图卷积神经网络(Graph Convolutional Network, GCN)
文章目录
- 从谱聚类说起
- RatioCut 切图聚类
- GCN
- 从傅里叶级数到傅里叶变换
- 傅里叶级数的直观意义
- 傅里叶变换推导
- Signal Processing on Graph
- 图上的傅里叶变换
- 参考资料
从谱聚类说起
谱聚类(spectral clustering)是一种针对图结构的聚类方法,它跟其他聚类算法的区别在于,他将每个点都看作是一个图结构上的点,所以,判断两个点是否属于同一类的依据就是,两个点在图结构上是否有边相连,可以是直接相连也可以是间接相连。举个例子,一个紧凑的子图(如完全图)一定比一个松散的子图更容易聚成一类。
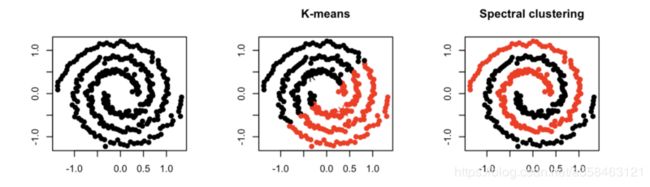
那谱聚类为什么叫谱而不是图聚类呢?这个spectral是什么东西?我们知道一个图是可以用一个邻接矩阵A来表示的。而矩阵的谱(spectral)就是指矩阵的特征值,那么这个特征值跟图的矩阵到底有什么深刻的联系呢?
那么首先,图的聚类是什么?我们可以将聚类问题简化为一个分割问题,如果图的结点被分割成A,B这两个集合,那么我们自然是希望在集合中的结点的相互连接更加紧密比如团,而使得子图之间更加尽可能松散。
为了建立这个联系,我们构造一个laplace matrix:
L = D − A L=D-A L=D−A
D是一个对角矩阵,每个对角元素 D i i \displaystyle D_{ii} Dii表示第i个结点的度。A则是这个图邻接矩阵。为什么要这样去构造一个矩阵呢?因为研究图的一些性质的时候,我们常常用到一个类似于下式的目标函数:
x T M x = ∑ { u , v } ∈ E ( x u − x v ) 2 \mathbf{x^{T}} M\mathbf{x} =\sum _{\{u,v\} \in E}( x_{u} -x_{v})^{2} xTMx={u,v}∈E∑(xu−xv)2
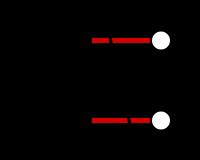
这个目标函数可以定义图上的很多问题,比如最小图分割问题,就是要找到一个方法将图分成两块的使得切割的边最少(如果边有权重那就是切割的权重最小)。如下图,你不能找到一个比切两条边更少的分割方法了。
而这个优化问题其实等价于当 x ∈ { 0 , 1 } V \displaystyle x\in \{0,1\}^{V} x∈{0,1}V的时候:
min ∑ { u , v } ∈ E ( x u − x v ) 2 = ∑ u ∈ A , v ̸ ∈ A ‾ ( 1 − 0 ) 2 + ∑ u ∈ A , v ̸ ∈ A ‾ ( 0 − 1 ) 2 = 2 c u t ( A , A ‾ ) \min\sum _{\{u,v\} \in E}( x_{u} -x_{v})^{2} =\sum _{u\in A,v\not{\in }\overline{A}}( 1-0)^{2} +\sum _{u\in A,v\not{\in }\overline{A}}( 0-1)^{2} =2cut\left( A,\overline{A}\right) min{u,v}∈E∑(xu−xv)2=u∈A,v̸∈A∑(1−0)2+u∈A,v̸∈A∑(0−1)2=2cut(A,A)
而这个方程不正是一个二次型吗。为了让二次型得到这个结果。我们发现,当 M = d I − A = D − A \displaystyle M=dI-A=D-A M=dI−A=D−A的时候就可以了。验证一下:
x T ( d I − A ) x = d x T x − x T A x = ∑ v d x v 2 − 2 ∑ { u , v } ∈ E x u x v = ∑ { u , v } ∈ E ( x u − x v ) 2 \mathbf{x}^{T}( dI-A)\mathbf{x} =d\mathbf{x}^{T}\mathbf{x} -\mathbf{x}^{T} A\mathbf{x} =\sum _{v} dx^{2}_{v} -2\sum _{\{u,v\} \in E} x_{u} x_{v} =\sum _{\{u,v\} \in E}( x_{u} -x_{v})^{2} xT(dI−A)x=dxTx−xTAx=v∑dxv2−2{u,v}∈E∑xuxv={u,v}∈E∑(xu−xv)2
此外,当A不是邻接矩阵而是权重矩阵W的时候,于是d就从度推广到权重的求和,那么这个公式还可以推广为:
x T L x = x T ( d I − W ) x = ∑ i , j ω i j ( x u − x v ) 2 x^{T} Lx\mathbf{=x}^{T}( dI-W)\mathbf{x} =\sum _{i,j} \omega _{ij}( x_{u} -x_{v})^{2} xTLx=xT(dI−W)x=i,j∑ωij(xu−xv)2
RatioCut 切图聚类
现在,我们可以尝试将这个目标函数与Ratio切图聚类的目标函数建立起联系,建立联系有什么好处呢?好处就是如果我们发现切图的目标函数是这个二次型,那么我们只要优化这个二次型,不就可以用连续的方法来解决一个离散的问题吗?
RatioCut考虑最小化 c u t ( A 1 , A 2 , . . . , A k ) \displaystyle cut( A_{1} ,A_{2} ,...,A_{k}) cut(A1,A2,...,Ak),同时最大化每个子图的个数即:
R a t i o C u t ( A 1 , A 2 , . . . A k ) = 1 2 ∑ i = 1 k c u t ( A i , A ‾ i ) ∣ A i ∣ RatioCut(A_{1} ,A_{2} ,...A_{k} )=\frac{1}{2}\sum\limits ^{k}_{i=1}\frac{cut(A_{i} ,\overline{A}_{i} )}{|A_{i} |} RatioCut(A1,A2,...Ak)=21i=1∑k∣Ai∣cut(Ai,Ai)
其中 c u t ( A i , A ‾ i ) \displaystyle cut(A_{i} ,\overline{A}_{i} ) cut(Ai,Ai)表示两个子图之间的距离(两个子图结点之间距离的求和):
c u t ( A i , A ‾ i ) = ∑ i ∈ A , j ∈ A ‾ i w i j cut(A_{i} ,\overline{A}_{i} )=\sum\limits _{i\in A,j\in \overline{A}_{i}} w_{ij} cut(Ai,Ai)=i∈A,j∈Ai∑wij
这里公式里的是A与A的补集的切图权重(切的边权重的求和),也就是说我们希望子图A与其余的图分离的代价最小,比如我只要切掉一条微不足道的边就能将两个复杂的图(比如两个团)分离开,那么就可以认为这是一个好的切割。
现在我们仿照上面的x,将其推广到多个簇,于是我们用一个指示函数(one-hot)来表达每个结点属于哪个子图,这样就将切割问题跟二次型建立起了联系
我们引入指示向量 h j ∈ { h 1 , h 2 , . . h k } j = 1 , 2 , . . . k h_{j} \in \{h_{1} ,h_{2} ,..h_{k} \}\ j=1,2,...k hj∈{h1,h2,..hk} j=1,2,...k,表示有k个子图,对于任意一个向量 h j \displaystyle h_{j} hj, 它是一个|V|-维向量(|V|为结点数,用来标记哪个结点属于哪个子图,类似于one-hot),我们定义 h i j \displaystyle h_{ij} hij为:
h i j = { 0 v j ∉ A i 1 ∣ A i ∣ v j ∈ A i h_{ij} =\begin{cases} 0 & v_{j} \notin A_{i}\\ \frac{1}{\sqrt{|A_{i} |}} & v_{j} \in A_{i} \end{cases} hij={0∣Ai∣1vj∈/Aivj∈Ai
那么,对于每一个子图都有:
h i T L h i = 1 2 ∑ m = 1 ∣ V ∣ ∑ n = 1 ∣ V ∣ w m n ( h i m − h i n ) 2 = 1 2 ( ∑ m ∈ A i , n ∉ A i w m n ( 1 ∣ A i ∣ − 0 ) 2 + ∑ m ∉ A i , n ∈ A i w m n ( 0 − 1 ∣ A i ∣ ) 2 = 1 2 ( ∑ m ∈ A i , n ∉ A i w m n 1 ∣ A i ∣ + ∑ m ∉ A i , n ∈ A i w m n 1 ∣ A i ∣ = 1 2 ( c u t ( A i , A ‾ i ) 1 ∣ A i ∣ + c u t ( A ‾ i , A i ) 1 ∣ A i ∣ ) = c u t ( A i , A ‾ i ) ∣ A i ∣ \begin{aligned} h^{T}_{i} Lh_{i} & =\frac{1}{2}\sum\limits ^{|V|}_{m=1}\sum\limits ^{|V|}_{n=1} w_{mn} (h_{im} -h_{in} )^{2}\\ & =\frac{1}{2} (\sum\limits _{m\in A_{i} ,n\notin A_{i}} w_{mn} (\frac{1}{\sqrt{|A_{i} |}} -0)^{2} +\sum\limits _{m\notin A_{i} ,n\in A_{i}} w_{mn} (0-\frac{1}{\sqrt{|A_{i} |}} )^{2}\\ & =\frac{1}{2} (\sum\limits _{m\in A_{i} ,n\notin A_{i}} w_{mn}\frac{1}{|A_{i} |} +\sum\limits _{m\notin A_{i} ,n\in A_{i}} w_{mn}\frac{1}{|A_{i} |}\\ & =\frac{1}{2} (cut(A_{i} ,\overline{A}_{i} )\frac{1}{|A_{i} |} +cut(\overline{A}_{i} ,A_{i} )\frac{1}{|A_{i} |} )\\ & =\frac{cut(A_{i} ,\overline{A}_{i} )}{|A_{i} |} \end{aligned} hiTLhi=21m=1∑∣V∣n=1∑∣V∣wmn(him−hin)2=21(m∈Ai,n∈/Ai∑wmn(∣Ai∣1−0)2+m∈/Ai,n∈Ai∑wmn(0−∣Ai∣1)2=21(m∈Ai,n∈/Ai∑wmn∣Ai∣1+m∈/Ai,n∈Ai∑wmn∣Ai∣1=21(cut(Ai,Ai)∣Ai∣1+cut(Ai,Ai)∣Ai∣1)=∣Ai∣cut(Ai,Ai)
其原理在于,因为当 m ∈ A i , n ∉ A i \displaystyle m\in A_{i} ,n\notin A_{i} m∈Ai,n∈/Ai时,因为结点 v m \displaystyle v_{m} vm属于子图i,结点 v n \displaystyle v_{n} vn不属于子图i,于是 h i m − h i n = 1 ∣ A i ∣ − 0 \displaystyle h_{im} -h_{in} =\frac{1}{\sqrt{|A_{i} |}} -0 him−hin=∣Ai∣1−0,同理,当 v m \displaystyle v_{m} vm, v n \displaystyle v_{n} vn都属于子图的时候 h i m − h i n = 1 ∣ A i ∣ − 1 ∣ A i ∣ = 0 \displaystyle h_{im} -h_{in} =\frac{1}{\sqrt{|A_{i} |}} -\frac{1}{\sqrt{|A_{i} |}} =0 him−hin=∣Ai∣1−∣Ai∣1=0。
上述是第i个子图的式子,我们将k个子图的h合并成一个H,于是式子变成:
R a t i o C u t ( A 1 , A 2 , . . . A k ) = ∑ i = 1 k h i T L h i = ∑ i = 1 k ( H T L H ) i i = t r ( H T L H ) s . t . h i T h i = 1 , i = 1 , 2 , . . . , k RatioCut(A_{1} ,A_{2} ,...A_{k} )=\sum\limits ^{k}_{i=1} h^{T}_{i} Lh_{i} =\sum\limits ^{k}_{i=1} (H^{T} LH)_{ii} =tr(H^{T} LH)\\ s.t.\ h^{T}_{i} h_{i} =1,\ i=1,2,...,k RatioCut(A1,A2,...Ak)=i=1∑khiTLhi=i=1∑k(HTLH)ii=tr(HTLH)s.t. hiThi=1, i=1,2,...,k
也就是说Ratiocut本质上就是在最小化 t r ( H T L H ) \displaystyle tr(H^{T} LH) tr(HTLH)这个东西。那么怎么优化呢?注意到每个 h i \displaystyle h_{i} hi都是相互正交的,因为一个结点不能同时属于多个类别,因此H是一个正交矩阵,又因为L是一个对称矩阵,那么可以证明,H是L的特征向量的时候,恰好是这个优化问题的解,我们需要要找到那么特征值比较小的特征向量,就可以找到一种代价最小的切割方法。我们可以来证明一下,特征向量恰好是他的极值:
∇ h ( h T L h − λ ( 1 − h T h ) ) = ∇ h t r ( h T L h − λ ( 1 − h T h ) ) = ∇ h t r ( h T L h ) − λ ∇ h t r ( h h T ) = ∇ u t r ( u u T L ) − λ ∇ h t r ( h E h T E ) = ∇ u t r ( u E u T L ) − λ ∇ h t r ( h E h T E ) = L u + L T u − λ ( h + h ) = 2 L u − 2 λ h = 0 ⟹ L u = λ h \begin{aligned} \nabla _{h}\left( h^{T} Lh-\lambda \left( 1-h^{T} h\right)\right) & =\nabla _{h} tr\left( h^{T} Lh-\lambda \left( 1-h^{T} h\right)\right)\\ & =\nabla _{h} tr\left( h^{T} Lh\right) -\lambda \nabla _{h} tr\left( hh^{T}\right)\\ & =\nabla _{u} tr(uu^{T} L)-\lambda \nabla _{h} tr(hEh^{T} E)\\ & =\nabla _{u} tr(uEu^{T} L)-\lambda \nabla _{h} tr(hEh^{T} E)\\ & =Lu+L^{T} u-\lambda ( h+h)\\ & =2Lu-2\lambda h\\ & =0\\ & \Longrightarrow Lu=\lambda h \end{aligned} ∇h(hTLh−λ(1−hTh))=∇htr(hTLh−λ(1−hTh))=∇htr(hTLh)−λ∇htr(hhT)=∇utr(uuTL)−λ∇htr(hEhTE)=∇utr(uEuTL)−λ∇htr(hEhTE)=Lu+LTu−λ(h+h)=2Lu−2λh=0⟹Lu=λh
这里用到了一些最优化求导常用公式技巧,其实这个推导跟PCA是一样的,只不过PCA找的是最大特征值(PCA中L是协方差矩阵,目标是找到一个向量最大化方差),这里是找最小特征值,我们目标是找到一个向量最小化这个二次型矩阵。
最后,通过找到L的最小的k个特征值,可以得到对应的k个特征向量,这k个特征向量组成一个nxk维度的矩阵,即为我们的H。一般需要对H矩阵按行做标准化,即
h i j ∗ = h i j ( ∑ t = 1 k h i t 2 ) 1 / 2 h^{*}_{ij} =\frac{h_{ij}}{(\sum\limits ^{k}_{t=1} h^{2}_{it} )^{1/2}} hij∗=(t=1∑khit2)1/2hij
由于我们在使用维度规约的时候损失了少量信息,导致得到的优化后的指示向量h对应的H不能完全指示各样本的归属(因为是连续的优化,不可能恰到得到一个one-hot向量),因此一般在得到nxk维度的矩阵H后还需要对每一行进行一次传统的聚类,比如使用K-Means聚类,从而得到一个真正的one-hot指示向量。
所以谱聚类的流程可以总结如下:
- 计算标准化后的lapace矩阵
- 求解标准化lapace矩阵的特征值与特征向量
- 取最小的k1个特征向量,及其对应的特征向量f
- 将f排列成一个n*k1的矩阵,对矩阵的每一行进行标准化,然后使用k means聚类,聚类数为k2
- 得到k2个簇,就是对应k2个划分。
GCN
图卷积神经网络,顾名思义就是在图上使用卷积运算,然而图上的卷积运算是什么东西?为了解决这个问题题,我们可以利用图上的傅里叶变换,再使用卷积定理,这样就可以通过两个傅里叶变换的乘积来表示这个卷积的操作。那么为了介绍图上的傅里叶变换,我接来下从最原始的傅里叶级数开始讲起。
从傅里叶级数到傅里叶变换
此部分主要参考了马同学的两篇文章:
- 从傅立叶级数到傅立叶变换
- 如何理解傅立叶级数公式?
傅里叶级数的直观意义
如下图,傅里叶级数其实就是用一组sin,cos的函数来逼近一个周期函数,那么每个sin,cos函数就是一组基,这组基上的系数就是频域,你会发现随着频域越来越多(基越来越多),函数的拟合就越准确。

傅里叶变换推导
要讲傅里叶变换的推导,我们要先从傅里叶级数讲起,考虑一周期等于T,现定义于区间[-T/2,T/2]的周期函数f(x),傅里叶级数近似的表达式如下:
f ( x ) = C + ∑ n = 1 ∞ ( a n c o s ( 2 π n T x ) + b n s i n ( 2 π n T x ) ) , C ∈ R {\displaystyle f(x)=C+\sum ^{\infty }_{n=1}\left( a_{n} cos(\frac{2\pi n}{T} x)+b_{n} sin(\frac{2\pi n}{T} x)\right) ,C\in \mathbb{R}} f(x)=C+n=1∑∞(ancos(T2πnx)+bnsin(T2πnx)),C∈R
利用偶函数*奇函数=奇函数的性质可以计算出 a k \displaystyle a_{k} ak与 b k \displaystyle b_{k} bk
a n = ∫ − T / 2 T / 2 f ( x ) c o s ( 2 π n T x ) d x ∫ − T / 2 T / 2 c o s 2 ( 2 π n T x ) d x = 2 T ∫ − T / 2 T / 2 f ( x ) c o s ( 2 π n T x ) d x b n = ∫ − T / 2 T / 2 f ( x ) s i n ( 2 π n T x ) d x ∫ − T / 2 T / 2 s i n 2 ( 2 π n T x ) d x = 2 T ∫ − T / 2 T / 2 f ( x ) s i n ( 2 π n T x ) d x a_{n} =\frac{\int ^{T/2}_{-T/2} f(x)cos(\frac{2\pi n}{T} x)dx}{\int ^{T/2}_{-T/2} cos^{2} (\frac{2\pi n}{T} x)dx} =\frac{2}{T}\int ^{T/2}_{-T/2} f(x)cos(\frac{2\pi n}{T} x)dx\\ b_{n} =\frac{\int ^{T/2}_{-T/2} f(x)sin(\frac{2\pi n}{T} x)dx}{\int ^{T/2}_{-T/2} sin^{2} (\frac{2\pi n}{T} x)dx} =\frac{2}{T}\int ^{T/2}_{-T/2} f(x)sin(\frac{2\pi n}{T} x)dx an=∫−T/2T/2cos2(T2πnx)dx∫−T/2T/2f(x)cos(T2πnx)dx=T2∫−T/2T/2f(x)cos(T2πnx)dxbn=∫−T/2T/2sin2(T2πnx)dx∫−T/2T/2f(x)sin(T2πnx)dx=T2∫−T/2T/2f(x)sin(T2πnx)dx
利用欧拉公式 e i x = cos x + i sin e^{ix} =\cos x+i\sin eix=cosx+isinx,我们发现 cos x , sin x \displaystyle \cos x,\sin x cosx,sinx 可表示成
cos x = e i x + e − i x 2 , sin x = e i x − e − i x 2 i , {\displaystyle \cos x=\frac{e^{ix} +e^{-ix}}{2} ,\sin x=\frac{e^{ix} -e^{-ix}}{2i} ,} cosx=2eix+e−ix,sinx=2ieix−e−ix,
再将傅立叶级数f(x)中 cos ( 2 π n T x ) \cos (\frac{2\pi n}{T} x) cos(T2πnx)和 sin ( 2 π n T x ) \sin (\frac{2\pi n}{T} x) sin(T2πnx)的线性组合式改写如下:
a n cos ( 2 π n T x ) + b n sin ( 2 π n T x ) = a n ( e i 2 π n T x + e − i 2 π n T x 2 ) + b k ( e i 2 π n T x − e − i 2 π n T x 2 i ) = ( a n − i b n 2 ) e i 2 π n T x + ( a n + i b n 2 ) e − i 2 π n T x = c n e i 2 π n T x + c − n e − i 2 π n T x \begin{aligned} a_{n}\cos (\frac{2\pi n}{T} x)+b_{n}\sin (\frac{2\pi n}{T} x) & =a_{n}\left(\frac{e^{i\frac{2\pi n}{T} x} +e^{-i\frac{2\pi n}{T} x}}{2}\right)+b_{k}\left(\frac{e^{i\frac{2\pi n}{T} x} -e^{-i\frac{2\pi n}{T} x}}{2i}\right)\\ & =\left(\frac{a_{n} -ib_{n}}{2}\right) e^{i\frac{2\pi n}{T} x} +\left(\frac{a_{n} +ib_{n}}{2}\right) e^{-i\frac{2\pi n}{T} x}\\ & =c_{n} e^{i\frac{2\pi n}{T} x} +c_{-n} e^{-i\frac{2\pi n}{T} x} \end{aligned} ancos(T2πnx)+bnsin(T2πnx)=an(2eiT2πnx+e−iT2πnx)+bk(2ieiT2πnx−e−iT2πnx)=(2an−ibn)eiT2πnx+(2an+ibn)e−iT2πnx=cneiT2πnx+c−ne−iT2πnx
可以验证 c − n = a − n − i b − n 2 = a n + i b n 2 \displaystyle c_{-n} =\frac{a_{-n} -ib_{-n}}{2} =\frac{a_{n} +ib_{n}}{2} c−n=2a−n−ib−n=2an+ibn,这是因为an是一个偶函数,bn是一个奇函数。此外,若n=0,就有 c 0 = a 0 / 2 c_{0} =a_{0} /2 c0=a0/2。将以上结果代回f(x)的傅立叶级数即得指数傅立叶级数:
f ( x ) = ∑ n = − ∞ ∞ c n ⎵ 基 的 坐 标 ⋅ e i 2 π n x T ⎵ 正 交 基 {\displaystyle f(x)=\sum ^{\infty }_{n=-\infty }\underbrace{c_{n}}_{基的坐标} \cdot \underbrace{e^{i\tfrac{2\pi nx}{T}}}_{正交基}} f(x)=n=−∞∑∞基的坐标 cn⋅正交基 eiT2πnx
现在我们知道 c n = a n − i b n 2 \displaystyle c_{n} =\frac{a_{n} -ib_{n}}{2} cn=2an−ibn,将 a n , b n \displaystyle a_{n} ,b_{n} an,bn的结果代进去可以得到:
c n = 1 T ∫ − T / 2 T / 2 f ( x ) ( cos ( 2 π n T x ) − i sin ( 2 π n T x ) ) d x = 1 T ∫ − T / 2 T / 2 f ( x ) e − i 2 π n T x d x c_{n} =\frac{1}{T}\int ^{T/2}_{-T/2} f(x)(\cos (\frac{2\pi n}{T} x)-i\sin (\frac{2\pi n}{T} x))dx=\frac{1}{T}\int ^{T/2}_{-T/2} f(x)e^{-i \frac{2\pi n}{T}} x dx cn=T1∫−T/2T/2f(x)(cos(T2πnx)−isin(T2πnx))dx=T1∫−T/2T/2f(x)e−iT2πnxdx
公式用频率替换: Δ ω = 2 π T \displaystyle \Delta \omega =\frac{2\pi }{T} Δω=T2π,再令 ω n = ω n \displaystyle \omega _{n} =\omega n ωn=ωn现在我们可以写出全新的傅里叶级数:
f ( x ) = ∑ n = − ∞ ∞ Δ ω 2 π ∫ − T / 2 T / 2 f ( x ) e − i ω n x d x ⋅ e i ω n x {\displaystyle f(x)=\sum ^{\infty }_{n=-\infty }\frac{\Delta \omega }{2\pi }\int ^{T/2}_{-T/2} f(x)e^{-i\omega _{n} x} dx\cdot } e^{i\omega _{n} x} f(x)=n=−∞∑∞2πΔω∫−T/2T/2f(x)e−iωnxdx⋅eiωnx
现在令 T → ∞ , Δ ω → 0 \displaystyle T\rightarrow \infty ,\Delta \omega \rightarrow 0 T→∞,Δω→0,并设 F ( ω ) = lim T → ∞ ∫ − T / 2 T / 2 f ( x ) e − i ω x d x \displaystyle F{\displaystyle ( \omega ) =\lim _{T\rightarrow \infty }\int ^{T/2}_{-T/2} f(x)e^{-i\omega x} dx} F(ω)=T→∞lim∫−T/2T/2f(x)e−iωxdx
f ( x ) = ∑ n = − ∞ ∞ Δ ω 2 π F ( ω n ) ⋅ e i ω n x = 1 2 π ∑ n = − ∞ ∞ F ( ω n ) ⋅ e i ω n x Δ ω = 1 2 π ∫ − ∞ + ∞ F ( ω ) ⋅ e i ω x d ω \begin{aligned} {\displaystyle f(x)} & ={\displaystyle \sum ^{\infty }_{n=-\infty }\frac{\Delta \omega }{2\pi } F( \omega _{n}) \cdot } e^{i\omega _{n} x}\\ & ={\displaystyle \frac{1}{2\pi }\sum ^{\infty }_{n=-\infty } F( \omega _{n}) \cdot } e^{i\omega _{n} x} \Delta \omega \\ & ={\displaystyle \frac{1}{2\pi }\int ^{+\infty }_{-\infty } F( \omega ) \cdot } e^{i\omega x} d\omega \end{aligned} f(x)=n=−∞∑∞2πΔωF(ωn)⋅eiωnx=2π1n=−∞∑∞F(ωn)⋅eiωnxΔω=2π1∫−∞+∞F(ω)⋅eiωxdω
于是得到了傅里叶变换就是
F ( ω ) = ∫ − ∞ + ∞ f ( x ) e − i ω x d x {\displaystyle F( \omega ) =\int ^{+\infty }_{-\infty } f(x)e^{-i\omega x} dx} F(ω)=∫−∞+∞f(x)e−iωxdx
Signal Processing on Graph
在将图的傅里叶变换之前,我们先介绍一下图信号是什么。我们在传统概率图中,考虑每个图上的结点都是一个feature,对应数据的每一列,但是图信号不一样,这里每个结点不是随机变量,相反它是一个object。也就是说,他描绘概率图下每个样本之间的图联系,可以理解为刻画了不满足iid假设的一般情形。

图上的傅里叶变换
那么我们要怎么将传统的傅里叶变换推广到图结构中去?回忆一下,传统对f作傅里叶变换的方法:
f ^ ( ξ ) : = < f , e 2 π i ξ t > = ∫ R f ( t ) e − 2 π i ξ t d t \hat{f} (\xi ):=\left< f,e^{2\pi i\xi t}\right> =\int _{\mathbb{R}} f(t)e^{-2\pi i\xi t} dt f^(ξ):=⟨f,e2πiξt⟩=∫Rf(t)e−2πiξtdt
我们换了种写法,其实我们发现这个傅里叶变换本质上是一个内积。这个 e − 2 π i ξ t \displaystyle e^{-2\pi i\xi t} e−2πiξt其实是lapace算子的一个特征函数,可以理解为一种特殊形式的特征向量:
− Δ ( e 2 π i ξ t ) = − ∂ 2 ∂ t 2 e 2 π i ξ t = ( 2 π ξ ) 2 e 2 π i ξ t -\Delta \left( e^{2\pi i\xi t}\right) =-\frac{\partial ^{2}}{\partial t^{2}} e^{2\pi i\xi t} =(2\pi \xi )^{2} e^{2\pi i\xi t} −Δ(e2πiξt)=−∂t2∂2e2πiξt=(2πξ)2e2πiξt
注意,这里导数本质上是一个线性变换,因为它满足线性算子的两个性质,T(x+y)=T(x)+T(y), cT(x)=T(cx)。可以看到 e 2 π i ξ t \displaystyle e^{2\pi i\xi t} e2πiξt是laplace算子的特征向量,而 ( 2 π ξ ) 2 \displaystyle (2\pi \xi )^{2} (2πξ)2则是lapace算子的特征值。那么在图上我们的laplace矩阵就是离散化的lapace算子,而这个算子在图上的基显然就是特征向量了!
关于拉普拉斯算子的直观理解推荐看这篇文章:https://www.zhihu.com/question/54504471/answer/630639025
因此,只要意识到传统的傅里叶变换本质上求的是与正交基的内积(比如基 e 2 π i ξ t \displaystyle e^{2\pi i\xi t} e2πiξt)上的系数,而推广到图上的正交基很显然就是laplace矩阵的特征向量,于是对于laplace矩阵的傅里叶变换就可以表达为:
f ^ ( λ l ) : = < f , u l > = ∑ i = 1 N f ( i ) u l ∗ ( i ) \hat{f}( \lambda _{l}) :=< \mathbf{f} ,\mathbf{u}_{l}> =\sum ^{N}_{i=1} f(i)u^{*}_{l} (i) f^(λl):=<f,ul>=i=1∑Nf(i)ul∗(i)
显然这个变换就是在求解特征向量的系数,也就是特征值,因此,可以理解为图上的经过傅里叶变换后的函数 f ^ \displaystyle \hat{f} f^就是一个计算特征值的函数。
更一般的,图上的傅里叶变换可以写成以下内积的形式,其中U是laplace矩阵的特征向量矩阵:
傅里叶变换:
x ^ = U T x \hat{x} =U^{T} x x^=UTx
傅里叶逆变换:
x = U x ^ x=U\hat{x} x=Ux^
因此,我们就可以定义图上的卷积,因为它就是简单的两个变换的乘积然后再逆变换而已:
比如,x,y的卷积,就是他们傅里叶变换频域对应相乘,再通过傅里叶逆变换求回去
y ∗ x = U ( ( U T y ) ⊙ ( U T x ) ) y * x=U\left(\left(U^{T} y\right) \odot\left(U^{T} x\right)\right) y∗x=U((UTy)⊙(UTx))
又因为
( x 1 ⋮ x n ) ⊙ ( y 1 ⋮ y n ) = ( x 1 ⋯ 0 ⋮ ⋱ ⋮ 0 ⋯ x n ) ( y 1 ⋮ y n ) \left( \begin{array}{c}{x_{1}} \\ {\vdots} \\ {x_{n}}\end{array}\right) \odot \left( \begin{array}{c}{y_{1}} \\ {\vdots} \\ {y_{n}}\end{array}\right)=\left( \begin{array}{ccc}{x_{1}} & {\cdots} & {0} \\ {\vdots} & {\ddots} & {\vdots} \\ {0} & {\cdots} & {x_{n}}\end{array}\right) \left( \begin{array}{c}{y_{1}} \\ {\vdots} \\ {y_{n}}\end{array}\right) ⎝⎜⎛x1⋮xn⎠⎟⎞⊙⎝⎜⎛y1⋮yn⎠⎟⎞=⎝⎜⎛x1⋮0⋯⋱⋯0⋮xn⎠⎟⎞⎝⎜⎛y1⋮yn⎠⎟⎞
因此我们将 U T y U^Ty UTy 参数并化为一个对角矩阵,设 g θ = diag ( θ ) \displaystyle g_{\theta } =\operatorname{diag} (\theta ) gθ=diag(θ),从而可以训练一个卷积核:
g θ ⋆ x = U g θ U ⊤ x g_{\theta } \star x=Ug_{\theta } U^{\top } x gθ⋆x=UgθU⊤x
然而计算U的代价太高了,因此要想办法去近似它,有人提出,
g θ ′ ( Λ ) ≈ ∑ k = 0 K θ k ′ T k ( Λ ~ ) g_{\theta ^{\prime }} (\Lambda )\approx \sum ^{K}_{k=0} \theta ^{\prime }_{k} T_{k} (\tilde{\Lambda } ) gθ′(Λ)≈k=0∑Kθk′Tk(Λ~)
其中 Λ ~ = 2 λ max Λ − I N \displaystyle \tilde{\Lambda } =\frac{2}{\lambda _{\max}} \Lambda -I_{N} Λ~=λmax2Λ−IN,现在假设 λ max ≈ 2 \displaystyle \lambda _{\max} \approx 2 λmax≈2,并且k=1,于是
g θ ′ ⋆ x ≈ θ 0 ′ x + θ 1 ′ ( L − I N ) x = θ 0 ′ x − θ 1 ′ D − 1 2 A D − 1 2 x g_{\theta ^{\prime }} \star x\approx \theta ^{\prime }_{0} x+\theta ^{\prime }_{1}( L-I_{N}) x=\theta ^{\prime }_{0} x-\theta ^{\prime }_{1} D^{-\frac{1}{2}} AD^{-\frac{1}{2}} x gθ′⋆x≈θ0′x+θ1′(L−IN)x=θ0′x−θ1′D−21AD−21x
最后再假设这两个参数是共享的,可以得到:
g θ ⋆ x ≈ θ ( I N + D − 1 2 A D − 1 2 ) x g_{\theta } \star x\approx \theta \left( I_{N} +D^{-\frac{1}{2}} AD^{-\frac{1}{2}}\right) x gθ⋆x≈θ(IN+D−21AD−21)x
最后,再将中间的项用一个trick变成: I N + D − 1 2 A D − 1 2 → D ~ − 1 2 A ~ D ~ − 1 2 \displaystyle I_{N} +D^{-\frac{1}{2}} AD^{-\frac{1}{2}}\rightarrow \tilde{D}^{-\frac{1}{2}}\tilde{A}\tilde{D}^{-\frac{1}{2}} IN+D−21AD−21→D~−21A~D~−21,其中 A ~ = A + I N \displaystyle \tilde{A} =A+I_{N} A~=A+IN, D ~ i i = ∑ j A ~ i j \displaystyle \tilde{D}_{ii} =\sum _{j}\tilde{A}_{ij} D~ii=j∑A~ij,最后的最后,终于得到了这样的近似卷积公式:
Z = D ~ − 1 2 A ~ D ~ − 1 2 X Θ Z=\tilde{D}^{-\frac{1}{2}}\tilde{A}\tilde{D}^{-\frac{1}{2}} X\Theta Z=D~−21A~D~−21XΘ
这样我们就可以直接用神经网络训练了:
H ( l + 1 ) = σ ( D ~ − 1 2 A ~ D ~ − 1 2 H ( l ) W ( l ) ) H^{(l+1)} =\sigma \left(\tilde{D}^{-\frac{1}{2}}\tilde{A}\tilde{D}^{-\frac{1}{2}} H^{(l)} W^{(l)}\right) H(l+1)=σ(D~−21A~D~−21H(l)W(l))
参考资料
https://towardsdatascience.com/spectral-clustering-82d3cff3d3b7
https://www.cnblogs.com/pinard/p/6221564.html
https://tkipf.github.io/graph-convolutional-networks/
https://ccjou.wordpress.com/2012/04/03/%E5%82%85%E7%AB%8B%E8%91%89%E7%B4%9A%E6%95%B8-%E4%B8%8B/
https://www.matongxue.com/madocs/712/
https://www.youtube.com/watch?v=Q99ZPGnUBAQ