舆情监控系统——step1.爬取微信公众号文章
小明酱于2018年元旦更新,写的还是很糙,如果你在爬虫问题中遇到问题,欢迎交流哦,评论区随时为你开放!
实习两周过去了,目前任务量还不是很大。我的老板很nice,是个军校生,给我安排的任务也比我预想的要贴近我的研究方向,做的是微信公众号文章的舆情监控系统,以下是该系统总体设计流程图:
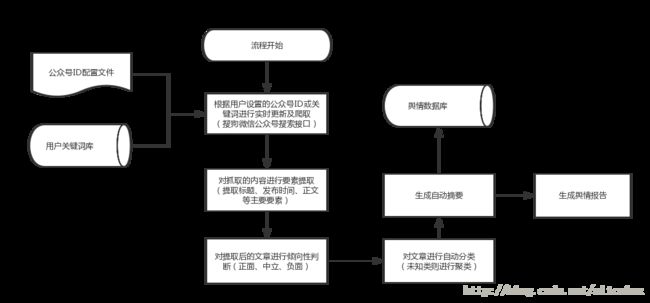
目前第一周是爬取微信公众号的文章,主要功能如下:
- 按照搜索公众号id和关键字两种方法爬取文章的标题、内容、发布时间、 公众号名称
- 以正确编码格式存储到数据库中
- 实现将新增数据添加入数据库
- 在关键字检索方式中按照时间顺序将文章排序,实现翻页爬取
以上功能均已实现,真心觉得在项目中学习才是最高效的方法,但同时也有不求甚解的毛病,希望自己能够深入把握下一周新学的知识,做一个总结,不能仅停留在插件式的编程。
下面我讲述下思路过程GitHub代码点击此处:
主体思路
- 通过微信合作方搜狗搜索引擎(http://weixin.sogou.com/),发送相应请求来间接抓取,可以实现两种检索方式,如下图:搜文章和搜公众号。
输入公众号ID,获取爬虫起始地址
http://weixin.sogou.com/weixin?type=1&s_from=input&query=+公众号ID+&ie=utf8&_sug_=n&_sug_type_=
- 所用环境:python 3.5 | scrapy爬虫框架 | Mac osX | mySQL数据库
根据网页结构设计爬取规则
在这个阶段我徘徊了很久,看到很多demo设计了花里胡哨的反扒策略,让我慌张了很久,多谢漫步大佬给我的讲解,他的嫌弃让我进步。
- 按照公众号id爬取该公众号最新的十条文章
简单的三级爬取
在搜索引擎上使用微信公众号英文名进行“搜公众号”操作(因为公众号英文名是公众号唯一的,而中文名可能会有重复,同时公众号名字一定要完全正确,不然可能搜到很多东西,这样我们可以减少数据的筛选工作,只要找到这个唯一英文名对应的那条数据即可)
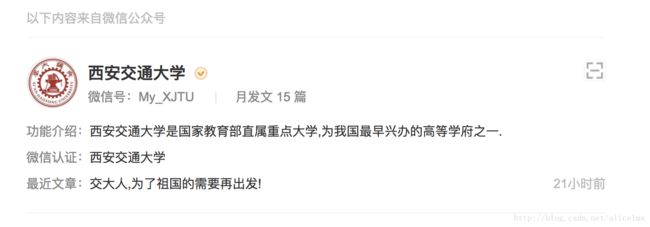
1.第一级:找到指定公众号,获取公众号主页链接
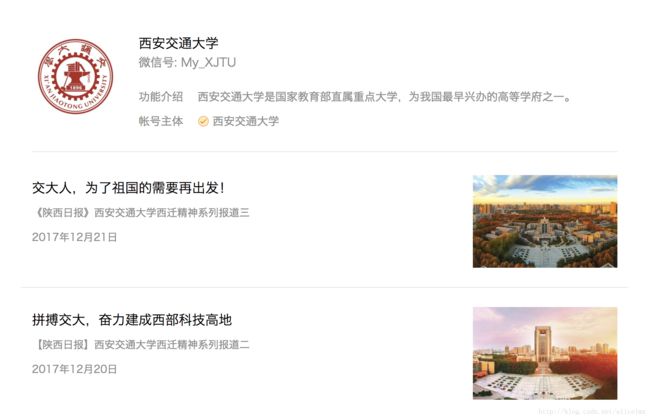
2.第二级:跳转到主页,找到每条文章的链接
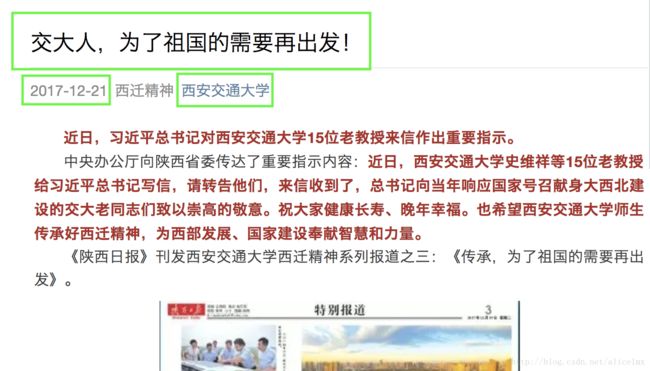
3.第三级:进入每条文章页面进行信息爬取,三条绿框中的信息,还有页面主体内容
主体思路就是这个,其中利用chrome进行检查部分就不在细说,都是常规操作
- 按照关键字爬取相关文章——二级爬取,思路同上,但是出现严重问题:
当我按照时间排序来获取具有时效性的文章时,通过筛选会得到一个URL
![]()
URL:
http://weixin.sogou.com/weixin?type=2&ie=utf8&query=%E6%98%A5%E8%8A%82&tsn=1&ft=&et=&interation=&wxid=&usip=但是我将该URL复制到浏览器中时,他会返回到微信搜索的主页,啊哦那该怎么办呢?我们先来看下开发者工具
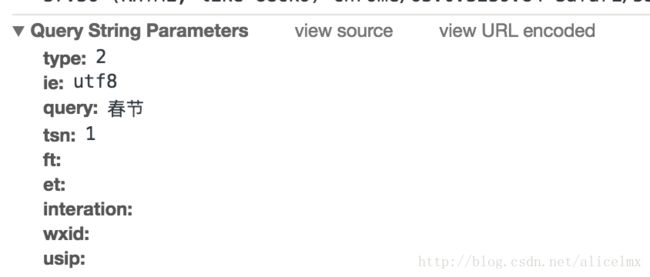
以上参数刚好和URL对应上了,重点关注tsn它代表访问的是一天内的文章,我们应该做如下请求:
return [scrapy.FormRequest(url='http://weixin.sogou.com/weixin',
formdata={'type':'2',
'ie':'utf8',
'query':key,
'tsn':'1',
'ft':'',
'et':'',
'interation':'',
'sst0': str(int(time.time()*1000)),
'page': str(self.page),
'wxid':'',
'usip':''},
method='get']以上问题就解决了~
存储细节
数据存储的量还是很大的,需要很多样本来训练模型,现在存储到数据库中,但是有一个细节值得引起我的注意就是数据的编码问题,现在公众号的文章中很多emoji字符,因此会出现以下错误:
pymysql.err.InternalError: (1366, "Incorrect string value: '\\xF0\\x9F\\x93\\xBD \\xC2...' for column 'article' at row 1")解决方法参照:
http://blog.csdn.net/alicelmx/article/details/78890311
http://blog.csdn.net/alicelmx/article/details/78890914
与反爬虫作斗争
主要是遇到了验证码的问题,但是如果爬取速度不是很快的话,是可以避免的,因此采用如下两个策略:
在下载中间件中添加随机User-Agent和随机代理IP
由于试了几个爬虫获取的代理都不能用,浪费了很长时间,代理IP添加方式如下:
http://blog.csdn.net/alicelmx/article/details/78947884在设置中delay参数设置为随机数字
import random
DOWNLOAD_DELAY = random.randint(1, 3)总结
遇到的问题
- 页面元素匹配,今后要多学习BeautifulSoup
- 翻页的逻辑问题,这个只能多自习自习,想想换页的逻辑
- 数据库存储编码问题,新换了Navicat,感觉一百分,这次配置好了以后就放心用吧
- 代理IP,通过网上的代码爬取的IP都不能用,浪费了很多时间
- 那个万恶的tsn,又学会一招
一笑了之
爬虫的基本思路是非常明确的,但是我其实还并没有完全掌握爬虫,还有很多方面需要继续学习,正如漫步所说的,我太心急了,以至于想要快速达到目的,而忽略了对原理和基础的把握,这是万万不行的,因此在寒假的时候我期待自己能把以下方面的知识学好:
- 极客学院前端第二阶段
- 爬虫第二遍学习并参与项目实战
- 吴恩达机器学习
- 韩家炜数据挖掘
尤其第二点是非常非常重要的,学习会才能证明你会爬虫,而不是你单单东拼西凑几个代码片能运行了,你就获得了很多东西,同时也希望志同道合的小伙伴加我微信,共同进步!哈哈我的微信号欢迎私聊哦~