目标检测系列学习笔记(RCNN系列+YOLO系列)
小白一枚 记录学习点滴
里面的“?”是我还没有太看懂的部分
1. RCNN
article: Rich feature hierarchiesfor accurate object detection and semantic segmentation(2014)
27th IEEE Conference onComputer Vision and Pattern Recognition (CVPR)
作者: Girshick, Ross; Donahue, Jeff; Darrell, Trevor; 等.
被引频次1161
code: http://www.cs.berkeley.edu/~rbg/rcnn
传统方法:HOG,DPM,LBP,SIFT,BoW
算法思路:
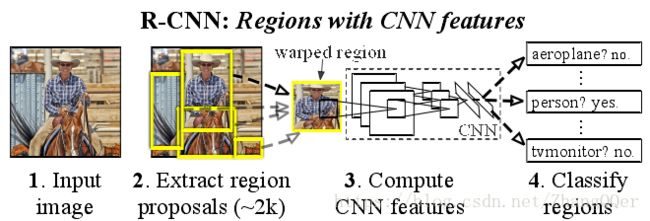

1) 候选区域选择
RegionProposal是一类传统的区域提取方法(selective search),可以看作不同宽高的滑动窗口(1-2k个),通过窗口滑动获得潜在的目标图像。然后进行归一化,作为CNN的标准输入
2) CNN特征提取(标准CNN过程,得到固定维度的输出)
提取图像的所有候选框(选择性搜索)
对于每个区域,修正大小以适合CNN的输入,将第五个池化层的输出(对候选框提取到的特征)存到硬盘
3) 分类与边界回归
实际包含两个子步骤,一是对上一步的输出向量进行分类(SVM);二是通过边界回归(bounding-boxregression) 得到精确的目标区域。
结果:


问题:
1) 多个候选区域对应的图像需要预先提取,占用较大的磁盘空间;
2) 针对传统CNN需要固定尺寸的输入图像,crop/warp(归一化)产生物体截断或拉伸,会导致输入CNN的信息丢失;
3) 每一个Proposal Region都需要进入CNN网络计算,上千个Region存在大量的范围重叠,重复的特征提取带来巨大的计算浪费。
附:
Ø Proposal Region(Selective Search和edge Boxes)
Selective search for objectrecognition. IJCV, 2013.
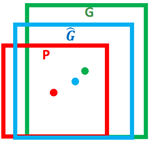
Ø Bounding Box Regression
对于窗口一般使用四维向量(x,y,w,h) 来表示,分别表示窗口的中心点坐标和宽高。红色的框 P 代表原始的Proposal, 绿色的框 G 代表目标的 Ground Truth,Bbox reg的目标是寻找一种关系使得输入原始的窗口 P 经过映射得到一个跟真实窗口 G 更接近的回归窗口。
article:Object Detection with Discriminatively Trained Part-Based Models(2010)
作者: Felzenszwalb,Pedro F.; Girshick, Ross B.; McAllester, David; 等.
IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE
被引频次: 2798
Ø SPPNet
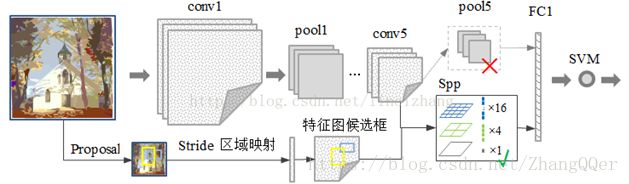
思路:
1) 取消了crop/warp图像归一化过程,解决图像变形导致的信息丢失以及存储问题
2) 采用空间金字塔池化(Spatial Pyramid Pooling )替换了全连接层之前的最后一个池化层
3) 只对原图进行一次卷积得到整张图的feature map,然后找到每个候选框在feature map上的映射patch,将此patch作为每个候选框的卷积特征输入到SPP layer和之后的层。节省了大量的计算时间,比R-CNN有一百倍左右的提速。
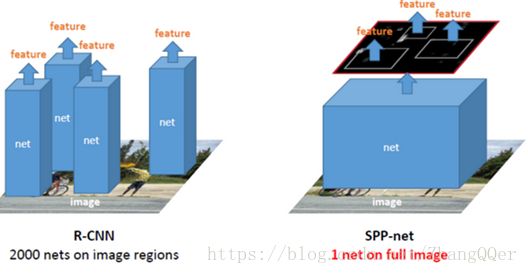
问题:
1) 和RCNN一样,训练过程仍然是隔离的,提取候选框、计算CNN特征、SVM分类、Bounding Box回归独立训练,大量的中间结果需要转存,无法整体训练参数
2) SPP-Net无法更新空间金字塔池层以下的权重(FastRCNN2.3解释了?)
3) 在整个过程中,Proposal Region仍然很耗时
2. FastR-CNN
article: Fast R-CNN
作者: Girshick,Ross
会议: IEEE International Conference on Computer Vision
2015 IEEE INTERNATIONALCONFERENCE ON COMPUTER VISION (ICCV)
被引频次: 381
code: https://github.com/rbgirshick/fast-rcnn.
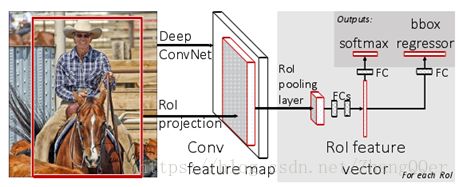

思路:
1) 生成region proposal(通过selective search),每张图片大约2000个候选框
2) Fast-RCNN把整张图片送入CNN,进行特征提取
3) Fast-RCNN把regionproposal映射到CNN的最后一层卷积feature map上
4) 通过RoI pooling层(其实是单层的SPP layer)使得每个建议窗口生成固定大小的feature map
5) 继续经过两个全连接层(FC)得到特征向量,得到两个输出向量(称为multi-task)
第一个是分类,使用softmax(比SVM效果好),第二个是每一类的boundingbox回归。利用SoftMax Loss和Smooth L1 Loss对分类概率和边框回归联合训练
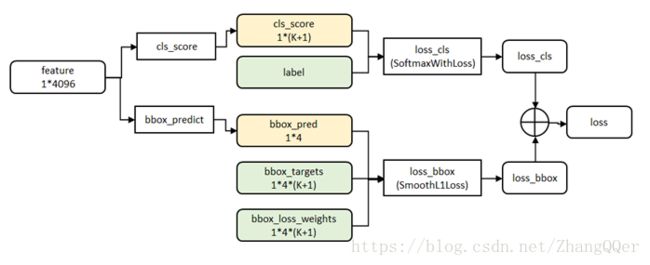
cls_score层用于分类,输出K+1维数组p,表示属于K类和背景的概率。
bbox_prdict层用于调整候选区域位置,输出4*K维数组t,表示分别属于K类时,应该平移缩放的参数
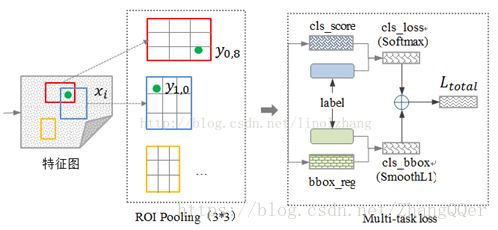
优点:
1) 平均准确率(mAP)高于R-CNN,SPPnet
2) 提速
在训练时,SGD分层次采样,先采样N张图像,然后在每张图像上采样R/N个RoI。来自于同一张图像的RoIs共享计算和内存。
3) 全连接层通过SVD加速(?)
4) 采用mult-task loss,将softmax分类器和bounding-box regressors联合优化
5) 训练可以更新所有网络层
6) 不需要缓存特征
结果:

问题:
1) Fast R-CNN中采用selectivesearch算法提取候选区域,而目标检测大多数时间都消耗在这里
2) Fast R-CNN并没有实现真正意义上的端到端训练模式
3. FasterR-CNN
article: Faster R-CNN: TowardsReal-Time Object Detection with Region Proposal Networks
作者: Ren,Shaoqing; He, Kaiming; Girshick, Ross; 等.
International Conference on Neural Information ProcessingSystems(2015)被引频次: 1661
IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE (2016)被引频次: 67
code: https://github.com/rbgirshick/py-faster-rcnn
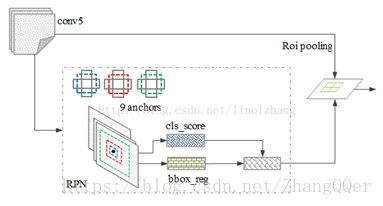
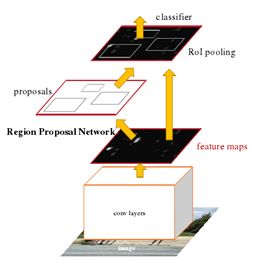
RPN:
RPN负责寻找proposal,Fast-RCNN负责对RPN的结果进一步优化。RPN可以找到图片中每个物体的种类和位置,如果更注重速度而不是精度的话完全可以只使用RPN。RPN是一个FCN,可以输入任意分辨率的图像,经过网络后就得到一个feature map
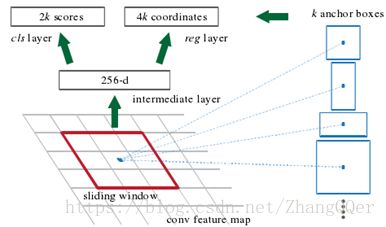

anchors:由generate_anchors.py生成的一组矩形
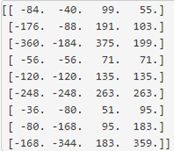
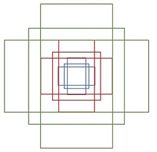
对RPN的改进: SSD(SingleShot MultiBox Detector)。RPN对小物体检测效果很差,假设输入为512*512,经过网络后得到的feature map是32*32,那么feature map上的一个点就要负责周围至少是16*16的一个区域的特征表达,那对于在原图上很小的物体它的特征就难以得到充分的表示,因此检测效果比较差。2016年的SSD允许从CNN各个level的feature map预测检测结果,这样就能很好地适应不同scale的物体,对于小物体可以由更底层的feature map做预测。
思路:
通过滑动窗口的方式实现候选框的提取,每个滑动窗口位置生成9个候选窗口(不同尺度、不同宽高),提取对应9个候选窗口(anchor)的特征,用于目标分类和边框回归,与FastRCNN类似。
目标分类只需要区分候选框内特征为前景或者背景。边框回归确定更精确的目标位置
候选框的选取依据:
1)丢弃跨越边界的anchor
2)与样本重叠区域大于0.7的anchor标记为前景,重叠区域小于0.3的标定为背景
训练方式:
1)根据现有网络初始化权值w,训练RPN
2)用RPN提取训练集上的候选区域,用候选区域训练FastRCNN,更新权值w
3)重复1、2,直到收敛
结果

小结:


4. YOLO
4.1 YOLOv1
article:You Only Look Once:Unified, Real-Time Object Detection
2016 IEEE Conference on Computer Vision andPattern Recognition (CVPR)
作者: Redmon, Joseph; Divvala, Santosh; Girshick, Ross; 等.
被引频次: 164
思想:
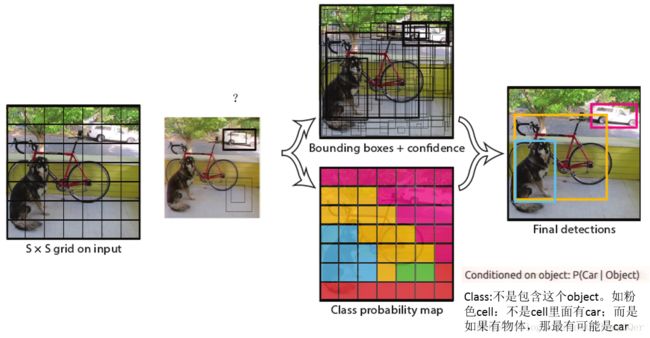
YOLO将输入图像分成S*S个格子,每个格子负责检测‘落入’该格子的物体。若某个物体的中心位置的坐标落入到某个格子,那么这个格子就负责检测出这个物体。如下图所示,图中物体狗的中心点(红色原点)落入第5行、第2列的格子内,所以这个格子负责预测图像中的物体狗。

网络结构

其中,卷积层用来提取图像特征,全连接层用来预测图像位置和类别概率值。
YOLO网络借鉴了GoogLeNet分类网络结构。不同的是,YOLO未使用inception module,而是使用1x1卷积层(此处1x1卷积层的存在是为了跨通道信息整合)+3x3卷积层简单替代。
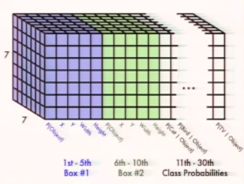
输出:
每个cell代表:
每个boundingbox的x,y,w,h和confidence
每一种类别的probabilities
对于 Pascal VOC:
7*7 grid
2 Bounding boxes
20 classes
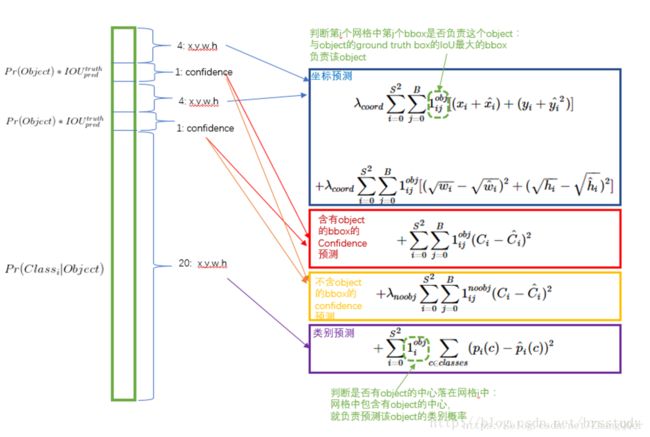
loss函数:
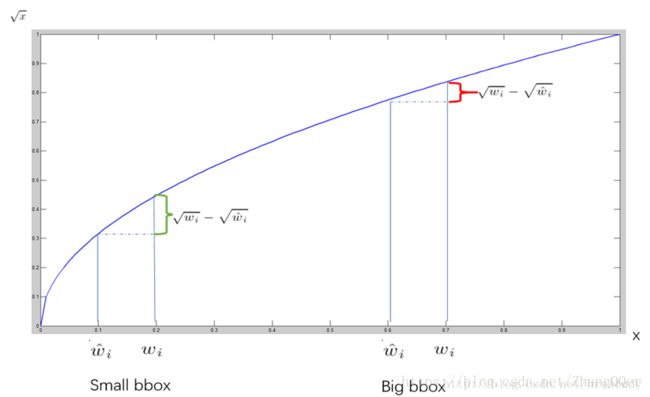
由于小框的变化对识别的影响比大框要大,所以使用根号让小框的影响更大
训练:
1. 预训练
使用ImageNet 1000类数据以一半分辨率(224×224输入图像)预先训练YOLO网络的前20个卷积层+1个average池化层+1个全连接层。然后将分辨率加倍以进行检测。
2. 用步骤1)得到的前20个卷积层网络参数来初始化YOLO模型前20个卷积层的网络参数,然后用VOC 20类标注数据进行YOLO模型训练。为提高图像精度,在训练检测模型时,将输入图像分辨率加倍以进行检测(resize到448x448)。
优点;
1. 快。
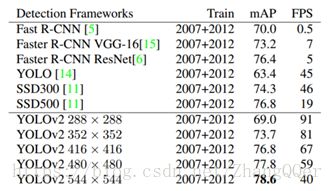
YOLO将物体检测作为回归问题进行求解,整个检测网络pipeline简单。在titan x GPU上,在保证检测准确率的前提下(63.4% mAP,VOC 2007 test set),可以达到45fps的检测速度。
2. 背景误检率低。
YOLO在训练和推理过程中能‘看到’整张图像的整体信息,而基于region proposal的物体检测方法(如rcnn/fast rcnn),在检测过程中,只‘看到’候选框内的局部图像信息。因此,若当图像背景(非物体)中的部分数据被包含在候选框中送入检测网络进行检测时,容易被误检测成物体。测试证明,YOLO对于背景图像的误检率低于fast rcnn误检率的一半。
3. 通用性强。
YOLO对于艺术类作品中的物体检测同样适用。它对非自然图像物体的检测率远远高于DPM和RCNN系列检测方法。
缺点:
1. 识别物体位置精准性差。
2. 召回率低。
3. 由于输出层为全连接层,因此在检测时,YOLO训练模型只支持与训练图像相同的输入分辨率。
4. 虽然每个格子可以预测B个bounding box,但是最终只选择只选择IOU最高的bounding box作为物体检测输出,即每个格子最多只预测出一个物体。当物体占画面比例较小,如图像中包含畜群或鸟群时,每个格子包含多个物体,但却只能检测出其中一个。
创新点:
1. YOLO训练和检测均是在一个单独网络中进行。
2. YOLO将物体检测作为一个回归问题进行求解,输入图像经过一次inference,便能得到图像中所有物体的位置和其所属类别及相应的置信概率。
fast YOLO
它只有9个卷积层和2个全连接层。使用titanx GPU,fast YOLO可以达到155fps的检测速度,但是mAP值也从YOLO的63.4%降到了52.7%,但却仍然远高于以往的实时物体检测方法(DPM)的mAP值
参考:
https://blog.csdn.net/hrsstudy/article/details/70305791
https://www.bilibili.com/video/av11200546/
4.2 YOLOv2
article:YOLO9000:Better, Faster, Stronger
作者: Redmon, Joseph; Farhadi, Ali
30th IEEE/CVF Conference on Computer Visionand Pattern Recognition (CVPR)
YOLO2主要有两个大方面的改进:
使用一系列的方法对YOLO进行了改进,在保持原有速度的同时提升精度得到YOLOv2。
提出了一种目标分类与检测的联合训练方法,同时在COCO和ImageNet数据集中进行训练得到YOLO9000,实现9000多种物体的实时检测。
1 Better
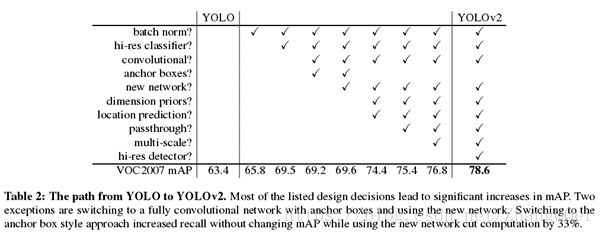
1.1 Batch Normalization
批量标准化。通过在YOLO中的所有卷积层上添加批量归一化,mAP中获得超过2%的改进效果。可以在舍弃dropout优化后依然不会过拟合。
1.2 High ResolutionClassifier
高分辨率分类器。原来的YOLO在224×224分辨率上训练分类器网络,并将分辨率增加到448以用于检测。YOLOv2首先在448×448的分辨率下使用分类网络(darknet)对ImageNet上的10个epoch进行微调。然后在检测时微调所得到的网络。这种高分辨率分类网络增加了近4%的mAP。
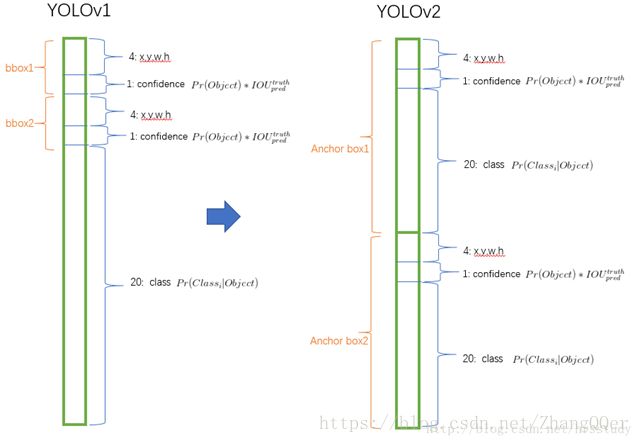
1.3 Convolutional WithAnchor Boxes
(借鉴了Faster R-CNN中的anchor思想)
1. 从YOLO中删除全连接层,并使用anchor box预测边界框。
2. 消除一个池化层,使网络的卷积层的输出更高的分辨率。
3. 缩小网络将输入尺寸为416*416而不是448*448。目的是为了让后面产生的卷积特征图的宽高都为奇数,这样就可以产生一个center cell(大物体通常占据了图像的中间位置,就可以只用中心的一个cell来预测这些物体的位置,否则就要用中间的4个cell来进行预测)。
4. YOLO的卷积层将图像下采样32倍,所以通过使用输入图像416,得到13×13的输出特征图。
5. YOLOv2不再由栅格去预测条件类别概率,而由Bounding boxes去预测。在YOLOv1中输出的维度为S * S * (B * 5 + C ),而YOLOv2为S * S * (B * (5 + C))。
使用anchorboxes, 模型的的精度有一点点下降,但是Recall有大幅上升。没有anchor box,我们的中间模型的mAP为69.5,Recall为81%。使用anchor boxes 模型的mAP为69.2,Recall为88%。
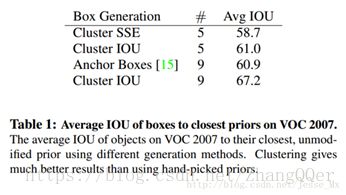
1.4 Dimension Clusters(维度聚类)
使用anchor的第一个问题:如何选择anchorboxes。Faster R-CNN的anchor boxes是手工精心挑选的,但未必是最好的。
使用K-means从训练集中聚类得到的anchorboxes可能更好。传统的K-means聚类方法使用的是欧氏距离函数,但是较大的boxes会比较小的boxes产生更多的error,聚类结果可能会偏离。因此采用的评判标准是IOU得分
![]()


左图显示了通过k的各种选择获得的平均IOU。 发现k = 5为模型的召回率与复杂性提供了良好的折衷。右图显示了VOC和COCO的相对质心。这两种套装都喜欢更薄,更高的盒子,而COCO的尺寸比VOC更大。
两种anchor选择方法的对比试验:使用聚类方法,仅仅5种boxes的召回率就和Faster R-CNN的9种相当
1.5 Direct locationprediction(直接位置预测)
使用anchor的第二个问题:模型不稳定,尤其是在早期迭代的时候。原因是
x=(tx∗wa)+xa
y=(ty∗wa)+ya
这个公式没有任何限制,使得无论在什么位置进行预测,任何anchor boxes可以在图像中任意一点结束,可能会出现anchor检测很远的目标box的情况,效率比较低,且不稳定。

1.6 Fine-Grained Features(细粒度特征)
添加了一个转移层(passthrough layer),这一层要把浅层特征图(分辨率为26 * 26,是底层分辨率4倍)连接到深层特征图。
前面26 * 26 *512的特征图使用按行和按列隔行采样的方法,就可以得到4个新的特征图,维度都是13 * 13 * 512,然后做concat操作,得到13 * 13 * 2048的特征图,将其拼接到后面的层,相当于做了一次特征融合,有利于检测小目标。?
1.7 Multi-Scale Training
目的是希望YOLOv2具有不同尺寸图片的鲁棒性。每经过10 epoch,就会随机选择新的图片尺寸。YOLO网络使用的降采样参数为32,那么就使用32的倍数进行池化{320,352,…,608}。
小尺寸图片检测中,YOLOv2成绩很好,输入为228 *228的时候,帧率达到90FPS,mAP几乎和Faster R-CNN的水准相同。
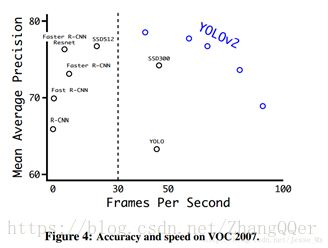
2 Faster
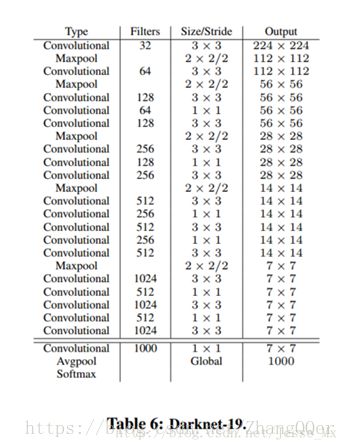
Darknet-19
YOLOv2使用了一个新的分类网络作为特征提取部分。使用Darknet-19在标准1000类的ImageNet上用随机梯度下降法训练了160次
Training for detection
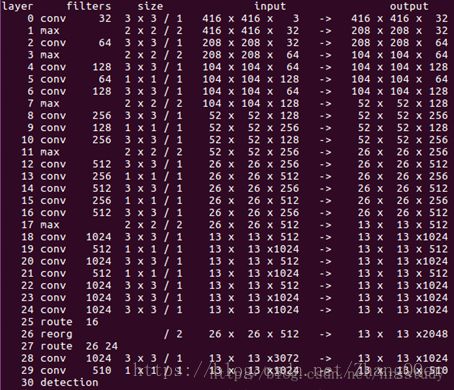
去掉了原网络最后一个卷积层,转而增加了三个3* 3 * 1024的卷积层,每一个后面跟一个1 * 1的卷积层,输出维度是检测所需的数量(B * (5 + C))。加入了passthrough layer,从最后一个输出为26 * 26 * 512的卷积层连接到新加入的三个卷积核尺寸为3 * 3的卷积层的第二层,使模型有了细粒度特征。
3 Stronger
提出了一种在分类数据集和检测数据集上联合训练的机制。
Hierarchical classification(层次式分类)
从ImageNet标签的WordNet(有向图)中构建了一个层次树结构(hierarchical tree)
创建层次树的步骤是:
1. 遍历ImageNet的所有视觉名词
2. 对每一个名词,在WordNet上找到从它所在位置到根节点(“physical object”)的路径。许多同义词集只有一条路径。所以先把这些路径加入层次树结构。
3. 然后迭代检查剩下的名词,得到路径,逐个加入到层次树。路径选择办法是:如果一个名词有两条路径到根节点,其中一条需要添加3个边到层次树,另一条仅需添加一条边,那么就选择添加边数少的那条路径。

预测每个节点的条件概率。例如: 在“terrier”节点会预测:

如果想求得特定节点的绝对概率,只需要沿着路径做连续乘积。例如 如果想知道一张图片是不是“Norfolkterrier ”需要计算:(分类时假设图片包含物体:Pr(physical object) = 1)

对于同义词(属于某个类别的节点),采用softmax方法进行分类:
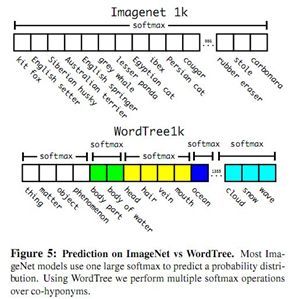
Dataset combination withWordTree
使用WordTree把多个数据集整合在一起。YOLO9000从COCO检测数据集中学习如何在图片中寻找物体,从ImageNet数据集中学习更广泛的物体分类。
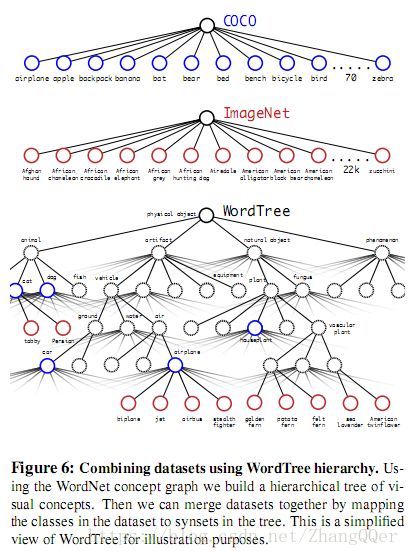
joint classification anddetection(联合训练分类和检测)
WordTree有9418个类别。采用基本YOLOv2的结构,anchor box数量由5调整为3用以限制输出大小。
当网络遇到一张检测图片就正常反向传播。其中对于分类损失只在当前及其路径以上对应的节点类别上进行反向传播。
当网络遇到一张分类图片仅反向传播分类损失。在该类别对应的所有bounding box中找到一个置信度最高的(作为预测坐标),同样只反向传播该类及其路径以上对应节点的类别损失。反向传播objectness损失基于如下假设:预测box与ground truth box的重叠度至少0.31IOU。
采用这种联合训练,YOLO9000从COCO检测数据集中学习如何在图片中寻找物体,从ImageNet数据集中学习更广泛的物体分类。
参考:
https://blog.csdn.net/jesse_mx/article/details/53925356
4.3 YOLOv3
article: YOLOv3: AnIncremental Improvement
作者: Joseph Redmon AliFarhadi
YOLO官网:YOLO: Real-Time Object Detection
论文链接:https://pjreddie.com/media/files/papers/YOLOv3.pdf
参考:http://www.sohu.com/a/226477679_129720
Bounding Box Prediction(边界框的预测)
1. yolov3的anchor boxes也是通过聚类的方法得到的。yolov3对每个boundingbox预测四个坐标值(tx, ty, tw, th)。对bounding box按如下方式预测:

2. 采用了sum of squared error loss(平方和距离误差损失)
3. 对每个bounding box通过逻辑回归预测一个物体的得分,如果预测的这个bounding box与真实的边框值大部分重合且比其他所有预测的要好,那么这个值就为1.如果overlap没有达到一个阈值(yolov3中这里设定的阈值是0.5),那么这个预测的bounding box将会被忽略,也就是会显示成没有损失值。
4. one bounding box prior for eachground truth
Class Prediction
1. 不使用softmax,而是逻辑回归independent logistic classifiers。使用softmax强加了一个假设,即每个盒子只有一个类别,通常情况并非如此,因为一些物体具有重叠的标签(例如,Woman and Person)。所以每个bounding box使用multilabel classification
2. 使用binary cross-entropy loss(对数损失)做分类预测。
Predictions Across Scales(跨尺度预测)
1. YOLOv3 用3种不同的尺度预测box
2. 使用类似FPN提取尺度的特征
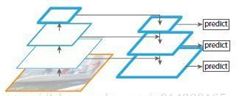
3. 仍然使用K-means选择了9个聚类(clusters)和3个尺度(scales),然后在整个尺度上均匀分割聚类,每个尺度有3个boxes。所以对于4个边界框偏移量,1个目标性预测和80个类别预测,张量为N×N×[3 *(4 + 1 + 80)]。
4. 从之前的两层中取得特征图,并将其上采样2倍。还从较早的网络中获取特征图(?),并使用element-wise addition将其与上采样特征进行合并。能够获得更有意义的语义信息。然后再添加几个卷积层来处理这个组合的特征图。
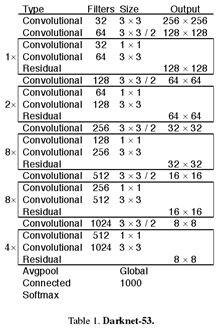
Feature Extractor
使用新网络(混合了YOLOv2,Darknet-19, and residual network)
相比Darknet-19,Res Net-101和 Res Net-152
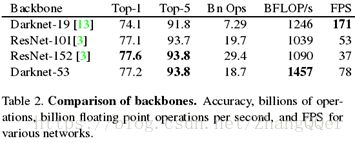
结果
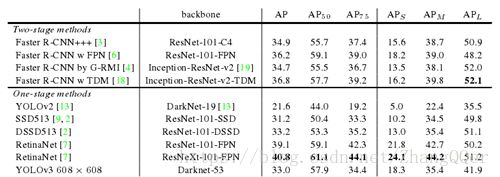
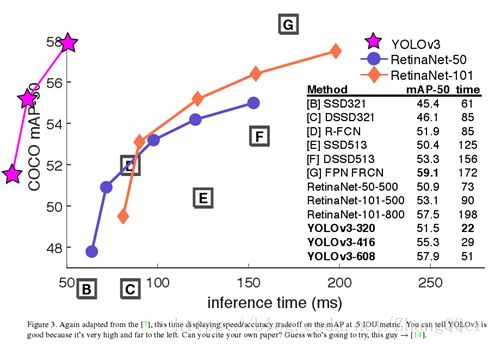
失败案例
Anchor box x,y offset predictions。我们尝试使用正常anchor box预测机制,这里你使用线性激活来预测x,y offset作为box的宽度或高度的倍数。我们发现这种方法降低了模型的稳定性,并且效果不佳。
Linear x,y predictions instead of logistic。我们尝试使用线性激活来直接预测x,y offeset 而不是逻辑激活。这导致mAP下降了几个点。
Focal loss。我们尝试使用focal loss。它使得mAp降低了2个点。YOLOv3对focal loss解决的问题可能已经很强大,因为它具有单独的对象预测和条件类别预测。因此,对于大多数例子来说,类别预测没有损失?或者其他的东西?我们并不完全确定。
Dual IOU thresholds and truth assignment。Faster R-CNN在训练期间使用两个IOU阈值。如果一个预测与groundtruth重叠达到0.7,它就像是一个正样本,如果达到0.3-0.7,它被忽略,如果小于0.3,这是一个负样本的例子。我们尝试了类似的策略,但无法取得好成绩。
我们非常喜欢我们目前的表述,似乎至少在局部最佳状态。有些技术可能最终会产生好的结果,也许他们只是需要一些调整来稳定训练。
创新点
Darknet-53
使用金字塔网络
用逻辑回归替代softmax作为分类器
-----------------------------------我是分割线--------------------------------------------
目前就看了这些,里面的“?”是我还没有太看懂的部分