机器学习算法应用篇之决策树算法(sklearn)
从本篇文章开始,我将开始写机器学习算法的一系列文章,总结自己在学习应用机器学习算法过程中的学习经验与方法,主要利用工具是python的机器学习库sklearn。主要包括以下算法:决策树算法(ID3,ID4.5,CART等),朴素贝叶斯方法(Navie Bayes),支持向量基(SVM),K均值算法(K-means),PageRank,K近邻方法(KNN),遗传算法,神经网络,主成分分析方法(PCA),流型方法(ISOMAP,LLE),期望最大化方法(EM)等,不定期更新。希望大家一起学习。
1.决策树
决策树算法主要是用于处理多变量决策类问题,类似于这类问题。同样处理多变量问题还有贝叶斯方法,神经网络等。

根据你的年龄,收入,学生与否,信用卡状况来判断你是否会买电脑。根据决策树算法可以得到一棵完整的树,根据树由根节点出发可以得到是否买电脑(label)的预测。
所以决策树的定义可以为: 决策树(decision tree)是一个树结构(可以是二叉树或非二叉树)。其每个非叶节点表示一个特征属性上的测试,每个分支代表这个特征属性在某个值域上的输出,而每个叶节点存放一个类别。使用决策树进行决策的过程就是从根节点开始,测试待分类项中相应的特征属性,并按照其值选择输出分支,直到到达叶子节点,将叶子节点存放的类别作为决策结果。
2.算法
(1)ID3算法
ID3算法的核心思想就是以信息增益度量属性选择,选择分裂后信息增益最大的属性进行分裂。
(2)C4.5算法
ID3算法存在一个问题,就是偏向于多值属性,例如,如果存在唯一标识属性ID,则ID3会选择它作为分裂属性,这样虽然使得划分充分纯净,但这种划分对分类几乎毫无用处。ID3的后继算法C4.5使用增益率(gain ratio)的信息增益扩充,试图克服这个偏倚。
(3)CART算法
CART(Classification And Regression Tree)算法采用一种二分递归分割的技术,将当前的样本集分为两个子样本集,使得生成的的每个非叶子节点都有两个分支。因此,CART算法生成的决策树是结构简洁的二叉树。CART树是采用了不纯度的概念。
具体的算法介绍可以参考书或者以下几篇文章
https://www.cnblogs.com/leoo2sk/archive/2010/09/19/decision-tree.html
http://blog.csdn.net/hewei0241/article/details/8280490
3.应用(sklearn)
1.读取数据
df_data_1 = pd.read_csv("data_file")2.数据前处理(定义X,Y数据集)
df_data_1 = df_data_1.fillna("NA")#缺省数据用NA表示
exc_cols = [u'Airport Rating']
cols = [c for c in df_data_1.columns if c not in exc_cols]
X_data = df_data_1.ix[:,cols]
y_data = df_data_1[u'Airport Rating'].values[:]
#X_train1 = df_data_1.ix[:,['Airport Wi Fi Use','Boarding Area','Gender','Country','Signage Rating']]
print y_data.shape
print X_data.shape
dict_X_train = X_data.to_dict(orient='records')#列表转换为字典3.导入模型(主要使用的sklearn中的tree(建立决策树模型),DictVectorizer(将文本向量化),processing(label的向量化))
import numpy as np
import pandas as pd
from sklearn import tree
from sklearn.feature_extraction import DictVectorizer
from sklearn import preprocessing4.测试集、数据集、one-hot
vec = DictVectorizer()
X_data = vec.fit_transform(dict_X_train).toarray()
X_train = X_data[:1300,:]
X_test = X_data[1300:,:]
y_train = y_data[:1300]
y_test = y_data[1300:]
print X_train.shape
print X_test.shape
lb = preprocessing.MultiLabelBinarizer()
dict_y_train = lb.fit_transform(y_train)5.建立CART树(criterion有’gini’和’entropy’两种建树规则)
tree 函数:
class sklearn.tree.DecisionTreeClassifier(criterion=’gini’,
splitter=’best’, max_depth=None,
min_samples_split=2,min_samples_leaf=1, min_weight_fraction_leaf=0.0,
max_features=None, random_state=None,
max_leaf_nodes=None,min_impurity_split=1e-07, class_weight=None,
presort=False)
http://scikit-learn.org/stable/modules/generated/sklearn.tree.DecisionTreeClassifier.html
其中比较重要的参数:
- criterion :规定了该决策树所采用的的最佳分割属性的判决方法,有两种:“gini”,“entropy”。 gini值表示采用了CART树的规则,即不纯度来作为树结构的指标,而entropy则表示选择C3树的规则,即信息增益来作为树结构产生的标准。
- max_depth:限定了决策树的最大深度,防止过拟合
- min_samples_leaf:限定了叶子节点包含的最小样本数,这个属性对于防止数据碎片问题很有作用。
fit函数中一些重要的属性:
- n_classes_ :决策树中的类数量。
- classes_ :返回决策树中的所有种类标签。
- feature_importances_:feature的重要性,值越大那么越重要。
- fit(X, y, sample_mask=None, X_argsorted=None,
check_input=True, sample_weight=None)
将数据集x,和标签集y送入分类器进行训练,这里要注意一个参数是:sample_weright,它和样本的数量一样长,所携带的是每个样本的权重。
决策树模型的一些重要属性方法:
- get_params(deep=True) :得到决策树的各个参数。
- set_params(**params) :调整决策树的各个参数。
- predict(X) :送入样本X,得到决策树的预测。可以同时送入多个样本。
- transform(X, threshold=None) :返回X的较重要的一些feature,相当于裁剪数据。
- score(X, y, sample_weight=None) :返回在数据集X,y上的测试分数,正确率。
使用建议:
当我们数据中的feature较多时,一定要有足够的数据量来支撑我们的算法,不然的话很容易overfitting 。
- PCA是一种避免高维数据overfitting的办法。从一棵较小的树开始探索,用export方法打印出来看看。
- 善用max_depth参数,缓慢的增加并测试模型,找出最好的那个depth。
- 善用min_samples_split和min_samples_leaf参数来控制叶子节点的样本数量,防止overfitting。
平衡训练数据中的各个种类的数据,防止一个种类的数据dominate。
以上引用自:http://blog.csdn.net/cherdw/article/details/54928619
clf = tree.DecisionTreeClassifier(criterion='gini')
clf = clf.fit(X_train,y_train)
with open("allElectronicInformationGainOri.dot", 'w') as f:#生成树
f = tree.export_graphviz(clf, feature_names = vec.get_feature_names(), out_file = f)6.决策树可视化
! pip install pydotplus
from IPython.display import Image
dot_data = StringIO()
tree.export_graphviz(clf,
out_file=dot_data,
feature_names=vec.get_feature_names(),
filled=True,rounded=True,
impurity=False)
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
Image(graph.create_png()) 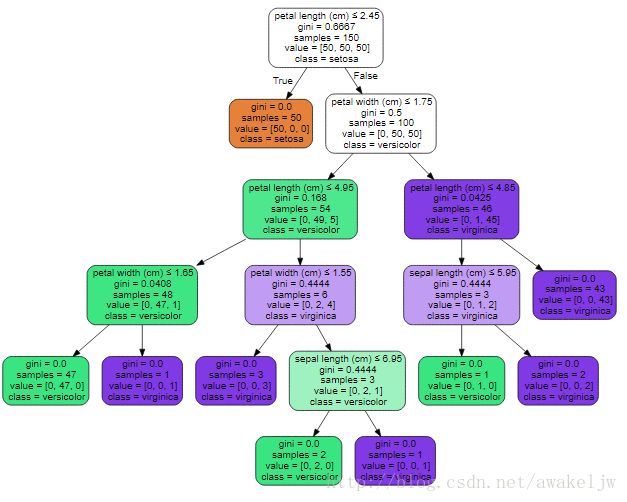
从可视化的决策树中可以看到根据划分的变量为petal length或者petal width,样本总数数是多少,分类的类型是哪个class,一共有setoss,versicolor,viginica三个类别,每个有50个例子,gini值是多少,也就是不纯度是多少,在叶子节点上不纯度一般均是0.第一次分类依据是petal length的大小,当其值小于2.45时,那么它的类别一定是setoss,然后根据petal width<1.75并且petal length<=4.95则是versicolor的可能性比较大,根据petal length<=4.85,则viginica的可能性大,依次向下判断,最后得到不纯度为0,则到达叶子节点。
关于决策树可视化的介绍可以参见:http://scikit-learn.org/stable/modules/tree.html
7.测试
predictedY = clf.score(X_test,y_test)
print str(predictedY)最近,google上线了机器学习的中文课程,第一节就是关于决策树算法的机器学习入门课程,欢迎大家一起学习。https://ai.google/education/#?modal_active=none