Python实现梯度下降法及算例分析以及可视化
代码和算例可以到博主github中下载:
https://github.com/Airuio/Implementing-the-method-of-gradient-descent-by-using-Python-
上一篇讲解了最原始的感知机算法,该算法的目的只为收敛,得到的往往不是基于样本的最佳解,梯度下降法以最小化损失函数为目标,得到的解比原始感知机算法一般更准确。
梯度下降法算法原理如下图所示:
基于以上原理来对权重系数和闵值进行更新即可得到最后的解。
原理实现可按如下代码操作:
#实现梯度下降法:
import numpy as np
class AdalineGD(object):
def __init__(self,eta=0.01,n_iter=50): #定义超参数学习率和迭代次数
self.eta = eta
self.n_iter = n_iter
def fit(self,X,y): #定义权重系数w和损失函数cost
self.w_ = np.zeros(1+X.shape[1])
self.cost_ = []
for i in range(self.n_iter): #更新权重
output = self.net_input(X) #计算预测值
errors = (y - output) #统计误差
self.w_[1:] += self.eta*X.T.dot(errors)
self.w_[0] += self.eta * errors.sum()
cost = (errors**2).sum()/2.0 #损失函数
self.cost_.append(cost)
return self
def net_input(self,X):
return np.dot(X,self.w_[1:]) + self.w_[0]
def activation(self,X):
return self.net_input(X)
def predict(self, X):
return np.where(self.activation(X) >= 0.0, 1, -1)
以上算法即实现了梯度下降法更新权重参数。将该模块命名为Adaline_achieve,基于鸢尾花lirs数据集,我们进行算例的验证如下所示:
from Adaline_achieve import AdalineGD
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
df = pd.read_excel(io = 'lris.xlsx',header = None) #读取数据为Dataframe结构,没有表头行
y = df.iloc[0:100,4].values #取前100列数据,4列为标识
y = np.where(y == 'Iris-setosa', -1,1)
X = df.iloc[0:100,[0,2]].values #iloc为选取表格区域,此处取二维特征进行分类,values为返回不含索引的表
plt.scatter(X[:50,0],X[0:50,1],color = 'red',marker = 'o', label = 'setosa')
plt.scatter(X[50:100,0],X[50:100,1],color = 'blue',marker = 'x', label = 'versicolor')
plt.xlabel('petal lenth')
plt.ylabel('sepal lenth')
plt.legend(loc = 2) #画出标签以及标签的位置参数
plt.show() #出图
#以上六行与分类无关,仅仅是为了直观的感受两块数据的分布区域
fig,ax = plt.subplots(nrows = 1 , ncols = 2, figsize = (8,4))
'''
完成不同学习率下的分类的任务,进行结果展示
plt.subplots(nrows = 1 , ncols = 2, figsize = (8,4)中nrows表示几行图,ncols表示几列
figsize为图片大小。
'''
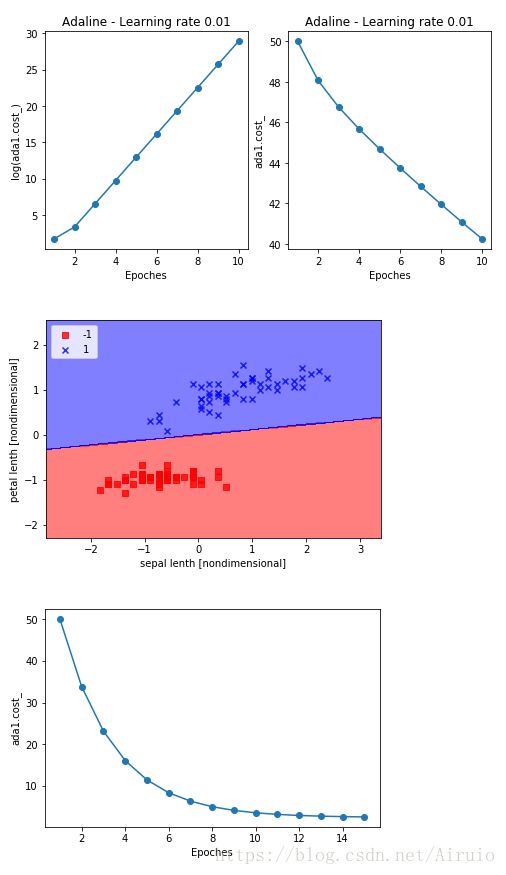
ada1 = AdalineGD(eta = 0.01,n_iter = 10).fit(X,y)
ax[0].plot(range(1,len(ada1.cost_) + 1), np.log10(ada1.cost_) , marker = 'o')
ax[0].set_xlabel('Epoches')
ax[0].set_ylabel('log(ada1.cost_)')
ax[0].set_title('Adaline - Learning rate 0.01')
ada2 = AdalineGD(eta = 0.0001,n_iter = 10).fit(X,y)
ax[1].plot(range(1,len(ada2.cost_) + 1), ada2.cost_ , marker = 'o')
ax[1].set_xlabel('Epoches')
ax[1].set_ylabel('ada1.cost_')
ax[1].set_title('Adaline - Learning rate 0.01')
plt.show()
'''
由以上得到的结果图可以看出,学习率过大会导致不收敛,过小会导致收敛速度慢
采用数据标准化、归一化的方法可以使得梯度下降法取得更好的效果
对同维度处的样本特征取均值和标准差,标准化后的值等于:
(原值-均值)/标准差,可以用numpy中的mean和std方法便捷的获得
'''
X_std = np.copy(X) #将样本特征归一化、标准化
X_std[:,0] = (X[:,0] - X[:,0].mean()) / X[:,0].std()
X_std[:,1] = (X[:,1] - X[:,1].mean()) / X[:,1].std()
ada = AdalineGD(eta = 0.01, n_iter = 15)
ada.fit(X_std,y)
def plot_decision_region(X,y,classifier,resolution = 0.02):
markers = ('s','x','o','~','v')
colors = ('red','blue','lightgreen','gray','cyan')
cmap = ListedColormap(colors[:len(np.unique(y))])
#画出界面
x1_min, x1max = X[:,0].min() - 1, X[:,0].max() + 1
x2_min, x2max = X[:,1].min() - 1, X[:,1].max() + 1
xx1,xx2 = np.meshgrid(np.arange(x1_min,x1max,resolution),
np.arange(x2_min,x2max,resolution)) #生成均匀网格点,
'''
meshgrid的作用是根据传入的两个一维数组参数生成两个数组元素的列表。如果第一个参数是xarray, 维度是xdimesion,第二个参数是yarray,维度是ydimesion。那么生成的第一个二维数组是以xarray为行,ydimesion行的向量;而第二个二维数组是以yarray的转置为列,xdimesion列的向量。
'''
Z = classifier.predict(X = np.array([xx1.ravel(),xx2.ravel()]).T)Z = Z.reshape(xx1.shape)
#在全图上每一个点(间隔0.2)计算预测值,并返回1或-1
plt.contourf(xx1,xx2,Z,alpha = 0.5,cmap = cmap) #画出等高线并填充颜色
plt.xlim(xx1.min(),xx1.max())
plt.ylim(xx2.min(),xx2.max())
#画上分类后的样本
for idx,cl in enumerate(np.unique(y)):
plt.scatter(x=X[y==cl,0], y=X[y==cl,1],alpha=0.8,
c=cmap(idx),marker=markers[idx],label=cl)
plot_decision_region(X_std, y, classifier = ada) #展示分类结果
plt.xlabel('sepal lenth [nondimensional]')
plt.ylabel('petal lenth [nondimensional]')
plt.legend(loc = 2)
plt.show()
plt.plot(range(1,len(ada.cost_)+1),ada.cost_,marker = 'o') #展示损失函数误差收敛过程
plt.xlabel('Epoches')
plt.ylabel('ada1.cost_')
plt.show()
结果如下图所示: