也谈谈机器学习中的Evaluation Metrics
判断事物的好坏需要一定的评判标准,判断分类系统的优劣自然需要一定的评判方式。作为设计机器学习系统的一个很重要的环节——评价指标(Evaluation Metric)即是本文的主角。本文首先介绍Accuracy单独作为评价指标可能有什么不足,再介绍从Precision-Recall到F-measure的推进,接着给出解决Accuracy Paradox的MCC(Matthews Correlation Coefficient),最后浅谈从ROC(Receiver Operating Characteristic)到AUC(Area Under Curve)。通过介绍这几种常见的Metrics,可以使得我们在行家面前不至于哑口无言。好,现在进入正题。
Accuracy为什么还不够
训练一个机器学习系统,懂行的大概都知道需要将训练数据至少切割为三部分,分别是training set,developing set和test set,前面两个data set用于训练模型和调整参数,后面的test set则用于测试系统的generalization performance。如何测试呢?这里就涉及到一些评判指标。最简单也是最直观能想到的是测试系统的准确率(即Accuracy),也就是对于test set中的 N 条数据,统计系统能够判断准确的数据条数 M ,最后进行简单相除得到 MN 作为评判标准。没错,很多时候以Accuracy作为评价标准并没有什么问题,那么,有什么情况使得以Accuracy作为评判标准变得不是一个好idea呢?为了探究这样的情况,我们必须深入研究一下系统的所有分类情形,特殊的,我们研究一下二元分类器的分类情形。
分类器的分类情形
假如我们用NaiveBayes算法训练出一个系统,可以用来识别邮件是否为垃圾,对于一封邮件的识别,有如下4种情况:
- 邮件为垃圾,系统正确识别为垃圾
- 邮件为垃圾,系统错误识别为非垃圾
- 邮件不是垃圾,系统正确识别为非垃圾
- 邮件不是垃圾,系统错误识别为垃圾
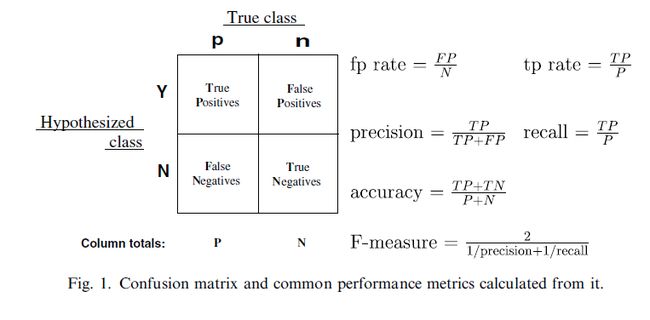
如上的4种情形,如果用一个2X2的表格概括起来,就是大名鼎鼎的Confusion Matrix:

其中True和False是对于评价预测结果而言,也就是评价预测结果是正确的(True)还是错误的(False)。而Positive和Negative则是对分类器的预测结果而言,Positive为预测是垃圾,Negative是预测为非垃圾。为了表达方便,一般会以他们的缩写TP,FP,FN,TN代替。那么上面提到的邮件分类四种情形对应一下就变成如下:
- 邮件为垃圾,系统正确识别为垃圾(TP正确地预测为垃圾)
- 邮件不是垃圾,系统错误识别为垃圾(FP错误的预测为垃圾)
- 邮件不是垃圾,系统正确识别为非垃圾(TN正确地预测为非垃圾)
- 邮件为垃圾,系统错误识别为非垃圾(FN错误地预测为非垃圾)
介绍了分类器的所有可能的分类情形,对于为什么不能只是用Accuracy作为唯一的判断标准还不是很明朗,我们接着分析。
上面的Confusion Matrix只是对于一封邮件而言,那么对于多封邮件的预测结果情形,TP,FP,FN,TN则是各种情形的计数结果,假如我们有100封测试邮件,其中50封为垃圾50封为非垃圾,就可能会预测出TP=40封,TN=40封,FP = 10封,FN = 10封。那么用Accuracy来衡量的话,就会得到:
从Precision-Recall到F-Measure
上一小节我们通过Accuracy Paradox说明Accuracy作为唯一指标的不足,还有Accuracy有时并不能很好地刻画Confusion Matrix所表达的内容。这一小节我们将了解信息检索领域中研究者如何对Confusion Matrix进行拆解,得到了Precision-Recall,从而对质和量得以把控,还有如何组合Precision-Recall得到一个对Confusion Matrix的一个统一解释数字。
Precision-Recall
对于信息检索问题,我们更关注搜索到的内容与用户想要搜索的内容是否相关。如果有测试数据的话,我们是希望搜索引擎返回的内容与用户要找的越相关越好,另一方面我们想让搜索引擎返回越多的相关内容越好,所以就有了Precision和Recall这两个指标。这两个指标中文翻译很多,但是很难有直观地翻译道明其中奥妙,所以这里也不尝试翻译,大家心领神会吧。但是Precision和Recall的侧重点是不一样的:
- Precision是返回的相关文献(TP)占总返回文献(TP+FP)的比例,所以Precision越大,返回的结果质量越高
- Recall是返回的相关文献(TP)占总相关文献(TP+FN)的比例,所以Recall越大,返回相关的文献就越多
一个是强调质量(返回结果只要给我相关的就好),一个是强调数量(返回相关的结果要尽可能越多越好)。按照上面的定义,我们根据Confusion Matrix可以给出Precision和Recall的数学形式:

这两个指标哪个值高更好呢?在实际应用中,必须根据具体需求设定,举个例子,对于识别是否为超市会员和非会员的系统,我们当然希望Recall越高越好,虽然这样会混进一些非会员,但是对于超市来说并非损失,就给个折扣而已,还是赚钱。但是对于一个银行的门禁系统,肯定是要Precision越高越好,Recall可以不用那么严格,这样虽然会让你打卡打多几次,但是总比把一个外人放进来安全吧。所以根据实际业务需求,在Precision和Recall上做权衡是很有必要的。有的人说,我很懒,我不想自己手工做权衡,能不能综合Precision和Recall得到一个指标呢?答案是有的。
F-Measure
对于想自动化权衡Precision和Recall的人,F Measure是他们的福音。首先介绍最简单也是最常用的合并Precision和Recall的方式—— F1meaure 或 F1score ,办法很简单,就像两个电阻并联求总电阻的形式相似,将Precision和Recall并联一下,就近似得到它们的加权平均:
Matthews Correlation Coefficient
上一节中,我们尝试利用 F1 作为Confusion Matrix的总结数字来解决Accuracy Paradox,最终以失败告终,这一节我们介绍一种可以解决这种问题的方法。
MCC详解
Matthews的原文中是这样描述这个系数的:
A correlation of:
C = 1 indicates perfect agreement,
C = 0 is expected for a prediction no better than random, and
C = -1 indicates total disagreement between prediction and observation
也就是说系数为1的时候,分类器是完美的,0的时候分类器和随机分类器没差,-1的时候分类器是最差的,所有预测结果和实际相反。那这样的系数是如何解决imbalance data问题呢?我们紧接着看他的数学形式:
MCC本质上是一个观察值和预测值之间的相关系数,维基百科上是这样评价MCC的:
While there is no perfect way of describing the confusion matrix of true and false positives and negatives by a single number, the Matthews correlation coefficient is generally regarded as being one of the best such measures
至此,我们解决了Accuracy Paradox问题,那么是不是说明我们可以只用MCC作为唯一标准呢,聪明的读者应该学会说不是了吧,Precsion和Recall可是很好地强调质和量的关系,并且能够通过F Measure体现出来,在很多情况下,用Accuracy作为指标也是一个不错的简单选择。
从ROC到AUC
本来到此就可以结束本篇的讨论了,奈何在众多Metric中还有一个备受争论的AUC,意犹未尽,再继续讨论吧。
ROC简史
维基上这样说的:
ROC曲线首先是由二战中的电子工程师和雷达工程师发明的,用来侦测战场上的敌军载具(飞机、船舰),也就是信号检测理论。之后很快就被引入了心理学来进行信号的知觉检测。数十年来,ROC分析被用于医学、无线电、生物学、犯罪心理学领域中,而且最近在机器学习(machine learning)和数据挖掘(data mining)领域也得到了很好的发展。
一开始接触ROC(Receiver Operating Characteristic)实在是不好理解为什么名字这样取,和机器学习如何挂上半毛钱关系的。了解一下他的历史就明白了,是一群电子工程师和雷达工程师发明的,他们的世界我们不懂,呵呵。
详解ROC曲线
我们之前讨论的几个评价指标,都是围绕Confusion Matrix做的一些数学上的形式总结,ROC则另辟蹊径,试图从图上直观地刻画,网上有一个视频教程ROC curves and Area Under the Curve explained,很直观形象地介绍了ROC曲线的作图过程。还有一篇可读性极高的论文An introduction to ROC analysis非常详细直观地介绍ROC和AUC。这里我不希冀能够更直观地讲解ROC曲线的作图过程,但是还是尽我所能讲清楚。
首先ROC是一个二维曲线,那么对于二维曲线我们必须建立一个坐标系,对于ROC,他的纵坐标是TPR(True Positive Rate),横坐标是FPR(False Positive Rate)。好,既然提到Rate了,那么对于整个测试集才有Rate的说法。回顾我们的老朋友Confusion Matrix,来看看TPR和FPR是如何定义。这里先看一幅来自An introduction to ROC analysis上面的一幅图:
我们可以知道:

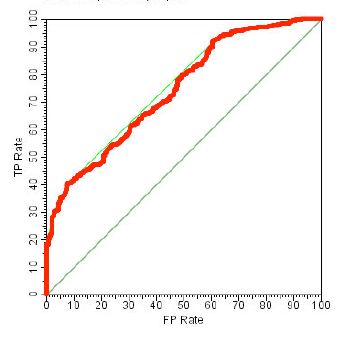
如果 θ 取得越小,测试样本越多,折线就会越趋向平滑。一般来说,对于好的分类器,ROC曲线会越偏向左上角(对应于(0,1)点,此时FPR=0,TPR=1代表完美的分类器),而越靠近对角线,分类器越趋向于随机分类器,更多动态展示,请参考 ROC curves and Area Under the Curve explained。也就是说,对于同一份测试集,图下分类器

一般要优于:
所代表的分类器,而该分类器一般又优于:
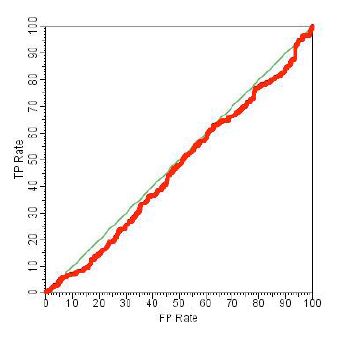
所代表的几乎随机的分类器。
所有迹象表明,ROC曲线包围的面积越大,分类器表现越好,那么我们是否可以利用ROC下面包围的面积大小来做为一种评判方式呢?答案自然是可以的,于是AUC便上场了。
AUC(Area Under Curve)
一开始接触AUC,如果没有什么预备知识,完全摸不着头脑,曲线下面的面积,居然是可以作为分类器的一种评判指标!然而事实就是如此,ROC曲线下面的面积,作为分类器的评判标准被广泛应用。至于如何用梯形法逼近计算面积,在An introduction to ROC analysis中有详细说明,此处不表。我们重点来讨论AUC作为评判标准到底应该如何理解。在An introduction to ROC analysis一文中,AUC是这样直观解释的:
the AUC of a classifier is equivalent to the probability that the classifier will rank a randomly chosen positive instance higher than a randomly chosen negative instance
这句话翻译过来是说,分类器的AUC相当于一个概率,一个什么样的概率呢?一个对于随机抽取的正样本和负样本,分类器会给出一个分数,使得正样本排名在负样本之前的概率。那么如果AUC越大,那么这个概率就越大,那么分类器能区分正负样本的能力就越强。好,这应该可以理解,但是有一个地方比较微妙,为什么说AUC相当于这样一个概率呢?An introduction to ROC analysis文中并没有解释。如果搞不清这一点,我们很难直观理解AUC。
好,接下来我们尝试揭开这层蒙纱。首先我们考虑概率的定义,对于任意一个合格的概率 p ,必须满足:
现在我们考虑实际情况下的作图过程,首先我们将所有测试样例进行评分并按照评分排序后,此时对于一个样本 a ,他的评分为为 score(a) ,将其作为threshold也就是 θ=score(a) ,可以得到
接下来我们不管面积问题了,我们来做一个概率问题,考虑这样的事件E:对于随机抽取的正样本和负样本,分类器会给出一个分数,使得正样本排名在负样本之前。我们假设一个Negative样本为 a ,他的评分为为 score(a) ,Positive 样本为 b ,他的评分为 score(b) ,那么对于事件A的概率,可以如下求取:
如果假设FPR服从0-1的均匀分布,此时可得
参考文献
- More on ROC/AUC
- An introduction to ROC analysis
- Wiki MCC
- Wiki ROC
- The Relationship Between Precision-Recall and ROC Curves