yolo系列
参考资料:https://blog.csdn.net/guleileo/article/details/80581858
一、yolov1
核心思想:输入整张图,直接在输出层回归bounding box的位置和类别概率。
摘要
此篇文章提出一种新的物体检测方法yolo,对于先前检测工作的分类器重新利用。把目标检测看作一个回归问题得到bounding box的空间位置和相关分类的概率。单个网络在一次评估中从完整图像中预测出bounding box框和类概率。因为整个检测框架是一个单网络,可以在检测性能上直接被端到端优化。结构非常快,基础yolo实时达到45帧/s。较小版本达到155帧/s,同时是其他实时检测器mAP的2倍。
问题:一种新的物体检测方法
方法:用回归思想解决物体检测,输入完整图像,直接在输出回归物体的bounding box框和类概率。

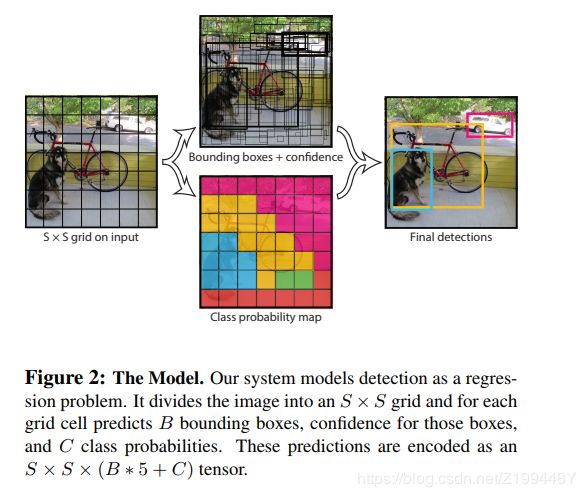
把输入图像换份为S*S个格子,对每个格子预测B个box以及置信分数,再通过NMS得到最终的框。简单粗暴的全部采用了 sum-squared error loss 。
效果:速度快,45帧/s;较小版本达到155帧/s,同时是其他实时检测器mAP的2倍。
缺点:yolo产生更多的定位误差,yolo学习目标的一般表示。
YOLO 对相互靠的很近的物体,还有很小的群体检测效果不好,这是因为一个网格中只预测了两个框,并且只属于一类。
同一类物体出现的新的不常见的长宽比和其他情况时,泛化能力偏弱。
由于损失函数的问题,定位误差是影响检测效果的主要原因。尤其是大小物体的处理上,还有待加强。
二、yolov2
YOLOv2:代表着目前业界最先进物体检测的水平,它的速度要快过其他检测系统(FasterR-CNN,ResNet,SSD),使用者可以在它的速度与精确度之间进行权衡。
核心思想:YOLO9000:这一网络结构可以实时地检测超过 9000 种物体分类,这归功于它使用了 WordTree,通过 WordTree 来混合检测数据集与识别数据集之中的数据。
1、提出一种联合训练算法,把分类数据集(ImageNet)和目标检测数据集(COCO)混合起来训练检测器,用分类数据集提高分类精确度,用检测数据集学习准确定位。
2、简化网络(加入BN,高分辨率、去掉全连接层使用anchor boxes、对box做聚类、多尺度训练)
wordTree优点:对未知或者新的物体进行分类时,性能降低的很优雅(gracefully)。比如看到一个狗的照片,但不知道是哪种种类的狗,那么就高置信度(confidence)预测是”狗“,而其他狗的种类的同义词如”哈士奇“”牛头梗“”金毛“等这些则低置信度。
三、yolov3
YOLOv3 在 Pascal Titan X 上处理 608x608 图像速度可以达到 20FPS,在 COCO test-dev 上 [email protected] 达到 57.9%,与RetinaNet(FocalLoss论文所提出的单阶段网络)的结果相近,并且速度快 4 倍。
yolov3在测试时会查看整个图像,预测用到了全局信息。
改进:
1、多尺度预测(类FPN)——每种尺度预测 3 个 box, anchor 的设计方式仍然使用聚类,得到9个聚类中心,将其按照大小均分给 3 个尺度
2、分类网络(类ResNet)和分类器(darknet-53)
四、总结
yolov1将目标检测分类问题转化为直接回归问题
yolov2采用了联合训练算法(将检测数据集和分类数据集混合训练)提高分类和定位精确度
yolov3采用多尺度预测和更快的分类网络darknet-53分别提高定位精确度和分类速度,同时也用到了anchor box的思想
五、yolo和SSD区别
SSD是结合了yolo系列的回归思想和Faster RCNN的anchor box思想得到的一阶段目标检测方法。
1、SSD在CNN后直接检测,yolo在全连接层后检测。
2、SSD提取了不同尺度的特征图来做检测,大尺度特征图(较靠前的特征图)可以用来检测小物体,而小尺度特征图(较靠后的特征图)用来检测大物体;
3、SSD采用了不同尺度和长宽比的先验框(Prior boxes, Default boxes,在Faster R-CNN中叫做锚,Anchors)。
Yolo算法缺点是难以检测小目标,而且定位不准,但是这几点重要改进使得SSD在一定程度上克服这些缺点。