让CarbonData使用更简单
CarbonData 是什么
引用官方的说法:
Apache CarbonData是一种新的高性能数据存储格式,针对当前大数据领域分析场景需求各异而导致的存储冗余问题,CarbonData提供了一种新的融合数据存储方案,以一份数据同时支持“任意维度组合的过滤查询、快速扫描、详单查询等”多种应用场景,并通过多级索引、字典编码、列存等特性提升了IO扫描和计算性能,实现百亿数据级秒级响应。
CarbonData的使用
我之前写过一篇使用的文章。CarbonData集群模式体验。到0.3.0版本,已经把kettle去掉了,并且我提交的PR已经能够让其在Spark Streaming中运行。之后将其集成到StreamingPro中,可以简单通过配置即可完成数据的流式写入和作为SQL服务被读取。
准备工作
CarbonData 使用了Hive的MetaStore。
- MySQL数据库
- hive-site.xml 文件
- 下载StreamingPro with CarbonData
MySQL
创建一个库:
create database hive CHARACTER SET latin1;
hdfs-site.xml
新建文件 /tmp/hdfs-site.xml,然后写入如下内容:
javax.jdo.option.ConnectionURL
jdbc:mysql://127.0.0.1:3306/hive?createDatabaseIfNoExist=true
javax.jdo.option.ConnectionDriverName
com.mysql.jdbc.Driver
javax.jdo.option.ConnectionUserName
你的账号
javax.jdo.option.ConnectionPassword
你的密码
hive.metastore.warehouse.dir
file:///tmp/user/hive/warehouse
hive.exec.scratchdir
file:///tmp/hive/scratchdir
hive.metastore.uris
datanucleus.autoCreateSchema
true
启动Spark Streaming写入数据
新建一个文件,/tmp/streaming-test-carbondata.json,内容如下:
{
"test": {
"desc": "测试",
"strategy": "spark",
"algorithm": [],
"ref": [
"testJoinTable"
],
"compositor": [
{
"name": "streaming.core.compositor.spark.streaming.source.MockInputStreamCompositor",
"params": [
{
"data1": [
"1",
"2",
"3"
],
"data2": [
"1",
"2",
"3"
],
"data3": [
"1",
"2",
"3"
],
"data4": [
"1",
"2",
"3"
]
}
]
},
{
"name": "streaming.core.compositor.spark.streaming.transformation.SingleColumnJSONCompositor",
"params": [
{
"name": "a"
}
]
},
{
"name": "stream.table",
"params": [
{
"tableName": "test"
}
]
},
{
"name": "stream.sql",
"params": [
{
"sql": "select a, \"5\" as b from test",
"outputTableName": "test2"
}
]
},
{
"name": "stream.sql",
"params": [
{
"sql": "select t2.a,t2.b from test2 t2, testJoinTable t3 where t2.a = t3.a"
}
]
},
{
"name": "stream.output.carbondata",
"params": [
{
"format": "carbondata",
"mode": "Append",
"tableName": "carbon4",
"compress": "true",
"useKettle": "false",
"tempCSV":"false"
}
]
}
],
"configParams": {
}
},
"testJoinTable": {
"desc": "测试",
"strategy": "refTable",
"algorithm": [],
"ref": [],
"compositor": [
{
"name": "streaming.core.compositor.spark.source.MockJsonCompositor",
"params": [
{
"a": "3"
},
{
"a": "4"
},
{
"a": "5"
}
]
},
{
"name": "batch.refTable",
"params": [
{
"tableName": "testJoinTable"
}
]
}
],
"configParams": {
}
}
}
运行即可(spark 1.6 都可以)
./bin/spark-submit --class streaming.core.StreamingApp \
--master local[2] \
--name test \
--files /tmp/hdfs-site.xml \
/Users/allwefantasy/CSDNWorkSpace/streamingpro/target/streamingpro-0.4.7-SNAPSHOT-online-1.6.1-carbondata-0.3.0.jar \
-streaming.name test \
-streaming.platform spark_streaming \
-streaming.job.file.path file:///tmp/streaming-test-carbondata.json \
-streaming.enableCarbonDataSupport true \
-streaming.carbondata.store /tmp/carbondata/store \
-streaming.carbondata.meta /tmp/carbondata/meta
如果/tmp/carbondata/store/default/ 目录生成了文件就代表数据已经写入。
启动SQL查询服务
新建一个/tmp/empty.json文件,内容为:
{}
启动命令:
./bin/spark-submit --class streaming.core.StreamingApp \
--master local[2] \
--name test \
--files /tmp/hdfs-site.xml \
/Users/allwefantasy/CSDNWorkSpace/streamingpro/target/streamingpro-0.4.7-SNAPSHOT-online-1.6.1-carbondata-0.3.0.jar \
-streaming.name test \
-streaming.rest true \
-streaming.spark.service true \
-streaming.platform spark \
-streaming.job.file.path file:///tmp/empty.json \
-streaming.enableCarbonDataSupport true \
-streaming.carbondata.store /tmp/carbondata/store \
-streaming.carbondata.meta /tmp/carbondata/meta
查询方式:
curl --request POST \
--url http://127.0.0.1:9003/sql \
--header 'cache-control: no-cache' \
--header 'content-type: application/x-www-form-urlencoded' \
--data 'sql=select%20*%20from%20carbon4%20where%20a%3D%223%22&resultType=json'
如果放在PostMan之类的东西里,是这样子的:
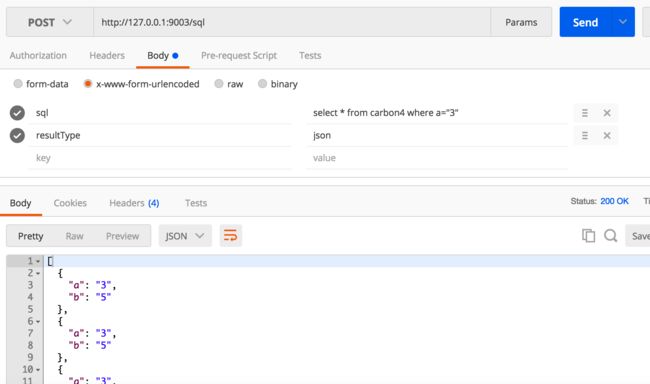
Snip20161130_4.png
常见问题
如果出现类似
File does not exist: /tmp/carbondata/store/default/carbon3/Fact/Part0/Segment_0
则是因为在你的环境里找到了hadoop相关的配置文件,比如hdfs-site.xml之类的。去掉或者自己写一个,比如新建一个 hdfs-site.xml,然后写入如下内容:
fs.default.name
file:///
这样就会读本地文件了。