GROUP BY!ROLLUP,CUBE,GROUPPING,GROUPING_ID,GROUPING SETS详解
原文地址:https://www.cnblogs.com/injet/p/10493930.html
ROLL UP
ROLL UP 搭配 GROUP BY 使用,可以为每一个分组返回一个小计行,为所有分组返回一个总计行。
直接看例子,我们有以下数据表,包含工厂列,班组列,数量列三列。
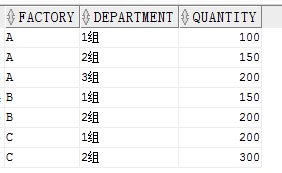
当向 ROLLUP 传入一列时,会得到一个总计行。
SELECT factory,
SUM(quantity)
FROM production
GROUP BY ROLLUP(factory)
ORDER BY factory结果:
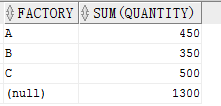
当向 ROLLUP 传递两列时,将会按照这两列进行分组,同时按照第一列的分组结果返回小计行。我们同时传入工厂和部门看一下。
SELECT factory,department,
SUM(quantity)
FROM production
GROUP BY ROLLUP(factory, department)
ORDER BY factory结果:
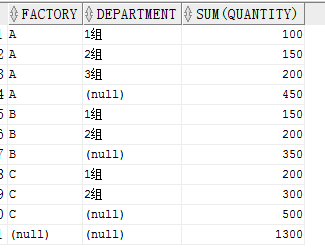
可以看到对每一个工厂都有一个小计行,最后对所有的有一个总计行。也可以这样理解
如果 ROLLUP(A,B)则先对 A,B进行 GROUP BY,之后对 A 进行 GROUP BY,最后对全表 GROUP BY。
如果 ROLLUP(A,B,C)则先对 A,B,C进行 GROUP BY ,然后对 A,B进行GROUP BY,再对 A 进行GROUP BY,最后对全表进行 GROUP BY.
CUBE
CUBE 和 ROLLUP 对参数的处理是不同的,我们可以这样理解。
如果 CUBE(A,B)则先对 A,B 进行 GROUP BY,之后对 A 进行 GROUP BY,然后对 B 进行 GROUP BY,最后对全表进行 GROUP BY.
如果 CUBE(A,B,C)则先对 A,B,C 进行 GROUP BY,之后对 A,B ,之后对A,C ,之后对 B,C 之后对 A,之后对 B,之后对 C,最后对全表GROUP BY
看一个简单的例子:
SELECT factory,department,
SUM(quantity)
FROM production
GROUP BY CUBE(factory, department)
ORDER BY factory,department;结果:

可以看出来首先对 FACTORY,DEPARTMENT进行分组汇总,然后对FACTORY 分组汇总,之后对 DEPARTMENT 分组汇总,最后有一行全表汇总。
GROUPING
GROUPING()函数只能配合 ROLLUP 和 CUBE 使用,GROUPING()接收一列,如果此列不为空则返回0,如果为空则返回1.
我们用第一个ROLLUP例子举例
SELECT GROUPING(factory),
factory,
department,
SUM(quantity)
FROM production
GROUP BY ROLLUP(factory, department)
ORDER BY factory,
department;结果:
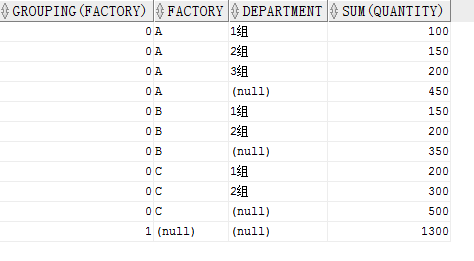
看到,最后一行的 FACTORY 为空,所以 GROUPING()返回 1.也可以与CUBE结合使用,方法是一样的。
GROUPING SETS
GROUPING SETS 与 CUBE 有点类似,CUBE是对参数进行自由组合进行分组。GROUPING SETS则对每个参数分别进行分组,GROUPING SETS(A,B)就代表先按照 A 分组,再按照 B分组。
SELECT factory,
department,
SUM(quantity)
FROM production
GROUP BY GROUPING SETS(factory, department)
ORDER BY factory,
department结果:
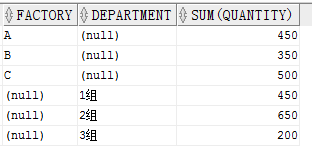
可以看出来结果是按照工厂和部门分别分组汇总的。
GROUPING_ID()
GROUPING_ID()配合GROUPING()函数使用,GROUPING_ID(A,B)的值由GROUPING(A)与GROUPING(B)的值决定,如果GROUPING(A)为1,GROUPING(B)为0,则GROUPING_ID(A,B)的值为 10,十进制的 3.
SELECT factory,
department,
GROUPING(factory),
GROUPING(department),
GROUPING_ID(factory,department),
SUM(quantity)
FROM production
GROUP BY CUBE(factory, department)
ORDER BY factory,
department;
结果:
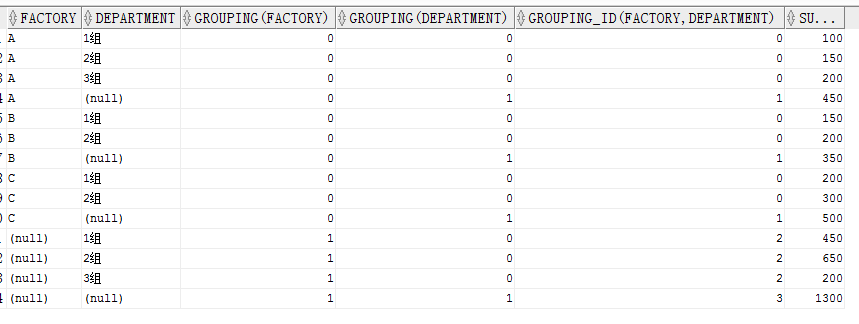
有了GROUPING_ID列,我们就可以使用 HAVING 字句来对查询结果进行过滤。选择GROUPING_ID=0的就表示 FACTORY,DEPARTMENT两列都不为空。