『MACHINE LEARNING』读书笔记|周志华《机器学习》|5.2神经网络感知机
写在前面
最近在看周志华的《机器学习》,看了书才知道水很深啊,算法,统计样样都有。小白看得很累,决定记点笔记,以防这之后忘了。
感知机(perceptron )
感知机是神经网络最开始雏形,是一个二类分类的线性分类模型,只有两层的神经元。周志华《机器学习》用的 sign 函数稍与李航的《统计学习方法》有不同,接下来利用的是周志华《机器学习》的版本。感知机形如下图。
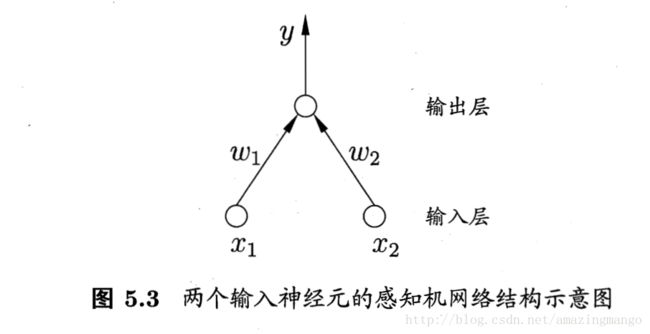
说好的二类分类的线性分类模型,体现在哪?
线性分类:
输出值 y 是一个有输入值 xi 线性决定的函数, y=f(∑iωixi−θ) ,
但是由于上式中的 −θ=ωi+1xi+1 ,其中 xi+1=−1 ,
其实就是给多一个输入节点(dummy node)固定输入x=-1.
so, y可以表示为 f(∑iωixi) 变得更简单了。
二类分类:
二类分类的原因来源于 f , f 使得 y 在 x∈R 可以只取两个值。所以, f 是个阶跃函数,但为了 f 可微,实际上,会近似的利用sigmoid函数去代替阶跃函数。但一下请假装 f 是个阶跃函数,方便理解。
机器学习的书中,公式(5.1)和(5.2)我觉得不能理解。下面做做解释:
上面我们讲到
不失一般性,我们考虑两个输入 x1 和 x2 , 那么 ∑iωixi=0 就会是分类的边界,被叫做超平面 S (seperating hyperplane), 如下图,图中取 ω1=3;ω2=−2 ,正例是么 ∑iωixi>0 的部分。
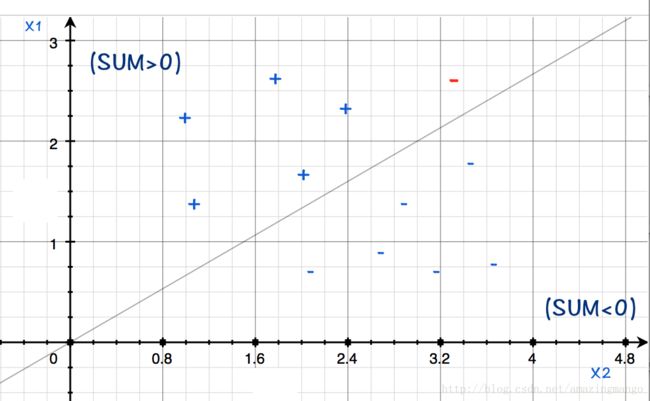
我们取两个输入的意图就是为了能在平面上表示出来。 x1 和 x2 , 其实就是图中的x和y。其中也会有被错误分类的例子,譬如图中红色标注的‘ − ’。
机器学习各式各样方法最终为了达到的目的就是预测的代价函数(cost function)要最小的。这里定义感知机的cost function为感知机分类错误的点到超平面的距离。why?其实我们也可以定义为被分类错误的点的数目,但是这个值不连续。
理解不能,是吗?
想想高中时,点到线的距离
这里的
现在该解决的就是绝对值的问题了,我们令真实值为 y ,预测值为 ŷ ,这样下来
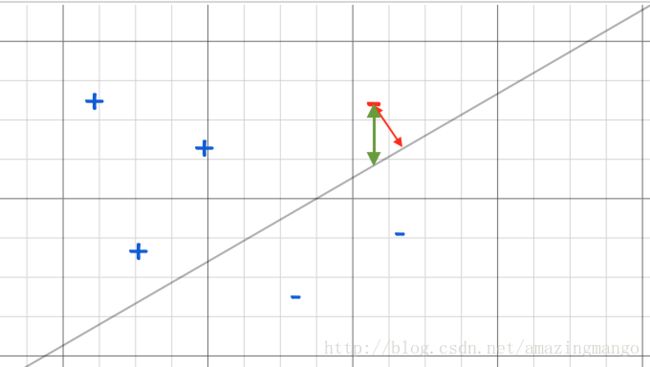
李航的《统计学习方法》中,将distance的 1||ω|| 给忽略掉了,为了后面方便对 ω 求导。这里的忽略可以理解为从距离计算从下图的红线变成了绿线。
最后 我们终于可以求和所有分类错误的点到超平面的距离作为代价函数:
怎么最优化代价函数达到最小值,这里利用的是随机梯度下降法(stochastic gradient descent),任意选取一个超平面 ω⃗ ,梯度下降不断极小化目标函数 L(ω)
通过迭代不断减小代价函数直至为0(能够被线性分类的例子)。
η 的作用是慢慢地修正超平面使其轻微地绕着原点转动,直至没有误分类点为止。
说在最后
其实本文就是充其量解释了《机器学习》-周志华的公式(5.1) 和(5.2),没多大意义,记个笔记,共同学习。
还有就是欢迎各位来看看我的blog,THX.
因为CSDN是程序员的天地了,我最多在这边会上传一些统计和机器学习的学习内容,我的blog里还会有一些有关投资的学习内容。
Anyway,我在每个领域都是小白,希望共同学习。
Refrence
[1]《统计学习方法》 李航
[2]《机器学习》周志华