响应式学习----从VUE1 到 VUE2
老大让搞个分享,实在想不出有啥能分享的地方,积累不够啊,之前研究过vue 0.1 的源码(对你没看错就是0.1不是1.0),所以想再看看vue2就乱说一通吧。这是原版PPT
大概讲一下以下五方面内容
1. 三大框架
2. 订阅发布模式
3. VUE1双向数据绑定
4. VUE2 virtual DOM
5.其他
1. 三大框架
最近比较喜欢一张非常喜感的图。

其实最初的前端很简单,就跟这位大爷的说法差不多,直接拿起键盘,搞个编辑器然后打开浏览器就可以了,我相信包括我在内的很多人也就是这么单纯地喜欢上前端的,记得宇豪也是说喜欢前端就是因为CSS。
起初的前端,标准混乱,浏览器性能差,随着ajax和node出现带来的两次飞跃,前端能做的事情越来越多,越来越多的需求也放到了前端,由后端主导的静态页面发展到了前后端分离的动态页面,前端逻辑变得复杂,也难以管理。
我们需要更好的管理视图层逻辑,需要更好性能、可维护性、开发效率,不需要关注视图层,只需要处理业务逻辑、管理状态即可。
与此同时,程序员的最大优点懒癌发作,所以,10年angular开源,13年react开源,14年vue发布。
现如今可能比较流行的还是这三大框架,我们简单介绍一下
angular,接触不多,数据绑定采用脏检查,简单理解,angular检测到几种类型的变化(DOM等),会对所有脏数据进行检查,其实性能也还不错,绝不像谣言中的定时检查一样那么差,包括谷歌也做了很多优化(团队实力毋庸置疑,开源贡献也很多,当然可能版本升级不兼容是最遭吐槽的地方了),也一直往更快、更小、更方便的方向优化,据说今年马上就出5了。angular也是早期web非常流行的框架,包括现在也还有不少使用它作为企业级解决方案,如网易等,不过现在的用户可能主要集中在angular1、2。
react和vue其实相似的地方很多
1. 都提供了响应式和组件化的视图组件
2. 都专注于核心库开发,其他功能作为插件
3. virtual DOM
不同之处:
1. jsx VS template
2. 数据绑定
react,按我理解的话,数据绑定是单向的
setState =》 传入新状态 =》 创建新virtual DOM =》 DOM diff =》 最小代价render
如果需要用户交互改变状态,那么需要手动绑定事件回调,再进行状态变动
vue双向数据邦迪是基于数据劫持 + 订阅发布模式,这也是本文的重点内容,后面会有比较详细的介绍。
每一个订阅发布都形成了一个链条,元编程实时追踪状态变化,并且根据依赖关系直接变更相应watcher,不用比较盲目脏检查
vue2 加入virtual DOM,同时开始支持ssr(服务端渲染)
2. 订阅发布模式
{
const interFace = function (){
const dependence = {}
return {
publish(type){ // 发布
if(event[type]){
event[type].forEach(function(element) {
element()
})
}
},
watch(type, callback){ // 订阅
if(event[type]){
event[type].push(callback)
} else {
event[type] = [callback]
}
}
}
}
const {dispatch, addEvent} = interFace()
watch("我会随时播报vue的数据变化", function(){
console.log("vue的数据变化了,我们要同步DOM更新")
}) // 订阅消息
publish("我会随时播报vue的数据变化") // 发布消息
}订阅发布模式,又称观察者模式,实质上是一种多对多关系的解耦,发布者会维护一个订阅列表(关系列表)记录订阅者的订阅行为,当有需要的时候,取出对应的订阅者并“通知”他们;订阅者会做出订阅行为,并等待发布者发布消息。
vue其实也是出于解耦“订阅者”和“发布者”两者关系考虑来使用者套模式,并且在发布者(劫持的变化)和订阅者(响应变化进行DOM变化)之间增加了dep对象来管理依赖,实现了更加明确的单一职责,使得代码组织变得更加清晰,可维护性更高,更方便进行后期优化和维护甚至重构。
下面我们结合前面的设计模式来实现一个最简单的vue
<div id="app" style="text-align:center;">
<input id="input" type="text" v-model="name"><br> 姓名:
<span id="text">{{name}}span>
div>
<script>
const Vue = function (options) {
let {node, data} = options,
name = data.name,
// 编译正则匹配取到 对象两个node节点
input = document.querySelector("#input"),
text = document.querySelector("#text")
Object.defineProperty(data, "name", {
enumerable: true,
configurable: true,
set(newVal) {
input.value = newVal
text.innerHTML = newVal
},
get(){
return name
}
})
input.addEventListener("input", function () {
data.name = this.value
})
// 编译后 利用setter初始化模板中的值 实际上是使用getter初始化
data.name = name
}
new Vue({
el: "#app",
data: {
name: "allen"
}
})
script>在这个例子中基本干掉了编译的代码,实际的生命周期中是先进行数据劫持,再进行编译和依赖收集。
首先看一下Object.defineProperty(obj, key, descriptor)这个函数,它的descriptor有几种选项,其中包括get和set,定义了当前obj键值key的取和改两种行为,简单说,如果你进行obj.key 触发get方法,其返回值就是get return的值;进行obj.key = 1 赋值会触发set方法,并且第一参数为1。
所以所谓数据劫持就是劫持数据的变化,改变原本正常的行为,在原本的数据变化中加入你的代码,如果你的数据发生变动可以第一时间“被动监听到”。
set函数中监听到了数据变化,那么我们的预期就是会进行相应的DOM变动,这里简单就直接进行了innerHTML等赋值操作改变DOM。
get函数中主要是进行初始化的逻辑,是依赖收集的重要部分,demo中使用setter进行简单替代,注意构造函数最后一行。
当然这么简单的代码确实是可以运行的,也实现了双向数据绑定,但是强耦合赋予的是效率低下和可维护性差;并且随着需要绑定的数据数量和种类增加,甚至更进一步各种复杂指令类型对应的复杂操作,我们的代码会变得越来越臃肿和不可维护。
所以我们需要一种更规范的初始化流程和数据流动管理,抽象公共行为,加入中间对象解耦逻辑,形成职责单一、低耦合、高内聚的代码块。
3. VUE1双向数据绑定
我们来看一个简单的VUE场景
<div id="main">
<h1>count: {{times}}h1>
div>
<script src="vue.js">script>
<script>
var vm = new Vue({
el: '#main',
data: function () {
return {
times: 1
};
},
created: function () {
var me = this;
setInterval(function () {
me.times++;
}, 1000);
}
});
script>主要实现了一个定时器功能,js操作状态(times)不断变化,视图层随着状态变化而变化。
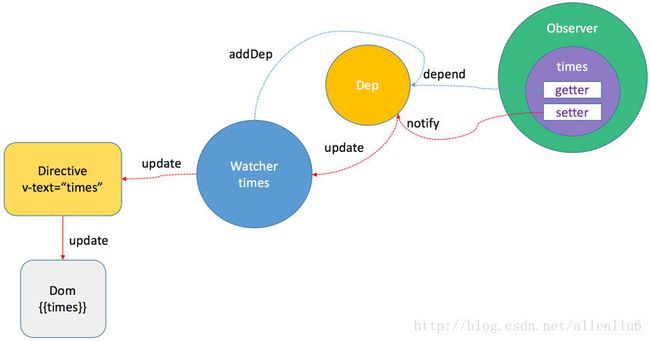
上图是简单的一个内部原理图,表示了times被赋值之后的变化,以及dep的依赖收集。
初始化,先进行数据劫持,然后模板编译,创建watcher也就是订阅者,紧接着dep进行依赖(发布订阅)关系确定,连接起observer和watcher,然后就等待数据变动。
初始化完毕后,times变化,数据劫持到变化,触发nodify(通知,即发布)行为,通知dep然后找到dep中,这个数据的相应依赖,然后updata watcher,watcher最终会进行相应DOM操作。
下面看一下我实现的简单vue的observer函数,其中有比较重要的数据劫持、初始化依赖收集、发布行为(nodify函数)
function Observer(options, keyword) {
this.data = options
Object.keys(options).forEach((key) => {
if (typeof options[key] === 'object' && options[key] instanceof Object) {
new Observer(options[key], key)
} else {
this.defineSetget(key, options[key])
}
})
}
Observer.prototype.defineReactive = function (key, val) {
const dep = new Dependence(key, val) // 闭包一个dep实例
Object.defineProperty(this.data, key, {
enumerable: true,
configurable: true,
get: function () {
if (Dependence.target) {
dep.addDep() // 添加watcher进 dep实例
}
return val // 返回闭包数据
},
set: function (newVal) {
if (val === newVal) return
val = newVal // 修改闭包数据
console.log(`你改变了${key}`)
if (typeof val === 'object' && val instanceof Object) {
new Observer(val)
}
dep.notify(newVal) // 通知,即发布数据变动
}
})
}遍历对象,对对象的每个属性数据劫持
在每个defineProperty函数外层作用域创建一个闭包dep,dep和observer是根据作用域链利用闭包进行通信,setter在数据变动时通知watcher,初始化时我们会触发一次getter使其自动收集依赖,完成订阅,进入闭包dep实例的依赖列表中。
再看一下简单的watcher函数,其中有
function Watcher(type, path, DOM, tokens, vm) {
this.type = type
this.keyPath = path
this.node = DOM
this.tokens = tokens
// Directive的功能
if (type === "model") {
DOM.addEventListener("input", e => this.set(vm, path, e.target.value))
}
Dependence.target = this
// get到值 完成依赖收集 然后进行node初始化赋值
this.tokens.forEach((elem) => {
if (!elem.html) {
this.update(this.get(vm, path))
}
})
}
// 触发相应发布者的getter
Watcher.prototype.get = function (vm, path) {}
// 触发相应发布者的getter
Watcher.prototype.set = function (vm, path, value) {}
// 通知Directive更新DOM
Watcher.prototype.update = function (value) {}其中事件监听是简单概括了diective实例的功能,之后根据传入参数进行依赖收集,先确定当前计算的target也就是当前的watcher实例,触发相应observer的getter函数,获得当前初始化值并直接进行updata,进而更新视图。
4. VUE2 virtual DOM
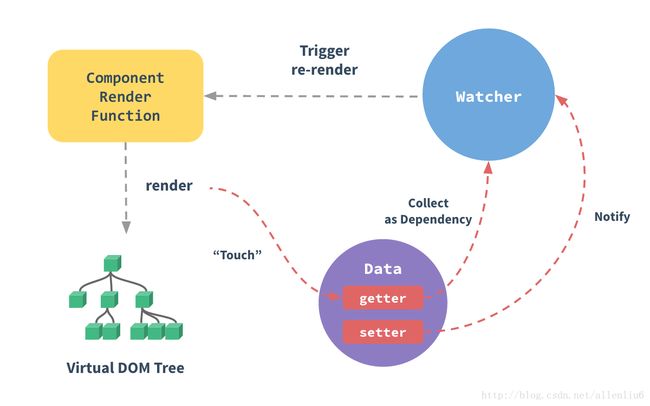
vue2一个很大的改动就是加了virtual DOM,对数据绑定影响不太大,主要接管了DOM更新这边的事情。
当watcher被通知发生变动时,watcher会通知组件的render函数进行re-render操作,创建一个新的virtual DOM,再跟旧virtual DOM进行diff,得到一个最优的DOM更新路径(操作次数少,动作小)
实质上可以看做加了一个中间层对DOM渲染进行优化,只需要当做黑盒把状态注入,virtual DOM自动计算最小代价渲染。
看一段snabbdom的代码,snabbdom是一个非常轻量的virtual DOM库
var snabbdom = require("snabbdom");
var patch = snabbdom.init([ // 初始化补丁功能与选定的模块
require("snabbdom/modules/class").default, // 使切换class变得容易
require("snabbdom/modules/props").default, // 用于设置DOM元素的属性(注意区分props,attrs具体看snabbdom文档)
require("snabbdom/modules/style").default, // 处理元素的style,支持动画
require("snabbdom/modules/eventlisteners").default, // 事件监听器
]);
var h = require("snabbdom/h").default; // 用于创建vnode,VUE中render(createElement)的原形
var container = document.getElementById("container");
var vnode = h("div#container.two.classes", {on: {click: someFn}}, [
h("span", {style: {fontWeight: "bold"}}, "This is bold"),
" and this is just normal text",
h("a", {props: {href: "/foo"}}, "I\"ll take you places!")
]);
// 第一次打补丁,用于渲染到页面,内部会建立关联关系,减少了创建oldvnode过程
patch(container, vnode);
//创建新节点
var newVnode = h("div#container.two.classes", {on: {click: anotherEventHandler}}, [
h("span", {style: {fontWeight: "normal", fontStyle: "italic"}}, "This is now italic type"),
" and this is still just normal text",
h("a", {props: {href: "/bar"}}, "I\"ll take you places!")
]);
//第二次比较,上一次vnode比较,打补丁到页面
//VUE的patch在nextTick中,开启异步队列,删除了不必要的patch
patch(vnode, newVnode);
// Snabbdom efficiently updates the old view to the new state注释已经比较详细了,就不详细讲了,再放一个virtual DOM的构造函数
export default class VNode {
tag: string | void;
data: VNodeData | void;
children: ?Array;
text: string | void;
elm: Node | void;
ns: string | void;
context: Component | void; // rendered in this component's scope
functionalContext: Component | void; // only for functional component root nodes
key: string | number | void;
componentOptions: VNodeComponentOptions | void;
componentInstance: Component | void; // component instance
parent: VNode | void; // component placeholder node
raw: boolean; // contains raw HTML? (server only)
isStatic: boolean; // hoisted static node
isRootInsert: boolean; // necessary for enter transition check
isComment: boolean; // empty comment placeholder?
isCloned: boolean; // is a cloned node?
isOnce: boolean; // is a v-once node?
constructor (
tag?: string,
data?: VNodeData,
children?: ?Array,
text?: string,
elm?: Node,
context?: Component,
componentOptions?: VNodeComponentOptions
) {
/*当前节点的标签名*/
this.tag = tag
/*当前节点对应的对象,包含了具体的一些数据信息,是一个VNodeData类型,可以参考VNodeData类型中的数据信息*/
this.data = data
/*当前节点的子节点,是一个数组*/
this.children = children
/*当前节点的文本*/
this.text = text
/*当前虚拟节点对应的真实dom节点*/
this.elm = elm
/*当前节点的名字空间*/
this.ns = undefined
/*编译作用域*/
this.context = context
/*函数化组件作用域*/
this.functionalContext = undefined
/*节点的key属性,被当作节点的标志,用以优化*/
this.key = data && data.key
/*组件的option选项*/
this.componentOptions = componentOptions
/*当前节点对应的组件的实例*/
this.componentInstance = undefined
/*当前节点的父节点*/
this.parent = undefined
/*简而言之就是是否为原生HTML或只是普通文本,innerHTML的时候为true,textContent的时候为false*/
this.raw = false
/*静态节点标志*/
this.isStatic = false
/*是否作为跟节点插入*/
this.isRootInsert = true
/*是否为注释节点*/
this.isComment = false
/*是否为克隆节点*/
this.isCloned = false
/*是否有v-once指令*/
this.isOnce = false
}
// DEPRECATED: alias for componentInstance for backwards compat.
/* istanbul ignore next */
get child (): Component | void {
return this.componentInstance
}
} 再放一个简单的解析virtual DOM的函数
HTMLParser(html, {
start: function( tag, attrs, unary ) { //标签开始
results += "<" + tag;
for ( var i = 0; i < attrs.length; i++ )
results += " " + attrs[i].name + "="" + attrs[i].escaped + """;
results += (unary ? "/" : "") + ">";
},
end: function( tag ) { //标签结束
results += " + tag + ">";
},
chars: function( text ) { //文本
results += text;
},
comment: function( text ) { //注释
results += "";
}
});
return results;5. 其他
劫持
一个vue的视图系统主体是一个个的vm实例,组件vm层层嵌套,最终组成整个视图,而在vm上vue将vm中的数据proxy控制到vm上,可能说的有点抽象,实际效果就是
const vm = new Vue({
data: {
name: allen
}
})按照逻辑来看访问name属性应该是这样的
vm.data.name但实际上你只需要这样
vm.name这是因为构造函数内部有一段这样的逻辑
_proxy(options.data);/*构造函数中*/
/*代理*/
function _proxy (data) {
const that = this; // 指向vue实例
Object.keys(data).forEach(key => {
Object.defineProperty(that, key, {
configurable: true,
enumerable: true,
get: function proxyGetter () {
return that._data[key];
},
set: function proxySetter (val) {
that._data[key] = val;
}
})
});
}其实就是做了一个劫持,当访问vm.name属性时,返回vm.data.name
数组的特殊处理
JavaScript似乎从很多角度都能被看做一门奇怪的语言,从设计上说,“+”既可以为相加有可以为连接(包括动态类型,这类问题其实导致了一些JavaScript引擎解析上的性能问题)、易错的with语句,从实现来看,早期一直有很多bug……
而数组呢,其实也比较奇怪,在es6之前没有标准明确定义数组空位的问题,而length又是可读写的同时创建数组限制十分宽松,所以各大浏览器也是有很多不同的实现,es6之后对数组空位有了明确的规定。
在vue中,因为数组的宽松规定,在给我们带来一定便利的同时也带来很多问题:

vue不仅定义了新方法,也重写了vue的一些变异方法(会改变被这些方法调用的原始数组的方法)
// vue version-0.1
['push',
'pop',
'shift',
'splice',
'unshift',
'sort',
'reverse']
.forEach(function(method){
// cache original method
var original = Array.prototype[method]
// define wrapped method
_.define(arrayAugmentations, method,
function(){
var args = slice.call(arguments)
var result = original.apply(this, args)
var ob = this.$observer
var inserted, removed, index
switch(method){
case 'push':
inserted = args
index = this.length - args.length
break
case 'unshift':
inserted = args
index = 0
break
case 'pop':
removed = [result]
index = this.length
break
case 'shift':
removed = [result]
index = 0
break
case 'splice':
inserted = args.slice(2)
removed = result
index = args[0]
break
}
// link/unlink added/removed elements
if (inserted) {
ob.link(inserted, index)
}
if (removed) {
ob.unlink(removed)
}
//updata indices
if (method !== 'push' && method !== 'pop') {
ob.updataIndecies()
}
// emit length change
if (inserted || removed) {
ob.notify('set', 'length', this.length)
}
// empty path, value is the Array itself
ob.notify('mutate', '', this, {
method: method,
args: args,
result: result,
index: index,
inserted: inserted || [],
removed: removed || []
})
return result
})
})上面是vue 0.1的部分源码,主要是对数组的增、删、改、排序等方法进行重写,将其变为适应vue响应式变化的方法,如删除则通知相应watcher变动,增加则要重新关联依赖等。
运行时编译 or 模板编译
如果用过比较新版的vue-cli的读者可能遇到过如下场景
Runtime + Compiler: recommended for most users
Runtime-only: about 6KB lighter min+gzip, but templates (or any Vue-specificHTML) are ONLY allowed in .vue files - render functions are required elsewhere 这两者的区别还得从vue内部的编译过程说起,大概分为以下两步:
1. 将template编译为render函数(可选)
2. 创建vue实例,调用render函数
在vue-loader解析过程中,template会被解析成一个对象,也就是说你打包好的代码已经完成了这一步,template在你的代码中是以对象形式呈现的,这跟react有异曲同工之妙(猜测是因为他们都使用virtual DOM,都需要render函数),这个过程称为模板编译,所以如果你不用template,那么模板编译其实就基本没有用武之地了。
而运行时编译则是用来创建 Vue 实例,渲染并处理 virtual DOM 等行为的代码。基本上就是除去编译器的其他一切。同时也是比较建议使用运行时,因为运行时构建相比完整版缩减了 30% 的体积。
其实在vue1中整个编译过程是不作区分的,而在vue2中因为有了两个编译环境—客户端和服务端,而在进行ssr(server side render)时,因为是node环境,所以需要document.dagment等DOM接口支持的编译就不在适用了,所以做出了以上区分。
6. 总结
源码看得比较少,理解的也比较浅显,下一步还是要多多深入,尽可能从整体架构以及设计模式设计思想上来看vue,当然也要学习尤大的编码习惯、风格以及代码组织等。
另外再讲点其他的吧,随着敲代码越多,理解以及感想也就越来越多:
其实很多比较吊的东西都是程序员懒癌发作的结果,可能每天写着重复的代码,做着重复的工作很崩溃,每次构建这么复杂,然后有了增量构建,每次打开网页这么慢,然后有了各种ssr优化手段。然后这些的方案啊,框架啊就诞生了。每六周换一个框架不是梦,真的是现实。
底层实现也越来越吊,就像我们维护优化自己的网站等产品一样,Chrome等浏览器厂商也在维护优化自己的产品,其成果比较喜人包括js速度越来越快, 各种跨平台跨端,同时前端的权限也越来越大,比如现在的chorme 61 beta,支持 javascript模块(script标签 type=”module”),桌面支付请求API ,web share API (与app共享内容),webUSB(外设通信)等,另外除了浏览器还有各种工具、编译器(编译为js),总之前端应用场景越来越多,能做的事情越来越多。
后端的逻辑越来越多的放到前端处理,甚至包括机器学习算法部分,可能主要还是考虑到分担服务端计算压力,提高即时用户体验,比如美登科技,他们也是试验了一套前后端机器学习的整体架构,前端会包括打点、个性化推荐、个性化配置学习等。
未来展望。这么发展下去还真的很难说未来如何,不过我个人还是很相信前端的前途的,有一种比较著名的说法(记得是阮一峰老师说的)是,未来只有两种工程师,端工程师和云工程师
就我理解而言,还是两大方向,数据化可视化(平台建设),数据挖掘(这里是自己理解比较广义的)
好了说一千道一万也没用,我们还是努力coding,多总结,多交流,也可以多参与开源。
番外:
上面提到了重写js原有方法,其实一般来说建议尽量避免这么做的~
当然我个人认为坑爹就要坑到底,所以如果真重置了标准方法,那么就多补一刀吧
重写方法后有一个不大不小的漏洞,比如Chrome的控制台再打印这个方法后就不会打印出[native code]字样了(以下注释为当前Chrome console实测结果)
Array.prototype.push = Array.prototype.pop
//ƒ pop() { [native code] }
const a = [1,2,3]
a.push(4)
a //(2) [1, 2]Array.prototype.pop.toString = () => 'function push() { [native code] }'
Array.prototype.push // ƒ push() { [native code] }