TensorFlow实现经典深度学习网络(5):TensorFlow实现自然语言处理基础网络Word2Vec
TensorFlow实现经典深度学习网络(5):TensorFlow实现自然语言处理
基础网络Word2Vec
循环神经网络RNN是在自然语言处理NLP领域最常使用的神经网络结构,和卷积神经网络在图像识别领域的地位相似,影响深远。而Word2Vec则是将语言中的字词转化为计算机可以理解的稠密向量Dense Vector,进而可以做其他自然语言处理任务,比如文本分类、词性标注、机器翻译等。有时,Word2Vec也称Word Embedings,中文也有很多叫法,比较普遍的是“词向量”或“词嵌入”,是一个可以将语言中字词转为向量形式表达的模型,是一种计算非常高效,可以从原始语料中学习词空间向量的预测模型。
随着21世纪处理技术的不断发展,人们逐渐开始从原始的词向量稀疏表示法过渡到现在的低维空间中的密集表示。自然语言处理技术在Word2Vec出现之前,通常将字词转为离散的单独的符号,这没有提供任何的关联信息,没有考虑到字词间可能存在的关系。用稀疏表示法在解决实际问题时经常会遇到维数灾难,并且语义信息无法表示,无法揭示word之间的潜在联系;而且将字词存储为悉数向量的话,通常需要更多的数据来训练,效率比较低,计算也非常麻烦。而采用低维空间表示法,不但解决了维数灾难问题,并且挖掘了word之间的关联属性,从而提高了向量语义上的准确度。
Word2Vec主要分为CBOW和Skip-Gram两种模式,其中CBOW是从原始语句推测目标单词;而Skip-Gram则正好相反,它是从目标字词推测出原始语句,其中CBOW对小型数据比较合适,而Skip-Gram在大型语料中表现更好。本文将主要使用Skip-Gram模式的Word2Vec。在准备工作就绪后,我们就可以搭建网络了。这里因为要从网络下载数据,因此需要的依赖库比较多。以下代码是根据本人对Word2Vec网络的理解和现有资源(《TensorFlow实战》、TensorFlow的开源实现等)整理而成,并根据自己认识添加了注释。代码注释若有错误请指正。
# -*- coding: utf-8 -*-
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
# TensorFlow实现Word2Vec训练
# 载入依赖库
import collections
import math
import os
import random
import zipfile
import numpy as np
import urllib
import tensorflow as tf
# 定义下载文本数据的函数
# 若已下载文件则跳过
url = 'http://mattmahoney.net/dc/'
def maybe_download(filename, expected_bytes):
if not os.path.exists(filename):
filename, _ = urllib.request.urlretrieve(url + filename, filename)
statinfo = os.stat(filename)
if statinfo.st_size == expected_bytes:
print('Found and verified', filename)
else:
print(statinfo.st_size)
raise Exception(
'Failed to verify ' + filename + '. Can you get to it with a browser?')
return filename
filename = maybe_download('text8.zip', 31344016)
# 解压下载的压缩文件
# 将数据转成单词的列表
def read_data(filename):
with zipfile.ZipFile(filename) as f:
data = tf.compat.as_str(f.read(f.namelist()[0])).split()
return data
words = read_data(filename)
print('Data size', len(words))
# 创建vocabulary词汇表
# 创建dict
vocabulary_size = 50000
def build_dataset(words):
count = [['UNK', -1]]
count.extend(collections.Counter(words).most_common(vocabulary_size - 1))
dictionary = dict()
for word, _ in count:
dictionary[word] = len(dictionary)
data = list()
unk_count = 0
for word in words:
if word in dictionary:
index = dictionary[word]
else:
index = 0
unk_count += 1
data.append(index)
count[0][1] = unk_count
reverse_dictionary = dict(zip(dictionary.values(), dictionary.keys()))
return data, count, dictionary, reverse_dictionary
data, count, dictionary, reverse_dictionary = build_dataset(words)
# 删除原始单词列表,打印最高频出现的词汇及其数量
del words
print('Most common words (+UNK)', count[:5])
print('Sample data', data[:10], [reverse_dictionary[i] for i in data[:10]])
# 生成Word2Vec训练样本
data_index = 0
def generate_batch(batch_size, num_skips, skip_window):
global data_index
assert batch_size % num_skips == 0
assert num_skips <= 2 * skip_window
batch = np.ndarray(shape=(batch_size), dtype=np.int32)
labels = np.ndarray(shape=(batch_size, 1), dtype=np.int32)
span = 2 * skip_window + 1
buffer = collections.deque(maxlen=span)
# 从序号data_index开始,将span个单词读入buffer作为初始值
for _ in range(span):
buffer.append(data[data_index])
data_index = (data_index + 1) % len(data)
for i in range(batch_size // num_skips):
target = skip_window
targets_to_avoid = [ skip_window ]
for j in range(num_skips):
while target in targets_to_avoid:
target = random.randint(0, span - 1)
targets_to_avoid.append(target)
batch[i * num_skips + j] = buffer[skip_window]
labels[i * num_skips + j, 0] = buffer[target]
buffer.append(data[data_index])
data_index = (data_index + 1) % len(data)
return batch, labels
# 调用generate_batch函数简单测试功能
batch, labels = generate_batch(batch_size=8, num_skips=2, skip_window=1)
for i in range(8):
print(batch[i], reverse_dictionary[batch[i]],
'->', labels[i, 0], reverse_dictionary[labels[i, 0]])
# 创建训练skip-gram模型
batch_size = 128
embedding_size = 128
skip_window = 1
num_skips = 2
valid_size = 16 # 用来抽取的验证单词数
valid_window = 100 # 验证单词只从频数最高的100个单词中抽取
valid_examples = np.random.choice(valid_window, valid_size, replace=False)
num_sampled = 64 # 训练时用来做负样本的噪声单词数量
# 定义Skip-Gram Word2Vec模型的网络结构
graph = tf.Graph()
with graph.as_default():
# 输入数据
train_inputs = tf.placeholder(tf.int32, shape=[batch_size])
train_labels = tf.placeholder(tf.int32, shape=[batch_size, 1])
valid_dataset = tf.constant(valid_examples, dtype=tf.int32)
# 限定所有计算在CPU上执行,因一些计算操作在GPU上可能还没有实现
with tf.device('/cpu:0'):
# 查找对应的输入
embeddings = tf.Variable(
tf.random_uniform([vocabulary_size, embedding_size], -1.0, 1.0))
embed = tf.nn.embedding_lookup(embeddings, train_inputs)
# 使用NCE Loss作为训练优化目标,初始化
nce_weights = tf.Variable(
tf.truncated_normal([vocabulary_size, embedding_size],
stddev=1.0 / math.sqrt(embedding_size)))
nce_biases = tf.Variable(tf.zeros([vocabulary_size]))
# 计算词向量embedding在训练数据上的loss,并汇总
loss = tf.reduce_mean(
tf.nn.nce_loss(weights=nce_weights,
biases=nce_biases,
labels=train_labels,
inputs=embed,
num_sampled=num_sampled,
num_classes=vocabulary_size))
# 定义优化器为SGD,且学习率为1.0
optimizer = tf.train.GradientDescentOptimizer(1.0).minimize(loss)
# 计算验证单词的嵌入向量与词表中所有单词的相似性
norm = tf.sqrt(tf.reduce_sum(tf.square(embeddings), 1, keep_dims=True))
normalized_embeddings = embeddings / norm
valid_embeddings = tf.nn.embedding_lookup(
normalized_embeddings, valid_dataset)
similarity = tf.matmul(
valid_embeddings, normalized_embeddings, transpose_b=True)
# 初始化所有模型参数
init = tf.global_variables_initializer()
# 训练,定义迭代最大次数为10万次
num_steps = 100001
with tf.Session(graph=graph) as session:
init.run()
print("Initialized")
average_loss = 0
for step in range(num_steps):
batch_inputs, batch_labels = generate_batch(
batch_size, num_skips, skip_window)
feed_dict = {train_inputs : batch_inputs, train_labels : batch_labels}
# 使用session.run()执行一次优化器运算和损失计算
# 将此步训练的loss累累积到average_loss
_, loss_val = session.run([optimizer, loss], feed_dict=feed_dict)
average_loss += loss_val
# 每2000次循环,计算并显示loss
if step % 2000 == 0:
if step > 0:
average_loss /= 2000
print("Average loss at step ", step, ": ", average_loss)
average_loss = 0
# 每10000次循环,计算一次验证单词与全部单词的相似度,并显示8个最相似的单词
if step % 10000 == 0:
sim = similarity.eval()
for i in range(valid_size):
valid_word = reverse_dictionary[valid_examples[i]]
top_k = 8
nearest = (-sim[i, :]).argsort()[1:top_k+1]
log_str = "Nearest to %s:" % valid_word
for k in range(top_k):
close_word = reverse_dictionary[nearest[k]]
log_str = "%s %s," % (log_str, close_word)
print(log_str)
final_embeddings = normalized_embeddings.eval()
# 定义可视化Word2Vec效果函数
def plot_with_labels(low_dim_embs, labels, filename='tsne.png'):
assert low_dim_embs.shape[0] >= len(labels), "More labels than embeddings"
plt.figure(figsize=(18, 18))
for i, label in enumerate(labels):
x, y = low_dim_embs[i, :]
plt.scatter(x, y) # 显示散点图
plt.annotate(label,
xy=(x, y),
xytext=(5, 2),
textcoords='offset points',
ha='right',
va='bottom')
plt.savefig(filename) # 保存图片到本地
# 使用sklearn.manifold.TSNE实现降维,再进行显示
try:
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
tsne = TSNE(perplexity=30, n_components=2, init='pca', n_iter=5000)
plot_only = 200
low_dim_embs = tsne.fit_transform(final_embeddings[:plot_only,:])
labels = [reverse_dictionary[i] for i in range(plot_only)]
plot_with_labels(low_dim_embs, labels)
except ImportError:
print("Please install sklearn, matplotlib, and scipy to visualize embeddings.")
Found and verified text8.zip
Data size 17005207
Most common words (+UNK) [['UNK', 418391], ('the', 1061396), ('of', 593677), ('and', 416629), ('one', 411764)]
Sample data [5236, 3081, 12, 6, 195, 2, 3137, 46, 59, 156] ['anarchism', 'originated', 'as', 'a', 'term', 'of', 'abuse', 'first', 'used', 'against']
3081 originated -> 5236 anarchism
3081 originated -> 12 as
12 as -> 3081 originated
12 as -> 6 a
6 a -> 12 as
6 a -> 195 term
195 term -> 6 a
195 term -> 2 of
Initialized
Average loss at step 0 : 305.99029541
Nearest to state: hring, compel, freebsd, accolades, wollheim, otherworldly, abdel, vigorous,
Nearest to d: memorial, magical, maul, turns, nanjing, renn, hutu, marmite,
Nearest to between: persona, currencies, weird, hydrodynamics, liturgy, sieve, microcomputer, dir,
Nearest to three: wembley, korn, perpendicularly, avery, alban, blondie, corrosion, gotland,
Nearest to in: tara, flown, boomerangs, bets, lammas, mishnayot, marysville, denotation,
Nearest to if: sexes, robes, jewish, conversation, outer, murmur, biopolymers, lanes,
Nearest to however: footballers, parliamentarian, guaranteeing, discretion, thief, faber, elgar, coursing,
Nearest to his: twa, parakeet, ostwald, booker, meme, localized, seam, ecclesiastica,
Nearest to nine: lat, leon, confederations, demolish, bulldogs, timepieces, disaffection, leonid,
Nearest to time: reelected, blyth, chifley, nosed, elaborates, coasts, discipleship, jacob,
Nearest to s: rages, abacus, skipping, aforementioned, thames, mummified, exclude, latins,
Nearest to with: silmarillion, hospitable, burundi, enters, grandmaster, daw, bytecode, eleusinian,
Nearest to often: within, reorganisation, kievan, cree, rattus, belle, unido, renouncing,
Nearest to people: cathal, psycho, barrels, gtb, guarded, kronecker, triadic, inventories,
Nearest to states: thickened, diphthongs, sync, readers, mantras, inordinate, melee, unsaturated,
Nearest to new: dropouts, squares, befitting, capability, shall, unenforceable, delusion, dissociation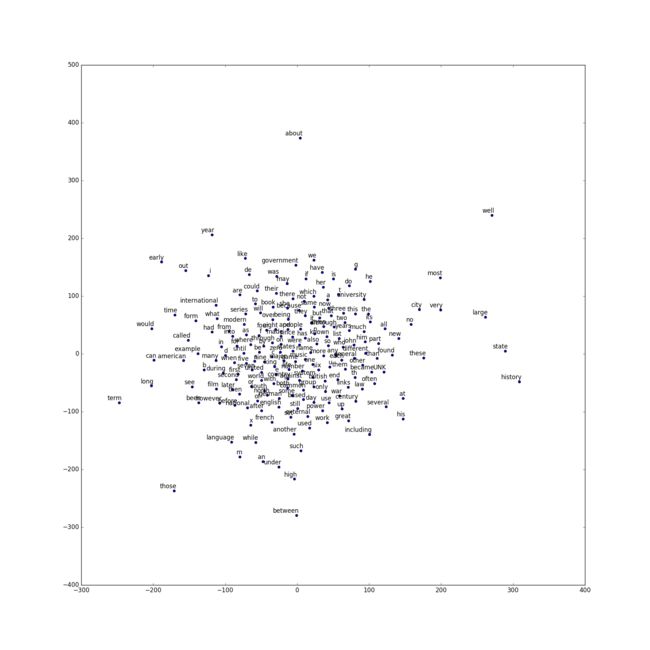
至此,Word2Vec的基本原理和TensorFlow实现Word2Vec的工作就完成了,并取得了非常好的效果。
在后续工作中,我将继续为大家展现TensorFlow和深度学习网络带来的无尽乐趣,我将和大家一起探讨深度学习的奥秘。当然,如果你感兴趣,我的Weibo将与你一起分享最前沿的人工智能、机器学习、深度学习与计算机视觉方面的技术。