详解TF中的Embedding操作!
embedding大家都不陌生,在我们的模型中,只要存在离散变量,那么一般都会用到embedding操作。今天这篇,我们将按以下的章节来介绍TF中的embedding操作。
- 什么是embedding?
- tf1.x中的embedding实现,对比embedding_lookup和matmul
- tf1.x中与embedding类似操作,包括gather,gather_nd
- tf1.x中多值离散特征处理tf.nn.embedding_lookup_sparse
- tf2.0中embedding实现
1、什么是embedding?
先来看看什么是embedding,我们可以简单的理解为,将一个特征转换为一个向量。在推荐系统当中,我们经常会遇到离散特征,如userid、itemid。对于离散特征,我们一般的做法是将其转换为one-hot,但对于itemid这种离散特征,转换成one-hot之后维度非常高,但里面只有一个是1,其余都为0。这种情况下,我们的通常做法就是将其转换为embedding。
embedding的过程是什么样子的呢?它其实就是一层全连接的神经网络,如下图所示:

假设一个特征共有5个取值,也就是说one-hot之后会变成5维,我们想将其转换为embedding表示,其实就是接入了一层全连接神经网络。由于只有一个位置是1,其余位置是0,因此得到的embedding就是与其相连的图中红线上的权重。
接下来,我们来看一下tf1.x中embedding的实现。
2、tf1.x中的embedding实现
在tf1.x中,我们使用embedding_lookup函数来实现emedding,代码如下:
# embedding
embedding = tf.constant(
[[0.21,0.41,0.51,0.11]],
[0.22,0.42,0.52,0.12],
[0.23,0.43,0.53,0.13],
[0.24,0.44,0.54,0.14]],dtype=tf.float32)
feature_batch = tf.constant([2,3,1,0])
get_embedding1 = tf.nn.embedding_lookup(embedding,feature_batch)
上面的过程为:

注意这里的维度的变化,假设我们的feature_batch 是 1维的tensor,长度为4,而embedding的长度为4,那么得到的结果是 4 * 4 的,同理,假设feature_batch是2 *4的,embedding_lookup后的结果是2 * 4 * 4。后面我们在观察结果。
上文说过,embedding层其实是一个全连接神经网络层,那么其过程等价于:

可以得到下面的代码:
embedding = tf.constant(
[
[0.21,0.41,0.51,0.11],
[0.22,0.42,0.52,0.12],
[0.23,0.43,0.53,0.13],
[0.24,0.44,0.54,0.14]
],dtype=tf.float32)
feature_batch = tf.constant([2,3,1,0])
feature_batch_one_hot = tf.one_hot(feature_batch,depth=4)
get_embedding2 = tf.matmul(feature_batch_one_hot,embedding)
二者是否一致呢?我们通过代码来验证一下:
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
embedding1,embedding2 = sess.run([get_embedding1,get_embedding2])
print(embedding1)
print(embedding2)
得到的结果为:

二者得到的结果是一致的。
3、tf1.x中与embedding类似操作
通过上面的讲解,embedding_lookup函数的作用更像是一个搜索操作,即根据我们提供的索引,从对应的tensor中寻找对应位置的切片。通过查看embedding_lookup函数的源码,不难发现,它是gather函数的一种特殊形式:

gather函数的原型为:
def gather(params, indices, validate_indices=None, name=None, axis=0):
该函数也是根据索引从params上获取切片,不过它可以指定索引的轴。当params是二维的tensor,轴axis=0时,跟我们讲的embedding_lookup函数等价:
embedding = tf.constant(
[
[0.21,0.41,0.51,0.11],
[0.22,0.42,0.52,0.12],
[0.23,0.43,0.53,0.13],
[0.24,0.44,0.54,0.14]
],dtype=tf.float32)
index_a = tf.Variable([2,3,1,0])
gather_a = tf.gather(embedding, index_a)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
print(sess.run(gather_a))
输出为:

跟我们使用embedding_lookup函数得到的结果一样,但假设我们的axis不是0,是1呢,其过程如下:

通过代码验证一下:
embedding = tf.constant(
[
[0.21,0.41,0.51,0.11],
[0.22,0.42,0.52,0.12],
[0.23,0.43,0.53,0.13],
[0.24,0.44,0.54,0.14]
],dtype=tf.float32)
gather_a_axis1 = tf.gather(embedding,index_a,axis=1)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
print(sess.run(gather_a_axis1))
输出为:

当然,params也可以不是二维的tensor,一维也可以:
b = tf.Variable([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
index_b = tf.Variable([2, 4, 6, 8])
gather_b = tf.gather(b, index_b)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
print(sess.run(gather_b))
输出为:
使用 tf.gather函数呢,我们只能通过一个维度的来获取切片,如果我们想要通过多个维度的联合索引来获取切片,可以通过gather_nd函数,下面是简单的代码示例:
a = tf.Variable([[1, 2, 3, 4, 5], [6, 7, 8, 9, 10], [11, 12, 13, 14, 15]])
index_a = tf.Variable([0, 2])
b = tf.get_variable(name='b',shape=[3,3,2],initializer=tf.random_normal_initializer)
index_b = tf.Variable([[0,1,1],[2,2,0]])
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
print(sess.run(tf.gather_nd(a, index_a)))
print(sess.run(b))
print(sess.run(tf.gather_nd(b, index_b)))
输出为:
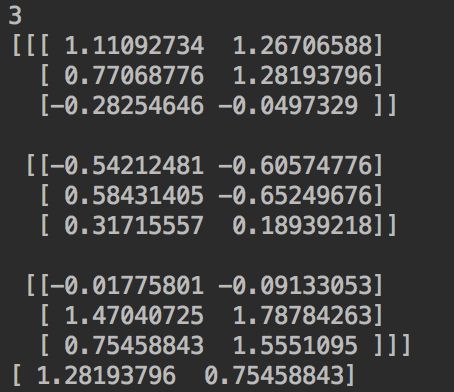
这个函数的切片功能,有点类似于numpy,大家可以参考一下。
4、tf1.x中多值离散特征处理
上面所说的embedding_lookup函数,只能处理一个离散特征有一个取值的情况,但实际中,有的离散特征可能有两三个取值,如一个人的爱好,可能既喜欢篮球又喜欢羽毛球,这样转成one-hot的时候,有两个地方为1(这里应该不叫one-hot,确切来说是multi-hot)。我们称这种情况为多值离散特征。这种情况下,如何处理呢?我们使用tf.nn.embedding_lookup_sparse函数。
使用该函数的例子如下:
# sparse embedding
a = tf.SparseTensor(indices=[[0, 0],[1, 2],[1,3]], values=[1, 2, 3], dense_shape=[2, 4])
embedding = tf.constant(
[
[0.21,0.41,0.51,0.11],
[0.22,0.42,0.52,0.12],
[0.23,0.43,0.53,0.13],
[0.24,0.44,0.54,0.14]
],dtype=tf.float32)
embedding_sparse = tf.nn.embedding_lookup_sparse(embedding, sp_ids=a, sp_weights=None)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
print(sess.run(embedding_sparse))
输出为:

我们一步步来看上面的过程,首先,我们需要有一个SparseTensor,这个tensor的shape是[2, 4]的,其中不为0的地方呢一共有三个,即[0, 0],[1, 2],[1,3],这三处的value分别是1,2,3,这个SparseTensor其实长下面这个样子:

可以使用下面的代码来将sparseTensor转换为DenseTensor:
b = tf.sparse_tensor_to_dense(a)
接下来,在embedding_lookup_sparse中我们提供了三个参数,第一个不解释了,第二个sp_ids即我们定义的SparseTensor,第三个参数sp_weights=None代表的每一个取值的权重,如果是None的话,所有权重都是1,也就是相当于取了平均。如果不是None的话,我们需要同样传入一个SparseTensor。
这样,结果的第一行没什么好解释的了,即取了我们定义的embedding这个tensor的index=1的那一行,结果的第二行相当于取了我们定义的embedding这个tensor的index=2和index=3这两行的平均值。
5、tf2.0中embedding实现
在tf2.0中,embedding同样可以通过embedding_lookup来实现,不过不同的是,我们不需要通过sess.run来获取结果了,可以直接运行结果,并转换为numpy。
embedding = tf.constant(
[
[0.21,0.41,0.51,0.11],
[0.22,0.42,0.52,0.12],
[0.23,0.43,0.53,0.13],
[0.24,0.44,0.54,0.14]
],dtype=tf.float32)
feature_batch = tf.constant([2,3,1,0])
get_embedding1 = tf.nn.embedding_lookup(embedding,feature_batch)
feature_batch_one_hot = tf.one_hot(feature_batch,depth=4)
get_embedding2 = tf.matmul(feature_batch_one_hot,embedding)
print(get_embedding1.numpy().tolist())
如果想要在神经网络中使用embedding层,推荐使用Keras:
num_classes=10
input_x = tf.keras.Input(shape=(None,),)
embedding_x = layers.Embedding(num_classes, 10)(input_x)
hidden1 = layers.Dense(50,activation='relu')(embedding_x)
output = layers.Dense(2,activation='softmax')(hidden1)
x_train = [2,3,4,5,8,1,6,7,2,3,4,5,8,1,6,7,2,3,4,5,8,1,6,7,2,3,4,5,8,1,6,7,2,3,4,5,8,1,6,7,2,3,4,5,8,1,6,7,2,3,4,5,8,1,6,7,2,3,4,5,8,1,6,7]
y_train = [0,1,0,1,1,0,0,1,0,1,0,1,1,0,0,1,0,1,0,1,1,0,0,1,0,1,0,1,1,0,0,1,0,1,0,1,1,0,0,1,0,1,0,1,1,0,0,1,0,1,0,1,1,0,0,1,0,1,0,1,1,0,0,1]
model2 = tf.keras.Model(inputs = input_x,outputs = output)
model2.compile(optimizer=tf.keras.optimizers.Adam(0.001),
#loss=tf.keras.losses.SparseCategoricalCrossentropy(),
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
history = model2.fit(x_train, y_train, batch_size=4, epochs=1000, verbose=0)
好了,本文的内容就这么多,小伙伴们可以回头多多练习一下这几个函数的使用。
对了,小编的公众号:“小小挖掘机”,最近有送书活动,赶紧关注公众号,后台回复“抽奖”参与吧,截止到5.28号晚8点哟~~