Python+gensim【中文LDA】简洁模型
文章目录
- 0、原理
- 1、代码实现
- 2、过程详解
- 2.1、打印中间件
- 2.2、doc2bow函数
- 2.3、主题推断
- 2.4、词和主题的关系
- 3、附录
0、原理
-
LDA文档主题生成模型,也称三层贝叶斯概率模型,包含词、主题和文档三层结构。
利用文档中单词的共现关系来对单词按主题聚类,得到“文档-主题”和“主题-单词”2个概率分布。

-
gensim流程
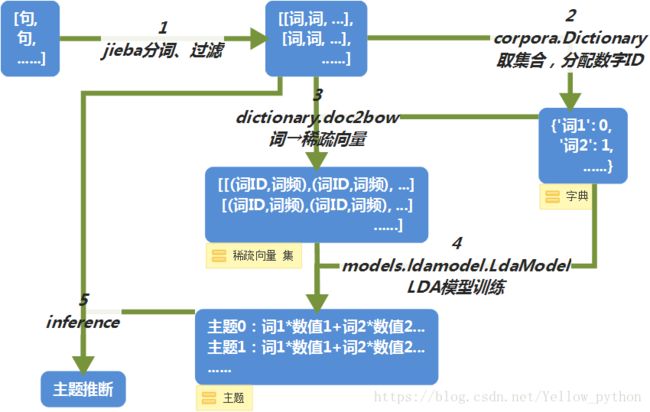
1、代码实现
from gensim import corpora, models
import jieba.posseg as jp, jieba
# 文本集
texts = [
'美国教练坦言,没输给中国女排,是输给了郎平' * 99,
'美国无缘四强,听听主教练的评价' * 99,
'中国女排晋级世锦赛四强,全面解析主教练郎平的执教艺术' * 99,
'为什么越来越多的人买MPV,而放弃SUV?跑一趟长途就知道了' * 99,
'跑了长途才知道,SUV和轿车之间的差距' * 99,
'家用的轿车买什么好' * 99]
# 分词过滤条件
jieba.add_word('四强', 9, 'n')
flags = ('n', 'nr', 'ns', 'nt', 'eng', 'v', 'd') # 词性
stopwords = ('没', '就', '知道', '是', '才', '听听', '坦言', '全面', '越来越', '评价', '放弃', '人') # 停词
# 分词
words_ls = []
for text in texts:
words = [w.word for w in jp.cut(text) if w.flag in flags and w.word not in stopwords]
words_ls.append(words)
# 构造词典
dictionary = corpora.Dictionary(words_ls)
# 基于词典,使【词】→【稀疏向量】,并将向量放入列表,形成【稀疏向量集】
corpus = [dictionary.doc2bow(words) for words in words_ls]
# lda模型,num_topics设置主题的个数
lda = models.ldamodel.LdaModel(corpus=corpus, id2word=dictionary, num_topics=2)
# 打印所有主题,每个主题显示5个词
for topic in lda.print_topics(num_words=5):
print(topic)
# 主题推断
print(lda.inference(corpus))
- 结果
-
主题0(
体育):‘0.081*“ 郎平” + 0.080*“ 中国女排” + 0.077*“ 输给” + 0.074*“ 主教练”’
主题1(汽车):‘0.099*“ 长途” + 0.092*“ SUV” + 0.084*“ 跑” + 0.074*“ 轿车”’
2、过程详解
2.1、打印中间件
- print(words_ls)
-
[[‘美国’, ‘输给’, ‘中国女排’, ‘输给’, ‘郎平’],
[‘美国’, ‘无缘’, ‘四强’, ‘主教练’],
[‘中国女排’, ‘晋级’, ‘世锦赛’, ‘四强’, ‘主教练’, ‘郎平’, ‘执教’, ‘艺术’],
[‘买’, ‘MPV’, ‘SUV’, ‘跑’, ‘长途’],
[‘跑’, ‘长途’, ‘SUV’, ‘轿车’, ‘差距’],
[‘家用’, ‘轿车’, ‘买’]] - print(dictionary.token2id)
- {‘中国女排’: 0, ‘美国’: 1, ‘输给’: 2, ‘郎平’: 3, ‘主教练’: 4, ‘四强’: 5, ‘无缘’: 6, ‘世锦赛’: 7, ‘执教’: 8, ‘晋级’: 9, ‘艺术’: 10, ‘MPV’: 11, ‘SUV’: 12, ‘买’: 13, ‘跑’: 14, ‘长途’: 15, ‘差距’: 16, ‘轿车’: 17, ‘家用’: 18}
- print(corpus)
-
[[(0, 1), (1, 1), (2, 2), (3, 1)],
[(1, 1), (4, 1), (5, 1), (6, 1)],
[(0, 1), (3, 1), (4, 1), (5, 1), (7, 1), (8, 1), (9, 1), (10, 1)],
[(11, 1), (12, 1), (13, 1), (14, 1), (15, 1)],
[(12, 1), (14, 1), (15, 1), (16, 1), (17, 1)],
[(13, 1), (17, 1), (18, 1)]] - print(lda)
- LdaModel(num_terms=19, num_topics=2, decay=0.5, chunksize=2000)
2.2、doc2bow函数
- [‘美国’, ‘输给’, ‘中国女排’, ‘输给’, ‘郎平’]
-
↓↓↓【词→ID】
↓↓↓(美国→0、输给→2、中国女排→1、郎平→3) -
[0,
2, 1,2, 3] -
↓↓↓【生成 稀疏向量】
↓↓↓(2有 两个,其它只有一个) -
[(0, 1), (1, 1), (
2, 2), (3, 1)] - …
2.3、主题推断
for e, values in enumerate(lda.inference(corpus)[0]):
print(texts[e])
for ee, value in enumerate(values):
print('\t主题%d推断值%.2f' % (ee, value))
美国教练坦言,没输给中国女排,是输给了郎平
主题0推断值5.29(体育)
主题1推断值0.71
美国无缘四强,听听主教练的评价
主题0推断值4.44(体育)
主题1推断值0.56
中国女排晋级世锦赛四强,全面解析主教练郎平的执教艺术
主题0推断值8.44(体育)
主题1推断值0.56
为什么越来越多的人买MPV,而放弃SUV?跑一趟长途就知道了
主题0推断值0.54
主题1推断值5.46(汽车)
跑了长途才知道,SUV和轿车之间的差距
主题0推断值0.56
主题1推断值5.44(汽车)
家用的轿车买什么好
主题0推断值0.68
主题1推断值3.32(汽车)
text5 = '中国女排将在郎平的率领下向世界女排三大赛的三连冠发起冲击'
bow = dictionary.doc2bow([word.word for word in jp.cut(text5) if word.flag in flags and word.word not in stopwords])
ndarray = lda.inference([bow])[0]
print(text5)
for e, value in enumerate(ndarray[0]):
print('\t主题%d推断值%.2f' % (e, value))
中国女排将在郎平的率领下向世界女排三大赛的三连冠发起冲击
主题0推断值2.40(体育)
主题1推断值0.60
2.4、词和主题的关系
- 单个词与主题的关系
word_id = dictionary.doc2idx(['长途'])[0]
for i in lda.get_term_topics(word_id):
print('【长途】与【主题%d】的关系值:%.2f%%' % (i[0], i[1]*100))
【长途】与【主题0】的关系值:1.61%
【长途】与【主题1】的关系值:7.41%(汽车)
- 全部词与主题的关系(
minimum_probability设置概率阈值)
for word, word_id in dictionary.token2id.items():
print(word, lda.get_term_topics(word_id, minimum_probability=1e-8))
- 对于每个主题,所有词对应的概率,求和=1
print(lda.show_topic(0, 9999))
print('概率总和', sum(i[0] for i in lda.show_topic(0, 9999)))
3、附录
-
阅读扩展
jieba中文分词
文本相似度分析 -
注释
| En | Cn |
|---|---|
| LDA | Latent Dirichlet Allocation |
| latent | 潜在的 |
| allocation | n. 分配;定位(allocation) |
| inference | n. 推理 |
| term | 术语;学期; |
| doc2bow | document to bag of words(词袋) |
| doc2idx | document to index |