知名数据集
知名数据集
MNIST
MNIST是一个手写字符集,也是学习深度学习和SVM的入门必备数据集。目前由Yann LeCun维护。网址:
http://yann.lecun.com/exdb/mnist/
MNIST是NIST的一个子集,包含了6万个训练样本和1万个测试样本。为了避免碎小文件的问题,所有的手写字符图片都被放到一个文件中。整个数据集包含4个这样的文件。它们的格式说明,实际上在官网就有,只是比较靠后面,容易被忽视。
Iris flower Data Set
Iris是一种叫做鸢尾的植物。Iris flower Data Set是Ronald Fisher在1936年的论文中给出的数据集。该数据集包含了三种鸢尾花的4个特征的样本集。Fisher基于该数据集,提出了linear discriminant analysis算法。
下图是该数据集的LDA图示。
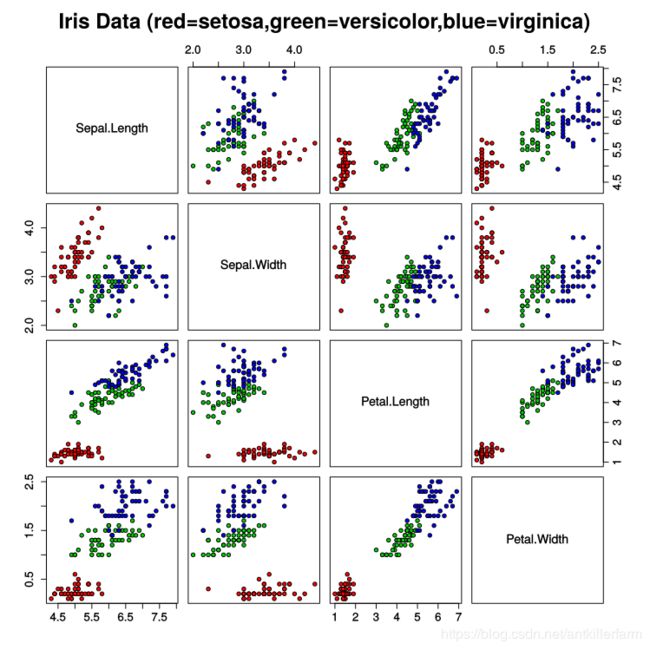
这个数据集并没有专门的网站,但实际上大多数ML软件都自带该数据集,比如R、sklearn等。
参考:
https://en.wikipedia.org/wiki/Iris_flower_data_set
http://scikit-learn.org/stable/auto_examples/datasets/plot_iris_dataset.html
CIFAR-10
CIFAR-10是由Hinton的两个大弟子Alex Krizhevsky、Ilya Sutskever收集的一个用于普适物体识别的数据集。Cifar是加拿大政府牵头投资的一个先进科学项目研究所。
说白了,就是看你穷的没钱搞研究,就施舍给你。Hinton、Bengio和他的学生在2004年拿到了Cifar投资的少量资金,建立了神经计算和自适应感知项目。
这个项目结集了不少计算机科学家、生物学家、电气工程师、神经科学家、物理学家、心理学家,加速推动了DL的进程。从这个阵容来看,DL已经和ML系的数据挖掘分的很远了。
DL强调的是自适应感知和人工智能,是计算机与神经科学交叉。DM强调的是高速、大数据、统计数学分析,是计算机和数学的交叉。
CIFAR-10由60000张32*32的RGB彩色图片构成,共10个分类。50000张训练,10000张测试(交叉验证)。这个数据集最大的特点在于将识别迁移到了普适物体,而且应用于多分类(姊妹数据集CIFAR-10达到100类,ILSVRC比赛则是1000类)。
官网:
https://www.cs.toronto.edu/~kriz/cifar.html
参考:
http://www.cnblogs.com/neopenx/p/4480701.html
CNN训练Cifar-10技巧
ImageNet
ImageNet是由李飞飞等创建的一个计算机视觉系统识别项目,是目前世界上图像识别最大的数据库。
官网:
http://www.image-net.org/
需要注意的是,由于ImageNet的数据过于庞大,因此主页下载的数据文件,仅仅只是图片的URL而已。
PASCAL VOC
PASCAL VOC是一个标有物体类别和位置的图片库。
官网:
http://host.robots.ox.ac.uk/pascal/VOC/
2005~2012年期间,围绕着该数据集展开了Pascal VOC挑战赛。
MSCOCO
COCO数据集是微软团队获取的一个可以用来图像recognition+segmentation+captioning的数据集。
官网:
http://cocodataset.org/
UCI数据集
UCI大学有个专门提供数据集的网站:
http://archive.ics.uci.edu/ml/datasets
其中包含360+的数据集,实在是个宝库啊。
猫狗数据集
最早的宠物数据集,当属Ronald Fisher在1947年的论文中给出的数据集。它包含了144只猫的性别、体重和心脏重量。该数据集的地址:
https://github.com/mathisonian/datasets-cats
其他的宠物数据集还包括:
http://www.robots.ox.ac.uk/~vgg/data/pets/
VGG提供的图片数据集,有语义分割的标签。
https://www.kaggle.com/c/dogs-vs-cats/data
kaggle的猫狗图片数据集
http://vision.stanford.edu/aditya86/ImageNetDogs/
Stanford的狗图片数据集。
WMT
WMT数据集是一个多语种的机器翻译数据集。
官网:
http://www.statmt.org/
这里不仅包含数据,还包含了若干相关软件。
数据下载:
http://data.statmt.org/
合集
https://mp.weixin.qq.com/s/jezxjPZTnOXWca-VUpfslw
AI研发者福利!谷歌推出数据集搜索专用引擎Dataset Search
https://mp.weixin.qq.com/s/Kmq2tG5XQUO9k1pD3YW2oA
从文本处理到自动驾驶:机器学习最常用的50大免费数据集
https://mp.weixin.qq.com/s?__biz=MzA3NDIyMjM1NA==&mid=2649030010&idx=1&sn=76e0123bf24064c4cb1eb7acacac86fd
深度学习从“数据集”开始
http://www.csdn.net/article/2014-06-06/2820111-100-Interesting-Data-Sets-for-Statistics/1
100+诡异的数据集
https://mp.weixin.qq.com/s/NjJRSim8DLvKoI01PMkNfw
机器学习高质量数据集大合辑
http://www.sogou.com/labs/
搜狗实验室的网站可以下载很多NLP和图片识别方面的数据
https://mp.weixin.qq.com/s/ywjgVzEh8e7-lcUmIAtzCA
这是一份非常全面的开源数据集,你真的不想要吗
https://zhuanlan.zhihu.com/p/25138563
各领域公开数据集下载
https://mp.weixin.qq.com/s/_A71fTgwSyaW5XTAySIGOA
最强数据集集合:50个最佳机器学习公共数据集
https://mp.weixin.qq.com/s/Aatv0Q-Mfkkb75h_ZF8AIA
100大机器学习数据集,总有一款适合你!
https://mp.weixin.qq.com/s/484E_ycxQVwKOD6Lcpy-GQ
开放数据集
http://www.dataonthemind.org/data-resources/datasets
认知科学数据集大列表Center for Data on the Mind
https://mp.weixin.qq.com/s/0-gBsoxKaXZz7ojtFrGlvQ
史上最全数据集网站汇总
https://mp.weixin.qq.com/s/B-dEz-uUfjG1r98glkY3Fg
数据科学家必用的25个深度学习的开放数据集!
https://mp.weixin.qq.com/s/vaIhDnyQ7vh8kfrgCpXpQA
从医疗语音到灾难响应,这八大优质数据集快抱走
https://mp.weixin.qq.com/s/COnDB9EveANOBmCksCqoYg
微软内部研究数据集正式对外开放,覆盖NLP、CV等9个领域
https://mp.weixin.qq.com/s/4jhtCUtv_szfMvyDCWKvoQ
最强数据集50个最佳机器学习公共数据,可以帮你验证idea!
NLP
https://mp.weixin.qq.com/s/tewjGzfAVCKcG1dlURxyeg
MIT发布的10大自然语言处理数据集和语料库
https://github.com/candlewill/Dialog_Corpus/blob/master/README.md
用于对话系统的中英文语料
https://mp.weixin.qq.com/s/qh4evahPVjvZlzqan7RIKg
囊括欧亚非大陆多种语言的25个平行语料库数据集
https://mp.weixin.qq.com/s/37cUxUzcSZ_OgfuN_yTmlA
阅读理解与问答数据集
https://mp.weixin.qq.com/s/W48TlxSLPk2E2DuSzEidNA
免费文本语料训练数据集
https://mp.weixin.qq.com/s/K1eYjrrWuHu8JgWgoDliJw
百度的中文问答数据集WebQA
https://mp.weixin.qq.com/s/WfcFiRXBKAMqnDi5KFpIEA
百万级字符:清华大学提出中文自然文本数据集CTW
https://mp.weixin.qq.com/s/AdzBrseH3SOgo5BrbjWVpw
机器能做中/高考英语试题吗?
https://mp.weixin.qq.com/s/myg_PCdHB3DUtdA7ROmTOg
100+个自然语言处理数据集大放送,再不愁找不到数据!
https://mp.weixin.qq.com/s/eAqtNDT7LDdMg_41QWJ5iA
DuReader:百度大规模的中文机器阅读理解数据集
https://mp.weixin.qq.com/s/tENiB4P1--sD5B5r3Af16w
Chinese Word Vectors:目前最全的中文预训练词向量集合
https://mp.weixin.qq.com/s/S6KrNNz3TJQr8i3-fAZe-Q
今日头条新闻文本分类数据集
https://mp.weixin.qq.com/s/gAFNbMhatFVwnGmBEUFOQA
耶鲁大学发布自然语言处理资源引擎TutorialBank: 让NLP学习不再困难
https://mp.weixin.qq.com/s/WkDTGxWtgUMjpIoO4LkLRg
腾讯AI Lab开源800万中文词的NLP数据集
https://mp.weixin.qq.com/s/isUT--guYrsIWRXApcutrg
耶鲁大学11名学生标注完成大规模复杂跨域Text-to-SQL数据集Spider
http://universaldependencies.org/
一个依存语法方面的标注数据集。这类数据也叫做treebank数据,原因是依存语法生成的结果是一棵语法树。
https://mp.weixin.qq.com/s/7xFlELcm325Q6wEB5Pyphg
让AI学会刨根问底和放飞自我,斯坦福最新问答数据集CoQA
https://mp.weixin.qq.com/s/Rf3NAYlNMrcVythVA-90cQ
端到端对话模型新突破!Facebook发布大规模个性化对话数据库
https://mp.weixin.qq.com/s/LC6bJOsJczTLolQ1Yx5cvg
最全中华古诗词数据库:近14k唐宋古诗人, 55k首唐诗,60k宋诗
https://mp.weixin.qq.com/s/yZ138cMv4203wJdIY_0sUA
FAIR重磅发布大规模语料库XNLI:解决跨15种语言理解难题
https://mp.weixin.qq.com/s/RduLMsu599YRSsxd-mjX2A
最新任务型对话数据集大全
https://github.com/fighting41love/funNLP
40个中文NLP词库
https://mp.weixin.qq.com/s/KK7jCN5yN_TOrnNQWLuUNg
CMU多语种语音数据集:700多种语言的语音/文本对齐语料
https://mp.weixin.qq.com/s/xzHMzQ4uVBJaUR8b_KNptA
你说“神马”?非正式汉语数据集资源上线,帮你训练网络语言处理
CV
http://www.cvpapers.com/datasets.html
常见的cvpr研究的数据库下载链接
https://mp.weixin.qq.com/s/SKZhcd3QpoVMubTkD14iWw
Fashion-MNIST:替代MNIST手写数字集的图像数据集
https://niessner.github.io/Matterport/
全球最大的3D数据集公开了!标记好的10800张全景图
https://mp.weixin.qq.com/s/q2lsD4MSqQG-LqRmVjEHeg
图像配对数据集TTL:展现人类和机器判断图像相似性的差异
https://mp.weixin.qq.com/s/Y__z-0nxAZNuZsZefCm4IA
纽约大学联合谷歌大脑提出“COG”数据集,可提高系统的“视觉推理”能力
https://mp.weixin.qq.com/s/0D8OQ6hF_70mNtadewyGVw
全球最大的第一视角视频数据集开源,取自真实生活,还能提升厨艺
https://mp.weixin.qq.com/s/NXI9Bp4xxbZCQqAddK1HgA
Google开放最大目标检测数据集,还要为它举办AI挑战赛
https://mp.weixin.qq.com/s/DsBoGT2Pl4tRwHX8REOqnw
MURA:斯坦福ML团队开放的大型放射影像数据集与挑战赛
https://mp.weixin.qq.com/s/_wQoiC6ogcLWSEUFUGHd5g
Facebook,MIT等发布大规模卫星图像理解数据挑战赛DeepGlobe 2018
https://mp.weixin.qq.com/s/WPESySGMv_ehSt6oNUkVGg
视频语义显著实例分割数据集SESIV
https://mp.weixin.qq.com/s/fR8-zODLNp24nlR5dJ85Nw
3万患者11万图像14类病理:NIH公开大规模胸部X光数据集
https://mp.weixin.qq.com/s/d-fIQwMxHXTJvFWQUKHAvw
我用5000万组数据分析了“猜画小歌”
https://mp.weixin.qq.com/s/jOjiAAK1byUx8ic011f33w
2200万室内场景数据集,包含语义、全景、灯光等十余种效果
https://mp.weixin.qq.com/s/aw5o-1Bwc4hQUatehFFx2A
南京大学发布WebCaricature漫画人脸识别数据集
https://mp.weixin.qq.com/s/deJ6dChES_WhYH8T05ruag
腾讯AI实验室宣布开源多标签图像数据集ML-Images
https://mp.weixin.qq.com/s?__biz=MzA3MzI4MjgzMw==&mid=2650750713&idx=5&sn=678eef1122d35c048a5fca8f22fa12c9
CIFAR-10+ImageNet=?CINIC-10!
https://mp.weixin.qq.com/s/Kxnvv1i0nvkg0vUDBlx6MA
向机器学习偏见开战:谷歌展示全球涂鸦数据集分析结果
https://mp.weixin.qq.com/s/vTnc55KAiGaFfktHPZctbw
捡漏!用谷歌图片搜索自制深度学习数据集
https://mp.weixin.qq.com/s/-NQa2VeuskDx5XN9WMCmPQ
腾讯开源业内最大多标签图像数据集,附ResNet-101模型
https://mp.weixin.qq.com/s/8nPfU72WocrDxToG6v5tIA
计算摄影学数据集汇总(一)