AI预测世界杯冠军?附完整代码!
 (本内容转载自公众号“科技与Python”)
(本内容转载自公众号“科技与Python”)
2018 年 FIFA 世界杯已经拉开帷幕,究竟谁将获得那梦寐以求的大力神杯?
如果你不仅是个足球迷,而且也是高科技人员,你肯定知道机器学习和人工智能这两个比较火的词。
让我们结合两者来预测一下本届俄罗斯 FIFA 世界杯哪个国家将夺冠。
足球比赛涉及的因素非常繁多,无法将所有因素都融入机器学习模型中。本文的目标是:
-
1.用机器学习来预测谁将赢得2018 FIFA世界杯的冠军;
-
2.预测整个比赛的小组赛结果;
-
3.模拟四分之一决赛、半决赛以及决赛。
下面将从数据集成、特征建模和结果预测这三个方面来介绍。
数据
我采用了两个来自 Kaggle 的数据集,我们将使用自 1930 年第一届世界杯以来所有参赛队的历史赛事结果。
FIFA 排名是于 90 年代创建的,因此这里缺失很大一部分数据,所以我们使用历史比赛记录。点击以下链接获取所有数据 :
https://www.kaggle.com/martj42/international-football-results-from-1872-to-2017/data;
本文中主要使用的环境和工具有:jupyter notebook、numpy、pandas、seaborn、matplotlib 和 scikit-learn。
首先,我们要针对两个数据集做探索性分析,然后经过特征工程来选择与预测关联性最强的特征,还有数据处理,再选择一个机器学习模型,最后将模型配置到数据集上。
让我们开始动手吧!
首先,导入所需的代码库,并将数据集加载到数据框中:

导入代码库:

下一步是加载数据集。如下所示:
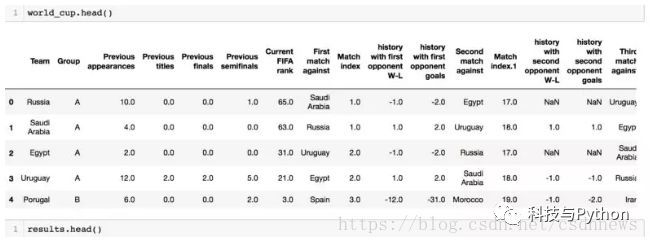
在分析了两组数据集后,所得的数据集包含了以往赛事的数据——这个新的(所得的)数据集对于分析和预测将来的赛事非常有帮助。
探索性分析和特征工程:需要建立与机器学习模型相关的特征,在任何数据科学的项目中,这部分工作都是最耗时的。
现在我们把目标差异和结果列添加到结果数据集:
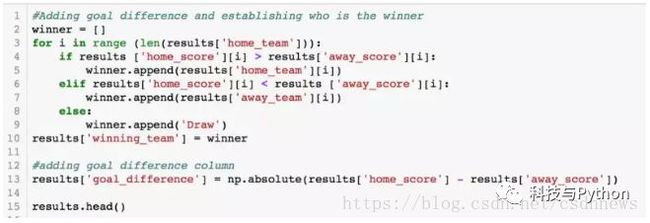
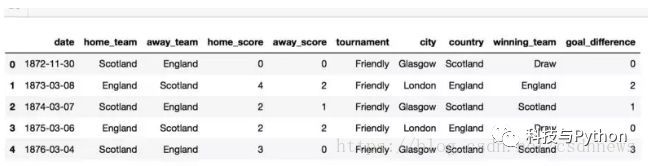
检查一下新的结果数据框:
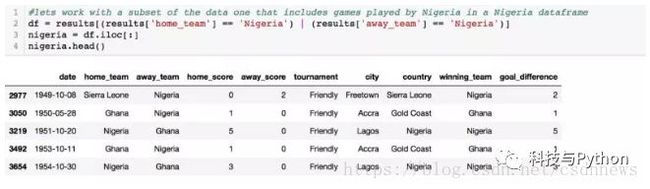
然后我们着手处理仅包含尼日利亚参加比赛的一组数据(这可以帮助我们集中找出哪些特征对一个国家有效,随后再扩展到参与世界杯的所有国家):
第一届世界杯于 1930 年举行。我们为年份创建一列,并选择所有 1930 年之后举行的比赛:
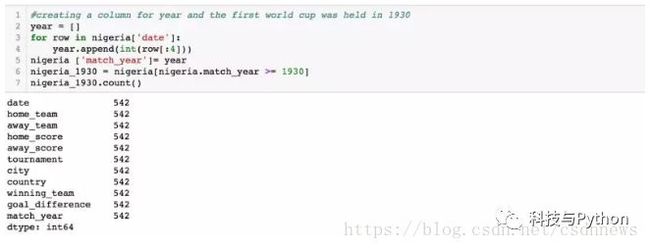
现在我们可以用图形表示这些年来尼日利亚队最普遍的比赛结果:
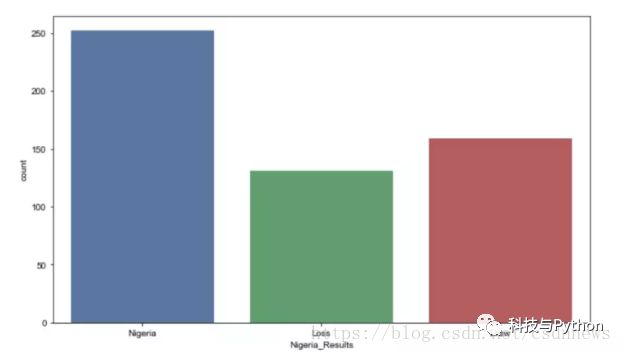
每个参加世界杯的国家的胜率是非常有帮助性的指标,我们可以用它来预测此次比赛最可能的结果。
锁定参加世界杯的队伍
我们为所有参赛队伍创建一个数据框:

然后从该数据框中进一步筛选出从 1930 年起参加世界杯的队伍,并去掉重复的队伍:

为年份创建一列,去掉 1930 年之前的比赛,并去掉不会影响到比赛结果的数据列,比如 date(日期)、home_score(主场得分)、away_score(客场得分)、tournament(锦标赛)、city(城市)、country(国家)、goal_difference(目标差异)和 match_year(比赛年份):
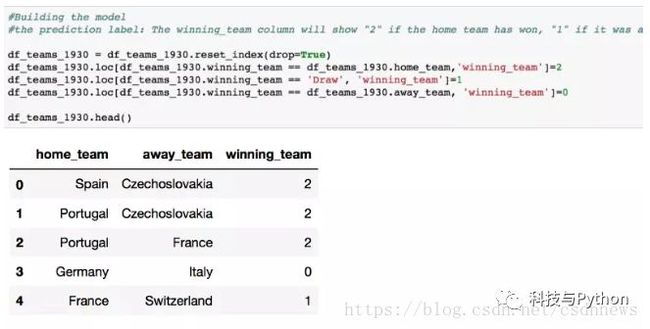
为了简化模型的处理,我们修改一下预测标签。
如果主场队伍获胜,那么 winning_team(获胜队伍)一列显示“2”,如果平局则显示“1”,如果是客场队伍获胜则显示“0”:
通过设置哑变量(dummy variables),我们将 home_team(主场队伍)和away _team(客场队伍)从分类变量转换成连续的输入。
这时可以使用 pandas 的 get_dummies() 函数,它会将分类列替换成一位有效值(one-hot,由数字‘1’和‘0’组成),以便将它们加载到 Scikit-learn 模型中。
接下来,我们将数据按照 70% 的训练数据集和 30% 的测试数据集分成 X 集和 Y 集:

这里我们将使用分类算法:逻辑回归。
在实践中这种方法的工作原理是:使用上述的两套“数据集”和比赛的实际结果,一次输入一场比赛到算法中。然后模型就会学习输入的每条数据对比赛结果产生了积极的效果还是消极的效果,以及影响的程度。
经过充分的(好)数据的训练后,就可以得到能够预测未来结果的模型,而模型的好坏程度取决于输入的数据。
让我们看看最终的数据框:

看起来很不错。现在我们将这些数据传递到算法中:
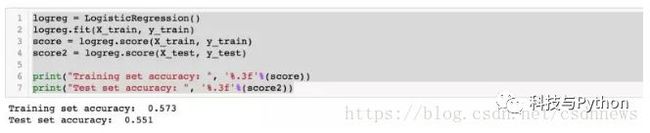
我们的模型子训练数据集的正确率为 57%,在测试数据集上的正确率为 55%。虽然结果不是很好,但是我们先继续下一步。
接下来我们建立需要配置到模型的数据框。
首先我们加载 2018 年 4 月 FIFA 排名数据和小组赛分组状况的数据集。由于世界杯比赛中没有“主场”和“客场”,所以我们把 FIFA 排名靠前的队伍作为“喜爱”的比赛队伍,将他们放到“home_teams”(主场队伍)一列。然后我们根据每个队伍的排名将他们加入到新的预测数据集中。下一步是创建默认变量,并部署机器学习模型。
2018 年 4 月 FIFA 排名数据:
https://us.soccerway.com/teams/rankings/fifa/?ICID=TN_03_05_01
小组赛分组状况的数据集:
https://fixturedownload.com/results/fifa-world-cup-2018
比赛结果预测
到这里你可能在想我们究竟什么时候开始预测啊?看了这么多代码和唠叨,究竟什么时候才给我们看预测结果?别着急,我们马上就要开始了……
将模型部署到数据集中
首先,我们将模型部署到小组赛中:
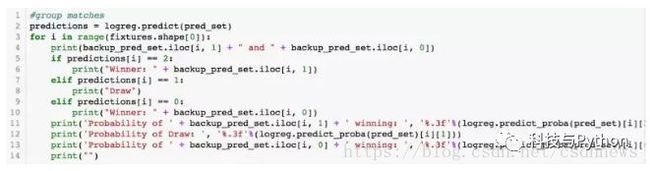
以下是小组赛的结果:

该模型的预测中出现了三场平局,并且获胜队伍会在葡萄牙和西班牙之间,且判定西班牙有更高的获胜概率。我使用该网站(https://ultra.zone/2018-FIFA-World-Cup-Group-Stage)模拟了小组赛。
以下是 16 强淘汰赛的模拟:
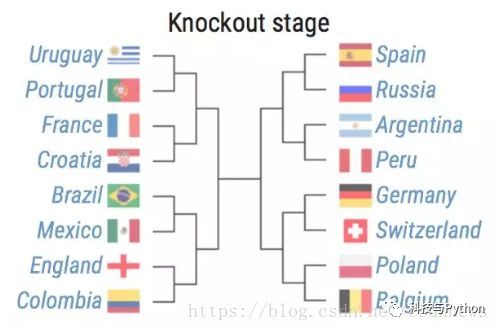
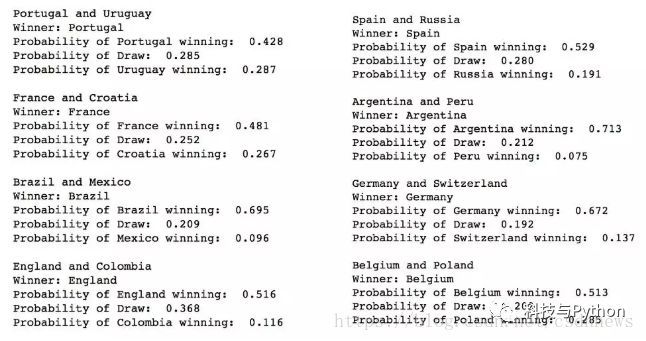
模型预测的四分之一决赛——葡萄牙vs法国,巴西vs英格兰,西班牙vs阿根廷,德国vs比利时。
下面是结果预测:
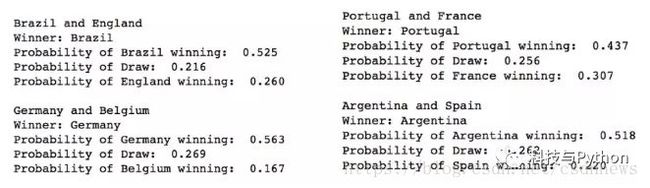
半决赛的阵容是——葡萄牙vs巴西,德国vs阿根廷。
结果预测:
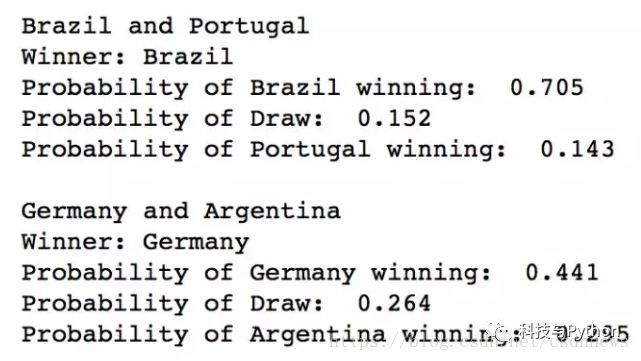
最后的冠军比赛是——巴西vs德国。
结果预测:

根据该模型,巴西将有可能获得本届世界杯的冠军。
进一步的研究和提高领域
1.为提高数据集的质量,可以利用 FIFA 的比赛数据评估每个球员的水平;
2.混淆矩阵可以帮助我们分析模型预测的哪场有误;
3.我们可以尝试将多个模型组合在一起,提高预测准确度。
获取完整代码只需关注该公众号,后台回复“世界杯”即可得到完整代码!
最新大数据及算法竞赛资讯
(只需关注我们,即可得到最新竞赛资讯)
资料赠送
5000+PPT模板 | 1000+简历模板 | 无人驾驶相关资料
(只需关注我们,即可得到相关资料)
