requests爬取微博
微博地址:蒋方舟微博
用到技术:requests+pyquery
分析页面
通过对比url发现,似乎只需要 改变page就能完成翻页

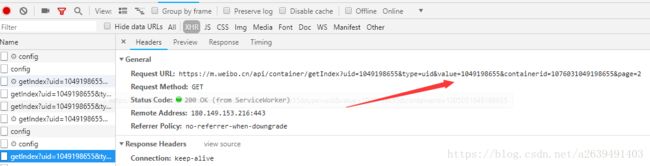
尝试把page=3放上去得到了如下内容,json序列化

点开调试工具的preview就能看到json反序列化


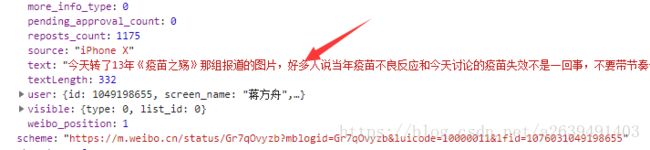
得来全不费工夫,里面包含了我们需要的所有内容
接着我们需要构造URL,requests中自带一个params()方法,能够拼接url

构造URL
url需要带的都在Query String Parameters中,并且需要把headers带上,在headers中要告诉requests这是个ajax。防止被发现是爬虫把UA和cookie带上。
headers = {
'X-Requested-With': 'XMLHttpRequest', #告诉爬虫这是个ajax
'Host': 'm.weibo.cn',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.75 Safari/537.36' ,
'Cookie': '_T_WM=8d449523b94f82f4d802ff17c007d9e4; WEIBOCN_FROM=1110106030; ALF=1535700259; SCF=AvbLZWV0dg7vKvS_Bj3z2Ib9euGzCJyp9GGmpPLRDA3icmj4eGE1ln6Ac-Am0mqUskHocbTfcnEKdVn38KkQ-Jg.; SUB=_2A252ZRB0DeRhGeBL7lUQ8yjOzTmIHXVVqbA8rDV6PUNbktANLULnkW1NRu9NVF2gu03sOjAuC_gQ3rcDTGvnLlk2; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9WW3H-n4HdpyaWP-dHOmFR-g5JpX5KzhUgL.FoqfSKMpe0qESo-2dJLoIpWhIsLoIc_DdspLMoqXSK5X; SUHB=0h1Z4VOSSzYtHi; SSOLoginState=1533108260; MLOGIN=1; M_WEIBOCN_PARAMS=luicode%3D20000174%26lfid%3D102803%26uicode%3D20000174'
}
params = {
'containerid': ' 2304131049198655_-_WEIBO_SECOND_PROFILE_WEIBO',
'page_type': '03',
'page': page,
}
url = 'https://m.weibo.cn/api/container/getIndex?'
#通过params函数将URL补全
response = requests.get(url, params=params, headers=headers)获取id,内容,点赞数,回复数,转发数
items = html.get('data').get('cards')
for i in items:
i = dict(i).get('mblog')
# 有的是没有内容的所以需要判断是否为字典类型
if isinstance(i,dict):
yield{
'id':i.get('id'),
'text':pq(i.get('text')).text(), #通过pyquery将HTML标签去除
'点赞数':i.get('attitudes_count'),
'回复数':i.get('comments_count'),
'转发数':i.get('reposts_count')完整代码
import requests,re,json
from requests.exceptions import RequestException
from pyquery import PyQuery as pq
def get_one_page(page):
headers = {
'X-Requested-With': 'XMLHttpRequest', #告诉爬虫这是个ajax
'Host': 'm.weibo.cn',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.75 Safari/537.36' ,
'Cookie': '_T_WM=8d449523b94f82f4d802ff17c007d9e4; WEIBOCN_FROM=1110106030; ALF=1535700259; SCF=AvbLZWV0dg7vKvS_Bj3z2Ib9euGzCJyp9GGmpPLRDA3icmj4eGE1ln6Ac-Am0mqUskHocbTfcnEKdVn38KkQ-Jg.; SUB=_2A252ZRB0DeRhGeBL7lUQ8yjOzTmIHXVVqbA8rDV6PUNbktANLULnkW1NRu9NVF2gu03sOjAuC_gQ3rcDTGvnLlk2; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9WW3H-n4HdpyaWP-dHOmFR-g5JpX5KzhUgL.FoqfSKMpe0qESo-2dJLoIpWhIsLoIc_DdspLMoqXSK5X; SUHB=0h1Z4VOSSzYtHi; SSOLoginState=1533108260; MLOGIN=1; M_WEIBOCN_PARAMS=luicode%3D20000174%26lfid%3D102803%26uicode%3D20000174'
}
params = {
'containerid': ' 2304131049198655_-_WEIBO_SECOND_PROFILE_WEIBO',
'page_type': '03',
'page': page,
}
url = 'https://m.weibo.cn/api/container/getIndex?'
#通过params函数将URL补全
response = requests.get(url, params=params, headers=headers)
try:
if response.status_code==200:
return response.json()
return None
except RequestException:
return '索引页错误'
def parse_one_page(html):
items = html.get('data').get('cards')
for i in items:
i = dict(i).get('mblog')
# 有的是没有内容的所以需要判断是否为字典类型
if isinstance(i,dict):
yield{
'id':i.get('id'),
'text':pq(i.get('text')).text(), #通过pyquery将HTML标签去除
'点赞数':i.get('attitudes_count'),
'回复数':i.get('comments_count'),
'转发数':i.get('reposts_count')
}
def main():
#只爬取10页的内容
for sum in range(1,11):
page = sum
html = get_one_page(page)
i= parse_one_page(html)
with open('蒋方舟.text', 'a',encoding='utf8')as f:
#返回过来的i是个生成器因此需要迭代出来
for k in i:
print(k)
f.write(json.dumps(k,ensure_ascii=False)+'\n')
if __name__ == '__main__':
main()