MySQL大表传输表空间的坑
MySQL大表传输表空间的坑
最近刚帮业务线拆分完数据库, 源环境遗留了一张700G的大表, 虽说现在不用了, 但是业务方还是不希望删掉, 于是打算把这张表迁移到归档库, 这样有需要是还可以查询.
700G的表想了想, 如果是逻辑导出再导入的话, 感觉会很慢. 于是决定使用传输表空间方式恢复到归档库中
源库和归档库均为MGR集群 Multi-Primary Mode.
恢复备份
过程简单写, 并非本文重点
xbstream -vx --parallel=10 < mysql_backup_20190618.xbstream -C /rundata/backup/ > /tmp/xb.log 2>&1 &
cd /rundata/backup/datadir
rm 除这张700g表A的所有其他表的qp文件
xtrabackup --decompress --parallel=10 --remove-original --target-dir=/rundata/backup/
innobackupex --apply-log --export /rundata/backup/
开始传输表空间
1.在归档库创建该表
mysql> create table A
3.在归档库写节点执行
mysql> alter table A discard tablespace;
3.将上一步产生的 A.ibd A.cfg 传输到归档库MGR集群每一个节点的datadir目录下
chown mysql:mysql A.*
mysql> alter table A import tablespace;
拷贝到所有节点的原因详见 主从传输表空间的坑
此时发现import tablespace卡住了State为System lock, 查看processlist
+----------+----------------+----------------------+----------+-------------+----------+---------------------------------------------------------------+-------------------------------------------------------+
| Id | User | Host | db | Command | Time | State | Info |
+----------+----------------+----------------------+----------+-------------+----------+---------------------------------------------------------------+-------------------------------------------------------+
| 370 | system user | | NULL | Connect | 26094679 | executing | NULL |
| 373 | system user | | NULL | Connect | 3703683 | Slave has read all relay log; waiting for more updates | NULL |
| 374 | system user | | NULL | Connect | 26094679 | Waiting for an event from Coordinator | NULL |
| 375 | system user | | NULL | Connect | 19086256 | Waiting for an event from Coordinator | NULL |
| 376 | system user | | NULL | Connect | 19086744 | Waiting for an event from Coordinator | NULL |
| 377 | system user | | NULL | Connect | 19086744 | Waiting for an event from Coordinator | NULL |
| 378 | system user | | NULL | Connect | 19086744 | Waiting for an event from Coordinator | NULL |
| 379 | system user | | NULL | Connect | 19086894 | Waiting for an event from Coordinator | NULL |
| 380 | system user | | NULL | Connect | 19086894 | Waiting for an event from Coordinator | NULL |
| 381 | system user | | NULL | Connect | 19086903 | Waiting for an event from Coordinator | NULL |
| 33199176 | dbms_monitor_r | 192.168.X.81:38804 | NULL | Binlog Dump | 7696834 | Master has sent all binlog to slave; waiting for more updates | NULL |
| 58758525 | root | localhost | archive | Query | 1598 | System lock | ALTER TABLE A IMPORT TABLESPACE |
| 58764027 | root | localhost | NULL | Query | 0 | starting | show processlist |
+----------+----------------+----------------------+----------+-------------+----------+---------------------------------------------------------------+-------------------------------------------------------+
查看error log, 发现在阶段1 Update all pages
2019-06-22T06:34:14.173468Z 58758525 [Note] InnoDB: Importing tablespace for table 'origin_db/A' that was exported from host 'Hostname unknown'
2019-06-22T06:34:14.173672Z 58758525 [Note] InnoDB: Phase I - Update all pages
又等了一会, 发现监控任务执行的SQL被阻塞了.
+----------+----------------+----------------------+--------------------+-------------+----------+---------------------------------------------------------------+------------------------------------------------------------------------------------------------------+
| Id | User | Host | db | Command | Time | State | Info |
+----------+----------------+----------------------+--------------------+-------------+----------+---------------------------------------------------------------+------------------------------------------------------------------------------------------------------+
| 370 | system user | | NULL | Connect | 26094907 | executing | NULL |
| 373 | system user | | NULL | Connect | 3703911 | Slave has read all relay log; waiting for more updates | NULL |
| 374 | system user | | NULL | Connect | 26094907 | Waiting for an event from Coordinator | NULL |
| 375 | system user | | NULL | Connect | 19086484 | Waiting for an event from Coordinator | NULL |
| 376 | system user | | NULL | Connect | 19086972 | Waiting for an event from Coordinator | NULL |
| 377 | system user | | NULL | Connect | 19086972 | Waiting for an event from Coordinator | NULL |
| 378 | system user | | NULL | Connect | 19086972 | Waiting for an event from Coordinator | NULL |
| 379 | system user | | NULL | Connect | 19087122 | Waiting for an event from Coordinator | NULL |
| 380 | system user | | NULL | Connect | 19087122 | Waiting for an event from Coordinator | NULL |
| 381 | system user | | NULL | Connect | 19087131 | Waiting for an event from Coordinator | NULL |
| 33199176 | dbms_monitor_r | 192.168.X.81:38804 | NULL | Binlog Dump | 7697062 | Master has sent all binlog to slave; waiting for more updates | NULL |
| 58758525 | root | localhost | archive | Query | 1826 | System lock | ALTER TABLE A IMPORT TABLESPACE |
| 58764075 | dbms_monitor_r | 192.168.X.142:41144 | information_schema | Query | 214 | Waiting for table metadata lock | select * from tables |
| 58764750 | dbms_monitor_r | 192.168.X.142:25374 | mysql | Query | 18 | Waiting for table metadata lock | select * from information_schema.tables where table_schema not in ('mysql','information_schema','sys |
| 58764840 | root | localhost | NULL | Query | 0 | starting | show processlist |
+----------+----------------+----------------------+--------------------+-------------+----------+---------------------------------------------------------------+------------------------------------------------------------------------------------------------------+
查看innodb status
[2019-06-22 14:35:11]root@localhost 14:35:02 [(none)]> show engine innodb status\G
[2019-06-22 14:35:11]------------
[2019-06-22 14:35:11]TRANSACTIONS
[2019-06-22 14:35:11]------------
[2019-06-22 14:35:11]Trx id counter 3747414252
[2019-06-22 14:35:11]Purge done for trx's n:o < 3747414158 undo n:o < 0 state: running but idle
[2019-06-22 14:35:11]History list length 1
[2019-06-22 14:35:11]LIST OF TRANSACTIONS FOR EACH SESSION:
[2019-06-22 14:35:11]---TRANSACTION 422073426655200, not started
...
[2019-06-22 14:35:11]0 lock struct(s), heap size 1136, 0 row lock(s)
[2019-06-22 14:35:11]MySQL thread id 58758525, OS thread handle 140583989245696, query id 6550373059 localhost root System lock
[2019-06-22 14:35:11]ALTER TABLE sales_sku_operation_log IMPORT TABLESPACE
[2019-06-22 14:35:11]---TRANSACTION 3747414146, ACTIVE 57 sec importing tablespace
[2019-06-22 14:35:11]mysql tables in use 1, locked 1
[2019-06-22 14:35:11]1 lock struct(s), heap size 1136, 0 row lock(s)
[2019-06-22 14:35:11]MySQL thread id 58758525, OS thread handle 140583989245696, query id 6550373059 localhost root System lock
[2019-06-22 14:35:11]ALTER TABLE sales_sku_operation_log IMPORT TABLESPACE
虽然innodb status我已经基本不会看了, 但是从TRANSACTIONS这里也可以看到IMPORT TABLESPACE语句并没有被什么锁阻塞
当时想不明白为啥import tablespace会这么慢, 以为被MGR复制的相关线程阻塞了,或者有什么bug之类的, 怕影响业务(虽说是归档库). 于是我kill了这个import tablespace语句,
kill 58758525;
在这之后如果想重新执行ALTER TABLE A IMPORT TABLESPACE会报错
root@localhost 15:11:53 [mafengwo]> ALTER TABLE sales_sku_operation_log IMPORT TABLESPACE;
ERROR 1815 (HY000): Internal error: Cannot reset LSNs in table `mafengwo`.`sales_sku_operation_log` : Data structure corruption
观察集群三个节点的文件状态发现, 执行ALTER TABLE A IMPORT TABLESPACE语句的节点的A.ibd文件修改时间变了(而其他节点没有变化).
[root@node001189 mafengwo]# ll | grep A
-rw-r--r-- 1 mysql mysql 1091 Jun 21 13:20 A.cfg
-rw-r----- 1 mysql mysql 16384 Jun 21 13:20 A.exp
-rw-r----- 1 mysql mysql 9094 Jun 22 14:11 A.frm
-rw-r--r-- 1 mysql mysql 799329484800 Jun 21 13:20 A.ibd
执行ALTER后
[root@node001189 mafengwo]# ll | grep A
-rw-r--r-- 1 mysql mysql 1091 Jun 21 13:20 A.cfg
-rw-r----- 1 mysql mysql 16384 Jun 21 13:20 A.exp
-rw-r--r-- 1 mysql mysql 799329484800 Jun 22 15:12 A.ibd --变了
为什么IMPORT TABLESPACE会卡住?
正常的import流程,日志中会有如下输出
2013-07-18 15:15:01 34960 [Note] InnoDB: Importing tablespace for table 'test/t' that was exported from host 'ubuntu'
2013-07-18 15:15:01 34960 [Note] InnoDB: Phase I - Update all pages
2013-07-18 15:15:01 34960 [Note] InnoDB: Sync to disk
2013-07-18 15:15:01 34960 [Note] InnoDB: Sync to disk - done!
2013-07-18 15:15:01 34960 [Note] InnoDB: Phase III - Flush changes to disk
2013-07-18 15:15:01 34960 [Note] InnoDB: Phase IV - Flush complete
我觉得问题关键在于InnoDB: Phase I - Update all pages到底做了什么, 因为事实上import过程一直卡在这里, 没有进入下一步
google了一圈发现一个类似的问题, 但是并没有答案(现在有了是我回答的)
https://dba.stackexchange.com/questions/165147/import-tablespace-is-hanging-in-the-system-lock-state/241182#241182
查看官方文档
https://dev.mysql.com/doc/refman/8.0/en/tablespace-copying.html
When ALTER TABLE … IMPORT TABLESPACE is run on the destination instance, the import algorithm performs the following operations for each tablespace being imported:
-
Each tablespace page is checked for corruption.
-
The space ID and log sequence numbers (LSNs) on each page are updated
-
Flags are validated and LSN updated for the header page.
-
Btree pages are updated.
-
The page state is set to dirty so that it is written to disk.
查看worklog
https://dev.mysql.com/worklog/task/?id=5522
Import algorithm
================
We scan the blocks in extents and modify individual blocks rather than using
logical index structure.
foreach page in tablespace {
1. Check each page for corruption.
2. Update the space id and LSN on every page --I think this is what "InnoDB: Phase I - Update all pages" does
* For the header page
- Validate the flags
- Update the LSN
3. On Btree pages
* Set the index id
* Update the max trx id
* In a cluster index, update the system columns
* In a cluster index, update the BLOB ptr, set the space id
* Purge delete marked records, but only if they can be easily
removed from the page
* Keep a counter of number of rows, ie. non-delete-marked rows
* Keep a counter of number of delete marked rows
* Keep a counter of number of purge failure
* If a page is stamped with an index id that isn't in the .cfg file
we assume it is deleted and the page can be ignored.
* We can't tell free pages from allocated paes (for now). Therefore
the assumption is that the free pages are either empty or are logically
consistent. TODO: Cache the extent bitmap and check free pages.
4. Set the page state to dirty so that it will be written to disk.
}
还有一个文档, 不过感觉不如上面两个说的明白
https://bugs.mysql.com/bug.php?id=75706
看到这里我认为
InnoDB: Phase I - Update all pages 阶段执行的就是 (按extend扫描整个表, 修改每个page的LSN等)
2. Update the space id and LSN on every page
* For the header page
- Validate the flags
- Update the LSN
这一步一定很耗时, 查看监控, 也确实发现执行ALTER TABLE A IMPORT TABLESPACE的节点再这个时间段IO有明显上升
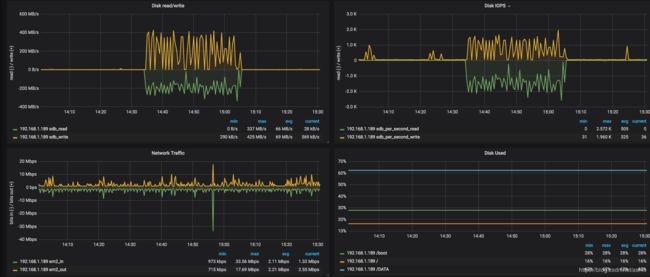
其他节点
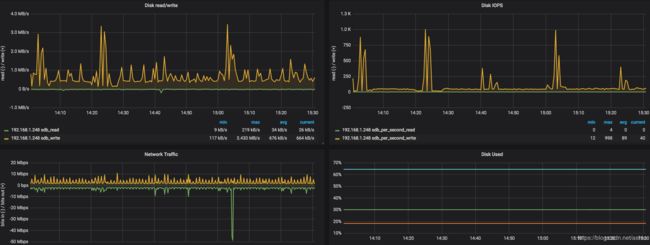
所以这会导致什么问题?
会导致复制延迟
无论主从复制, PXC 还是 MGR ,本质都是应用binlog
示例, 与之前的操作无关
/usr/local/mysql-5.7.23-linux-glibc2.12-x86_64/bin/mysqlbinlog -vv --base64-output=decode-rows 0242133310-relay-bin-group_replication_applier.000002|less
SET @@SESSION.GTID_NEXT= '88f93f74-ed3a-50c0-bc63-beb926cedcb5:1033040'/*!*/;
# at 15134136
#190621 10:45:09 server id 242123310 end_log_pos 126 Query thread_id=4948397 exec_time=0 error_code=0
SET TIMESTAMP=1561085109/*!*/;
alter table t_monitor_sync_delay DISCARD TABLESPACE
/*!*/;
# at 15134262
#190227 16:34:38 server id 242123310 end_log_pos 61 GTID last_committed=196812 sequence_number=196813 rbr_only=no
SET @@SESSION.GTID_NEXT= '88f93f74-ed3a-50c0-bc63-beb926cedcb5:1033041'/*!*/;
# at 15134323
#190621 10:46:21 server id 242123310 end_log_pos 125 Query thread_id=4948487 exec_time=0 error_code=0
SET TIMESTAMP=1561085181/*!*/;
alter table t_monitor_sync_delay import tablespace
/*!*/;
# at 15134448
#190227 16:34:38 server id 242123310 end_log_pos 61 GTID last_committed=198535 sequence_number=198536 rbr_only=no
可以看到binlog中其实只记录了alter table t_monitor_sync_delay DISCARD TABLESPACE 和 alter table t_monitor_sync_delay import tablespace两个语句, 并没有对这张表的INSERT语句
我们假设发起import tablespace的节点最终话费1小时更新了所有A表pages的LSN和其他信息, 成功的跑完了import tablespace语句.
当其他节点应用到这个import tablespace语句是就也要花费1小时去做相同的操作, 那面后面的事务是否就需要等待这个import tablespace执行完毕呢?
所以应该如何导入?
以三节点MGR为例
先建表
create table A
然后一个一个节点执行
stop group_replication
set read_only=1, 确保没有数据写入
set sql_log_bin=0
alter table A discard tablespace
alter table A import tablespace
set sql_log_bin=1
start group_replication