python入门使用
1.导入包
import pandas as pd
import numpy as np
2.读取表格
df=pd.read_csv('C:\\Users\\lingtian\\Desktop\\DataAnalyst.csv',encoding='gb2312') // 除此之外还有read_excel和read_table,table可以读取txt。若是服务器相关的部署,则还会用到read_sql,直接访问数据库,但它必须配合mysql相关包。
链接可以写双\\ 可以写反/
读取sheet #通过表名 In [17]: sheet = pd.read_excel('example.xls',sheet_name= 'Sheet2')
#通过表的位置 In [19]: sheet = pd.read_excel('example.xls',sheet_name= 1)
https://blog.csdn.net/brucewong0516/article/details/79096633
3.预览
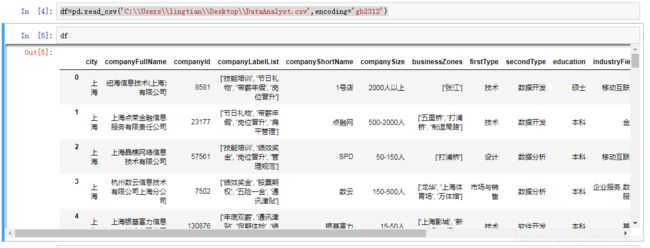
df
4.预览N行表格情况
df.head(6) //查看前6行,括号里不加6,则默认5行
df.tail(3) //查看后6行

5.快速查看表格数据类型
df.info() // 这里列举出了数据集拥有的各类字段

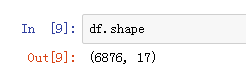
6. 查看数据表的维度,也就是行数和列数
df.shape //6876行,17列
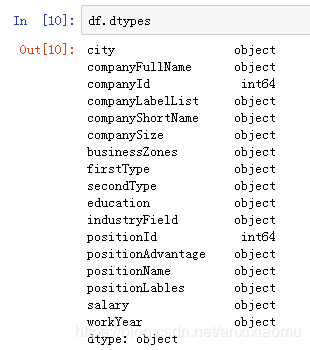
7.查看数据类型
df.dtypes #查看数据表各列格式
df['B'].dtype #查看单列格式
8.查看空值
df.isnull() #返回的结果是逻辑值,包含空值返回True,不包含则返回False。可以对整个数据表进行检查,也可以单独对某一列进行空值检查。
df['city'].isnull() #检查特定列空值
9.查看唯一值
#两种写法都对

10.去除重复项
df_duplicates=df.drop_duplicates(subset='positionId',keep='first')
df_duplicates.head()
# drop_duplicates函数通过subset参数选择以哪个列为去重基准。keep参数则是保留方式,first是保留第一个,删除后余重复值,last是删除前面,保留最后一个。duplicated函数功能类似,但它返回的是布尔值。

11.表中类型转换
df.return_tp.astype('str')
12.分列
df_split_1=pd.merge(df, pd.DataFrame(df['return_tp'].str.split(',',expand=True)), how='left', left_index=True, right_index=True)
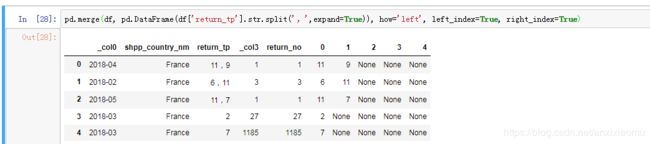
将分列后的内容自动转变匹配到行中
df_split_2=df.drop('return_tp', axis=1).join(df['return_tp'].str.split(',', expand=True).stack().reset_index(level=1, drop=True).rename('return_tp'))
多个分隔符分列时,加[ ] 中括号
df_split_2=df.drop('支付返回信息', axis=1).join(df['支付返回信息'].str.split('[|||]', expand=True).stack().reset_index(level=1, drop=True).rename('支付返回信息'))
13.输出表格
df_inner.to_excel('excel_to_python.xlsx', sheet_name='bluewhale_cc')
pandas分隔字符 https://blog.csdn.net/qq_22238533/article/details/76187597
14.地址分号有问题
df=pd.read_csv('0725.csv',quoting = 3)
解释quoting https://blog.csdn.net/u012803639/article/details/64128295
15.按筛选条件去重计数
df_choose=df.loc[(df['EM per CC'] == 3) & (df['AD per CC'] == 1), ['全部']]
df_1=df_choose.drop_duplicates() #去重,去重还可以用unique
df_1.count() #计数
16.pandas中进行连接用:
pd.merge(df1, df2, on='key')
pd.merge(left, right, on = ['key1', 'key2']) #多条件合并
等同于
SELECT *
FROM df1
INNER JOIN df2
ON df1.key = df2.key;
或
SELECT *
FROM df1,df2 where df1.key=df2.key
#coding=utf-8
from pandas import Series,DataFrame,merge
import numpy as np
data=DataFrame([{"id":0,"name":'lxh',"age":20,"cp":'lm'},{"id":1,"name":'xiao',"age":40,"cp":'ly'},{"id":2,"name":'hua',"age":4,"cp":'yry'},{"id":3,"name":'be',"age":70,"cp":'old'}])
data1=DataFrame([{"id":100,"name":'lxh','cs':10},{"id":101,"name":'xiao','cs':40},{"id":102,"name":'hua2','cs':50}])
data2=DataFrame([{"id":0,"name":'lxh','cs':10},{"id":101,"name":'xiao','cs':40},{"id":102,"name":'hua2','cs':50}])
print "单个列名做为内链接的连接键\r\n",merge(data,data1,on="name",suffixes=('_a','_b'))
print "多列名做为内链接的连接键\r\n",merge(data,data2,on=("name","id"))
print '不指定on则以两个DataFrame的列名交集做为连接键\r\n',merge(data,data2) #这里使用了id与name
#使用右边的DataFrame的行索引做为连接键
##设置行索引名称
indexed_data1=data1.set_index("name")
print "使用右边的DataFrame的行索引做为连接键\r\n",merge(data,indexed_data1,left_on='name',right_index=True)
print '左外连接\r\n',merge(data,data1,on="name",how="left",suffixes=('_a','_b'))
print '左外连接1\r\n',merge(data1,data,on="name",how="left")
print '右外连接\r\n',merge(data,data1,on="name",how="right")
data3=DataFrame([{"mid":0,"mname":'lxh','cs':10},{"mid":101,"mname":'xiao','cs':40},{"mid":102,"mname":'hua2','cs':50}])
#当左右两个DataFrame的列名不同,当又想做为连接键时可以使用left_on与right_on来指定连接键
print "使用left_on与right_on来指定列名字不同的连接键\r\n",merge(data,data3,left_on=["name","id"],right_on=["mname","mid"])
17.拼接字段 https://blog.csdn.net/u012063773/article/details/73863212
18.读取文本出问题了,gb2312读取不了时,可以换取编码范围更大的gb18030,如果还不行,可以直接忽略非法字符
df=pd.read_csv('C:/Users/lingtian/Desktop/Data Cal - Sub2.csv',encoding='gb18030')
df=pd.read_csv('C:/Users/lingtian/Desktop/Data Cal - Sub2.csv',encoding='gb18030',errors='ignore')
19.字段拼接
#map(str)转换字符串
df["newColumn"] = df["Card Number"].map(str) + df["RGID"].map(str)
df.head()
#先转换成字符串类型的
df['Card Number']=df['Card Number'].astype('string_')
df['RGID']=df['RGID'].astype('string_')
#拼接两个字段
df['new']=df['Card Number']+df['RGID']
#输出
df.to_csv('C:/Users/lingtian/Desktop/0-0.csv')