python 清洗数据
1、导入数据
import pandas as pd
import os
import numpy as np
os.chdir(r"E:\Python_learning\data_science\train_0529\5Preprocessing")
camp = pd.read_csv('teleco_camp_orig.csv')
camp.head()
Out[1]:
ID Suc_flag ARPU PromCnt12 PromCnt36 PromCntMsg12 PromCntMsg36 \
0 12 1 50.0 6 10 2 3
1 53 0 NaN 5 9 1 4
2 67 1 25.0 6 11 2 4
3 71 1 80.0 7 10 2 4
4 142 1 15.0 6 11 2 4
Class Age Gender HomeOwner AvgARPU AvgHomeValue AvgIncome
0 4 57.0 M H 49.894904 33400 39460
1 3 55.0 M H 48.574742 37600 33545
2 1 57.0 F H 49.272646 100400 42091
3 1 52.0 F H 47.334953 39900 39313
4 1 NaN F U 47.827404 47500 0 2、查看数据某属性分布情况,并进行统计描述
import matplotlib.pyplot as plt
plt.hist(camp['AvgIncome'], bins=20, normed=True)#查看分布情况
camp['AvgIncome'].describe(include='all')Out[3]:
count 9686.000000
mean 40491.444249
std 28707.494146
min 0.000000
25% 24464.000000
50% 43100.000000
75% 56876.000000
max 200001.000000
Name: AvgIncome, dtype: float64
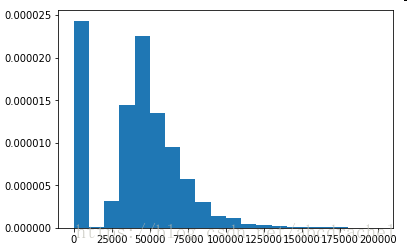
由上图可以看出异常值(平均收入不可能为0)
plt.hist(camp['AvgHomeValue'], bins=20, normed=True)#查看分布情况
camp['AvgHomeValue'].describe(include='all')Out[4]:
count 9686.000000
mean 110986.299814
std 98670.855450
min 0.000000
25% 52300.000000
50% 76900.000000
75% 128175.000000
max 600000.000000
Name: AvgHomeValue, dtype: float64
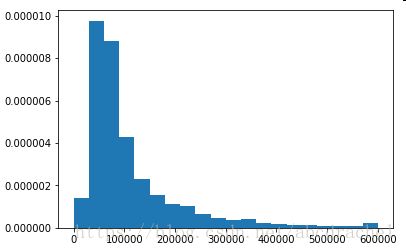
同样也出现了0,为异常值
3、对异常值进行处理
#这里的0值应该是缺失值
camp['AvgIncome']=camp['AvgIncome'].replace({0: np.NaN})
#像这种外部获取的数据要比较小心,经常出现意义不清晰或这错误值。AvgHomeValue也有这种情况
plt.hist(camp['AvgIncome'], bins=20, normed=True,range=(camp.AvgIncome.min(),camp.AvgIncome.max()))
#由于数据中存在缺失值,需要指定绘图的值域
camp['AvgIncome'].describe(include='all')Out[5]:
count 7329.000000
mean 53513.457361
std 19805.168339
min 2499.000000
25% 40389.000000
50% 48699.000000
75% 62385.000000
max 200001.000000
Name: AvgIncome, dtype: float64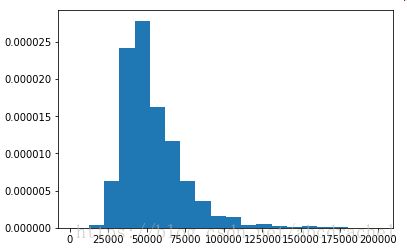
同理对另一个属性进行处理
camp['AvgHomeValue']=camp['AvgHomeValue'].replace({0: np.NaN})
plt.hist(camp['AvgHomeValue'], bins=20, normed=True,range=(camp.AvgHomeValue.min(),camp.AvgHomeValue.max()))
#由于数据中存在缺失值,需要指定绘图的值域
camp['AvgHomeValue'].describe(include='all')Out[6]:
count 9583.000000
mean 112179.202755
std 98522.888583
min 7500.000000
25% 53200.000000
50% 77700.000000
75% 129350.000000
max 600000.000000
Name: AvgHomeValue, dtype: float64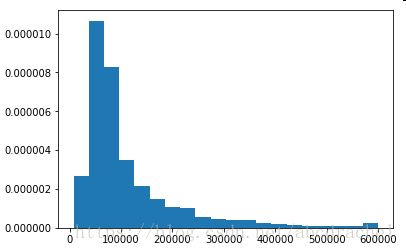
4、对各属性值去重
camp.describe()
#如果count数量少于样本量,说明存在缺失
#缺失最多的两个变量是Age和AvgIncome,缺失了大概20%。
ID Suc_flag ARPU PromCnt12 PromCnt36 \
count 9686.000000 9686.000000 4843.000000 9686.000000 9686.000000
mean 97975.474086 0.500000 78.121722 3.495251 7.466963
std 56550.171120 0.500026 62.225686 1.270258 1.977909
min 12.000000 0.000000 5.000000 1.000000 1.000000
25% 48835.500000 0.000000 50.000000 3.000000 6.000000
50% 99106.000000 0.500000 65.000000 3.000000 8.000000
75% 148538.750000 1.000000 100.000000 4.000000 8.000000
max 191779.000000 1.000000 1000.000000 15.000000 20.000000
PromCntMsg12 PromCntMsg36 Class Age AvgARPU \
count 9686.000000 9686.000000 9686.000000 7279.000000 9686.000000
mean 1.034586 2.323044 2.424530 49.567386 52.905156
std 0.244171 0.904083 1.049047 6.991306 4.993775
min 0.000000 0.000000 1.000000 16.000000 46.138968
25% 1.000000 1.000000 2.000000 45.000000 49.760116
50% 1.000000 3.000000 2.000000 50.000000 50.876672
75% 1.000000 3.000000 3.000000 55.000000 54.452822
max 4.000000 6.000000 4.000000 60.000000 99.444787
AvgHomeValue AvgIncome
count 9583.000000 7329.000000
mean 112179.202755 53513.457361
std 98522.888583 19805.168339
min 7500.000000 2499.000000
25% 53200.000000 40389.000000
50% 77700.000000 48699.000000
75% 129350.000000 62385.000000
max 600000.000000 200001.000000对重复值打标签
camp['dup'] = camp.duplicated() # 生成重复标识变量
camp.dup.head()
Out[7]:
0 False
1 False
2 False
3 False
4 False
Name: dup, dtype: bool根据标签提取数据
camp_dup = camp[camp['dup'] == True] # 把有重复的数据保存出来,以备核查
camp_nodup = camp[camp['dup'] == False] # 注意与camp.drop_duplicates()的区别
camp_nodup.head()camp['dup1'] = camp['ID'].duplicated() # 按照主键进行重复记录标识5、对缺失值进行填充
现对属性age进行处理:
camp['Age'].describe()
Out[9]:
count 7279.000000
mean 49.567386
std 6.991306
min 16.000000
25% 45.000000
50% 50.000000
75% 55.000000
max 60.000000
Name: Age, dtype: float64计算age的均值
vmean = camp['Age'].mean(axis=0, skipna=True)
vmean
Out[10]: 49.56738562989422
对age缺失值打标签
camp['Age_empflag'] = camp['Age'].isnull()
camp.head()Out[11]:
ID Suc_flag ARPU PromCnt12 PromCnt36 PromCntMsg12 PromCntMsg36 \
0 12 1 50.0 6 10 2 3
1 53 0 NaN 5 9 1 4
2 67 1 25.0 6 11 2 4
3 71 1 80.0 7 10 2 4
4 142 1 15.0 6 11 2 4
Class Age Gender HomeOwner AvgARPU AvgHomeValue AvgIncome \
0 4 57.0 M H 49.894904 33400.0 39460.0
1 3 55.0 M H 48.574742 37600.0 33545.0
2 1 57.0 F H 49.272646 100400.0 42091.0
3 1 52.0 F H 47.334953 39900.0 39313.0
4 1 NaN F U 47.827404 47500.0 NaN
Age_empflag
0 False
1 False
2 False
3 False
4 True 对age中的缺失值用均值填充
camp['Age']= camp['Age'].fillna(vmean)
camp['Age'].describe()Out[12]:
count 9686.000000
mean 49.567386
std 6.060585
min 16.000000
25% 47.000000
50% 49.567386
75% 54.000000
max 60.000000
Name: Age, dtype: float64同理对AvgHomeValue属性进行处理
vmean = camp['AvgHomeValue'].mean(axis=0, skipna=True)
camp['AvgHomeValue_empflag'] = camp['AvgHomeValue'].isnull()
camp['AvgHomeValue']= camp['AvgHomeValue'].fillna(vmean)
camp['AvgHomeValue'].describe()
Out[13]:
count 9686.000000
mean 112179.202755
std 97997.592632
min 7500.000000
25% 53500.000000
50% 78450.000000
75% 128175.000000
max 600000.000000
Name: AvgHomeValue, dtype: float64vmean = camp['AvgIncome'].mean(axis=0, skipna=True)
camp['AvgIncome_empflag'] = camp['AvgIncome'].isnull()
camp['AvgIncome']= camp['AvgIncome'].fillna(vmean)
camp['AvgIncome'].describe()Out[14]:
count 9686.000000
mean 53513.457361
std 17227.468161
min 2499.000000
25% 42775.000000
50% 53513.457361
75% 56876.000000
max 200001.000000
Name: AvgIncome, dtype: float64