Flink常用算子Transformation(转换)
在之前的《Flink DataStream API》一文中,我们列举了一些Flink自带且常用的transformation算子,例如map、flatMap等。在Flink的编程体系中,我们获取到数据源之后,需要经过一系列的处理即transformation操作,再将最终结果输出到目的Sink(ES、mysql或者hdfs),使数据落地。因此,除了正确的继承重写RichSourceFunction<>和RichSinkFunction<>之外,最终要的就是实时处理这部分,下面的图介绍了Flink代码执行流程以及各模块的组成部分。
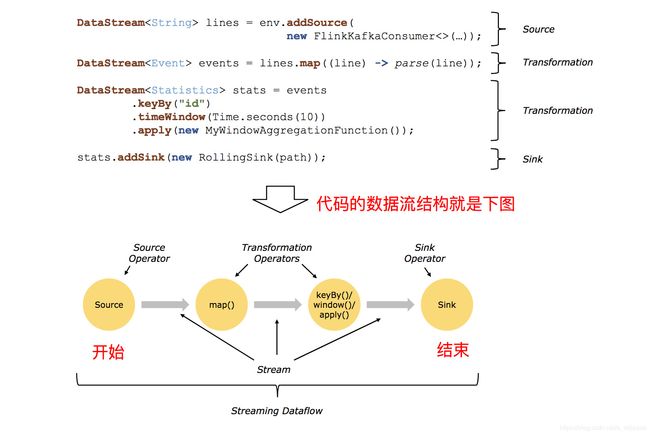
在Storm中,我们常常用Bolt的层级关系来表示各个数据的流向关系,组成一个拓扑。在Flink中,Transformation算子就是将一个或多个DataStream转换为新的DataStream,可以将多个转换组合成复杂的数据流拓扑。如下图所示,DataStream会由不同的Transformation操作,转换、过滤、聚合成其他不同的流,从而完成我们的业务要求。

那么以《Flink从kafka中读数据存入Mysql Sink》一文中的业务场景作为基础,在Flink读取Kafka的数据之后,进行不同的算子操作来分别详细介绍一下各个Transformation算子的用法。Flink消费的数据格式依然是JSON格式:{"city":"合肥","loginTime":"2019-04-17 19:04:32","os":"Mac OS","phoneName":"vivo"}
1、map
map:输入一个元素,输出一个元素,可以用来做一些清洗工作。
/**
* create by xiax.xpu on @Date 2019/4/11 20:47
*/
public class FlinkSubmitter {
public static void main(String[] args) throws Exception{
//获取运行时环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//checkpoint配置
//为了能够使用支持容错的kafka Consumer,开启checkpoint机制,支持容错,保存某个状态信息
env.enableCheckpointing(5000);
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);
env.getCheckpointConfig().setCheckpointTimeout(60000);
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
//kafka配置文件
Properties props = new Properties();
props.put("bootstrap.servers", "192.168.83.129:9092");
props.setProperty("group.id","con1");
props.put("zookeeper.connect","192.168.83.129:2181");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); //key 反序列化
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); //value 反序列化
System.out.println("ready to print");
FlinkKafkaConsumer011 consumer = new FlinkKafkaConsumer011<>(
"kafka_flink_mysql",
new SimpleStringSchema(),
props);
consumer.setStartFromGroupOffsets();//默认消费策略
SingleOutputStreamOperator StreamRecord = env.addSource(consumer)
.map(string -> JSON.parseObject(string, Entity.class))
.setParallelism(1);
//融合一些transformation算子进来
//map:输入一个元素,输出一个元素,可以用来做一些清洗工作
SingleOutputStreamOperator result = StreamRecord.map(new MapFunction() {
@Override
public Entity map(Entity value) throws Exception {
Entity entity1 = new Entity();
entity1.city = value.city+".XPU.Xiax";
entity1.phoneName = value.phoneName.toUpperCase();
entity1.loginTime = value.loginTime;
entity1.os = value.os;
return entity1;
}
});
result.print().setParallelism(1);
env.execute("new one");
}
}
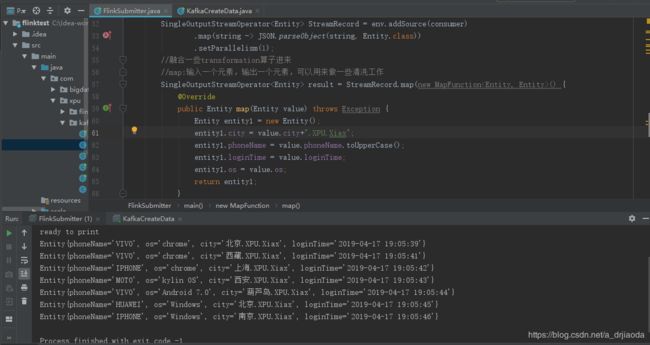
本例中我们将获取的JSON字符串转换到Entity object之后,使用map算子让所有的phoneName编程大写,city后面添加XPU.Xiax后缀。
2、flatMap
flatMap:打平操作,我们可以理解为将输入的元素压平,从而对输出结果的数量不做要求,可以为0、1或者多个都OK。它和Map相似,但引入flatMap的原因是因为一般java方法的返回值结果都是一个,因此引入flatMap来区别这个。
//flatMap, 输入一个元素,返回0个、1个或者多个元素
SingleOutputStreamOperator result = StreamRecord
.flatMap(new FlatMapFunction() {
@Override
public void flatMap(Entity entity, Collector out) throws Exception {
if (entity.city.equals("北京")) {
out.collect(entity);
}
}
}); 这里我们将所有city是北京的结果集聚合输出,注意这里并不是过滤,有些人可能会困惑这不是起了过滤filter的作用吗,其实不然,只是这里的用法刚好相似而已。简单分析一下,new FlatMapFunction

3、filter
filter:过滤筛选,将所有符合判断条件的结果集输出
//filter 判断条件输出
SingleOutputStreamOperator result = StreamRecord
.filter(new FilterFunction() {
@Override
public boolean filter(Entity entity) throws Exception {
if (entity.phoneName.equals("HUAWEI")) {
return true;
}
return false;
}
}); 这里我们将所有phoneName是HUAWEI的值过滤,在直接输出。

4、keyBy
keyBy:在逻辑上将Stream根据指定的Key进行分区,是根据key的Hash值进行分区的。
//keyBy 从逻辑上对逻辑分区
KeyedStream result = StreamRecord
.keyBy(new KeySelector() {
@Override
public String getKey(Entity entity) throws Exception {
return entity.os;
}
}); 这里只是对DataStream进行分区而已,按照os进行分区,然而这输出的效果其实没什么变化

由于下面这些操作,在之前模拟生成的数据,去做转换操作不太适合。因此每个操作附上其他demo
5、reduce
reduce:属于归并操作,它能将3的keyedStream转换成DataStream,Reduce 返回单个的结果值,并且 reduce 操作每处理每一天新数据时总是创建一个新值。常用聚合操作例如min、max等都可使用reduce方法实现。这里通过实现一个Socket的wordCount简单例子,来帮助了解flatMap/keyBy/reduce/window等操作的过程。
package com.bigdata.flink.Stream;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
/**
* 滑动窗口的计算
*
* 通过socket模拟产生单词数据 flink对其进行统计计数
* 实现时间窗口:
* 每隔1秒统计前两秒的数据
*/
public class SocketWindowWordCount {
public static void main(String[] args) throws Exception{
//定义端口号,通过cli接收
int port;
try{
ParameterTool parameterTool = ParameterTool.fromArgs(args);
port = parameterTool.getInt("port");
}catch(Exception e){
System.err.println("No port Set, use default port---java");
port = 9000;
}
//获取运行时环境,必须要
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//绑定Source,通过master的nc -l 900 产生单词
String hostname = "192.168.83.129";
String delimiter = "\n";
//连接socket 绑定数据源
DataStreamSource socketWord = env.socketTextStream(hostname, port, delimiter);
DataStream windowcounts = socketWord.flatMap(new FlatMapFunction() {
public void flatMap(String value, Collector out) throws Exception {
String[] splits = value.split("\\s");
for (String word : splits) {
out.collect(new WordWithCount(word, 1));
}
}
}).keyBy("word")
//.sum("count");//这里求聚合 可以用reduce和sum两种方式
.reduce(new ReduceFunction() {
public WordWithCount reduce(WordWithCount a, WordWithCount b) throws Exception {
return new WordWithCount(a.word, a.count + b.count);
}
});
windowcounts.print().setParallelism(1);
env.execute("socketWindow");
}
public static class WordWithCount{
public String word;
public int count;
//无参的构造函数
public WordWithCount(){
}
//有参的构造函数
public WordWithCount(String word, int count){
this.count = count;
this.word = word;
}
@Override
public String toString() {
return "WordWithCount{" +
"word='" + word + '\'' +
", count=" + count +
'}';
}
}
}

这里只是做单词计数,至于为什么有的单词重复出现,但是请注意它后面的count值都不一样,我们直接生成了toString方法打印出的结果。
6、aggregations
aggregations:进行一些聚合操作,例如sum(),min(),max()等,这些可以用于keyedStream从而获得聚合。用法如下
KeyedStream.sum(0)或者KeyedStream.sum(“Key”)
7、unoin
union:可以将多个流合并到一个流中,以便对合并的流进行统一处理,有点类似于Storm中的将上一级的两个Bolt数据汇聚到这一级同一个Bolt中。注意,合并的流类型需要一致
//1.获取执行环境配置信息
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2.定义加载或创建数据源(source),监听9000端口的socket消息
DataStream textStream9000 = env.socketTextStream("localhost", 9000, "\n");
DataStream textStream9001 = env.socketTextStream("localhost", 9001, "\n");
DataStream textStream9002 = env.socketTextStream("localhost", 9002, "\n");
DataStream mapStream9000=textStream9000.map(s->"来自9000端口:"+s);
DataStream mapStream9001=textStream9001.map(s->"来自9001端口:"+s);
DataStream mapStream9002=textStream9002.map(s->"来自9002端口:"+s);
//3.union用来合并两个或者多个流的数据,统一到一个流中
DataStream result = mapStream9000.union(mapStream9001,mapStream9002);
//4.打印输出sink
result.print();
//5.开始执行
env.execute();
8、connect
connect:和union类似,但是只能连接两个流,两个流的数据类型可以不同,会对两个流中的数据应用不同的处理方法。
//获取Flink运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//绑定数据源
DataStreamSource text1 = env.addSource(new MyParalleSource()).setParallelism(1);
DataStreamSource text2 = env.addSource(new MyParalleSource()).setParallelism(1);
//为了演示connect的不同,将第二个source的值转换为string
SingleOutputStreamOperator text2_str = text2.map(new MapFunction() {
@Override
public String map(Long value) throws Exception {
return "str" + value;
}
});
ConnectedStreams connectStream = text1.connect(text2_str);
SingleOutputStreamOperator 9、split
split:根据规则吧一个数据流切分成多个流,可能在实际场景中,源数据流中混合了多种类似的数据,多种类型的数据处理规则不一样,所以就可以根据一定的规则把一个数据流切分成多个数据流。
//获取Flink运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//绑定数据源
DataStreamSource text = env.addSource(new MyParalleSource()).setParallelism(1);
//对流进行切分 奇数偶数进行区分
SplitStream splitString = text.split(new OutputSelector() {
@Override
public Iterable select(Long value) {
ArrayList output = new ArrayList<>();
if (value % 2 == 0) {
output.add("even");//偶数
} else {
output.add("odd");//奇数
}
return output;
}
});
//选择一个或者多个切分后的流
DataStream evenStream = splitString.select("even");//选择偶数
DataStream oddStream = splitString.select("odd");//选择奇数
DataStream moreStream = splitString.select("odd","even");//选择多个流
//打印到控制台,并行度为1
evenStream.print().setParallelism(1);
env.execute( "StreamingDemoWithMyNoParalleSource"); 10、window以及windowAll
window:按时间进行聚合或者其他条件对KeyedStream进行分组,用法:inputStream.keyBy(0).window(Time.seconds(10));
windowAll: 函数允许对常规数据流进行分组。通常,这是非并行数据转换,因为它在非分区数据流上运行。用法:inputStream.keyBy(0).windowAll(Time.seconds(10));
关于时间窗口,这个我们后期会详细说一下,敬请关注。