PyTorch1.0安装教程(附三个测试示例)
Summary:Python1.0安装教程
Author:Amusi
Date:2018-12-20
github:https://github.com/amusi/PyTorch-From-Zero-To-One
知乎:https://www.zhihu.com/people/amusi1994
微信公众号:CVer
本文是在Ubuntu下进行PyTorch1.0正式版的安装,Windows安装教程与之类似,也可以参考该教程进行安装:https://blog.csdn.net/amusi1994/article/details/80077667
环境说明
- OS:Ubuntu16.04
- CUDA:8.0
- cudnn:6.0
- Python(conda):3.6.4
安装教程
官网:https://pytorch.org/
检查Python环境

根据当前系统环境点击选项
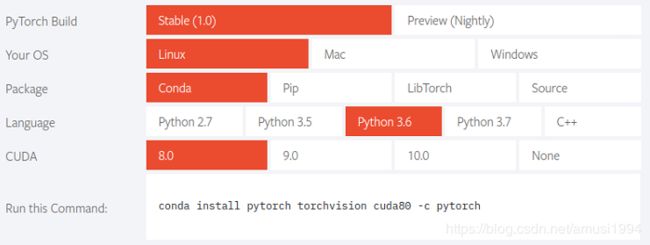
在终端输入匹配的安装PyTorch1.0的命令
conda install pytorch torchvision cuda80 -c pytorch
回车进行安装,此时会有如下提示,当搜索到PyTorch1.0的相关packages时,输入 y,确定继续安装。
注:此时可能会找不到相应的packages,比如Windows环境下。所以你可以添加相关的搜索源,如清华的源。此处可以自行百度解决。
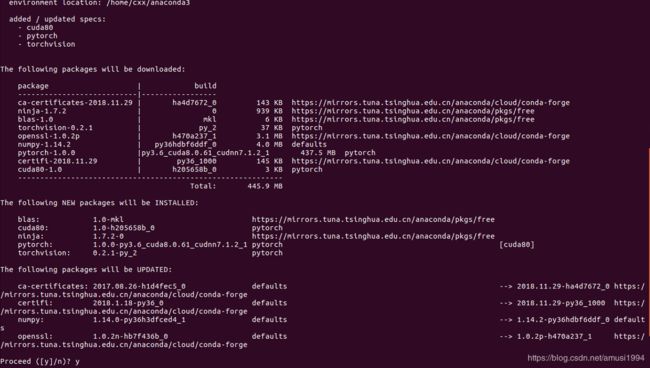
此时需要等待一会儿(具体看网速),因为PyTorch 1.0.0这个packages有437.5 MB大小。

安装成功后,会提示done。
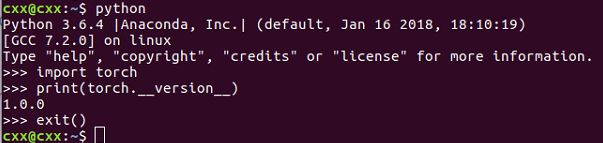
加载PyTorch并输出版本号,验证是否安装成功。
python
import torch
print(torch.__version__)
测试示例
测试1:检查CUDA和CUDNN
创建并打开新的脚本文件pytorch_cudn_cudnn_test.py
touch pytorch_cudn_cudnn_test.py
gedit pytorch_cudn_cudnn_test.py
写入测试代码
# Summary: 检测当前Pytorch和设备是否支持CUDA和cudnn
# Author: Amusi
# Date: 2018-12-20
# github: https://github.com/amusi/PyTorch-From-Zero-To-One
import torch
if __name__ == '__main__':
print("Support CUDA ?: ", torch.cuda.is_available())
x = torch.Tensor([1.0])
xx = x.cuda()
print(xx)
y = torch.randn(2, 3)
yy = y.cuda()
print(yy)
zz = xx + yy
print(zz)
# CUDNN TEST
from torch.backends import cudnn
print("Support cudnn ?: ",cudnn.is_acceptable(xx))
运行该测试代码
python pytorch_cudn_cudnn_test.py
输入结果如下:
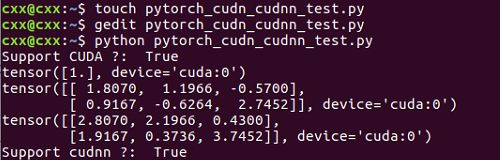
测试2:Tensors
创建并打开新的脚本文件pytorch_tensors.py
touch pytorch_tensors.py
gedit pytorch_tensors.py
写入测试代码:
# Summary:PyTorch的Tensor基础知识
# Author: Amusi
# Date: 2018-12-20
# github: https://github.com/amusi/PyTorch-From-Zero-To-One
# Reference: http://pytorch.org/tutorials/beginner/pytorch_with_examples.html#pytorch-tensors
import torch
dtype = torch.FloatTensor
# dtype = torch.cuda.FloatTensor # Uncomment this to run on GPU
# N is batch size; D_in is input dimension;
# H is hidden dimension; D_out is output dimension.
N, D_in, H, D_out = 64, 1000, 100, 10
# Create random input and output data
x = torch.randn(N, D_in).type(dtype)
y = torch.randn(N, D_out).type(dtype)
# Randomly initialize weights
w1 = torch.randn(D_in, H).type(dtype)
w2 = torch.randn(H, D_out).type(dtype)
learning_rate = 1e-6
for t in range(500):
# Forward pass: compute predicted y
h = x.mm(w1)
h_relu = h.clamp(min=0)
y_pred = h_relu.mm(w2)
# Compute and print loss
loss = (y_pred - y).pow(2).sum()
print(t, loss)
# Backprop to compute gradients of w1 and w2 with respect to loss
grad_y_pred = 2.0 * (y_pred - y)
grad_w2 = h_relu.t().mm(grad_y_pred)
grad_h_relu = grad_y_pred.mm(w2.t())
grad_h = grad_h_relu.clone()
grad_h[h < 0] = 0
grad_w1 = x.t().mm(grad_h)
# Update weights using gradient descent
w1 -= learning_rate * grad_w1
w2 -= learning_rate * grad_w2
运行该测试代码
python pytorch_tensors.py
输入结果如下:
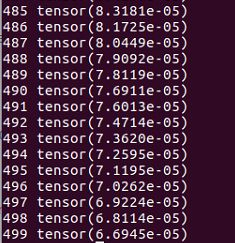
测试3:MNIST
创建并打开新的脚本文件pytorch_mnist.py
touch pytorch_mnist.py
gedit pytorch_mnist.py
写入测试代码:
# Summary: 使用PyTorch玩转MNIST
# Author: Amusi
# Date: 2018-12-20
# github: https://github.com/amusi/PyTorch-From-Zero-To-One
# Reference: https://blog.csdn.net/victoriaw/article/details/72354307
from __future__ import print_function
import argparse
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torch.autograd import Variable
# Training settings
parser = argparse.ArgumentParser(description='PyTorch MNIST Example')
parser.add_argument('--batch-size', type=int, default=64, metavar='N',
help='input batch size for training (default: 64)')
parser.add_argument('--test-batch-size', type=int, default=1000, metavar='N',
help='input batch size for testing (default: 1000)')
parser.add_argument('--epochs', type=int, default=10, metavar='N',
help='number of epochs to train (default: 10)')
parser.add_argument('--lr', type=float, default=0.01, metavar='LR',
help='learning rate (default: 0.01)')
parser.add_argument('--momentum', type=float, default=0.5, metavar='M',
help='SGD momentum (default: 0.5)')
parser.add_argument('--no-cuda', action='store_true', default=False,
help='disables CUDA training')
parser.add_argument('--seed', type=int, default=1, metavar='S',
help='random seed (default: 1)')
parser.add_argument('--log-interval', type=int, default=10, metavar='N',
help='how many batches to wait before logging training status')
args = parser.parse_args()
args.cuda = not args.no_cuda and torch.cuda.is_available()
torch.manual_seed(args.seed) #为CPU设置种子用于生成随机数,以使得结果是确定的
if args.cuda:
torch.cuda.manual_seed(args.seed)#为当前GPU设置随机种子;如果使用多个GPU,应该使用torch.cuda.manual_seed_all()为所有的GPU设置种子。
kwargs = {'num_workers': 1, 'pin_memory': True} if args.cuda else {}
"""加载数据。组合数据集和采样器,提供数据上的单或多进程迭代器
参数:
dataset:Dataset类型,从其中加载数据
batch_size:int,可选。每个batch加载多少样本
shuffle:bool,可选。为True时表示每个epoch都对数据进行洗牌
sampler:Sampler,可选。从数据集中采样样本的方法。
num_workers:int,可选。加载数据时使用多少子进程。默认值为0,表示在主进程中加载数据。
collate_fn:callable,可选。
pin_memory:bool,可选
drop_last:bool,可选。True表示如果最后剩下不完全的batch,丢弃。False表示不丢弃。
"""
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=args.batch_size, shuffle=True, **kwargs)
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=args.batch_size, shuffle=True, **kwargs)
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)#输入和输出通道数分别为1和10
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)#输入和输出通道数分别为10和20
self.conv2_drop = nn.Dropout2d()#随机选择输入的信道,将其设为0
self.fc1 = nn.Linear(320, 50)#输入的向量大小和输出的大小分别为320和50
self.fc2 = nn.Linear(50, 10)
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 2))#conv->max_pool->relu
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))#conv->dropout->max_pool->relu
x = x.view(-1, 320)
x = F.relu(self.fc1(x))#fc->relu
x = F.dropout(x, training=self.training)#dropout
x = self.fc2(x)
return F.log_softmax(x)
model = Net()
if args.cuda:
model.cuda()#将所有的模型参数移动到GPU上
optimizer = optim.SGD(model.parameters(), lr=args.lr, momentum=args.momentum)
def train(epoch):
model.train()#把module设成training模式,对Dropout和BatchNorm有影响
for batch_idx, (data, target) in enumerate(train_loader):
if args.cuda:
data, target = data.cuda(), target.cuda()
data, target = Variable(data), Variable(target)#Variable类对Tensor对象进行封装,会保存该张量对应的梯度,以及对生成该张量的函数grad_fn的一个引用。如果该张量是用户创建的,grad_fn是None,称这样的Variable为叶子Variable。
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)#负log似然损失
loss.backward()
optimizer.step()
if batch_idx % args.log_interval == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
def test(epoch):
model.eval()#把module设置为评估模式,只对Dropout和BatchNorm模块有影响
test_loss = 0
correct = 0
for data, target in test_loader:
if args.cuda:
data, target = data.cuda(), target.cuda()
data, target = Variable(data, volatile=True), Variable(target)
output = model(data)
test_loss += F.nll_loss(output, target).item()#Variable.data
pred = output.data.max(1)[1] # get the index of the max log-probability
correct += pred.eq(target.data).cpu().sum()
test_loss = test_loss
test_loss /= len(test_loader) # loss function already averages over batch size
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
if __name__ == '__main__':
for epoch in range(1, args.epochs + 1):
train(epoch)
test(epoch)
运行该测试代码
python pytorch_mnist.py
输入结果如下:

参考
-
https://pytorch.org/
-
https://github.com/amusi/PyTorch-From-Zero-To-One
-
https://blog.csdn.net/amusi1994/article/details/80077667