python学习之第一个入门爬虫
昨天得知苍老师结婚的微博,不由得想结合一下所学的python写个爬虫,爬一下苍老师的作品。
前提准备:Anaconda3(要完全安装哦)
编写代码:
# -*- coding: utf-8 -*-
"""
Created on Tue Jan 2 22:30:00 2018
@author: ARCHer
"""
from bs4 import BeautifulSoup
import requests
info = []
name = ''
name = input('请输入你要寻找的影片并回车\n')
print('请稍等......')
page = 0
step = 1
page_url = 'https://www.zhongzidi.com/list/' + name + '/1'
page_wb_data = requests.get(page_url)
page_wb_data.encoding='utf-8'
page_Soup = BeautifulSoup(page_wb_data.text,'lxml')
last = page_Soup.select('div > div > ul > li > a')
pagemax = last[-1].get('href')
if pagemax == '/about.php#about':
pages = 1
else:
j = 1
pages = 0
while pagemax[-j] != '/':
pages = pages + int(pagemax[-j])*pow(10,j-1)
j = j + 1
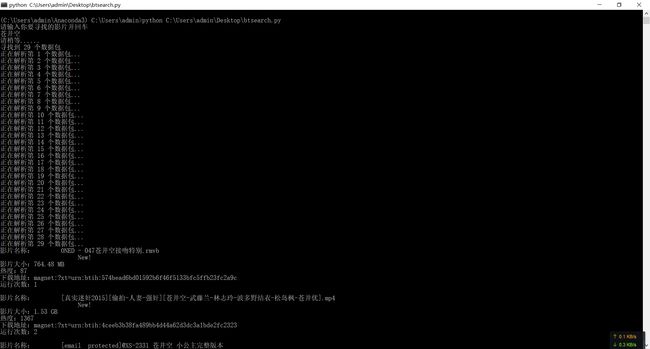
print('寻找到',pages,'个数据包')
while page < pages:
print('正在解析第',page+1,'个数据包...')
page = page + 1
url = 'https://www.zhongzidi.com/list/' + name + '/' + str(page)
wb_data = requests.get(url)
wb_data.encoding='utf-8'
Soup = BeautifulSoup(wb_data.text,'lxml')
last = Soup.select('div > div > ul > li')
titles = Soup.select('div.panel-body.table-responsive.table-condensed > table > tbody > tr:nth-of-type(1) > td > div')
sizes = Soup.select('div.panel-body.table-responsive.table-condensed > table > tbody > tr:nth-of-type(2) > td:nth-of-type(2) > strong')
hots = Soup.select('div.panel-body.table-responsive.table-condensed > table > tbody > tr:nth-of-type(2) > td:nth-of-type(3) > strong')
magnets = Soup.select('div.panel-body.table-responsive.table-condensed > table > tbody > tr:nth-of-type(2) > td.ls-magnet > a')
for title,size,hot,magnet in zip(titles,sizes,hots,magnets):
data = {
'title':title.get_text(),
'size':size.get_text(),
'hot':hot.get_text().strip(' '),
'magnet':magnet.get('href'),
'step':step
}
step = step + 1
info.append(data)
for i in info:
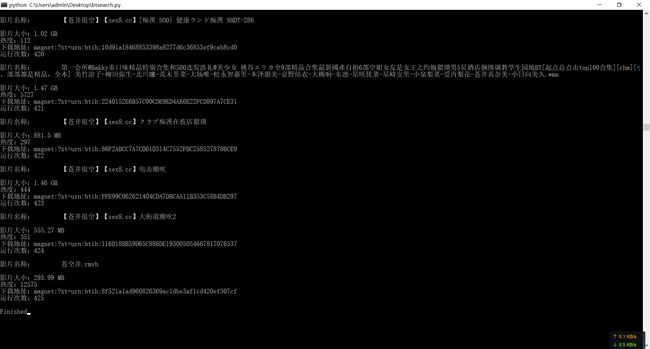
print('影片名称:'+i['title']+'\n'+'影片大小:'+i['size']+'\n'+'热度:'+i['hot']+'\n'+'下载地址:'+i['magnet']+'\n'+'运行次数:'+str(i['step'])+'\n')
input('Finished')对于代码中的一些解释:
if pagemax == '/about.php#about':
pages = 1
else:
j = 1
pages = 0
while pagemax[-j] != '/':
pages = pages + int(pagemax[-j])*pow(10,j-1)
j = j + 1这里是根据读取网页源码来判断是否需要翻页操作。
print('正在解析第',page+1,'个数据包...')这种代码是为了执行起来知道进行到了哪一步,个人认为比较实用。
下面来讲解一下BeautifulSoup:
from bs4 import BeautifulSoup
page_Soup = BeautifulSoup(page_wb_data.text,'lxml')第二句是他的格式,BeautifulSoup(data.text,'lxml'),我的理解这里data.text是要读取的网页源码文本,而lxml是指解析方式,还有很多种,lxml应该算是比较常用的。
使用page_soup变量来储存。
其他的就很好理解了,来看看效果: