Hadoop基础教程-第12章 Hive:进阶(12.3 HiveServer2)(草稿)
第12章 Hive:进阶
12.3 HiveServer2
12.3.1 HiveServer1
HiveServer是一种可选服务,允许远程客户端可以使用各种编程语言向Hive提交请求并检索结果。HiveServer是建立在Apache ThriftTM(http://thrift.apache.org/) 之上的,因此有时会被称为Thrift Server,这可能会导致混乱,因为新服务HiveServer2也是建立在Thrift之上的.自从引入HiveServer2后,HiveServer也被称为HiveServer1。
HiveServer无法处理来自多个客户端的并发请求.这实际上是HiveServer导出的Thrift接口所施加的限制,也不能通过修改HiveServer源代码来解决。HiveServer2对HiveServer进行了重写,来解决这些问题,从Hive 0.11.0版本开始。建议使用HiveServer2。
12.3.2 HiveServer2
HiveServer2是一种能使客户端执行Hive查询的服务。 HiveServer2是HiveServer1的改进版,HiveServer1已经被废弃。从Hive 2.0版本开始,为HiveServer2提供了一个简单的WEBUI界面,界面中可以直观的看到当前链接的会话、历史日志、配置参数以及度量信息, 所以配置一个HiveServer2的UI端口
默认值:
hive.server2.thrift.port:10000
hive.server2.webui.port:10002
开启hiveserver2服务
[root@node3 ~]# hive --service hiveserver2 >/dev/null 2>/dev/null &
[4] 3889
[root@node3 ~]#其中,输出的3889是hiveserver2的pid,需要关闭hiveserver2服务时可以通过该pid进行kill。
[root@node3 ~]# jps
2723 QuorumPeerMain
3889 RunJar
2873 JournalNode
2779 DataNode
2973 NodeManager
4093 Jps
[root@node3 ~]# jps -ml
2723 org.apache.zookeeper.server.quorum.QuorumPeerMain /opt/zookeeper-3.4.10/bin/../conf/zoo.cfg
3889 org.apache.hadoop.util.RunJar /opt/hive-2.1.1/lib/hive-service-2.1.1.jar org.apache.hive.service.server.HiveServer2
4103 sun.tools.jps.Jps -ml
2873 org.apache.hadoop.hdfs.qjournal.server.JournalNode
2779 org.apache.hadoop.hdfs.server.datanode.DataNode
2973 org.apache.hadoop.yarn.server.nodemanager.NodeManager
[root@node3 ~]#通过命令netstat -pan查看所有的进程和端口使用情况,其中最后一栏是PID/Program name
[root@node3 ~]# netstat -pan | grep 10000
tcp 0 0 0.0.0.0:10000 0.0.0.0:* LISTEN 3889/java
[root@node3 ~]#发现端口号10000被PID是3889的Java进程占用。
http://192.168.80.133:10002/hiveserver2.jsp

Beeline工作模式有两种,即本地嵌入模式和远程模式。嵌入模式情况下,它返回一个嵌入式的Hive(类似于Hive CLI)。
而远程模式则是通过Thrift协议与某个单独的HiveServer2进程进行连接通信。
12.3.3 JDBC连接Hive
4.0.0
cn.hadron
hive
0.0.1-SNAPSHOT
jar
hive
http://maven.apache.org
UTF-8
junit
junit
3.8.1
test
org.apache.hive
hive-jdbc
1.2.1
org.apache.hadoop
hadoop-common
2.7.1
jdk.tools
jdk.tools
1.8
system
${JAVA_HOME}/lib/tools.jar
package cn.hadron.hive.dao;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
public class HiveDao {
// hive的jdbc驱动类
private static String dirverName = "org.apache.hive.jdbc.HiveDriver";
// 连接hive的URL hive1.2.1版本需要的是jdbc:hive2,而不是 jdbc:hive
private static String url = "jdbc:hive2://192.168.1.160:10000/default";
// 登录linux的用户名 一般会给权限大一点的用户,否则无法进行事务形操作
private static String user = "root";
// 登录linux的密码
private static String password = "123456";
private Connection connection;
private PreparedStatement ps;
private Statement st;
private ResultSet rs;
public void getConnection() {
try {
Class.forName("org.apache.hive.jdbc.HiveDriver");
connection = DriverManager.getConnection("jdbc:hive2://192.168.18.130:10000/", user, password);
System.out.println(connection);
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
}
}
public void getConnection(String ip) {
try {
Class.forName("org.apache.hive.jdbc.HiveDriver");
connection = DriverManager.getConnection("jdbc:hive2://" + ip + ":10000/", user, password);
System.out.println(connection);
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
}
}
public void getConnection(String ip, String db) {
try {
StringBuilder sb = new StringBuilder();
sb.append("jdbc:hive2://").append(ip).append(":10000/").append(db);
Class.forName("org.apache.hive.jdbc.HiveDriver");
connection = DriverManager.getConnection(sb.toString(), user, password);
System.out.println(connection);
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
}
}
public void createDatabase(String dbName) {
try {
String sql = "create database if not exists " + dbName;
ps = connection.prepareStatement(sql);
// true if the first result is a ResultSet object;
// false if the first result is an update count or there is no result
ps.execute();
} catch (SQLException e) {
e.printStackTrace();
}
}
public void createTable(String sql) {
try {
ps = connection.prepareStatement(sql);
ps.execute();
} catch (SQLException e) {
e.printStackTrace();
}
}
public void dropTable(String tableName) {
String sql = "drop table if exists " + tableName;
try {
st = connection.createStatement();
st.execute(sql);
} catch (SQLException e) {
e.printStackTrace();
}
}
// 添加数据
public boolean load(String loadData) {
try {
ps = connection.prepareStatement(loadData);
return ps.execute();
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
return false;
}
}
public ResultSet query(String sql) {
try {
ps = connection.prepareStatement(sql);
return ps.executeQuery();
} catch (SQLException e) {
e.printStackTrace();
return null;
}
}
public void descTables(String tableName){
String sql = "desc " + tableName;
try {
st = connection.createStatement();
rs=st.executeQuery(sql);
while (rs.next()) {
System.out.println(rs.getString(1) + "\t" + rs.getString(2));
}
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
// 关闭连接
public void close() {
try {
if (rs != null) {
rs.close();
}
if (ps != null) {
ps.close();
}
if (connection != null) {
connection.close();
}
} catch (SQLException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
HiveDao dao = new HiveDao();
dao.getConnection("192.168.1.157");
dao.createDatabase("mydb");
dao.dropTable("mydb.goods");
dao.createTable("create table mydb.goods(id int,name string) row format delimited fields terminated by '\t' ");
dao.load("load data inpath 'input/goods.txt' into table mydb.goods");
dao.descTables("mydb.goods");
ResultSet rs=dao.query("select * from mydb.goods");
try {
while(rs.next()){
System.out.println(rs.getInt(1)+"\t"+rs.getString(2));
}
} catch (SQLException e) {
e.printStackTrace();
}
dao.close();
}
}log4j:WARN No appenders could be found for logger (org.apache.hive.jdbc.Utils).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
org.apache.hive.jdbc.HiveConnection@7a0ac6e3
id int
name string
1 Java
2 Java EE
3 Android
4 Hadoop
5 Zookeeper
6 Hive
7 HBase
8 Sparkhive> show databases;
OK
default
mydb
Time taken: 2.165 seconds, Fetched: 2 row(s)
hive> use mydb;
OK
Time taken: 0.056 seconds
hive> show tables;
OK
goods
Time taken: 0.063 seconds, Fetched: 1 row(s)
hive> select * from goods;
OK
1 Java
2 Java EE
3 Android
4 Hadoop
5 Zookeeper
6 Hive
7 HBase
8 Spark
Time taken: 0.908 seconds, Fetched: 8 row(s)
hive>12.3.5 HiveServer2 HA
(1)HiveServer2的优点
在生产环境中使用Hive,强烈建议使用HiveServer2来提供服务,好处很多:
在应用端不用部署Hadoop和hive客户端;
相比hive-cli方式,HiveServer2不用直接将HDFS和Metastore暴漏给用户;
有安全认证机制,并且支持自定义权限校验;
有HA机制,解决应用端的并发和负载均衡问题
JDBC方式,可以使用任何语言,方便与应用进行数据交互;
从2.0开始,HiveServer2提供了WEB UI。
(2)单点故障
如果使用HiveServer2的Client并发比较少,可以使用一个HiveServer2实例,没问题。 
但如果这一个实例挂掉,那么会导致所有的应用连接失败。
(3)高可用
Hive从0.14开始,使用Zookeeper实现了HiveServer2的HA功能(ZooKeeperService Discovery),Client端可以通过指定一个nameSpace来连接HiveServer2,而不是指定某一个host和port。 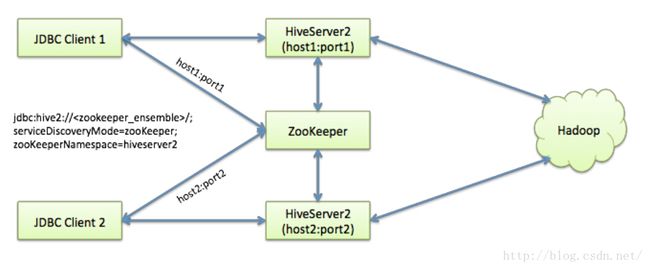
(4)HA 配置
hive-site.xml
hive.server2.support.dynamic.service.discovery
true
hive.server2.zookeeper.namespace
hiveserver2_zk
hive.zookeeper.quorum
node1:2181,node2:2181,node3:2181
hive.zookeeper.client.port
2181
hive.server2.thrift.bind.host
0.0.0.0
hive.server2.thrift.port
10001 //两个HiveServer2实例的端口号要一致