分布式理论:关于一致性讨论
一、回顾分布式特点
1.集中式特点
一台或多台计算机组成中心接节点,所有的数据都存在中心节点上。Client端只负责数据的展示,Server处理数据的存储和处理。显而易见,优点是结构简单容易部署,无需考虑服务多个节点部署,更不用考虑节点之间的协调。缺点是系统性能以来中心节点的性能,无法水平扩展。
2.分布式特点
对等:各个节点没有主次之分
分布:在空间上随意分布,水平扩展,比如我们sinai随意再lf和dx随意添加机器
并发:对等的节点可能并发访问访问共享资源,如同时访问redis,db,或一个接口
缺乏全局的时钟:因为分布和对等性,你不知道两个事件发生的前后顺序
故障不固定:很依赖节点之间的通信,因为网路分区或通信异常会导致机器状态不一致
3.分布式问题
通信异常:网路光纤,路由,DNS各种因素导致网络太不可靠了。。。面临重要的两个方面是丢包和包的延迟
网络分区:整个集群只有一部分之间能正常通信,实际上我们美团服务治理中,SG_agent为部署在各服务节点,通过与服务注册路由中心进行通信,实际承担服务注册、服务发现、动态路由解析、负载均衡等功能及
调用统计上报的应用代理程序。
三态:成功,失败,超时
节点故障:一个分布式集群必须支持异常的节点的摘除,节点的扩容等,比如我们的thrift的server 端节点必须能有服务注册、服务发现等功能
4.数据库的事务ACID
ACID各个字母代表什么意思就不用提了,A(原子性,只有成功和失败状态),C(一致性),I(隔离性,各个事物都有自己的数据空间),D(持久性,commit事务的后状态必须是永久的)
经常听到数据库事务的四层隔离,自己画一个图就清楚了:
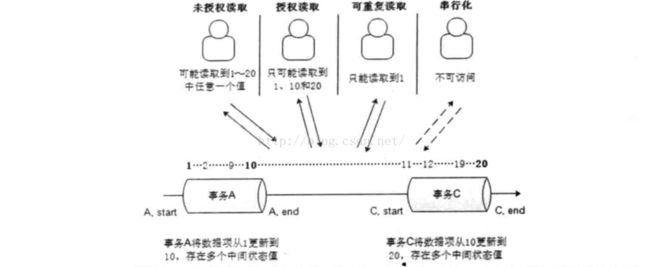
为什么涉及到各种级别呢?是为了保证数据的一致性和完整性,级别越高并发性能差,我们数据库一般都设为第二种授权读,避免脏读有保证较好的并发性能,程序中可主动采用悲观锁和乐观锁来控制,即使我们不用看mysql的源码什么的,我们也可以用锁的原理,实现四层隔离,具体mysql怎么实现的还待深入看看,其实是通过行锁、区间锁等实现的乐观锁和悲观锁实现的,四种隔离是这些锁的组合运用。
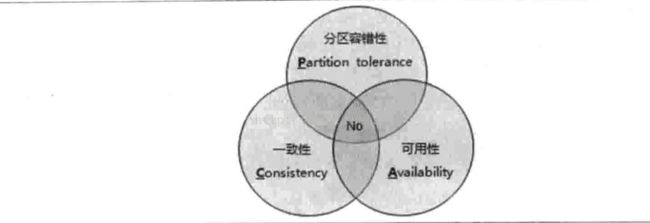
5.分布式事务的强一致性CAP
C:一致性,是指对每个节点一个数据的更新,整个集群都知道更新,并且是一致的 ;
A:可用性,服务必须是24小时可用可访问;
P:分区容错性,出现网络分区故障时,仍然保证一致性很可用性,除非整个集群都down掉;
CAP定理:一个分布式系统无法同时满足CAP要求,只能满足其中的两项。
下面可以讲个例子:
场景是这样的,一个reids服务搭建在两个机房(永丰yf和大兴dx),两个服务进程可以同时提供写入和读取,
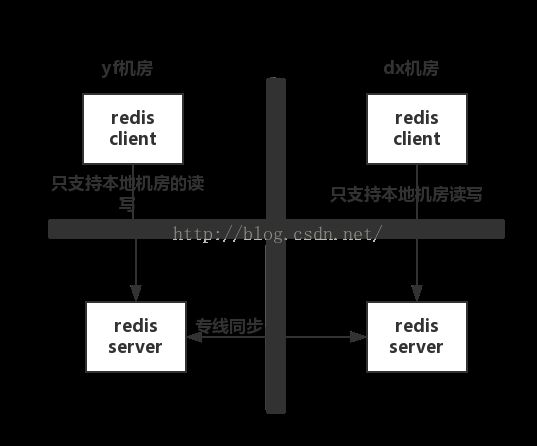
- 假设更新操作是同时写yf和dx都成功才返回成功
在没有出现网络故障的时候,满足CA原则,C 即我的任何一个写入,更新操作成功并返回客户端完成后,分布式的所有节点在同一时间的数据完全一致, A 即我的读写操作都能够成功,但是当出现网络故障时,我不能同时保证CA,即P条件无法满足
- 假设更新操作是只写本地机房成功就返回,通过log回放方式同步至侧边机房
这种操作保证了在出现网络故障时,双边机房都是可以提供服务的,且读写操作都能成功,意味着他满足了AP ,但是它不满足C,因为更新操作返回成功后,双边机房看到的数据会存在短暂不一致,且在网络故障时,不一致的时间差会很大(仅能保证最终一致性)
- 假设更新操作是同时写yf和dx的redis都成功才返回成功且网络故障时提供降级服务
降级服务,如停止写入,只提供读取功能,这样能保证数据是一致的,且网络故障时能提供服务,满足CP原则,但是他无法满足可用性A原则
6.分布式事务弱一致性BASE
在工业的生产中,因为我们无法满足分布式CAP的强一致性,但可以实现分布式的弱一致性。
(basic available):基本可用,指的是响应时间上和功能上做妥协,一般有服务降级,如砍功能等可做到保证服务基本可用
(soft state) : 软可用,数据存在中间态,一般是服务节点在同步数据
(eventually consistent ): 最终一致性,决定数据复制,网络延迟,系统的负载等。
总的来说,base通过牺牲强一致性来保证可用性,和ACID 的相反,允许有一段时间数据在个节点上不一致,只保证数据的最终的一致性。不同业务对数据的一致性的要求不同,我猜测比如一些我们美团金融或支付部门,可能宁可系统停顿也要保证数据的一致,不会像应用数据展示层,短暂的不一致是可以容忍的。所以工业上会结合ACID和BASE使用。
所以在分布式集群中P是不可能放弃的,只是一致性和可用性之间的权衡。
二、一致性协议
2PC:二阶段提交
事务提交机制:
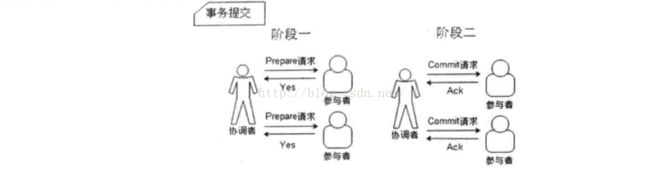
事务中断机制:
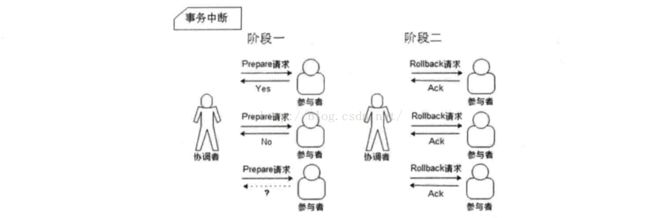
优点:简单
缺点:单点、参与者被堵塞
3PC:三阶段提交,是2PC的延伸
cancommit阶段
precommit阶段(参与者undo和redo日志)
docommit阶段
优点:解决参与者堵塞范围。
缺点:一出新的问题–数据不一致性,因为precommit阶段,参与者接受消息后如果出现网络分区,依然进行进行事务的提交。
paxos算法以及工程实践chubby
他能解决什么问题呢?就是可能发生异常的分布式系统中,快速正确的在集群内对数据对象达成一致,保证无论发生什么异常,都不会破坏整个系统的一致性。一个典型的场景是,在一个分布式数据库系统中,如果各节点的初始状态一致,每个节点执行相同的操作序列,那么他们最后能得到一个一致的状态。
拜占廷问题?网络上可以通过校验算法保证不会出现消息被篡改。
大概内容如下:
proposers 提出提案,提案信息包括提案编号和提议的 value;
acceptor 收到提案后可以接受(accept)提案,若提案获得多数 acceptors 的接受,则称该提案被批准(chosen);
learners 只能“学习”被批准的提案。
划分角色后,就可以更精确的定义问题:
- 决议(value)只有在被 proposers 提出后才能被批准(未经批准的决议称为“提案(proposal)”);
- 在一次 Paxos 算法的执行实例中,只批准(chosen)一个 value;
- learners 只能获得被批准(chosen)的 value。
通过加强约束2,得到paxos算法:
P1:一个 acceptor 必须接受(accept)第一次收到的提案。
无法形成多数派,于是...
P2:一旦一个具有 value v 的提案被批准(chosen),那么之后批准(chosen)的提案必须具有 value v。
何不如对提案加强,于是...
P2a:一旦一个具有 value v 的提案被批准(chosen),那么之后任何 acceptor 再次接受(accept)的提案必须具有 value v。
p1和p2a由于通信异步,没法做到,于是...
P2b:一旦一个具有 value v 的提案被批准(chosen),那么以后任何 proposer 提出的提案必须具有 value v。
假如满足P2c,p2b就可以满足,可以数学归纳法证明。而p3c容易通过消息通信实现,于是...
P2c:如果一个编号为 n 的提案具有 value v,那么存在一个多数派,要么他们中所有人都没有接受(accept)编号小于 n 的任何提案,要么他们已经接受(accpet)的所有编号小于 n 的提案中编号最大的那个提案具有 value v。
要满足 P2c 的约束,proposer 提出一个提案前,首先要和足以形成多数派的 acceptors 进行通信,获得他们进行的最近一次接受(accept)的提案(prepare 过程),之后根据回收的信息决定这次提案的 value,
形成提案开始投票。当获得多数 acceptors 接受(accept)后,提案获得批准(chosen),由 proposer 将这个消息告知 learner。这个简略的过程经过进一步细化后就形成了 Paxos 算法。
一个例子:http://blog.sina.com.cn/s/blog_3dbab28401014lt4.html
分布式锁服务google chubby ,采用paxos算法来解决master的选举问题:

三、zookeeper
zookeeper是决解分布式一致性问题的解决方案,如订阅/发布、负载均衡、命名服务、分布式协调/通知、集群管理、master选举、分布式锁、分布式队列等问题。
zk能保证:顺序性、原子性、单一视图、可靠、实时性(保证一定时间内)。
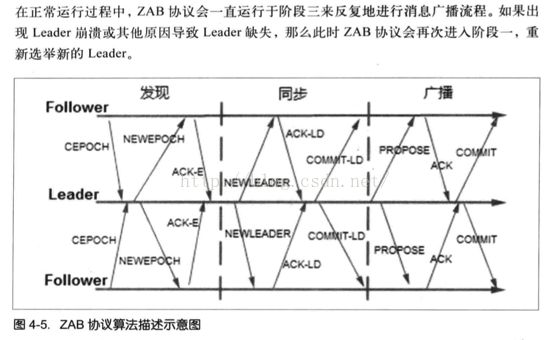
zab协议(zookeeper atomic broadcast)
跟paxos算法一样,都是解决一致性问题。
分为两过程(广播和崩溃)三阶段(发现、同步、广播)
三个阶段:
(1)发现:分布式的多个进程选取主进程作为leader
(2)同步:leader和follower同步,处理上一轮事务和准备新一轮的事务
(3)广播:接受客户端请求,同时进行消息通信
所有的进程状态:looking、followering、leading状态
四、zk使用场景
(1)订阅/发布
如mtconfig服务,一般消息有两种模式(push和pull),zk使用的是推拉相结合的方式:client向server注册关注数据节点,一旦数据发生变更,server向client发送watcher时间通知,client收到后到服务端拉去数据。
(2)负载均衡

(3)命名服务
比如mtthrift的PRC框架,通过服务的key拿到服务端服务器列表等信息。
(4)分布式协调/通知
如:通过wacher协调各个进程进行数据备份
(5)集群管理
如:分布式日志收集、云主机管理等
(5)master选举
一般来说,跟数据库的master和slave概念一样,master进行更新操作等一些复杂的逻辑关系。比如海量数据计算有mater去完成,然后更新到cache,提供给其他的follower共享。
(6)分布式锁、分布式队列
感觉我们大部分的比较大的分布式系统或服务,瓶颈在于频繁进行数据库的操作,比如行锁、表锁甚至是繁重的事务处理。
比如:sinai的job更新事务如何做到分布式?可以通过分布式锁机制。
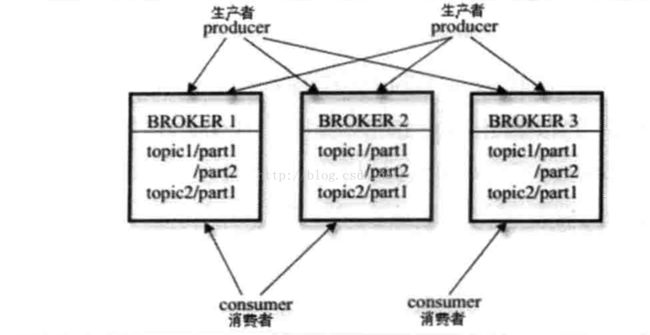
五:zk在kafka 中的应用
hadoo用zk解决resourcemanager的单点问题、
hbase、
zk在kafka上的应用
六、zookeeper简单搭建
集群模式:
单机模式:
伪集群模式:
ls、create、get、delete、set命令使用
client使用方式:
(1)直接调用原生的zookeeper类直连
(2)zkclient包
(3)curator包