问答QA(二)基于BERT的知识库问答实战
GitHub: https://github.com/jkszw2014/bert-kbqa-NLPCC2017
一、问题描述
本篇知识问答实战来源NLPCC2017的Task5:Open Domain Question Answering;其包含 14,609 个问答对的训练集和包含 9870 个问答对的测试集。并提供一个知识库,包含 6,502,738 个实体、 587,875 个属性以及 43,063,796 个三元组。
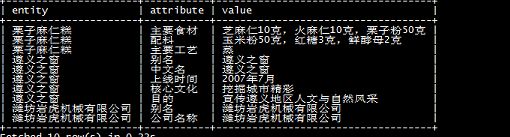
- 知识库(nlpcc-iccpol-2016.kbqa.kb)
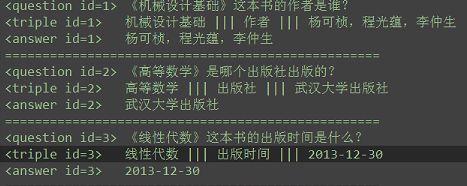
- 训练集(nlpcc-iccpol-2016.kbqa.traing-data)
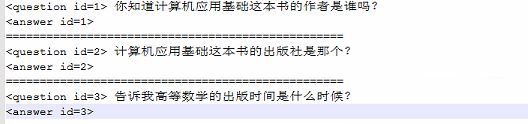
- 测试集(nlpcc-iccpol-2016.kbqa.testing-data,提交结果进行评测)
二、解决方案
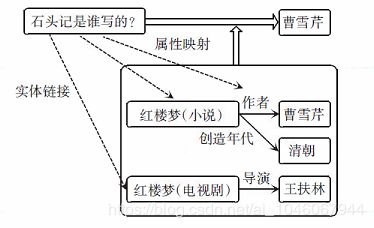
基于知识库的自动问答拆分为2 个主要步骤: 命名实体识别步骤和属性映射步骤。其中,实体识别步骤的目的是找到问句中询问的实体名称,而属性映射步骤的目的在于找到问句中询问的相关属性。
- 命名实体识别步骤,采用BERT+BiLSTM+CRF方法(另外加上一些规则映射,可以提高覆盖度)
- 属性映射步骤,转换成文本相似度问题,采用BERT作二分类(对于歧义答案,需要有问答上下文)
思路参考文章:
InsunKBQA: 一个基于知识库的问答系统
基于知识图谱的问答系统入门—NLPCC2016KBQA数据集
三、BERT命名实体识别效果:(https://github.com/jkszw2014/bert-kbqa-NLPCC2017/tree/master/NER_BERT-BiLSTM-CRF)
- 构造NER的数据集,需要根据三元组-Enitity 反向标注问题,给 Question 打标签。
代码: python ./NLPCC2016KBQA/construct_dataset.py
训练集:
《机械设计基础》这本书的作者是谁? 机械设计基础
标注后:
《 O
机 B-LOC
械 I-LOC
设 I-LOC
计 I-LOC
基 I-LOC
础 I-LOC
》 O
这 O
本 O
书 O
的 O
作 O
者 O
是 O
谁 O
? O
- 训练代码:
python bert_lstm_ner.py \
--task_name="NER" \
--do_train=True \
--do_eval=True \
--do_predict=True \
--data_dir=NERdata \
--max_seq_length=128 \
--train_batch_size=32 \
--learning_rate=2e-5 \
--num_train_epochs=3.0 \
--output_dir=./output/result_dir_ner/ - 预测代码:
python terminal_predict.py
结果:识别实体还是可以,统计过准确率,还不错。(结果文件: ./NERdata/q_t_a_testing_predict.txt)

四、BERT属性映射效果评估(https://github.com/jkszw2014/bert-kbqa-NLPCC2017/tree/master/AttributeMap-BERT-Classification)
- 构造BERT二分类问题的数据集:
1. 构造测试集的整体属性集合,提取+去重,获得 4373 个属性 RelationList;
2. 一个 sample 由“问题+属性+Label”构成,原始数据中的属性值置为 1;
3. 从 RelationList 中随机抽取五个属性作为 Negative Samples。

构造数据集代码:
python ./NLPCC2016KBQA/construct_dataset_attribute.py
生成的文件,移动到data_kbqa目录下: val.txt test.txt train.txt
- 训练代码:
export BERT_BASE_DIR=/home/bert/chinese_L-12_H-768_A-12
export MY_DATASET=/home/bert/data_sim
python run_classifier.py \
--data_dir=$MY_DATASET \
--task_name=similarity \
--vocab_file=$BERT_BASE_DIR/vocab.txt \
--bert_config_file=$BERT_BASE_DIR/bert_config.json \
--output_dir=./data_sim/output/ \
--do_train=true \
--do_eval=true \
--init_checkpoint=$BERT_BASE_DIR/bert_model.ckpt \
--max_seq_length=128 \
--train_batch_size=32 \
--learning_rate=5e-5\
--num_train_epochs=2.0
INFO:tensorflow:***** Eval results *****
INFO:tensorflow: eval_accuracy = 0.98575
INFO:tensorflow: eval_loss = 0.06471516
INFO:tensorflow: global_step = 4727
INFO:tensorflow: loss = 0.06471516- 测试结果:
export BERT_BASE_DIR=/home/bert/chinese_L-12_H-768_A-12
export MY_DATASET=/home/bert/data_kbqa
python run_classifier.py \
--task_name=similarity \
--do_predict=true \
--data_dir=$MY_DATASET \
--vocab_file=$BERT_BASE_DIR/vocab.txt \
--bert_config_file=$BERT_BASE_DIR/bert_config.json \
--init_checkpoint=./data_kbqa/output \
--max_seq_length=128 \
--output_dir=./data_kbqa/output/
----预测准确率: 0.986
import pandas as pd
test_df = pd.read_csv('test.csv',header=None,sep = '\t')
test_label = test_df[3].tolist()
test_predict_df = pd.read_csv('./output/test_results.tsv',header=None,sep = '\t')
test_predict_df['label'] = test_predict_df.apply(lambda x: 0 if x[0] > x[1] else 1, axis=1)
test_predict_label = test_predict_df['label'].tolist()
result = [1 if x==y else 0 for x,y in zip(test_label,test_predict_label)]
sum(result)/len(result)
0.9863194162950952
【参考文献】
【1】基于该数据集实现的论文 http://www.doc88.com/p-9095635489643.html
【2】 NLPCC比赛数据集下载页面
http://tcci.ccf.org.cn/conference/2017/taskdata.php
http://tcci.ccf.org.cn/conference/2016/pages/page05_evadata.html
【3】InsunKBQA_一个基于知识库的问答系统_周博通_孙承杰_林磊_刘秉权 http://www.doc88.com/p-9095635489643.html
【4】 基于知识库的问答:seq2seq模型实践 https://zhuanlan.zhihu.com/p/34585912
【5】基于BERT预训练的中文命名实体识别TensorFlow实现 https://blog.csdn.net/macanv/article/details/85684284