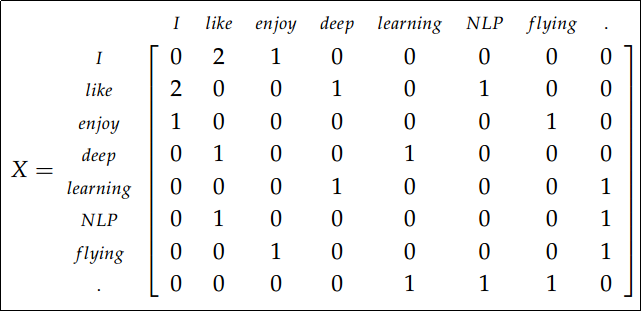
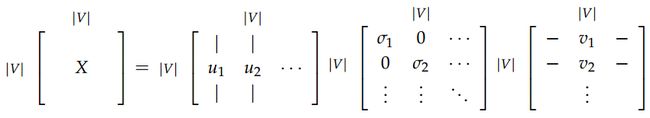

- 矩阵进行一些修正来修复词频分布不均匀问题
对 X
矩阵的一些修正:
- 功能词(the, he, has)过于频繁,对语法有很大影响,解决办法是降低使用或完全忽略功能词
- 采用带权重的窗口,距离当前词距离越近共现权重越大
- 用皮尔逊相关系数代替计数,并置负数为0
Word2vec
Word2vec的基本思想与共现计数不同,word2vec主要分为两种,采用当前词来预测窗口中 的其他词(skip-gram),另一种是用窗口中的词来预测当前词(cbow)。
CBOW
CBOW(Continuous Bag of Words)的基本思想是用窗口中的词的向量求平均之后来预测中心词。训练语料是上下文和对应的中心词的对,上下文窗口内的每个词都用一个one-hot向量 x(i)
表示,中心词用one-hot向量 y(i) 表示,CBOW中预测的中心词只有一个所以直接把输出向量表示成 y。
随机初始化两个矩阵(一般用正态分布进行初始化) W(1)∈Rn×|V|
和 W(2)∈R|V|×n 分别用来存储输入向量和输出向量,最后训练完每个词有两个向量,一个是当作输入时的向量,一个是当作输出时的向量。 n 为词向量的维度; W(1) 的第 i 列表示词 w(i) 当作输入时的向量表示,记作 u(i) ; W(2) 的第 j 行表示词 w(j) 当作输出时的向量表示,记作 v(j)。利用上下文预测中心词的步骤如下:
- 把大小为 C
- 一致
我们希望模型输出的概率分布和真实分布的尽量相似,可以利用信息论中的交叉熵来衡量两个概率分布的距离,离散情况下两个概率分布的交叉熵 H(y^,y)
如下:
考虑CBOW中的情况,此时 y
是一个one-hot向量,假设 y 的第 i维为1,那么交叉熵可以简化成:
可以看出交叉熵的最小值为0,优化目标就是最小化交叉熵:
由上描述可知整个模型的未知参数就是 W(1)
和 W(2) ,即对于每个输出向量 v(j) 和上下文中的输入向量 (u(i−C),…,u(i−1),u(i+1),…,u(i+C))求导。
首先是 ∂J∂v(j)

然后对窗口内的其中一个输入向量求导 ∂J∂u(i−C)
,其他输入向量求导方法与之相同,最后结果相等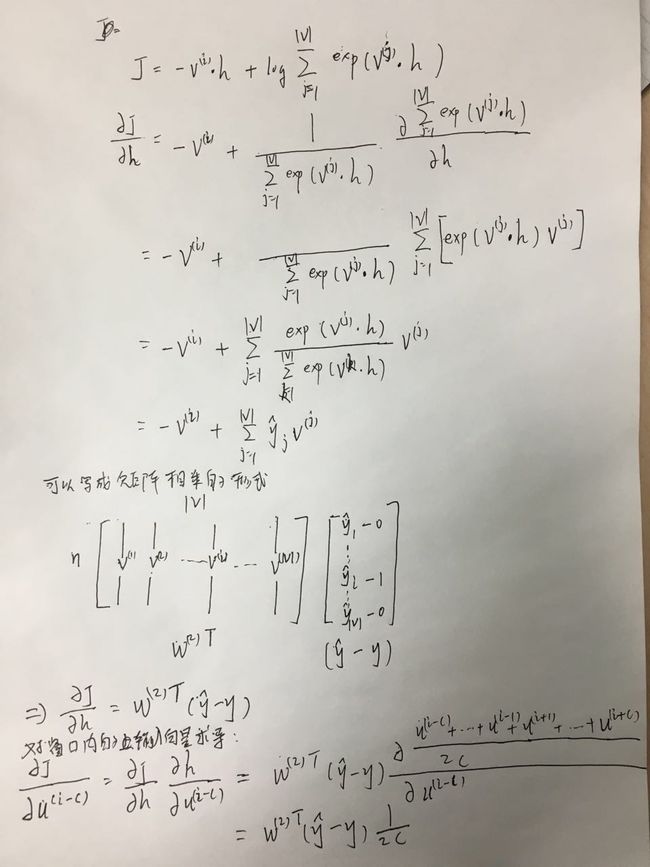
Skip-Gram
Skip-Gram的基本思想用当前词预测窗口长度为 C
内的其他词,此时模型的输入是中心词one-hot向量 x ,窗口内的词one-hot向量为 (y(i−C),…,y(i−1),y(i+1),…,y(i+C))。 利用中心词预测周边词的过程如下:
- 输入one-hot向量为 x
- 一致
这里把 P(w(i−C),…,w(i−1),w(i+1),…,w(i+C)|w(i))
整体看成一个分布, 然后用朴素贝叶斯假设来简化这个条件概率的求解,即:
对于这个损失函数我们可以先不考虑对窗口内的所有词求和,假设我们现在只针对窗口内的特定词 w(j)
进行预测, 此时
该损失函数对于每个输出向量的导数的求解结果与CBOW类似,损失函数对于输入向量的求导结果也和CBOW类似。唯一的区别在于skip-gram的输入向量只有一个,所以 J
对于 u(i) 的导数直接为 W(2)T(y^−y) 不需要除以 2C。
负采样
上述的CBOW和Skip-Gram模型都存在一个问题,就是损失函数都有一个求和是 |V|
规模的,这个计算非常耗时,英文的词汇表规模大概是1300万。负采样是基于Skip-Gram模型,但是和优化目标和Skip-Gram不同。给定一对词 (w,c) ,其中 w 是中心词, c 代表 w 的上下文窗口内出现的另一个词,用 P(D=1|w,c) 表示 (w,c) 确实出现在语料中的概率,相应的 P(D=0|w,c) 表示 (w,c) 没有出现在语料中的概率。用sigmoid函数(下文用 σ 表示sigmoid函数)来表示 P(D=1|w,c) 这个概率,这里用 vc 表示输出向量, uw表示输入向量。
我们期望优化的目标是希望真实存在语料中 (w,c)
对 P(D=1|w,c) 最大化,同时不存在语料中的 (w,c) 对 P(D=0|w,c) 概率最大化,公式中的 θ 包括了上面提到的两个矩阵 W(1) 和 W(2) ,我们希望 θ 满足下列公式: 上述推导中用到需要用到了一个等式 1−σ(x)=σ(−x) ,这个等式比较好验证,其中 D~
上述推导中用到需要用到了一个等式 1−σ(x)=σ(−x) ,这个等式比较好验证,其中 D~ 为负样本。由此可得新的 目标函数
在这个目标函数中 vk
是从 Pn(w) 从采样出来的,这个 Pn(w) 是unigram概率 U(w) 的 3/4次方, 这样可以增大一些概率很小的词被采样出来的概率。
可以求得 ∂J∂uw
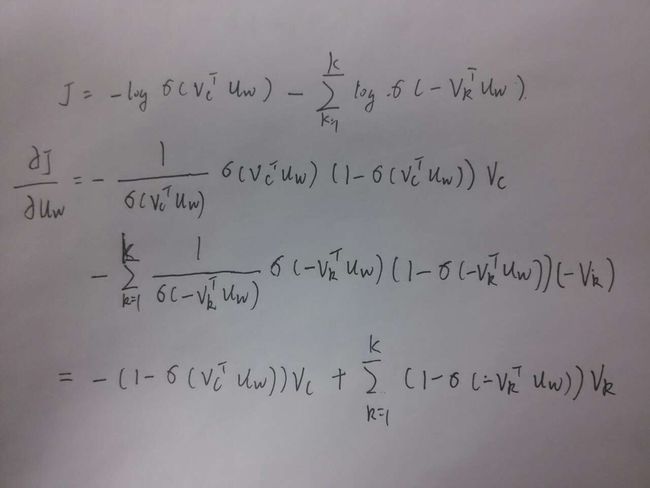
然后是 J
对相关的输出向量求导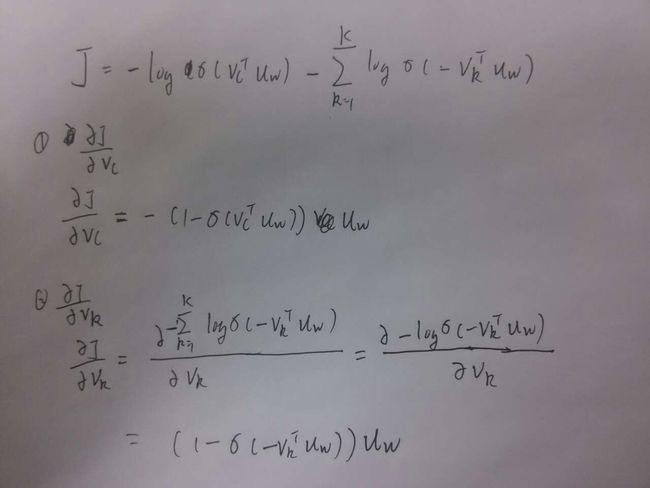
求得梯度之后可以采用随机梯度下降优化目标函数,得到向量表示。上述三种方法训练完成之后对于每个词都会得到两个向量,一个是作为模型输入时的向量,一个是作为模型输出时的向量,最后的向量表示是把这两种向量相加使用,即对于词 w(i)
的向量为 v(i)+u(i)。
词向量评测
词向量的评测方法可以分为内部(intrinsic)评测和外部(extrinsic)评测,两种评测的对比如下:
- 内部评测:
- 在一个特定的子任务中进行评测
- 计算迅速
- 有助于理解相关的系统
- 不太清楚是否有助于真实任务除非和实际的NLP任务的相关性已经建立起来
- 外部评测:
- 在一个真实任务中进行评测
- 需要花很长的实际来计算精度
- 不太清楚是否是这个子系统或者其他子系统引起的问题
- 如果用这个子系统替换原有的系统后获得精度提升–>有效(Winning!)
词向量内部评测方法
词向量内部评测方法主要有词向量类比、词向量相关度,这两种方法有相应的数据集。
词向量类比的基本思想如下
目前评测的数据集主要是word2vec项目提供的数据集包含了语义类比和语法类比两种。语义类比的数据有州名包含城市名、首都和国家, 语法类比的数据是比较级类比和时态类比。
词向量相关度的数据集例如WordSim353,该数据集是人为地给两个词的相关度打分(从0-10),然后通过计算词向量的Cosine相似度与 这个相关度进行对比。
词向量外部评测方法
简单来说就是把词向量应用于具体的任务中来评测不同的词向量对于任务整体性能的影响。这里需要注意的问题是,应用于具体任务的时候是否还需要调整词向量, 一般来说调整词向量会降低向量的范化能力。所以一般具体任务的训练集足够大时才考虑调整词向量。