sklearn交叉验证
Scikit-learn 交叉验证
原来是通过调用cross_validation来使用这种交叉验证
现在通过引用model_selection来调用
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import cross_val_score
import matplotlib.pyplot as plt
train_test_split使用
之后首先使用model_selection中的train_test_split来对训练集和测试集进行区分并进行训练,比较
iris = load_iris()
X = iris.data
y = iris.target
X_train,X_test, y_train, y_test = train_test_split(X, y, random_state=4)
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(X_train, y_train)
print(knn.score(X_test, y_test))
pycharm结果显示
/usr/bin/python3 /home/yyl/PycharmProjects/test/venv/sklearn3.py
0.9736842105263158
Process finished with exit code 0
cross_val_score使用
之后使用这一函数对测试集和训练集进行多次分类,然后可以将得到的结果得到其平均值
k_range = range(1, 31)
k_scores = []
for k in k_range:
knn = KNeighborsClassifier(n_neighbors=k)
scores = cross_val_score(knn, X, y, cv=10, scoring='accuracy') #for classification 分类
k_scores.append(loss.mean())
plt.plot(k_range,k_scores)
plt.xlabel('K')
plt.ylabel('cross_cal_score')
plt.show()
结果显示:
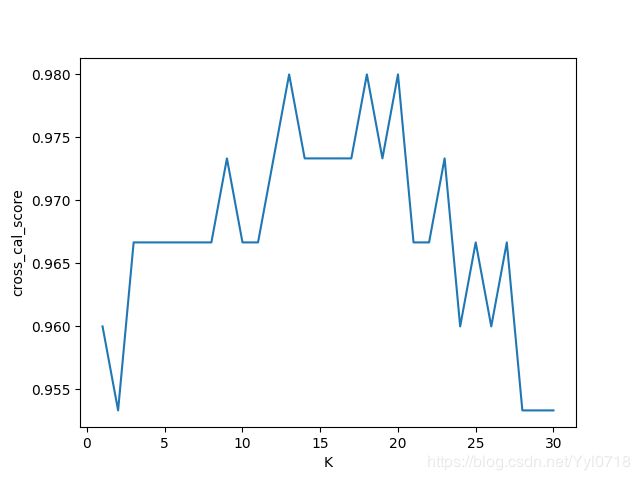
overfitting
如何解决这个问题
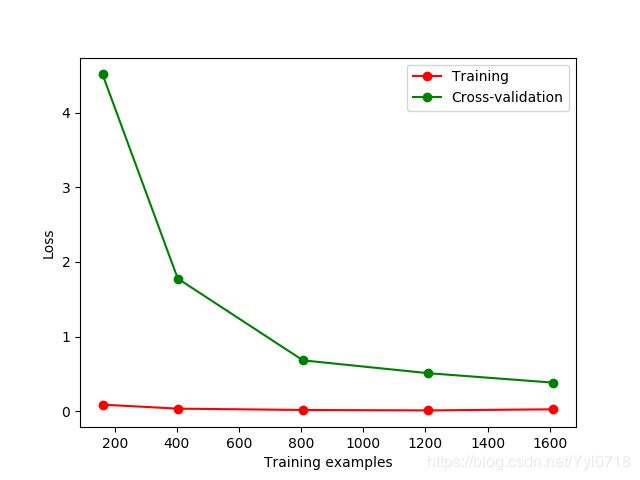
可以通过learning_curve来直观的看到训练的过程
from sklearn.model_selection import learning_curve
from sklearn.datasets import load_digits
from sklearn.svm import SVC
import matplotlib.pyplot as plt
import numpy as np
digits = load_digits()
X = digits.data
y = digits.target
train_sizes, train_loss, test_loss = learning_curve(SVC(gamma=0.001), X, y, cv=10, scoring='neg_mean_squared_error',
train_sizes = [0.1, 0.25, 0.5, 0.75, 1])
train_loss_mean = -np.mean(train_loss, axis=1)
test_loss_mean = -np.mean(test_loss, axis=1)
plt.plot(train_sizes,train_loss_mean, 'o-', color="r",
label = "Training")
plt.plot(train_sizes,test_loss_mean, 'o-', color="g",
label = "Cross-validation")
plt.xlabel("Training examples")
plt.ylabel("Loss")
plt.legend(loc="best")
plt.show()
结果显示:
将gamma值改为0.01之后,结果显示为;
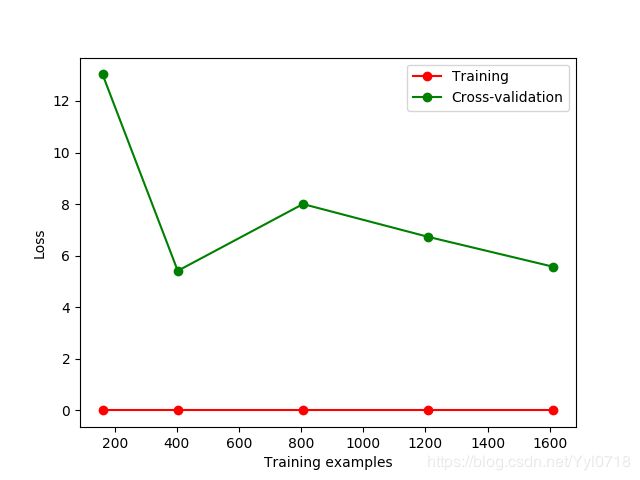
可以看出过拟合
可以通过修改gamma参数来改变这种情况,通过图像来显示
#修改部分import
from sklearn.model_selection import validation_curve
#修改部分代码
param_range=np.logspace(-6,-2.3, 5)
train_loss, test_loss = validation_curve(SVC(), X, y,param_name='gamma',param_range=param_range, cv=10, scoring='neg_mean_squared_error')
train_loss_mean = -np.mean(train_loss, axis=1)
test_loss_mean = -np.mean(test_loss, axis=1)
结果显示
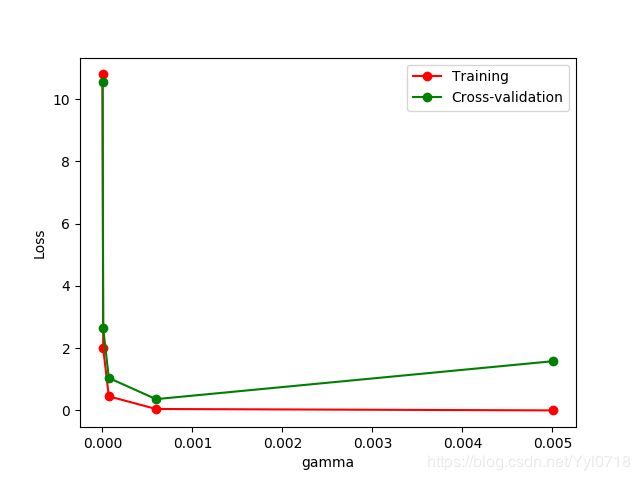
保存model
from sklearn import svm
from sklearn import datasets
import pickle
clf=svm.SVC()
iris =datasets.load_iris()
X,y =iris.data, iris.target
clf.fit(X,y)
#
#
# # #method 1:pickle
#保存
# # with open('save/clf.pickle','wb') as f:
# # pickle.dump(clf,f)
# 读取
# with open('save/clf.pickle','rb') as f:
# clf2 = pickle.load(f)
# print(clf2.predict(X[0:1]))
#method 2:joblib
from sklearn.externals import joblib
#保存
joblib.dump(clf,'save/clf.pkl')
#读取
clf3=joblib.load('save/clf.pkl')
print(clf3.predict(X[0:1]))