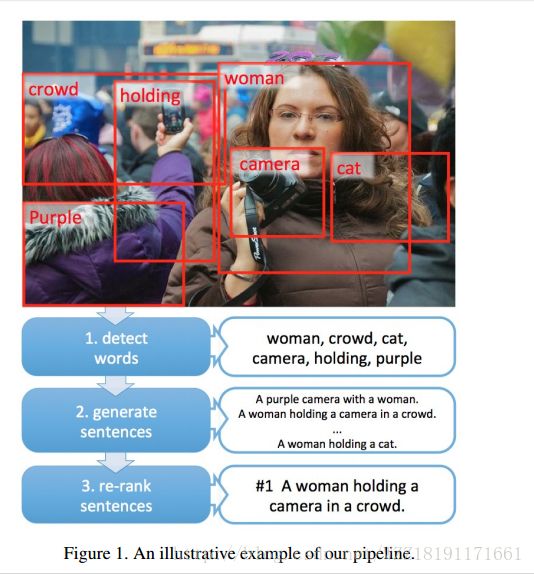
Phrase-based Image Captioning:

Learning like a Child: Fast Novel Visual Concept Learning from Sentence Descriptions of Images:
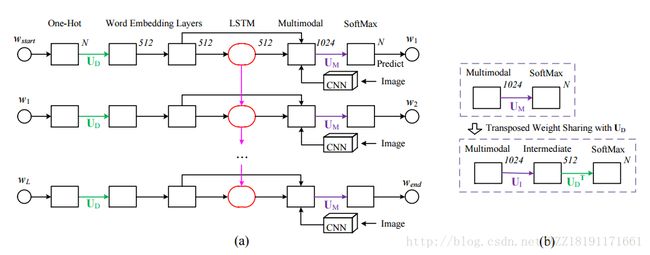
Exploring Nearest Neighbor Approaches for Image Captioning:
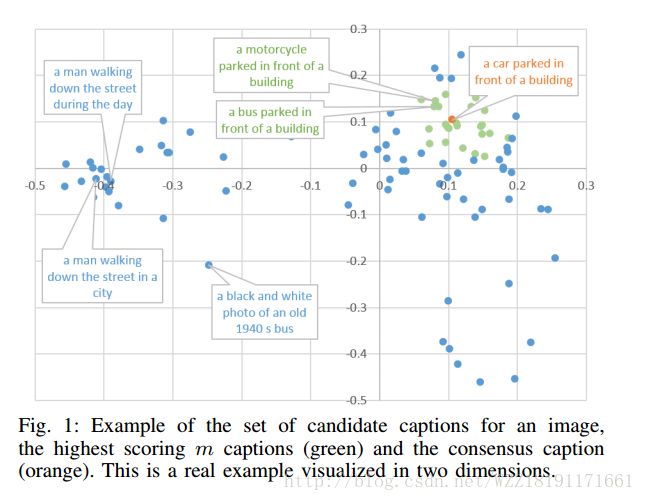
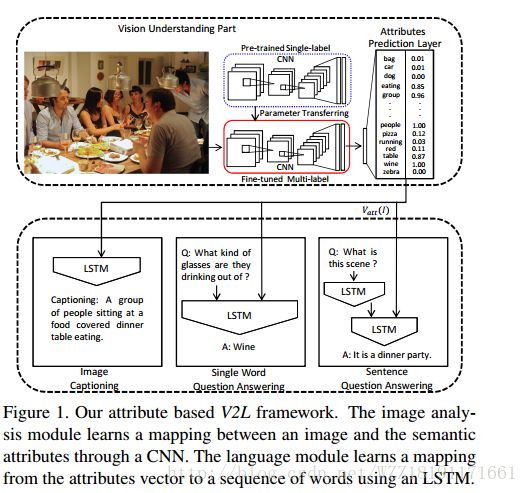
Image Captioning with an Intermediate Attributes Layer:
Learning language through pictures:

Describing Multimedia Content using Attention-based Encoder-Decoder Networks:
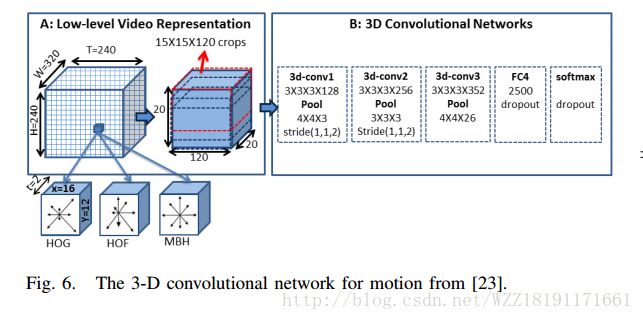
Image Representations and New Domains in Neural Image Captioning:

Learning Query and Image Similarities with Ranking Canonical Correlation Analysis:
Generative Adversarial Text to Image Synthesis:
GENERATING IMAGES FROM CAPTIONS WITH ATTENTION:
视频标注
经典模型:
Long-term Recurrent Convolutional Networks for Visual Recognition and Description
https://arxiv.org/pdf/1411.4389.pdfTranslating Videos to Natural Language Using Deep Recurrent Neural Networks
https://arxiv.org/pdf/1412.4729.pdfJoint Modeling Embedding and Translation to Bridge Video and Language
https://arxiv.org/pdf/1505.01861.pdfSequence to Sequence–Video to Text
https://arxiv.org/pdf/1505.00487.pdfDescribing Videos by Exploiting Temporal Structure
https://arxiv.org/pdf/1502.08029.pdfThe Long-Short Story of Movie Description
https://arxiv.org/pdf/1506.01698.pdfAligning Books and Movies: Towards Story-like Visual Explanations by Watching Movies and Reading Books
https://arxiv.org/pdf/1506.06724.pdfDescribing Multimedia Content using Attention-based Encoder-Decoder Networks
https://arxiv.org/pdf/1507.01053.pdfTemporal Tessellation for Video Annotation and Summarization
https://arxiv.org/pdf/1612.06950.pdfSummarization-based Video Caption via Deep Neural Networks
acm=1492135731_7c7cb5d6bf7455db7f4aa75b341d1a78”>http://delivery.acm.org/10.1145/2810000/2806314/p1191-li.pdf?ip=123.138.79.12&id=2806314&acc=ACTIVE%20SERVICE&key=BF85BBA5741FDC6E%2EB37B3B2DF215A17D%2E4D4702B0C3E38B35%2E4D4702B0C3E38B35&CFID=923677366&CFTOKEN=37844144&acm=1492135731_7c7cb5d6bf7455db7f4aa75b341d1a78Deep Learning for Video Classification and Captioning
https://arxiv.org/pdf/1609.06782.pdf
Long-term Recurrent Convolutional Networks for Visual Recognition and Description:

Translating Videos to Natural Language Using Deep Recurrent Neural Networks:
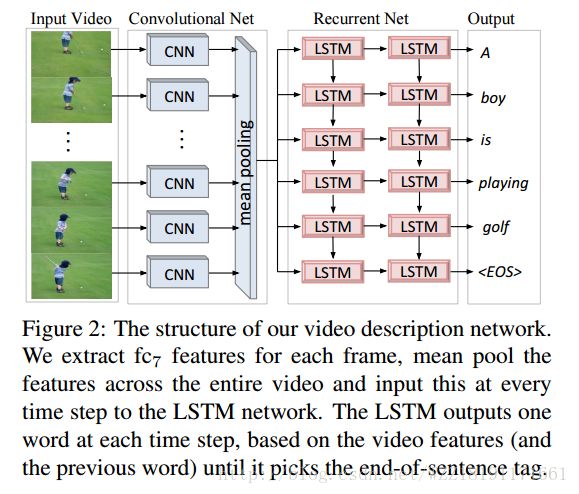
Joint Modeling Embedding and Translation to Bridge Video and Language:

Sequence to Sequence–Video to Text:
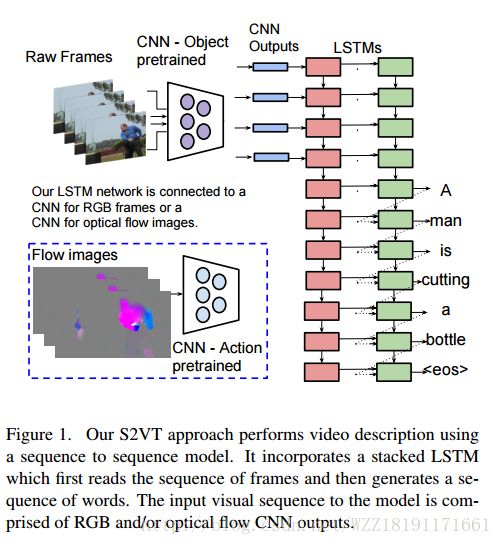
Describing Videos by Exploiting Temporal Structure:
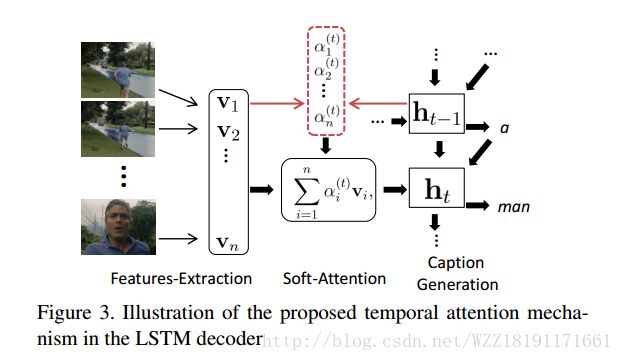
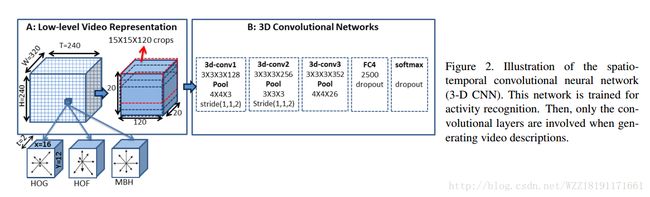
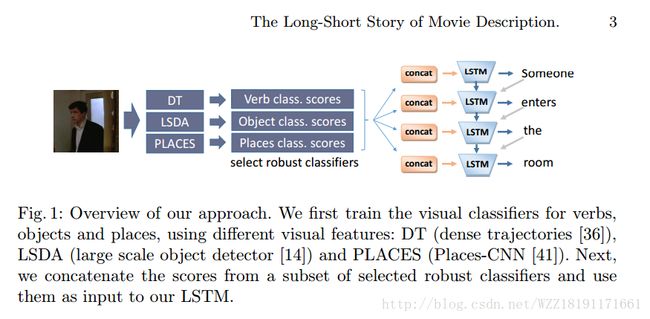
The Long-Short Story of Movie Description:
Aligning Books and Movies: Towards Story-like Visual Explanations by Watching Movies and Reading Books:
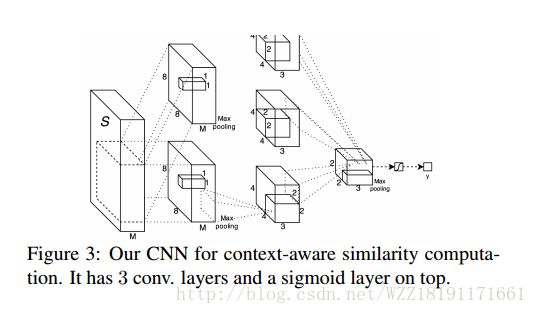
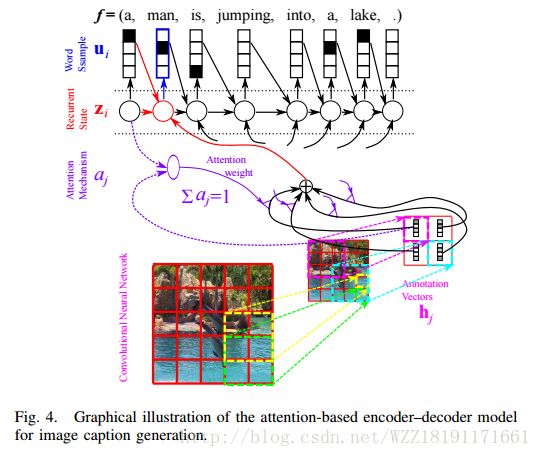
Describing Multimedia Content using Attention-based Encoder-Decoder Networks:
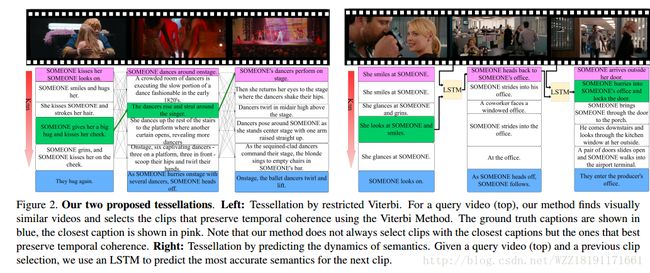
Temporal Tessellation for Video Annotation and Summarization:
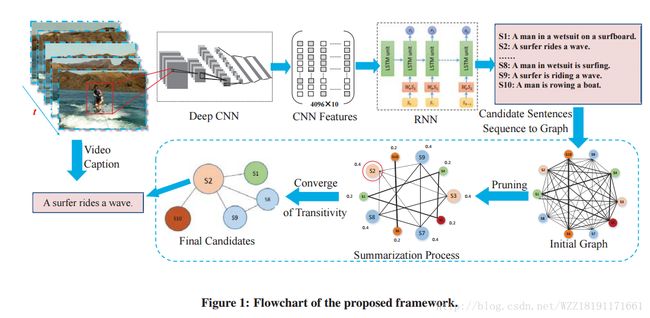
Summarization-based Video Caption via Deep Neural Networks:
Deep Learning for Video Classification and Captioning:

问答系统
经典模型:
VQA: Visual Question Answering
https://arxiv.org/pdf/1505.00468.pdfAsk Your Neurons: A Neural-based Approach to Answering Questions about Images
https://arxiv.org/pdf/1505.01121.pdfImage Question Answering: A Visual Semantic Embedding Model and a New Dataset
https://arxiv.org/pdf/1505.02074.pdfStacked Attention Networks for Image Question Answering
https://arxiv.org/pdf/1511.02274v2.pdfDataset and Methods for Multilingual Image Question Answering
https://arxiv.org/pdf/1505.05612.pdfImage Question Answering using Convolutional Neural Network with Dynamic Parameter Prediction
Dynamic Memory Networks for Visual and Textual Question Answering
https://arxiv.org/pdf/1603.01417v1.pdfMultimodal Residual Learning for Visual QA
https://arxiv.org/pdf/1606.01455.pdfMultimodal Compact Bilinear Pooling for Visual Question Answering and Visual Grounding
https://arxiv.org/pdf/1606.01847.pdfTraining Recurrent Answering Units with Joint Loss Minimization for VQA
https://arxiv.org/pdf/1606.03647.pdfHadamard Product for Low-rank Bilinear Pooling
https://arxiv.org/pdf/1610.04325.pdfQuestion Answering Using Deep Learning
https://cs224d.stanford.edu/reports/StrohMathur.pdf
VQA: Visual Question Answering:
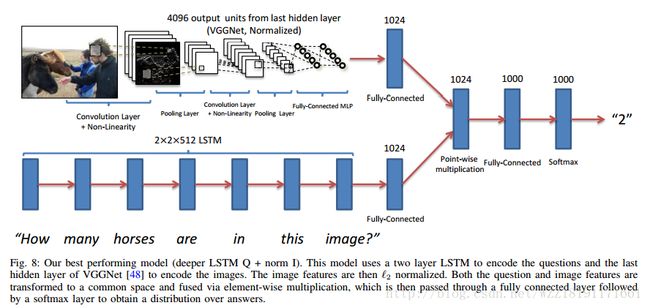
Ask Your Neurons: A Neural-based Approach to Answering Questions about Images:
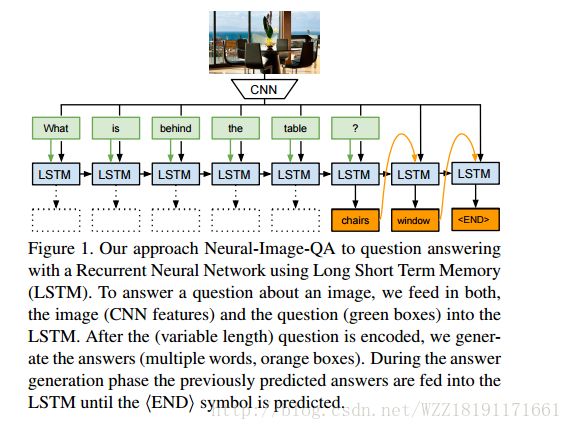
Image Question Answering: A Visual Semantic Embedding Model and a New Dataset:
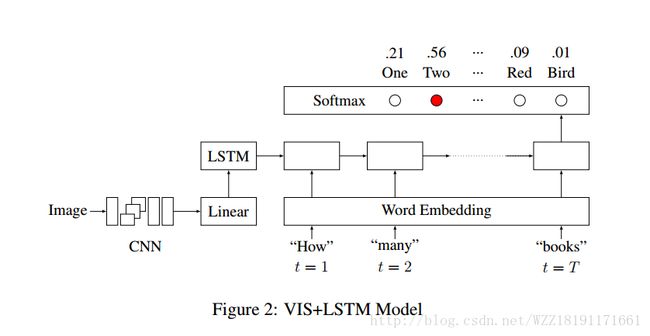
Stacked Attention Networks for Image Question Answering:
Dataset and Methods for Multilingual Image Question Answering:
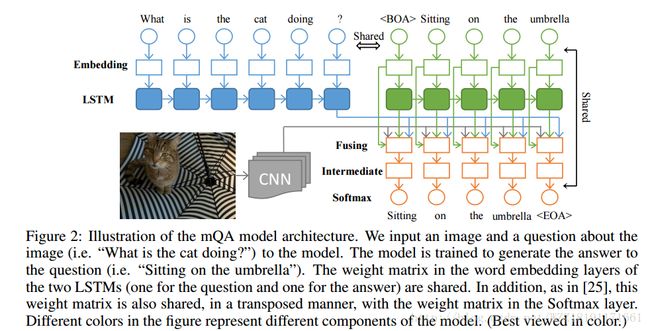
Image Question Answering using Convolutional Neural Network with Dynamic Parameter Prediction:
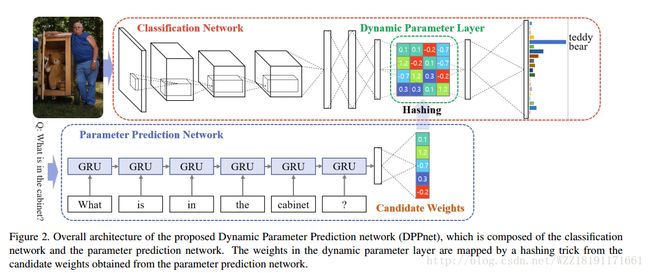
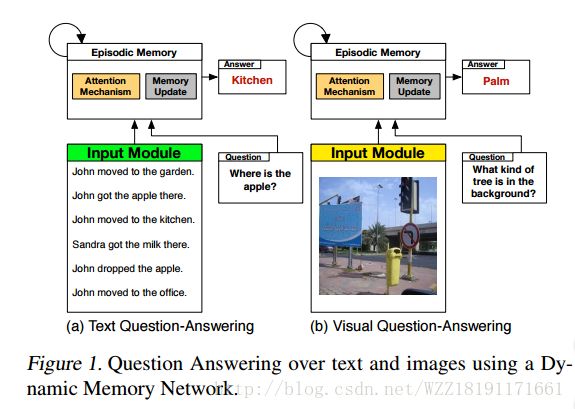
Dynamic Memory Networks for Visual and Textual Question Answering:
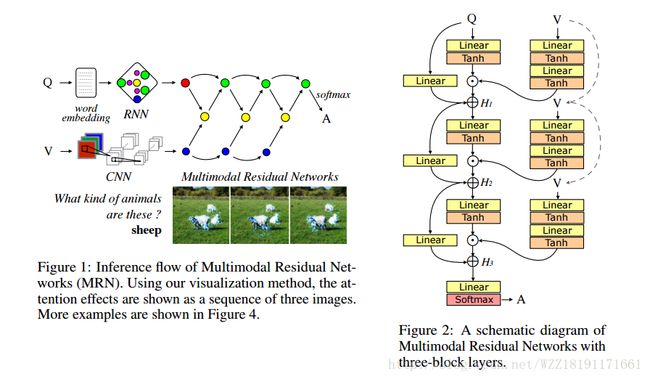
Multimodal Residual Learning for Visual QA:
Multimodal Compact Bilinear Pooling for Visual Question Answering and Visual Grounding:
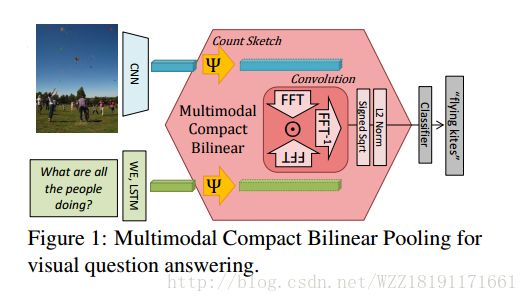
Training Recurrent Answering Units with Joint Loss Minimization for VQA:
Hadamard Product for Low-rank Bilinear Pooling:

Question Answering Using Deep Learning:
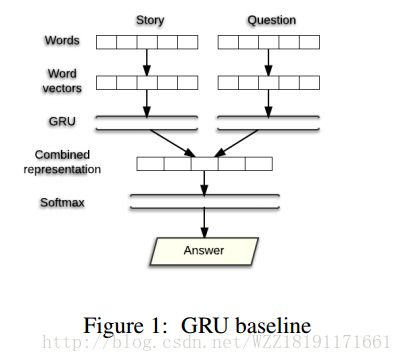
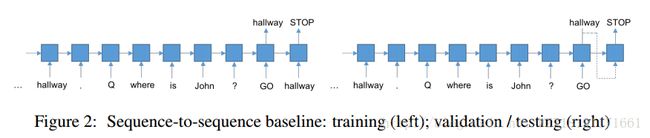
图片生成(CNN、RNN、LSTM、GAN)
经典模型:
Conditional Image Generation with PixelCNN Decoders
https://arxiv.org/pdf/1606.05328v2.pdfLearning to Generate Chairs with Convolutional Neural Networks
http://www.cv-foundation.org/openaccess/content_cvpr_2015/papers/Dosovitskiy_Learning_to_Generate_2015_CVPR_paper.pdfDRAW: A Recurrent Neural Network For Image Generation
https://arxiv.org/pdf/1502.04623v2.pdfGenerative Adversarial Networks
https://arxiv.org/pdf/1406.2661.pdfDeep Generative Image Models using a Laplacian Pyramid of Adversarial Networks
https://arxiv.org/pdf/1506.05751.pdfA note on the evaluation of generative models
https://arxiv.org/pdf/1511.01844.pdfVariationally Auto-Encoded Deep Gaussian Processes
https://arxiv.org/pdf/1511.06455v2.pdfGenerating Images from Captions with Attention
https://arxiv.org/pdf/1511.02793v2.pdfUnsupervised and Semi-supervised Learning with Categorical Generative Adversarial Networks
https://arxiv.org/pdf/1511.06390v1.pdfCensoring Representations with an Adversary
https://arxiv.org/pdf/1511.05897v3.pdfDistributional Smoothing with Virtual Adversarial Training
https://arxiv.org/pdf/1507.00677v8.pdfGenerative Visual Manipulation on the Natural Image Manifold
https://arxiv.org/pdf/1609.03552v2.pdfUnsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks
https://arxiv.org/pdf/1511.06434.pdfWasserstein GAN
https://arxiv.org/pdf/1701.07875.pdfLoss-Sensitive Generative Adversarial Networks on Lipschitz Densities
https://arxiv.org/pdf/1701.06264.pdfConditional Generative Adversarial Nets
https://arxiv.org/pdf/1411.1784.pdfInfoGAN: Interpretable Representation Learning byInformation Maximizing Generative Adversarial Nets
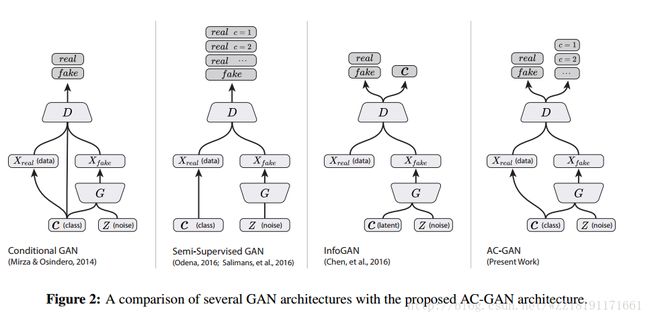
https://arxiv.org/pdf/1606.03657.pdfConditional Image Synthesis With Auxiliary Classifier GANs
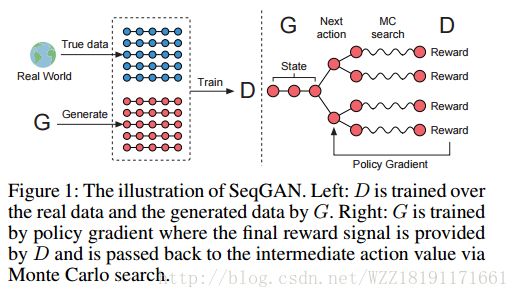
https://arxiv.org/pdf/1610.09585.pdfSeqGAN: Sequence Generative Adversarial Nets with Policy Gradient
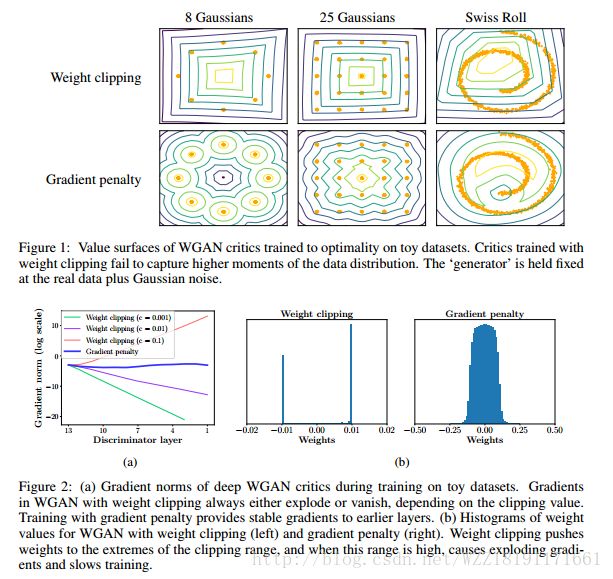
https://arxiv.org/pdf/1609.05473.pdfImproved Training of Wasserstein GANs
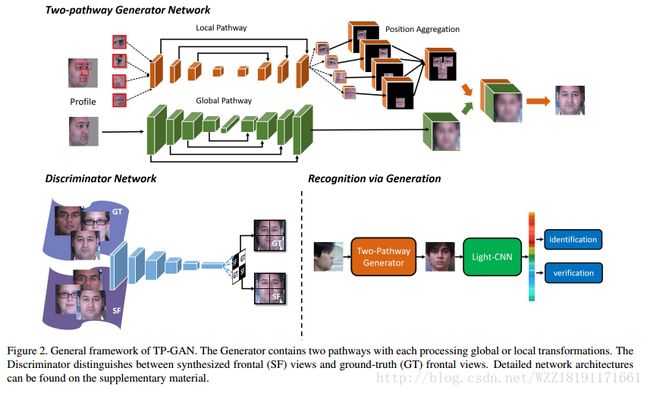
https://arxiv.org/pdf/1704.00028.pdfBeyond Face Rotation: Global and Local Perception GAN for Photorealistic and Identity Preserving Frontal View Synthesis
https://arxiv.org/pdf/1704.04086.pdf
Conditional Image Generation with PixelCNN Decoders:
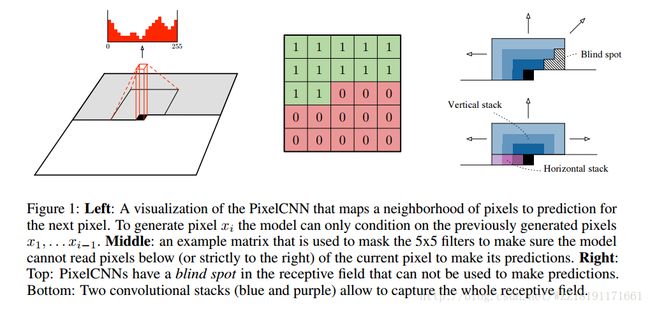
Learning to Generate Chairs with Convolutional Neural Networks:

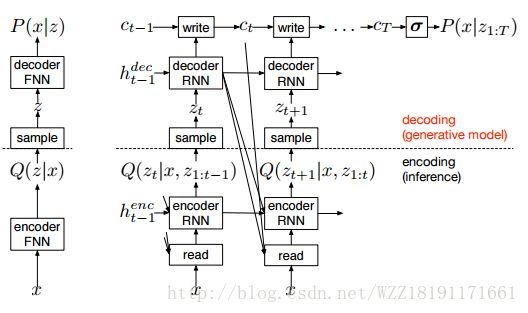
DRAW: A Recurrent Neural Network For Image Generation:

Generative Adversarial Networks:

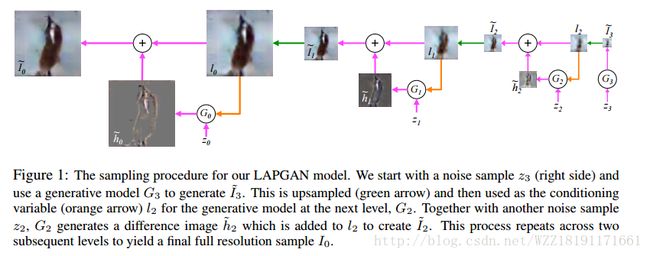
Deep Generative Image Models using a Laplacian Pyramid of Adversarial Networks:
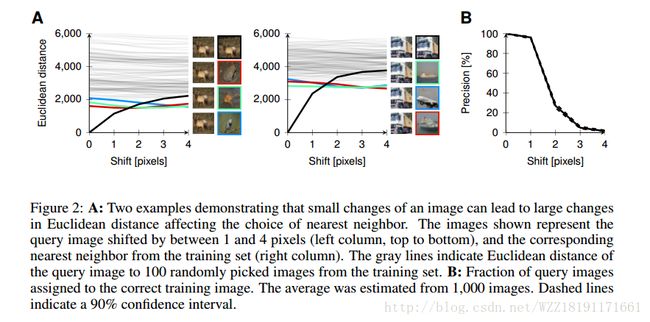
A note on the evaluation of generative models:
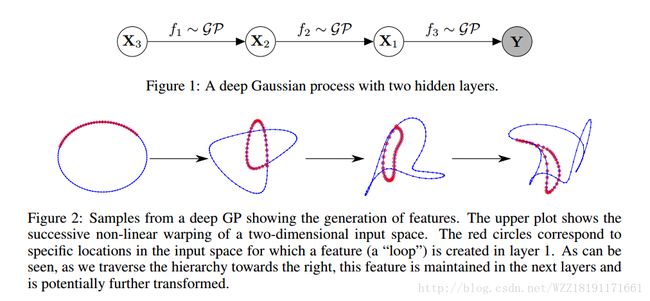
Variationally Auto-Encoded Deep Gaussian Processes:
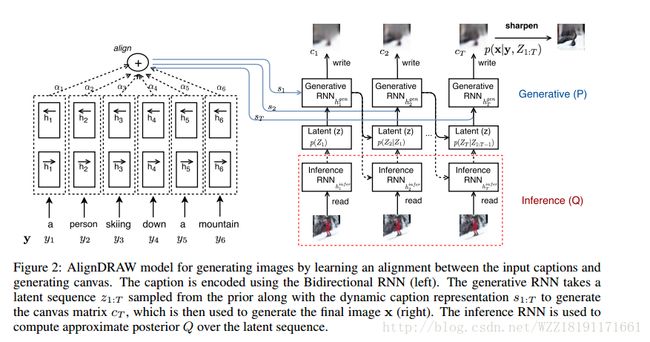
Generating Images from Captions with Attention:
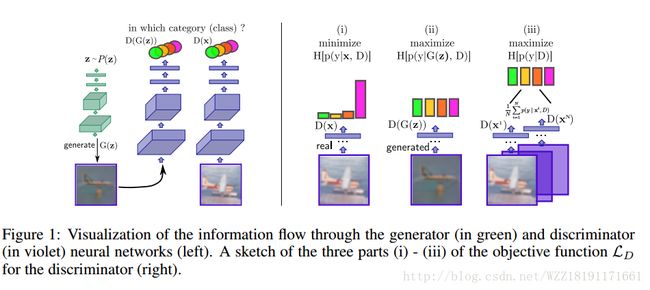
Unsupervised and Semi-supervised Learning with Categorical Generative Adversarial Networks:
Censoring Representations with an Adversary:

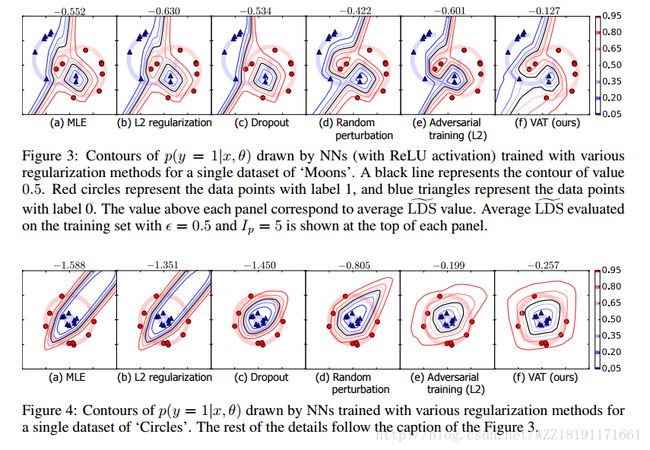
Distributional Smoothing with Virtual Adversarial Training:
Generative Visual Manipulation on the Natural Image Manifold:

Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks:
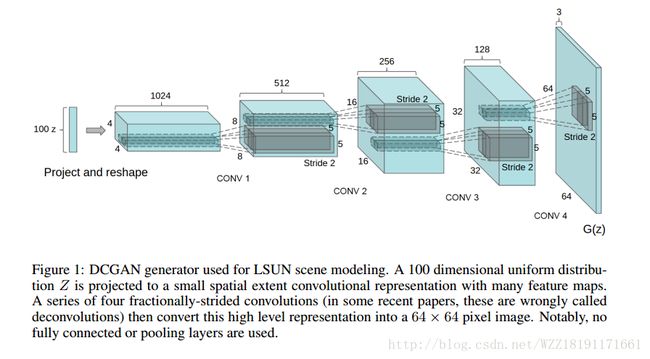
Wasserstein GAN:

Loss-Sensitive Generative Adversarial Networks on Lipschitz Densities:
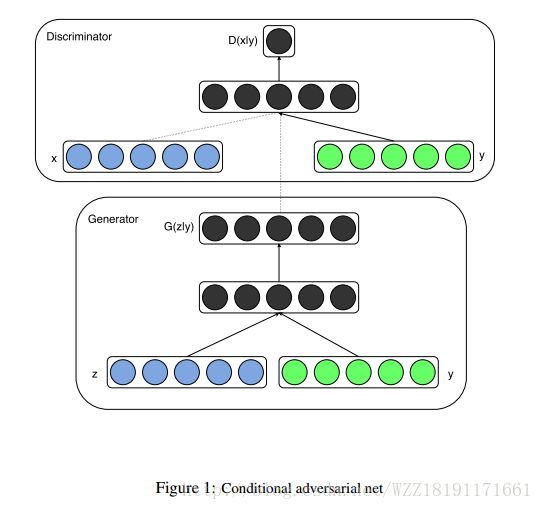
Conditional Generative Adversarial Nets:
InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets:

Conditional Image Synthesis With Auxiliary Classifier GANs:
SeqGAN: Sequence Generative Adversarial Nets with Policy Gradient:
Improved Training of Wasserstein GANs:
Beyond Face Rotation: Global and Local Perception GAN for Photorealistic and Identity Preserving Frontal View Synthesis:
视觉关注性和显著性
经典模型:
Predicting Eye Fixations using Convolutional Neural Networks
http://www.cv-foundation.org/openaccess/content_cvpr_2015/papers/Liu_Predicting_Eye_Fixations_2015_CVPR_paper.pdfLearning a Sequential Search for Landmarks
http://www.cv-foundation.org/openaccess/content_cvpr_2015/papers/Singh_Learning_a_Sequential_2015_CVPR_paper.pdfMultiple Object Recognition with Visual Attention
https://arxiv.org/pdf/1412.7755.pdfRecurrent Models of Visual Attention
http://papers.nips.cc/paper/5542-recurrent-models-of-visual-attention.pdfCapacity Visual Attention Networks
http://easychair.org/publications/download/Capacity_Visual_Attention_NetworksFully Convolutional Attention Networks for Fine-Grained Recognition
https://arxiv.org/pdf/1603.06765.pdf
Predicting Eye Fixations using Convolutional Neural Networks:
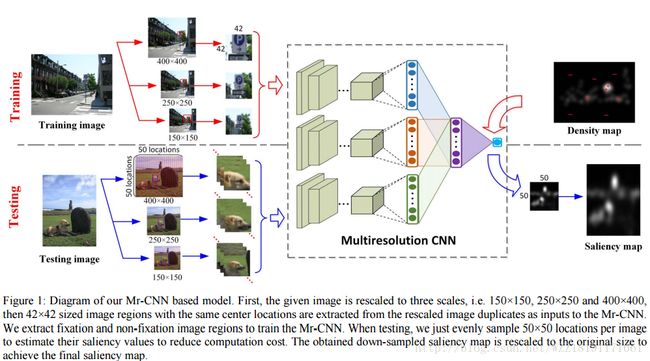
Learning a Sequential Search for Landmarks:

Multiple Object Recognition with Visual Attention:
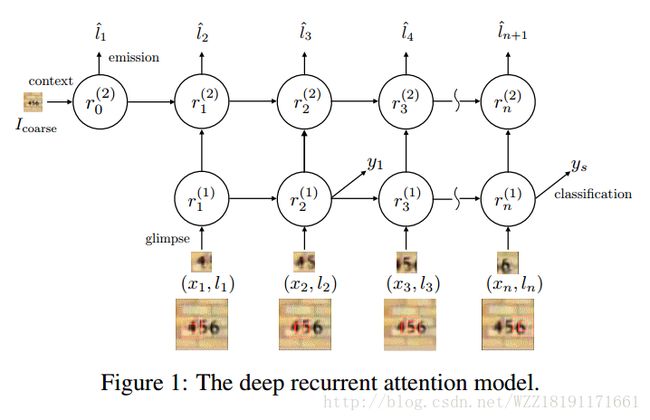
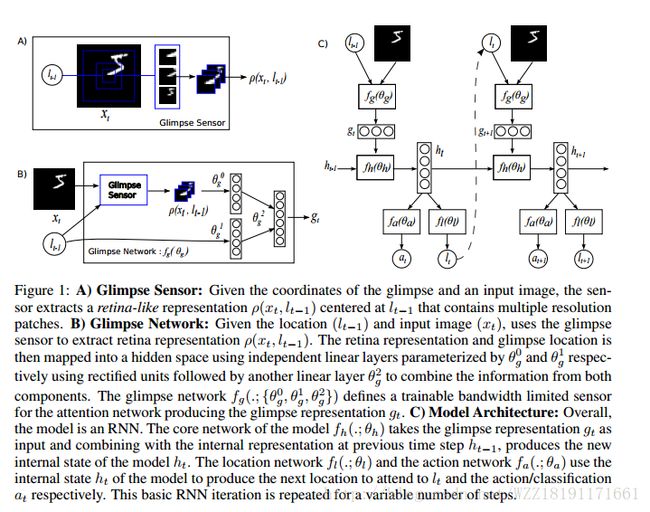
Recurrent Models of Visual Attention:
Capacity Visual Attention Networks:

Fully Convolutional Attention Networks for Fine-Grained Recognition:
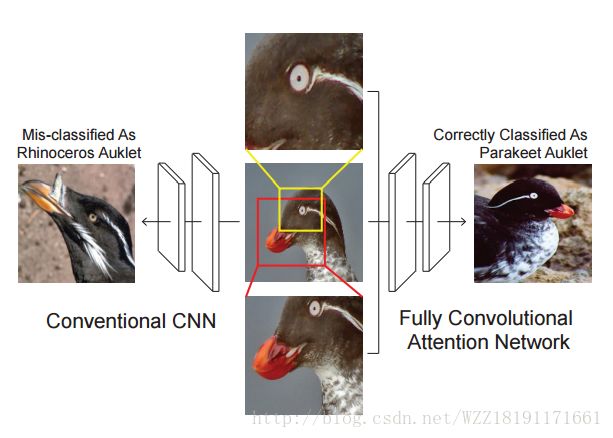
特征检测与匹配(块)
经典模型:
TILDE: A Temporally Invariant Learned DEtector
https://arxiv.org/pdf/1411.4568.pdfMatchNet: Unifying Feature and Metric Learning for Patch-Based Matching
https://pdfs.semanticscholar.org/81b9/24da33b9500a2477532fd53f01df00113972.pdfDiscriminative Learning of Deep Convolutional Feature Point Descriptors
http://cvlabwww.epfl.ch/~trulls/pdf/iccv-2015-deepdesc.pdfLearning to Assign Orientations to Feature Points
https://arxiv.org/pdf/1511.04273.pdfPN-Net: Conjoined Triple Deep Network for Learning Local Image Descriptors
https://arxiv.org/pdf/1601.05030.pdfMulti-scale Pyramid Pooling for Deep Convolutional Representation
http://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=7301274Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
https://arxiv.org/pdf/1406.4729.pdfLearning to Compare Image Patches via Convolutional Neural Networks
https://arxiv.org/pdf/1504.03641.pdfPixelNet: Representation of the pixels, by the pixels, and for the pixels
http://www.cs.cmu.edu/~aayushb/pixelNet/pixelnet.pdfLIFT: Learned Invariant Feature Transform
https://arxiv.org/pdf/1603.09114.pdf
TILDE: A Temporally Invariant Learned DEtector:

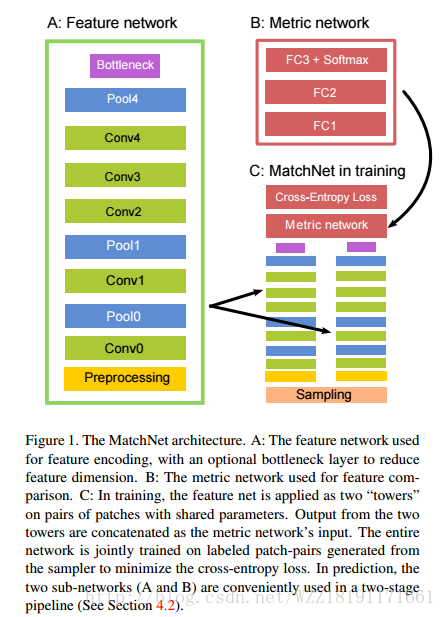
MatchNet: Unifying Feature and Metric Learning for Patch-Based Matching:
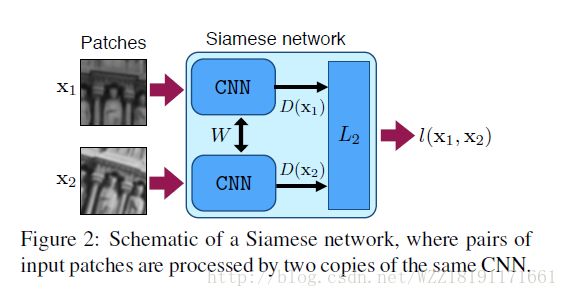
Discriminative Learning of Deep Convolutional Feature Point Descriptors:

Learning to Assign Orientations to Feature Points:

PN-Net: Conjoined Triple Deep Network for Learning Local Image Descriptors:

Multi-scale Pyramid Pooling for Deep Convolutional Representation:

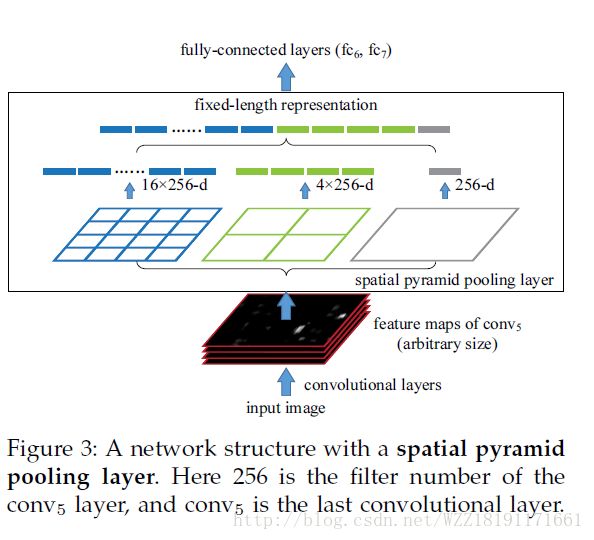
Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition:

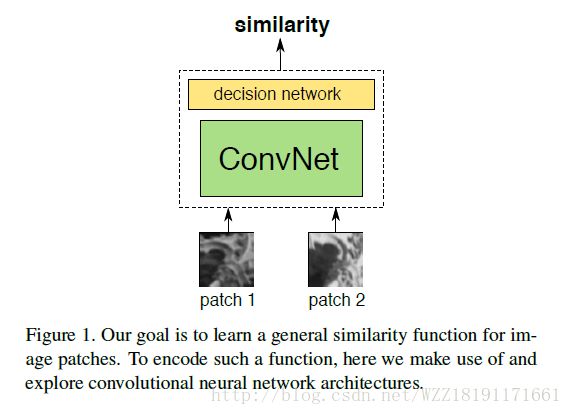
Learning to Compare Image Patches via Convolutional Neural Networks:
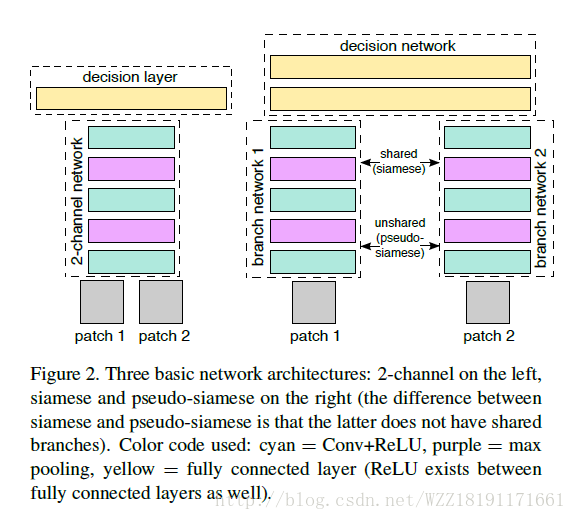
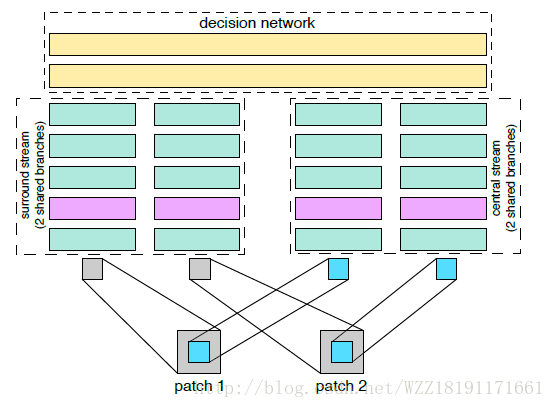
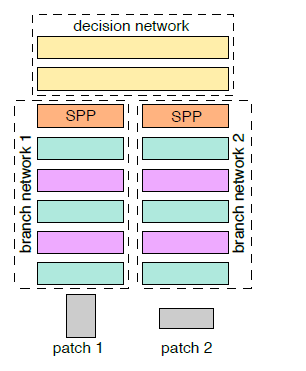
PixelNet: Representation of the pixels, by the pixels, and for the pixels:


LIFT: Learned Invariant Feature Transform:
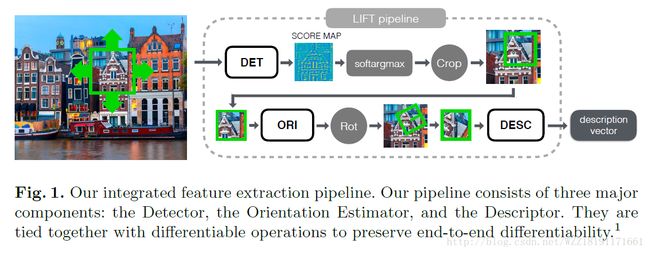
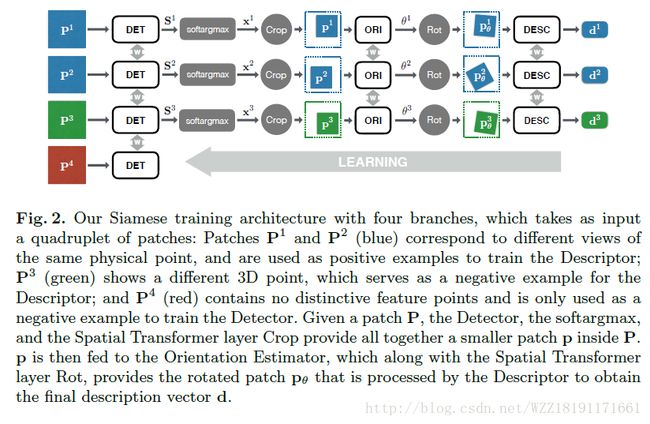
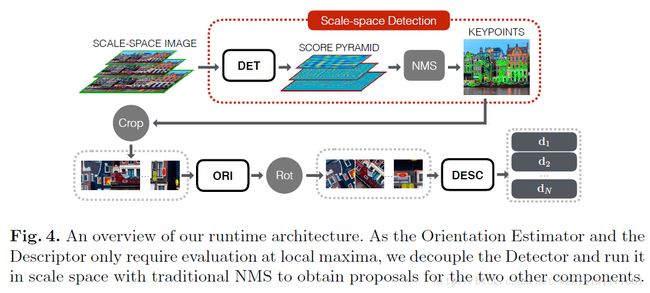
人脸识别
经典模型:
Learning Hierarchical Representations for Face Verification with Convolutional Deep Belief Networks
http://vis-www.cs.umass.edu/papers/HuangCVPR12.pdfDeep Convolutional Network Cascade for Facial Point Detection
http://mmlab.ie.cuhk.edu.hk/archive/CNN/data/CNN_FacePoint.pdfDeep Nonlinear Metric Learning with Independent Subspace Analysis for Face Verification
acm=1492152722_04e9cce5378080a18ec7e700dfb4cd28”>http://delivery.acm.org/10.1145/2400000/2396303/p749-cai.pdf?ip=123.138.79.12&id=2396303&acc=ACTIVE%20SERVICE&key=BF85BBA5741FDC6E%2EB37B3B2DF215A17D%2E4D4702B0C3E38B35%2E4D4702B0C3E38B35&CFID=923677366&CFTOKEN=37844144&acm=1492152722_04e9cce5378080a18ec7e700dfb4cd28DeepFace: Closing the Gap to Human-Level Performance in Face Verification
https://www.cs.toronto.edu/~ranzato/publications/taigman_cvpr14.pdfDeep learning face representation by joint identification-verification
https://arxiv.org/pdf/1406.4773.pdfDeep learning face representation from predicting 10,000 classes
http://mmlab.ie.cuhk.edu.hk/pdf/YiSun_CVPR14.pdfDeeply learned face representations are sparse, selective, and robust
https://arxiv.org/pdf/1412.1265.pdfDeepid3: Face recognition with very deep neural networks
https://arxiv.org/pdf/1502.00873.pdfFaceNet: A Unified Embedding for Face Recognition and Clustering
https://arxiv.org/pdf/1503.03832.pdfFunnel-Structured Cascade for Multi-View Face Detection with Alignment-Awareness
https://arxiv.org/pdf/1609.07304.pdfLarge-pose Face Alignment via CNN-based Dense 3D Model Fitting
http://www.cv-foundation.org/openaccess/content_cvpr_2016/papers/Jourabloo_Large-Pose_Face_Alignment_CVPR_2016_paper.pdfUnconstrained 3D face reconstruction
http://cvlab.cse.msu.edu/pdfs/Roth_Tong_Liu_CVPR2015.pdfAdaptive contour fitting for pose-invariant 3D face shape reconstruction
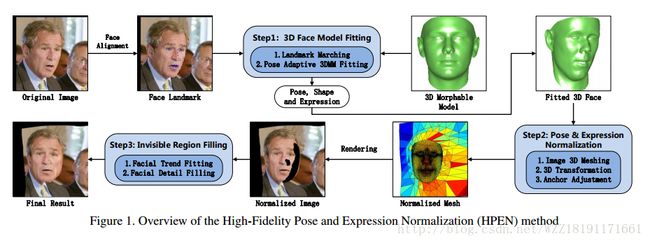
http://akme-a2.iosb.fraunhofer.de/ETGS15p/2015_Adaptive%20contour%20fitting%20for%20pose-invariant%203D%20face%20shape%20reconstruction.pdfHigh-fidelity pose and expression normalization for face recognition in the wild
http://www.cbsr.ia.ac.cn/users/xiangyuzhu/papers/CVPR2015_High-Fidelity.pdfAdaptive 3D face reconstruction from unconstrained photo collections
http://cvlab.cse.msu.edu/pdfs/Roth_Tong_Liu_CVPR16.pdfDense 3D face alignment from 2d videos in real-time
http://ieeexplore.ieee.org/stamp/stamp.jsp arnumber=7163142Robust facial landmark detection under significant head poses and occlusion
http://www.cv-foundation.org/openaccess/content_iccv_2015/papers/Wu_Robust_Facial_Landmark_ICCV_2015_paper.pdfA convolutional neural network cascade for face detection
http://users.eecs.northwestern.edu/~xsh835/assets/cvpr2015_cascnn.pdfDeep Face Recognition Using Deep Convolutional Neural
Network
http://aiehive.com/deep-face-recognition-using-deep-convolution-neural-network/Multi-view Face Detection Using Deep Convolutional Neural Networks
acm=1492157015_8ffa84e6632810ea05ff005794fed8d5”>http://delivery.acm.org/10.1145/2750000/2749408/p643-farfade.pdf?ip=123.138.79.12&id=2749408&acc=ACTIVE%20SERVICE&key=BF85BBA5741FDC6E%2EB37B3B2DF215A17D%2E4D4702B0C3E38B35%2E4D4702B0C3E38B35&CFID=923677366&CFTOKEN=37844144&acm=1492157015_8ffa84e6632810ea05ff005794fed8d5HyperFace: A Deep Multi-task Learning Framework for Face Detection, Landmark Localization, Pose Estimation, and Gender Recognition
https://arxiv.org/pdf/1603.01249.pdfWider face: A face detectionbenchmark
http://mmlab.ie.cuhk.edu.hk/projects/WIDERFace/support/paper.pdfJoint training of cascaded cnn for face detection
http://www.cv-foundation.org/openaccess/content_cvpr_2016/papers/Qin_Joint_Training_of_CVPR_2016_paper.pdfFace detection with end-to-end integration of a convnet and a 3d model
https://arxiv.org/pdf/1606.00850.pdfFace Detection using Deep Learning: An Improved Faster RCNN Approach
https://arxiv.org/pdf/1701.08289.pdf
新旧方法对比:
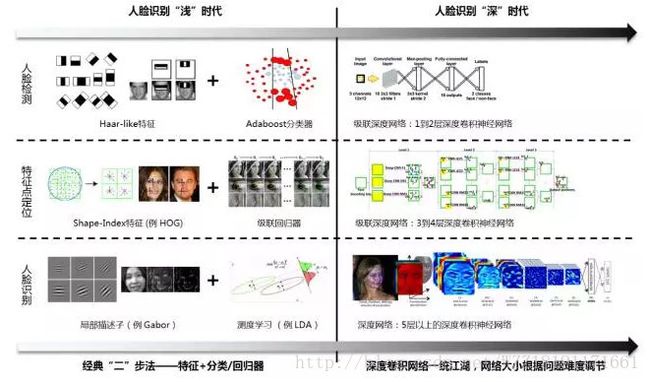
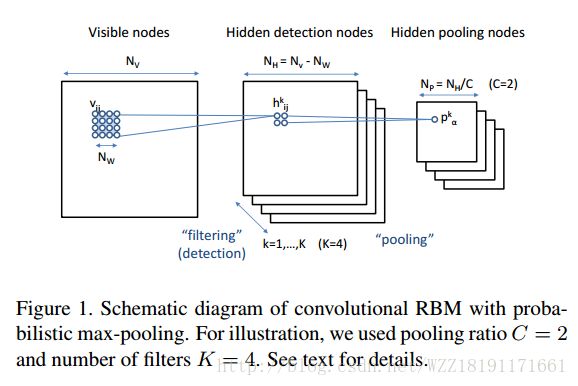
Learning Hierarchical Representations for Face Verification with Convolutional Deep Belief Networks:
Deep Convolutional Network Cascade for Facial Point Detection:
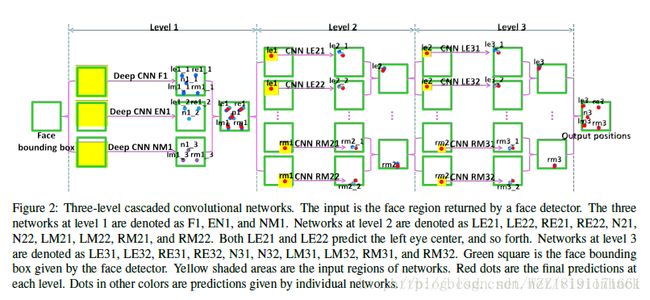
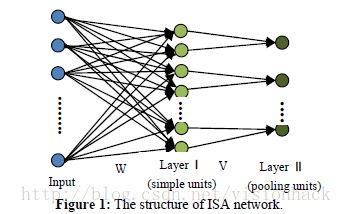
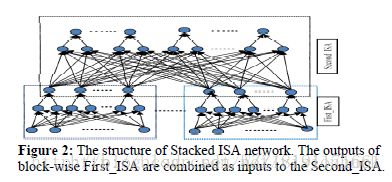
Deep Nonlinear Metric Learning with Independent Subspace Analysis for Face Verification:
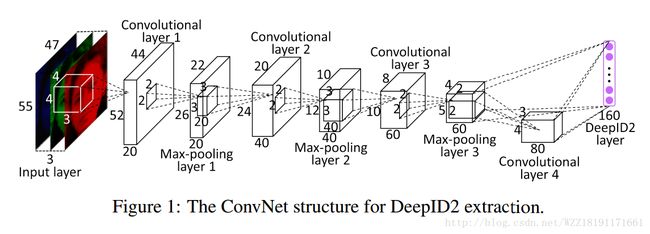
DeepFace: Closing the Gap to Human-Level Performance in Face Verification:

Deep learning face representation by joint identification-verification:
Deep learning face representation from predicting 10,000 classes:
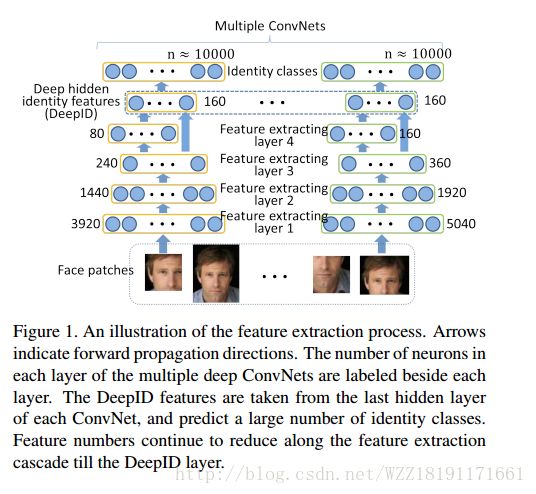
Deeply learned face representations are sparse, selective, and robust:
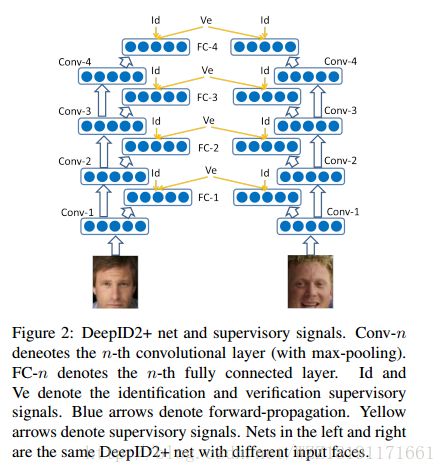
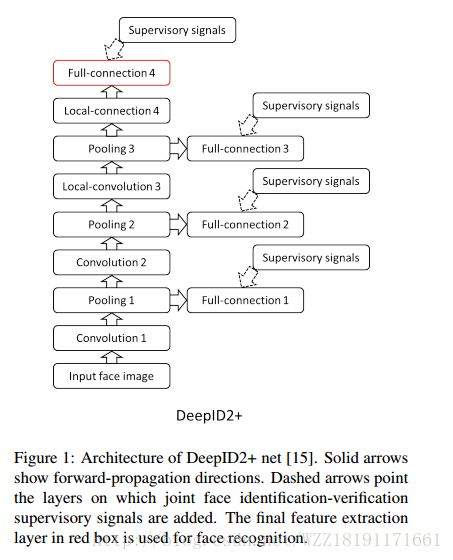
Deepid3: Face recognition with very deep neural networks:
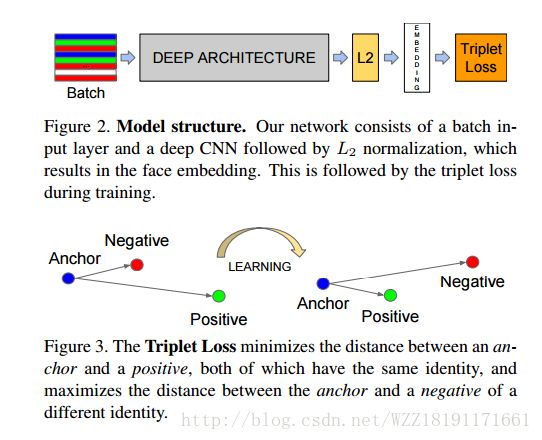
FaceNet: A Unified Embedding for Face Recognition and Clustering:
Funnel-Structured Cascade for Multi-View Face Detection with Alignment-Awareness:
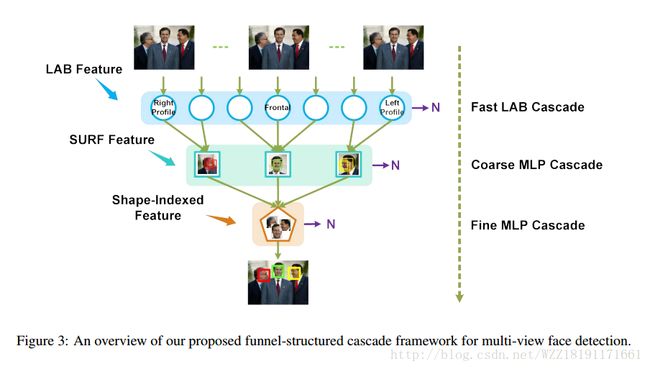
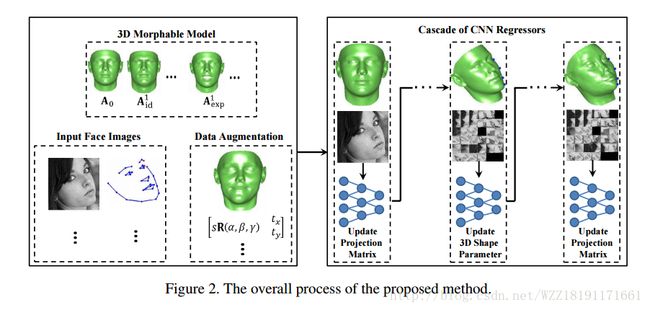
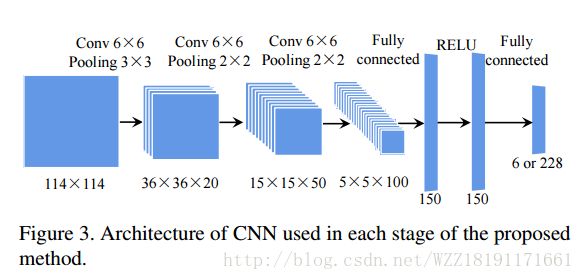
Large-pose Face Alignment via CNN-based Dense 3D Model Fitting:
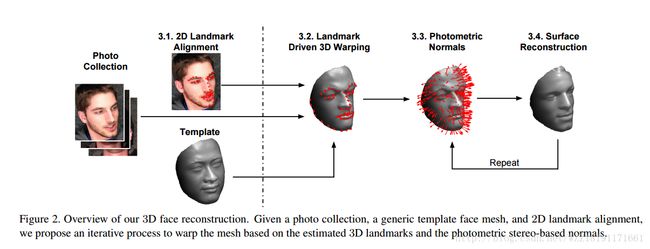
Unconstrained 3D face reconstruction:
Adaptive contour fitting for pose-invariant 3D face shape reconstruction:
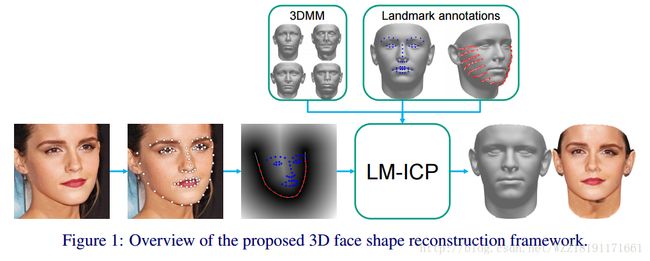
High-fidelity pose and expression normalization for face recognition in the wild:
Adaptive 3D face reconstruction from unconstrained photo collections:

Regressing a 3D face shape from a single image:
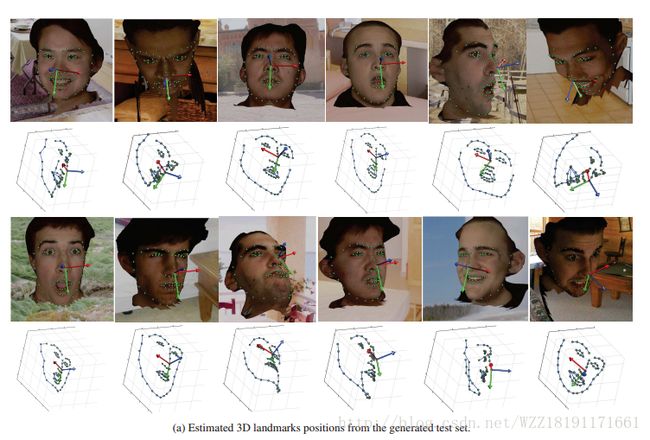
Dense 3D face alignment from 2d videos in real-time:

Robust facial landmark detection under significant head poses and occlusion:

A convolutional neural network cascade for face detection:

Deep Face Recognition Using Deep Convolutional Neural
Network:

Multi-view Face Detection Using Deep Convolutional Neural Networks:

HyperFace: A Deep Multi-task Learning Framework for Face Detection, Landmark Localization, Pose Estimation, and Gender
Recognition:

Wider face: A face detectionbenchmark

Joint training of cascaded cnn for face detection::
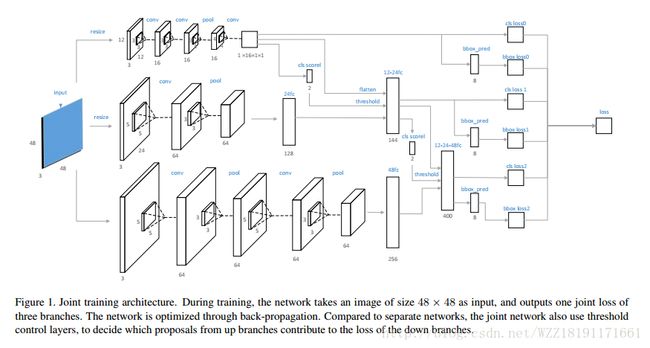
Face detection with end-to-end integration of a convnet and a 3d model:
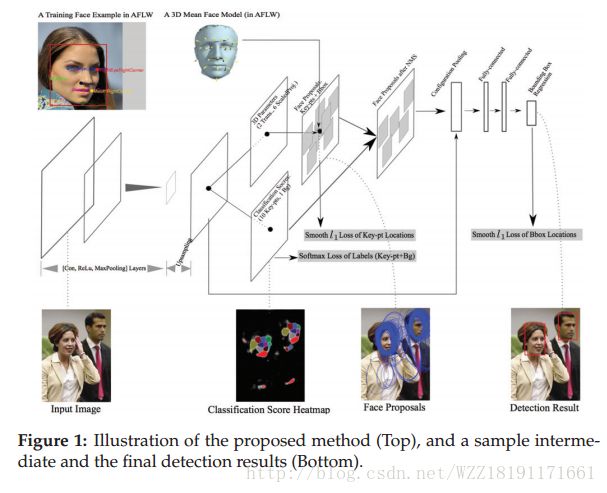
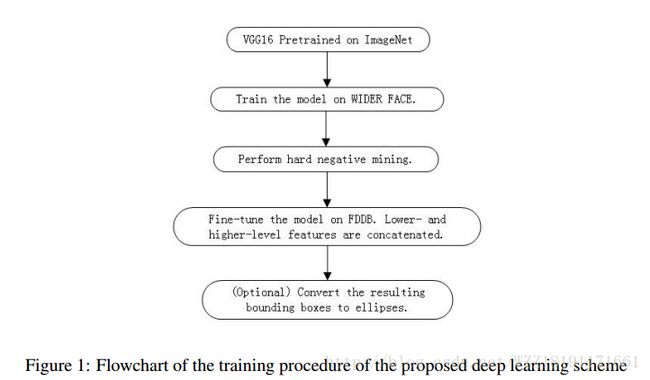
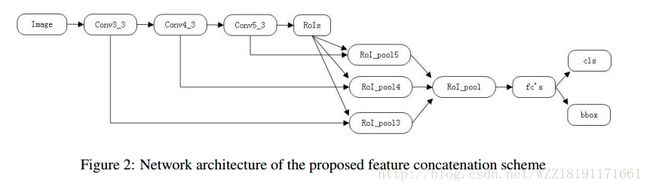
Face Detection using Deep Learning: An Improved Faster RCNN Approach:
3D重建
经典模型:
3D ShapeNets: A Deep Representation for Volumetric Shapes
https://people.csail.mit.edu/khosla/papers/cvpr2015_wu.pdf3D-R2N2: A Unified Approach for Single and Multi-view 3D Object Reconstruction
https://arxiv.org/pdf/1604.00449.pdfLearning to generate chairs with convolutional neural networks
https://arxiv.org/pdf/1411.5928.pdfCategory-specific object reconstruction from a single image
http://people.eecs.berkeley.edu/~akar/categoryshapes.pdfEnriching Object Detection with 2D-3D Registration and Continuous Viewpoint Estimation
http://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=7298866ShapeNet: An Information-Rich 3D Model Repository
https://arxiv.org/pdf/1512.03012.pdf3D reconstruction of synapses with deep learning based on EM Images
http://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=7558866Analysis and synthesis of 3d shape families via deep-learned generative models of surfaces
https://arxiv.org/pdf/1605.06240.pdfUnsupervised Learning of 3D Structure from Images
https://arxiv.org/pdf/1607.00662.pdfDeep learning 3d shape surfaces using geometry images
http://download.springer.com/static/pdf/605/chp%253A10.1007%252F978-3-319-46466-4_14.pdf?originUrl=http%3A%2F%2Flink.springer.com%2Fchapter%2F10.1007%2F978-3-319-46466-4_14&token2=exp=1492181498~acl=%2Fstatic%2Fpdf%2F605%2Fchp%25253A10.1007%25252F978-3-319-46466-4_14.pdf%3ForiginUrl%3Dhttp%253A%252F%252Flink.springer.com%252Fchapter%252F10.1007%252F978-3-319-46466-4_14*~hmac=b772943d8cd5f914e7bc84a30ddfdf0ef87991bee1d52717cb4930e3eccb0e63FPNN: Field Probing Neural Networks for 3D Data
https://arxiv.org/pdf/1605.06240.pdfRender for CNN: Viewpoint Estimation in Images Using CNNs Trained with Rendered 3D Model Views
https://arxiv.org/pdf/1505.05641.pdfLearning a probabilistic latent space of object shapes via 3d generative-adversarial modeling
https://arxiv.org/pdf/1610.07584.pdfSurfNet: Generating 3D shape surfaces using deep residual networks
https://arxiv.org/pdf/1703.04079.pdf
3D ShapeNets: A Deep Representation for Volumetric Shapes:
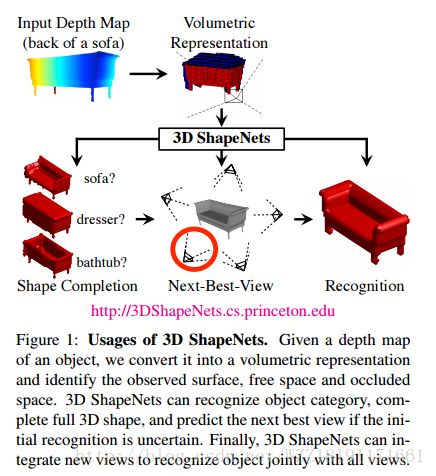
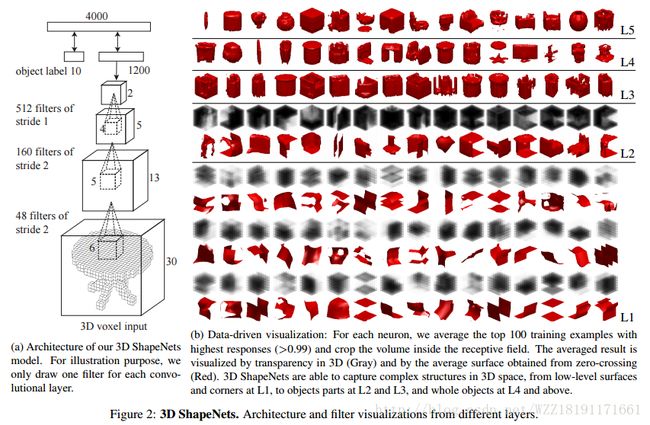
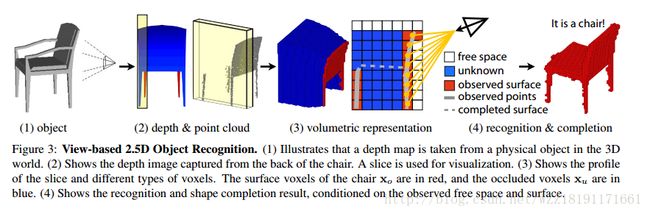
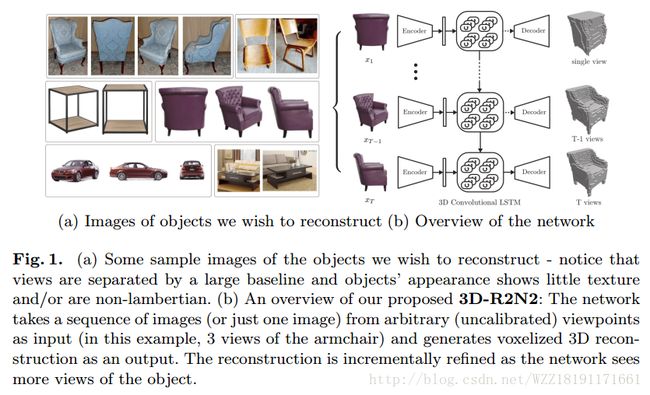
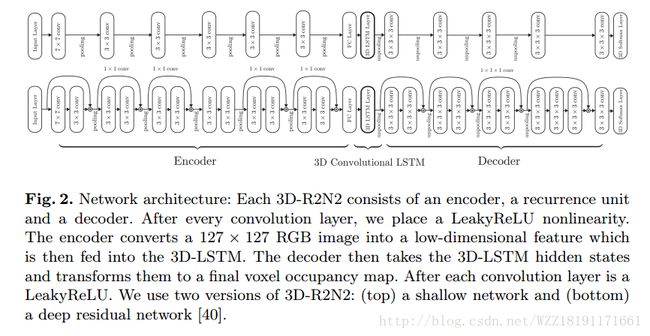
3D-R2N2: A Unified Approach for Single and Multi-view 3D Object Reconstruction:
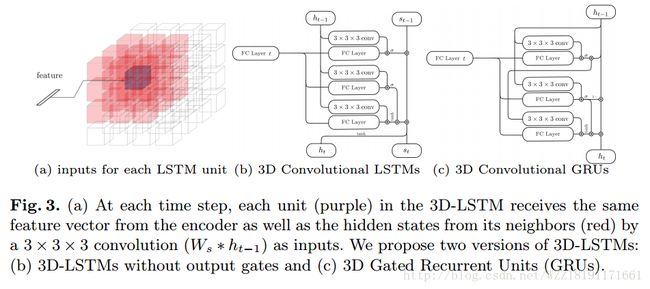
Learning to generate chairs with convolutional neural networks:
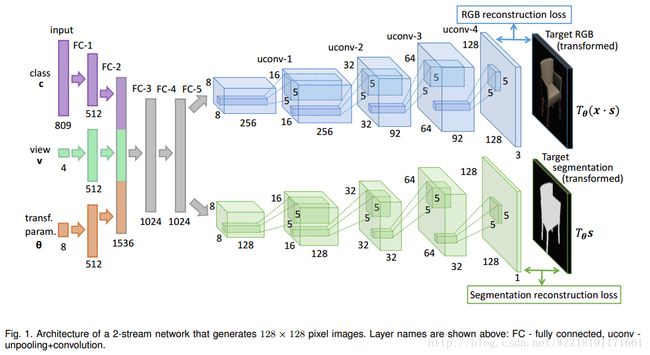

Category-specific object reconstruction from a single image:


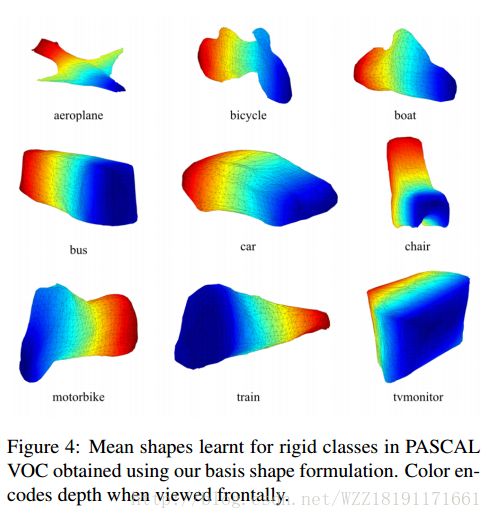
Enriching Object Detection with 2D-3D Registration and Continuous Viewpoint Estimation:
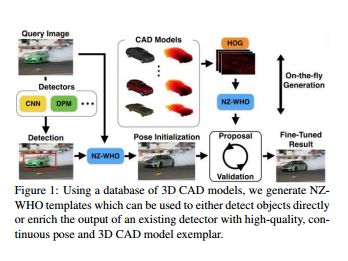
Completing 3d object shape from one depth image:

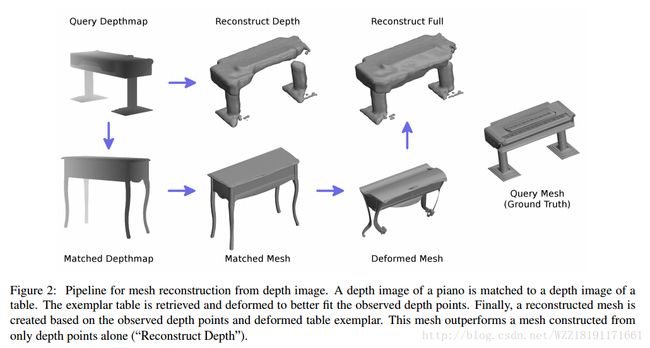
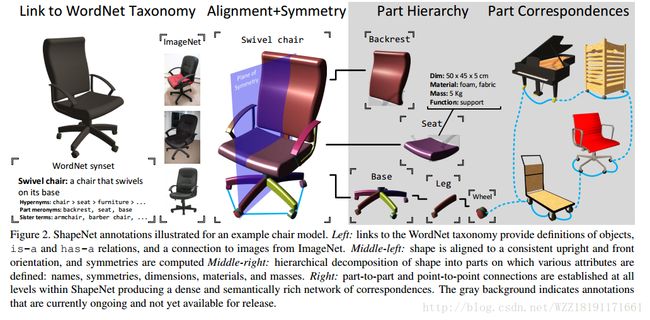
ShapeNet: An Information-Rich 3D Model Repository:
3D reconstruction of synapses with deep learning based on EM Images:
Analysis and synthesis of 3d shape families via deep-learned generative models of surfaces:
FPNN: Field Probing Neural Networks for 3D Data:
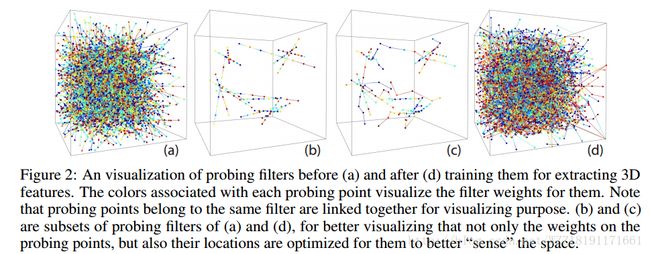
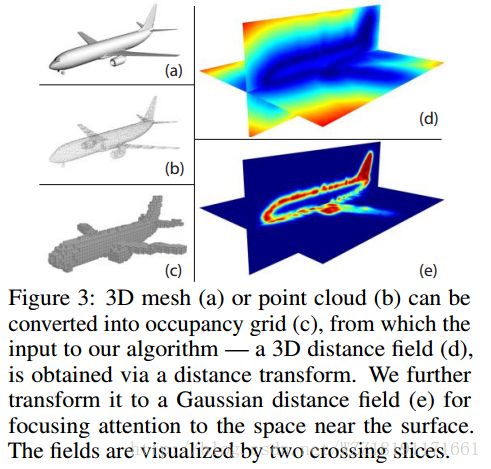
Unsupervised Learning of 3D Structure from Images:

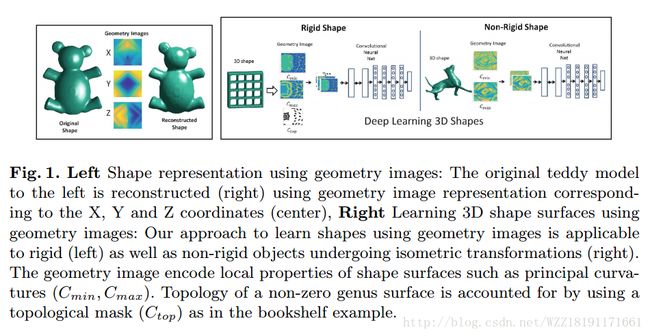
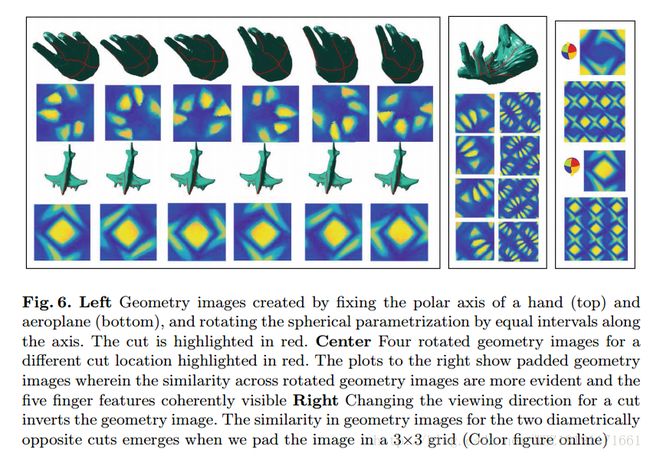
Deep learning 3d shape surfaces using geometry images:

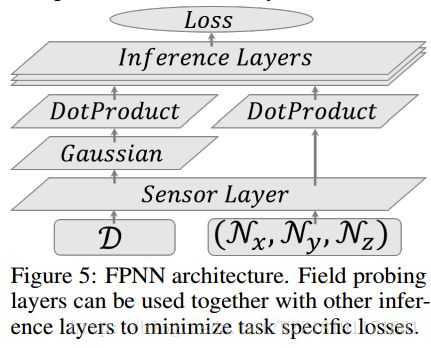
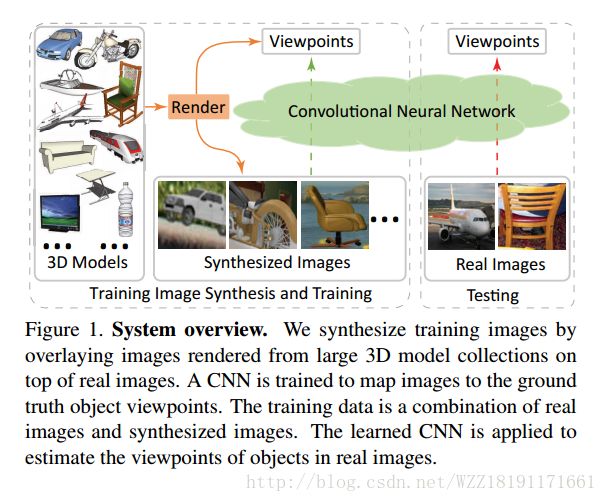
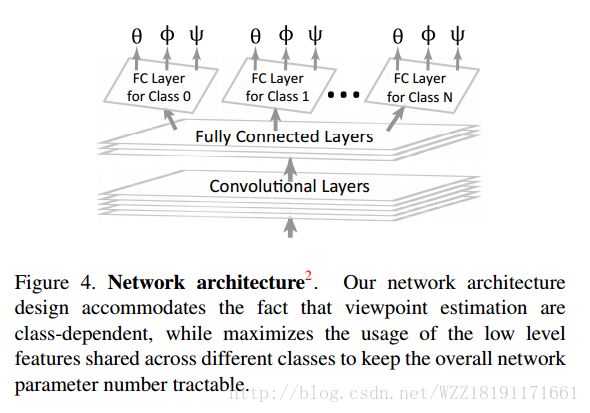
Render for CNN: Viewpoint Estimation in Images Using CNNs Trained with Rendered 3D Model Views:
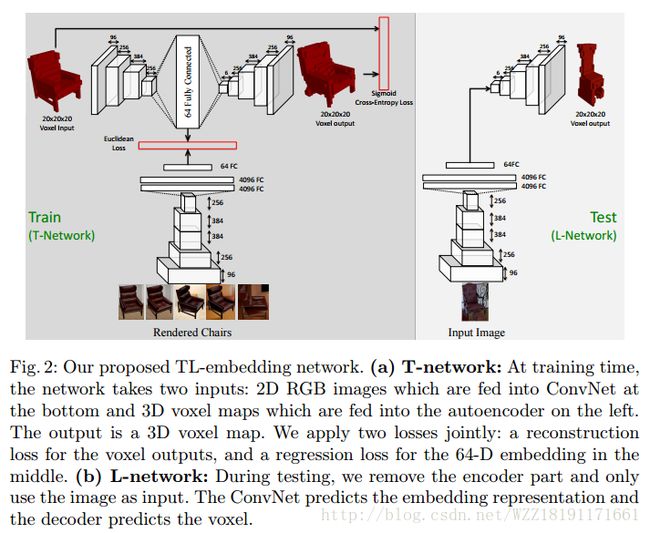
Learning a probabilistic latent space of object shapes via 3d generative-adversarial modeling:

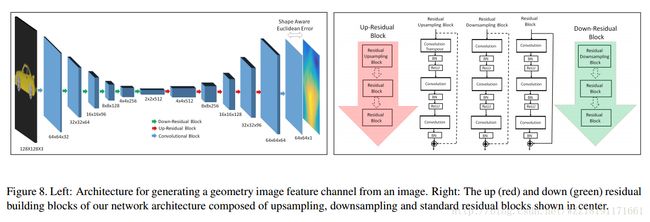
SurfNet: Generating 3D shape surfaces using deep residual networks:

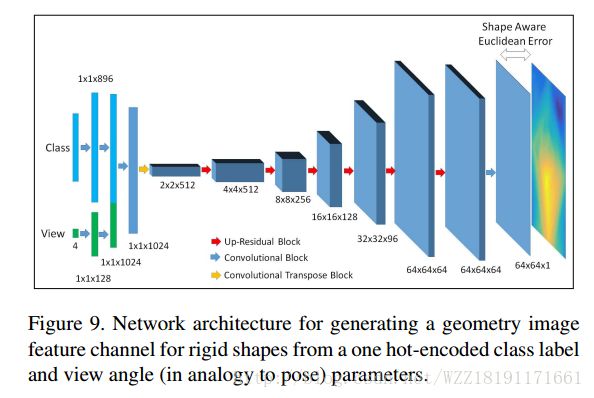
推荐系统
经典模型:
Autorec: Autoencoders meet collaborative filtering
http://users.cecs.anu.edu.au/~akmenon/papers/autorec/autorec-paper.pdfUser modeling with neural network for review rating prediction
https://www.google.com.hk/url?sa=t&rct=j&q=&esrc=s&source=web&cd=1&ved=0ahUKEwj35dyVo6nTAhWEnpQKHSAwCw4QFggjMAA&url=http%3a%2f%2fwww%2eaaai%2eorg%2focs%2findex%2ephp%2fIJCAI%2fIJCAI15%2fpaper%2fdownload%2f11051%2f10849&usg=AFQjCNHeMJX8AZzoRF0ODcZE_mXazEktUQCollaborative Deep Learning for Recommender Systems
https://arxiv.org/pdf/1409.2944.pdfA Multi-View Deep Learning Approach for Cross Domain User Modeling in Recommendation Systems
https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/frp1159-songA.pdfA neural probabilistic model for context based citation recommendation
http://www.personal.psu.edu/wzh112/publications/aaai_slides.pdfHybrid Recommender System based on Autoencoders
acm=1492356698_958d1b64105cd41b9719c8d285736396”>http://delivery.acm.org/10.1145/2990000/2988456/p11-strub.pdf?ip=123.138.79.12&id=2988456&acc=ACTIVE%20SERVICE&key=BF85BBA5741FDC6E%2EB37B3B2DF215A17D%2E4D4702B0C3E38B35%2E4D4702B0C3E38B35&CFID=751612499&CFTOKEN=37099060&acm=1492356698_958d1b64105cd41b9719c8d285736396Wide & Deep Learning for Recommender Systems
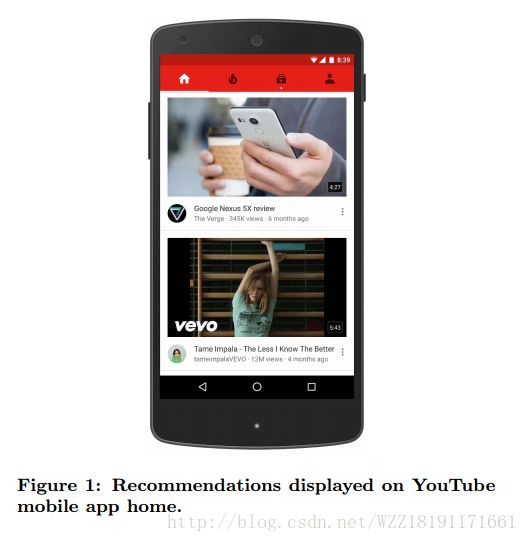
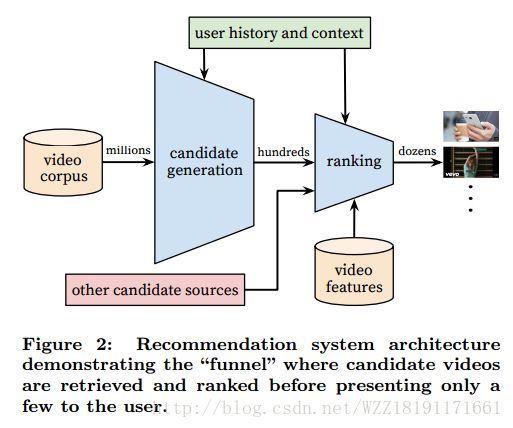
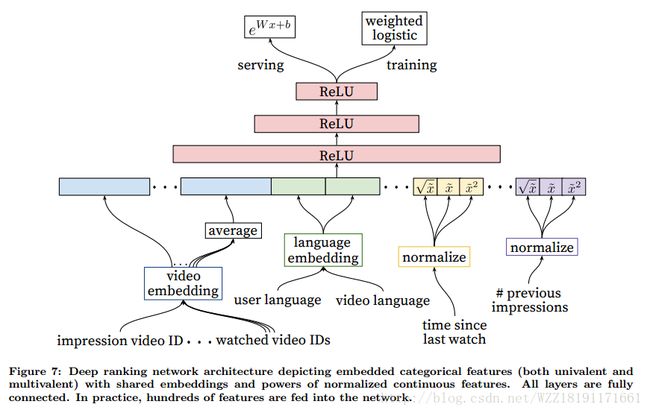
https://arxiv.org/pdf/1606.07792.pdfDeep Neural Networks for YouTube Recommendations
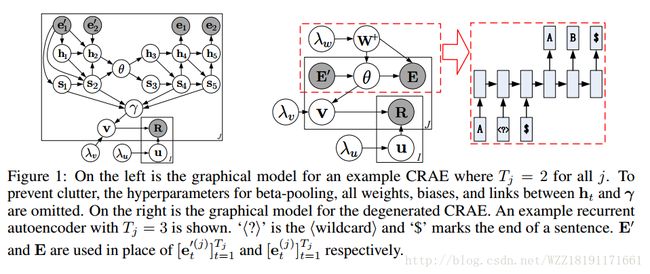
https://static.googleusercontent.com/media/research.google.com/zh-CN//pubs/archive/45530.pdfCollaborative Recurrent Autoencoder: Recommend while Learning to Fill in the Blanks
http://www.wanghao.in/paper/NIPS16_CRAE.pdfNeural Collaborative Filtering
http://www.comp.nus.edu.sg/~xiangnan/papers/ncf.pdfRecurrent Recommender Networks
http://alexbeutel.com/papers/rrn_wsdm2017.pdf
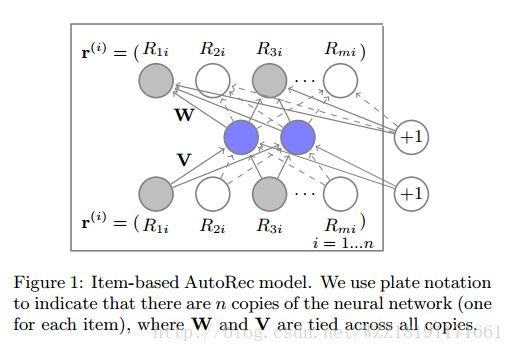
Autorec: Autoencoders meet collaborative filtering:
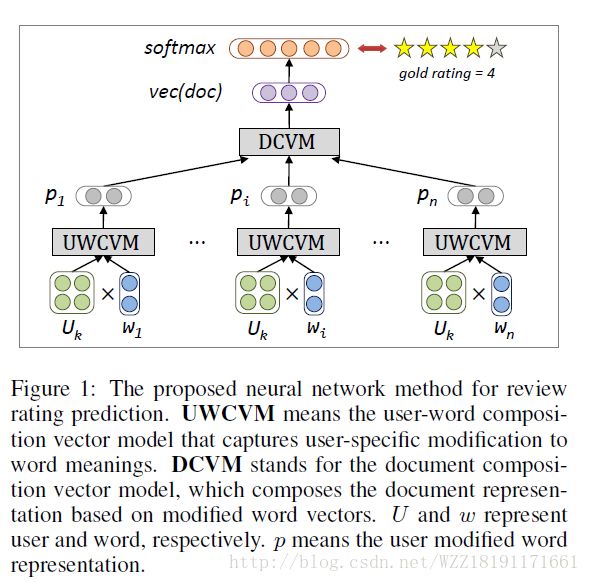
User modeling with neural network for review rating prediction:
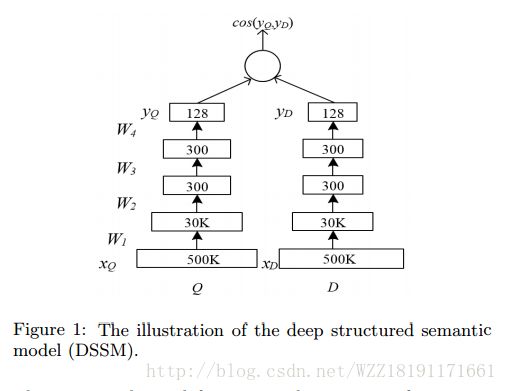
A neural probabilistic model for context based citation recommendation:

A Multi-View Deep Learning Approach for Cross Domain User Modeling in Recommendation Systems:
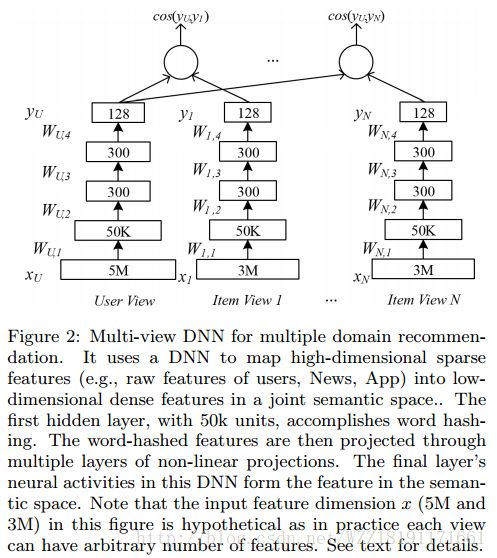
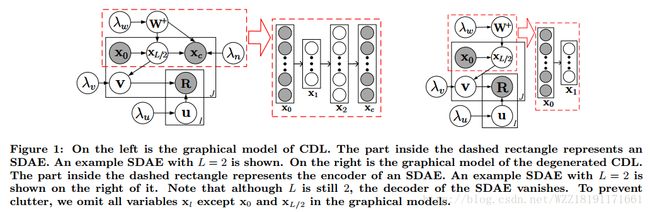
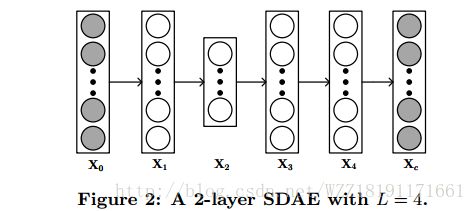
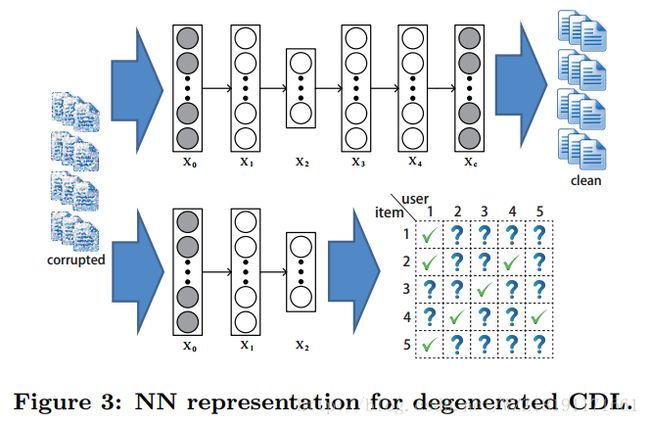
Collaborative Deep Learning for Recommender Systems:
Wide & Deep Learning for Recommender Systems:
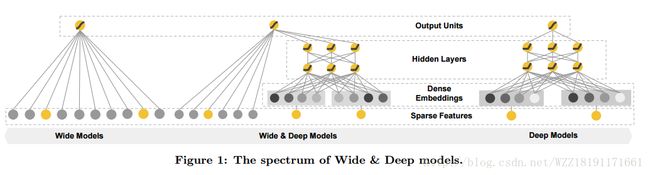
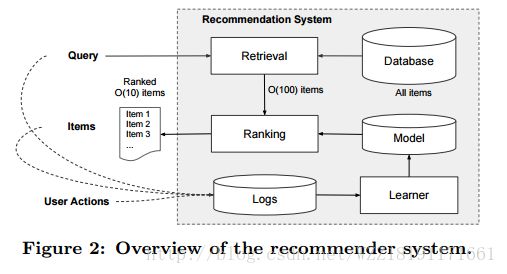
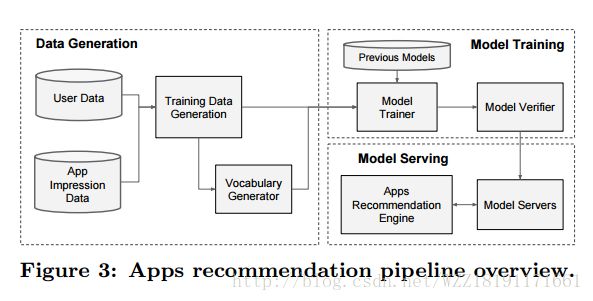
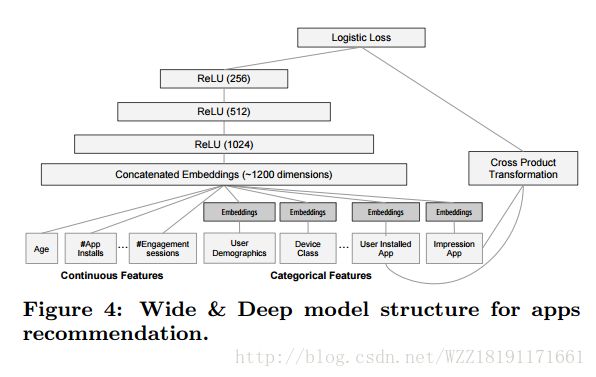
Deep Neural Networks for YouTube Recommendations:
Collaborative Recurrent Autoencoder: Recommend while Learning to Fill in the Blanks:
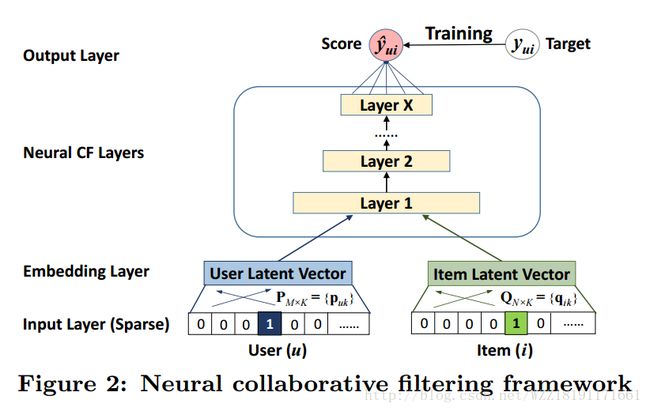
Neural Collaborative Filtering:
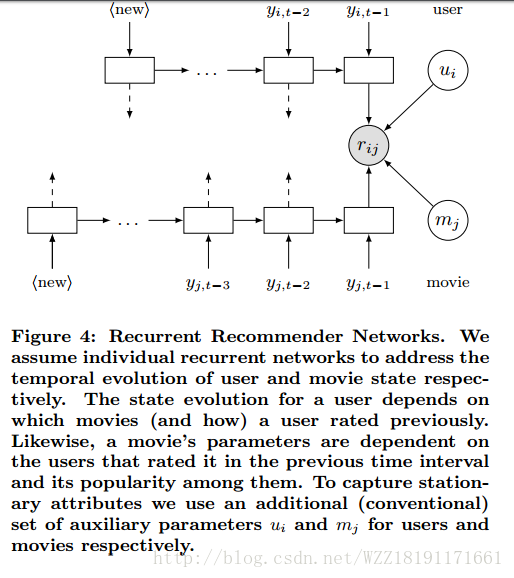
Recurrent Recommender Networks:

细粒度图像分析
经典模型:
Part-based R-CNNs for Fine-grained Category Detection
https://people.eecs.berkeley.edu/~nzhang/papers/eccv14_part.pdfBird Species Categorization Using Pose Normalized Deep Convolutional Nets
http://www.bmva.org/bmvc/2014/files/paper071.pdfMask-CNN: Localizing Parts and Selecting Descriptors for Fine-Grained Image Recognition
https://arxiv.org/pdf/1605.06878.pdfThe Application of Two-level Attention Models in Deep Convolutional Neural Network for Fine-grained Image Classification
http://www.cv-foundation.org/openaccess/content_cvpr_2015/papers/Xiao_The_Application_of_2015_CVPR_paper.pdfBilinear CNN Models for Fine-grained Visual Recognition
http://vis-www.cs.umass.edu/bcnn/docs/bcnn_iccv15.pdfSelective Convolutional Descriptor Aggregation for Fine-Grained Image Retrieval
https://arxiv.org/pdf/1604.04994.pdfNear Duplicate Image Detection: min-Hash and tf-idf Weighting
https://www.robots.ox.ac.uk/~vgg/publications/papers/chum08a.pdfFine-grained image search
https://users.eecs.northwestern.edu/~jwa368/pdfs/deep_ranking.pdfEfficient large-scale structured learning
http://www.cv-foundation.org/openaccess/content_cvpr_2013/papers/Branson_Efficient_Large-Scale_Structured_2013_CVPR_paper.pdfNeural Activation Constellations: Unsupervised Part Model Discovery with Convolutional Networks
https://arxiv.org/pdf/1504.08289.pdf
Part-based R-CNNs for Fine-grained Category Detection:

Bird Species Categorization Using Pose Normalized Deep Convolutional Nets
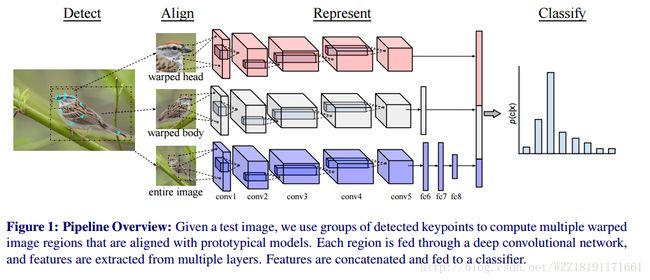
Mask-CNN: Localizing Parts and Selecting Descriptors for Fine-Grained Image Recognition


The Application of Two-level Attention Models in Deep Convolutional Neural Network for Fine-grained Image Classification:
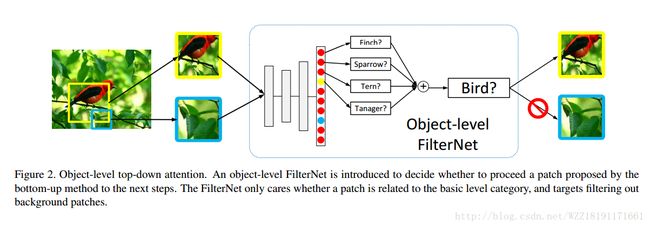
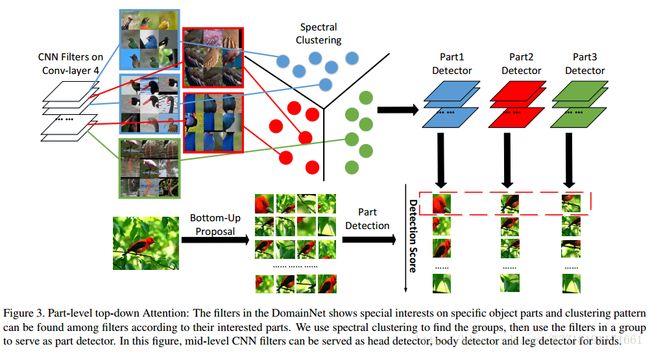
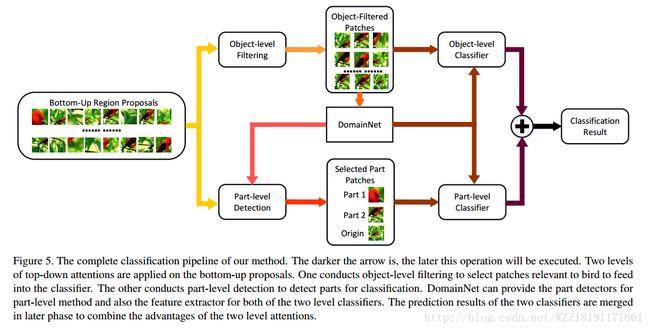
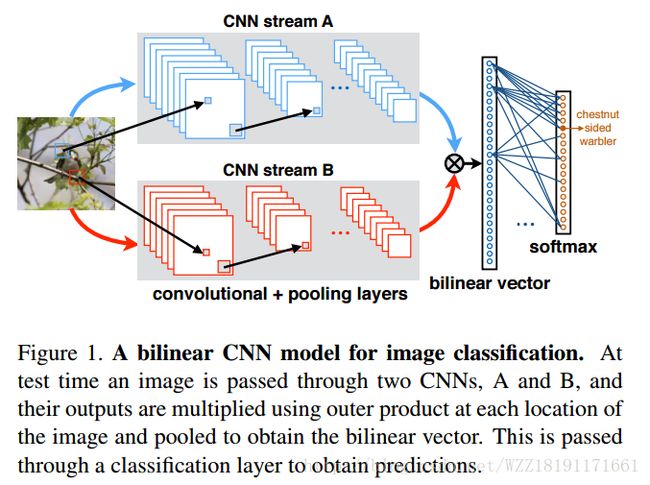
Bilinear CNN Models for Fine-grained Visual Recognition:
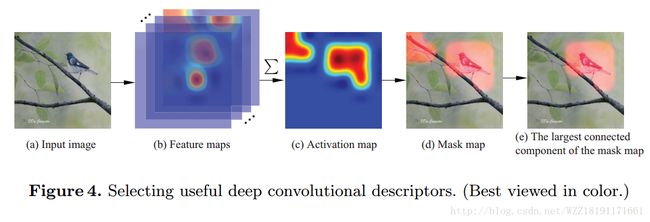
Selective Convolutional Descriptor Aggregation for Fine-Grained Image Retrieval:

Near Duplicate Image Detection: min-Hash and tf-idf Weighting:

Fine-grained image search:


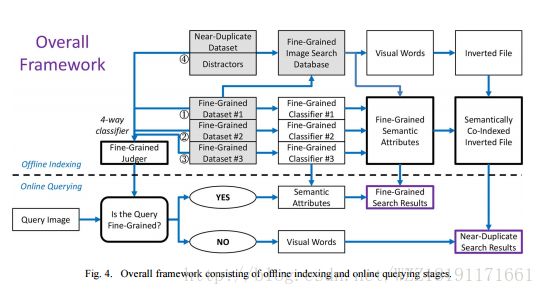
Efficient large-scale structured learning:
Neural Activation Constellations: Unsupervised Part Model Discovery with Convolutional Networks:

图像压缩
经典模型:
Auto-Encoding Variational Bayes
https://arxiv.org/pdf/1312.6114.pdfk-Sparse Autoencoders
https://arxiv.org/pdf/1312.5663.pdfContractive Auto-Encoders: Explicit Invariance During Feature Extraction
http://www.iro.umontreal.ca/~lisa/pointeurs/ICML2011_explicit_invariance.pdfStacked Denoising Autoencoders: Learning Useful Representations in a Deep Network with a Local Denoising Criterion
http://www.jmlr.org/papers/volume11/vincent10a/vincent10a.pdfTutorial on Variational Autoencoders
https://arxiv.org/pdf/1606.05908.pdfEnd-to-end Optimized Image Compression
https://openreview.net/pdf?id=rJxdQ3jegGuetzli: Perceptually Guided JPEG Encoder
https://arxiv.org/pdf/1703.04421.pdf
Auto-Encoding Variational Bayes:


k-Sparse Autoencoders:


Contractive Auto-Encoders: Explicit Invariance During Feature Extraction:
Stacked Denoising Autoencoders: Learning Useful Representa-tions in a Deep Network with a Local Denoising Criterion:
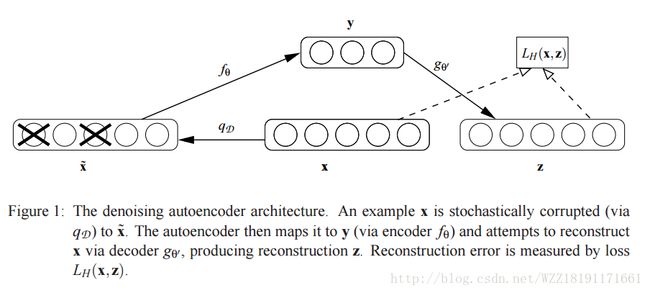
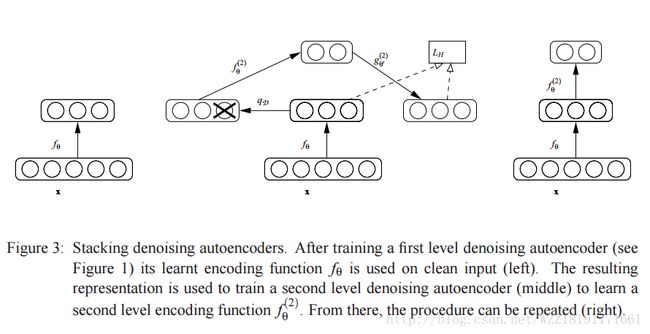
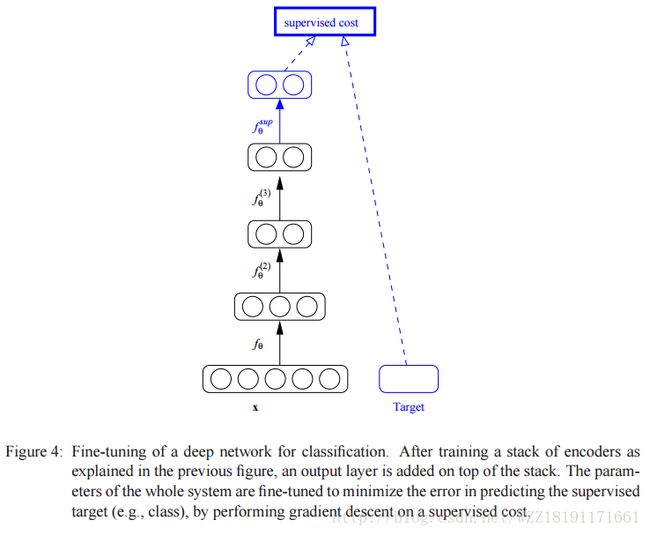


Tutorial on Variational Autoencoders:
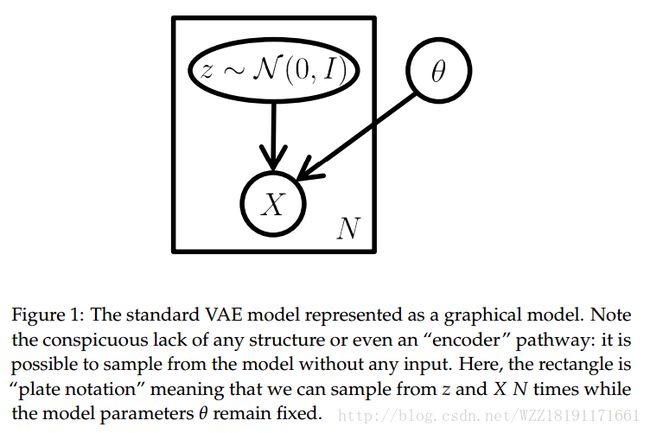

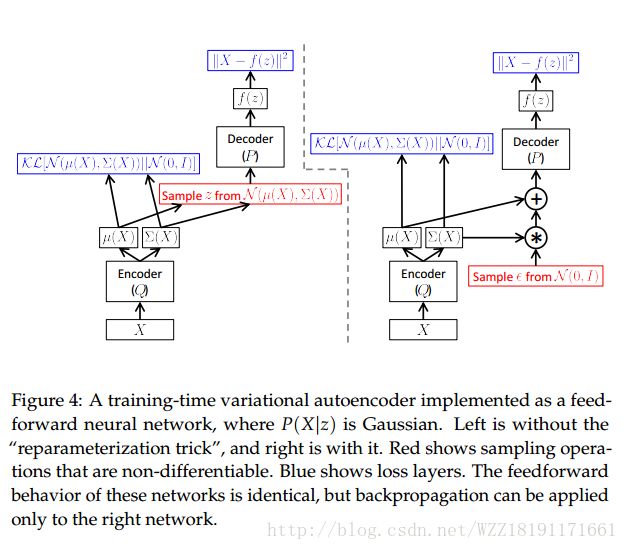
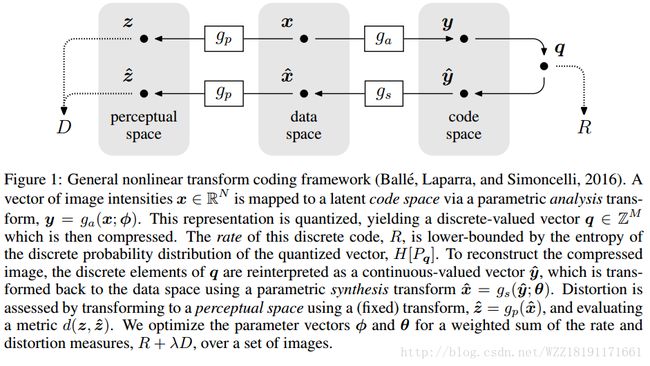
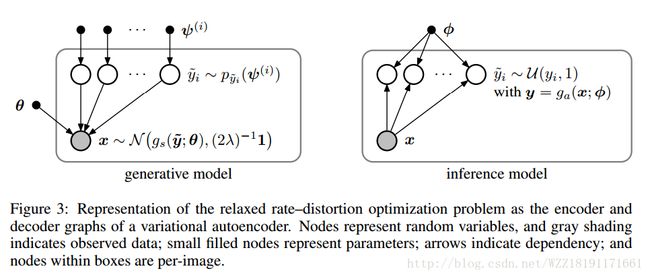
End-to-end Optimized Image Compression:

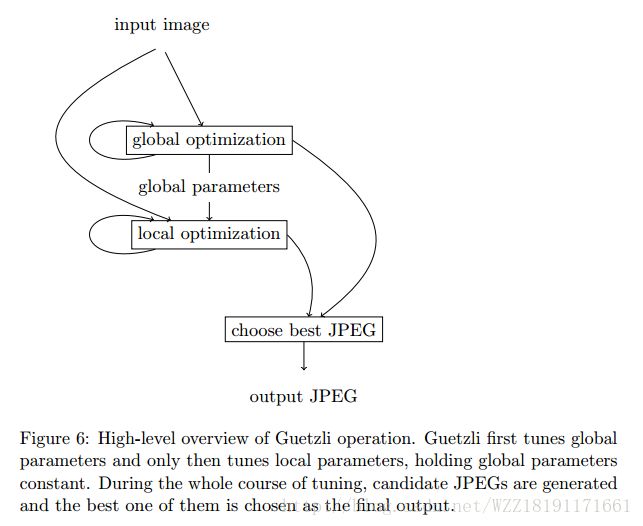
Guetzli: Perceptually Guided JPEG Encoder:



引用块内容
NLP领域
教程:http://cs224d.stanford.edu/syllabus.html
注:
1)目前接触了该领域的一点皮毛,后续会慢慢更新。
2)也希望研究该领域的朋友们做出一些贡献,期待你们的加入。语音识别领域
注:
1)目前还没有详细了解语音识别领域,后续会慢添加更新。
2)也希望研究该领域的朋友们做出一些贡献,期待你们的加入。AGI – 通用人工智能领域
注:
1)目前还没有详细了解语音识别领域,后续会慢添加。
2)也希望研究该领域的朋友们做出一些贡献,期待你们的加入。
深度学习引起的一些新的技术:
- 迁移学习:近些年来在人工智能领域提出的处理不同场景下识别问题的主流方法。相比于浅时代的简单方法,深度神经网络模型具备更加优秀的迁移学习能力。并有一套简单有效的迁移方法,概括来说就是在复杂任务上进行基础模型的预训练(pre-train),在特定任务上对模型进行精细化调整(fine-tune)
- 联合学习(JL):
- 强化学习(RL):强化学习(reinforcement learning,又称再励学习,评价学习)是一种重要的机器学习方法,在智能控制机器人及分析预测等领域有许多应用。但在传统的机器学习分类中没有提到过强化学习,而在连接主义学习中,把学习算法分为三种类型,即非监督学习(unsupervised learning)、监督学习(supervised leaning)和强化学习。
视频教程:
https://cn.udacity.com/course/reinforcement-learning–ud600
注:由于还没有学习到该部分,仅仅知道这个新的概念,后面会慢慢添加进来。
- 深度强化学习(DRL):
Tutorial:http://icml.cc/2016/tutorials/deep_rl_tutorial.pdf
课程: http://rll.berkeley.edu/deeprlcourse/
DeepMind:
https://deepmind.com/blog/deep-reinforcement-learning/
终结语
注:
1. 好了,终于差不多啦,为了写这个东西,花费了很多时间,但是通过这个总结以后,我也学到了很多,我真正的认识到DeepLearning已经贯穿了整个CV领域。如果你从事CV领域的话,我建议你花一些时间去了解深度学习吧!毕竟,它正在颠覆这个邻域!
2. 由于经验有限,可能会有一些错误,希望大家多多包涵。如果你有任何问题,可以你消息给我,我会及时的回复大家。
3. 由于本博客是我自己原创,如需转载,请联系我。
邮箱:[email protected]