[机器学习实战] 阅读第五章
文章目录
- 支持向量机
- 1 线性SVM分类
- 1.1 软件隔分类
- - numpy.array.astype()
- 1.2 使SVM分类器输出类别概率的方法
- 方法一:SVC类 ,kernel(核心)参数
- 方法二:SGDClassifier类
- 2 非线性SVM分类
- 2.1 为数据集添加多项式特征的方法
- 方法一:搭建流水线
- *方法二:多项式核 核技巧(SVC类中实现)
- 网格搜索使用技巧
- 2.2 添加相似特征
- 2.2.1 *高斯径向基函数(RBF) RBF核
- 公式5-1:高斯RBF
- 选择地标的方法
- 高斯 RBF 核函数
- 超参数gamma()
- 字符串核
- 2.2.2 核函数的选择技巧
- 3 计算复杂度
- 3.1 LinearSVC的复杂度
- 3.2 SVC的复杂度
- 4 SVM回归
- 4.1 工作原理
- 决策函数和预测
- 公式5-2:线性SVM分类器预测
- 4.2 训练目标
- 公式5-3:硬间隔线性SVM分类器的目标
- *超参数C的原理:
- 公式5-4:软间隔线性SVM分类器目标
- 4.3 二次规划
- 公式5-5:二次规划问题
- 4.4 对偶问题
支持向量机
功能强大并且全面的机器学习模型,能够执行线性或非线性分类、回归,甚至是异常值检测任务。
适用于中小型复杂数据的分类
1 线性SVM分类
可将SVM分类器视为在类别之间拟合可能的最宽的街道,因此又被称为(large margin classification)
注意:在街道(虚线)以外的地方增加更多训练实例,不会对决策边界产生影响:也就是说它完全由位于街道边缘的实例所决定(或者称之为“支持”)。这些实例被称为支持向量(虚线上的实例)。
![[机器学习实战] 阅读第五章_第1张图片](http://img.e-com-net.com/image/info8/7f2896d650134a4fbb2559de216bc12d.jpg)
SVM对特征缩放非常敏感。
1.1 软件隔分类
如果严格地让所有实例都不在街道上,并且位于正确地一边,这就是硬间隔分类。
硬间隔分类地两个主要问题,首先,它只在数据是线性可分离地时候才有效;其次,它对异常值非常敏感。
要避免这些问题,最好使用更灵活地模型。目标是尽可能在保持街道宽阔和限制间隔违例(即位于街道之上,甚至在错误地一边地实例)之间找到良好地平衡,这就是软件隔分类。
在scikit-learn地SVM类中,可以通过超参数C来控制这个平衡:C值越小,则街道越宽,但是间隔违例也会越多。
街道宽度大一些地模型地泛化效果可能会更好。
如果你的SVM模型过度拟合,可以试试通过降低C来进行正则化。
- numpy.array.astype()
copy数据集生成一个新副本,在这个副本中,数据类型被转换成指定地类型。
1.2 使SVM分类器输出类别概率的方法
与Logistic回归分类器不同的是,SVM分类器不会输出每个类别的概率。
方法一:SVC类 ,kernel(核心)参数
或者,可以选择SVC类,使用SVC(kernel="linear",C=1)但是这要慢得多,特别是对于大型训练集而言,因此不推荐使用。
方法二:SGDClassifier类
使用SGDClassifier(loss=“hinge”,alpha=1/(m*C))。这适用于常规随机梯度下降(参见第4章)来训练线性SVM分类器。它不会像LinearSVC类那样快速收敛,但是对于内存处理不了的大型数据集
(核外训练)或是在线分类任务,它非常有效。
2 非线性SVM分类
处理非线性数据集的方法之一是添加更多特征,比如多项式特征,在某些情况下,这可能导致数据集变得线性可分离。
2.1 为数据集添加多项式特征的方法
方法一:搭建流水线
1、一个PolynomialFeatures转换器
2、接着一个StandardScaler转换器
3、然后是LinearSVC估算器
from sklearn.datasets import make_moons
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import PolynomialFeatures
polynomial_svm_clf = Pipeline((
("poly_features", PolynomialFeatures(degree=3)),
("scaler", StandardScaler()),
("svm_clf", LinearSVC(C=10, loss="hinge"))
))
polynomial_svm_clf.fit(X, y)
*方法二:多项式核 核技巧(SVC类中实现)
添加多项式特征实现起来非常简单,并且对所有机器学习(不只是SVM)都非常有效。但问题是,如果多项式太低阶,处理不了非常复杂的数据集,而高级则会创造出大量的特征,导致模型变慢。
幸运的是,在SVM中,有一个魔术般的数学技巧可以应用,这就是核技巧。它产生的结果就跟添加了许多多项式特征,甚至是非常高阶的多项式特征一样,但实际上并不需要真的添加。因为实际没有添加任何特征,所以也就不存在数量爆炸的组合特征了。这个技巧由SVC类来实现。
from sklearn.svm import SVC
poly_kernel_svm_clf = Pipeline((
("scaler", StandardScaler()),
("svm_clf", SVC(kernel="poly", degree=3, coef0=1, C=5))
))
poly_kernel_svm_clf.fit(X, y)
参数:degree,多项式的阶数。
参数:coef0,控制模型受多项式还是低阶多项式影响的程度。
网格搜索使用技巧
先进行一次粗略的网格搜索,然后在最好的值附近展开一轮更精细的网格搜索,这样通常会快一些。
2.2 添加相似特征
解决非线性问题的另一种方法
这些特征经过相似函数计算得出,相似函数可以测量没个实例与一个特定地标(landmark)之间的相似度。
2.2.1 *高斯径向基函数(RBF) RBF核
公式5-1:高斯RBF
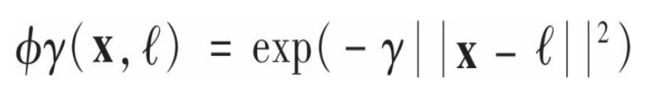
这是一个从0(离地标差得非常远)到1(跟地标一样)变化的钟形函数。
选择地标的方法
最简单的方法是在数据集里每一个实例的位置上创建一个地标。这会创建出许多维度,因而也增加了转换后的训练集可分离的机会。缺点是,一个有m个实例n个特征的训练集会被转换成一个m个实例m个特征的训练集(假设抛弃了原始特征)。如果训练集非常大,那就会得到同样大数量的特征。
高斯 RBF 核函数
要计算出所有附加特征,其计算代价可能非常昂贵,尤其是对大型训练集来说。然而,核技巧再一次施展了它的SVM魔术:它能够产生的结果就跟添加了许多相似特征一样,但实际上也并不需要添加。
我猜测,这些相似特征或是多项式特征应当是根据核函数计算出来的,在用的时候调用,用完即回收,这样就不会占据内存空间和过多的计算资源。
超参数gamma()
增加gamma值,模型更易受到单个实例的影响
就像一个正则化的超参数:模型过度拟合,就降低它的值,如果拟合不足则提升它的值(类似超参数C)。
字符串核
常用于文本文档或是DNA序列(如使用字符串子序列核或是基于莱文斯坦距离的核函数)的分类。
2.2.2 核函数的选择技巧
经验法则:永远从线性核函数开始尝试(要记住,LinearSVC比SVC(kernel=“linear”)快得多),特别是训练集非常大或特征非常多的时候。如果训练集不太大,你可以试试高斯RBF核,大多数情况下它都非常好用。如果你还有多余的时间和计算能力,你可以使用交叉验证和网格搜索来尝试一些其他的和函数,特别是那些专门针对你的数据集数据结构的核函数。
3 计算复杂度
3.1 LinearSVC的复杂度
liblinear库为线性SVM实现了一个优化算法,LinearSVC正是基于该库的。这个算法不支持核技巧,不过它与训练实例的数量和特征数量几乎呈线性相关:其训练时间复杂度大致为O(m×n)。
如果你想要非常高的精度,算法需要的时间更长。它由容差超参数ε(在Scikit-Learn中为tol)来控制。大多数分类任务中,默认的容差就够了。
3.2 SVC的复杂度
SVC则是基于libsvm库的,这个库的算法支持核技巧。[2]训练时间复杂度通常在O(m2×n)和O(m3×n)之间。很不幸,这意味着如果训练实例的数量变大(例如上十万个实例),它将会慢得可怕,所以这个算法完美适用于复杂但是中小型的训练集。但是,它还是可以良好适应地特征数量的增加,特别是应对稀疏特征(即,每个实例仅有少量的非零特征)。在这种情况下,算法复杂度大致与实例的平均非零特征数成比例。
4 SVM回归
SVM算法非常全面:它不仅支持线性和非线性分类,而且还支持线性和非线性回归。诀窍在于将目标反转一下:不再是尝试拟合两个类别之间可能的最宽的街道的同时限制间隔违例,SVM回归要做的是让尽可能多的实例位于街道上,同时限制间隔违例(也就是不在街道上的实例)。街道的宽度由超参数ε控制。
在间隔内添加更多的实例不会影响模型的预测,所以这个模型被称为ε不敏感。
要解决非线性回归任务,可以使用核化的SVM模型。
4.1 工作原理
符号约定:
偏置项表示为b,特征权重向量表示为w,同时输入特征向量中不添加偏置特征。
决策函数和预测
线性SVM分类器通过简单地计算决策函数wT·x+b=w1x1+…+wnxn+b来预测新实例x的分类。如果结果为正,则预测类别是正类(1),不然则预测其为负类(0),见公式5-2。
公式5-2:线性SVM分类器预测
![[机器学习实战] 阅读第五章_第2张图片](http://img.e-com-net.com/image/info8/e7373e11b4b44bc08bbd7ee7ae11600f.jpg)
训练线性SVM分类器即意味着找到w和b的值,从而使这个间隔尽可能宽的同时,避免(硬间隔)或是限制(软间隔)间隔违例。
4.2 训练目标
![[机器学习实战] 阅读第五章_第3张图片](http://img.e-com-net.com/image/info8/363afbcd75fe468e83e917577bb06343.jpg)
公式5-3:硬间隔线性SVM分类器的目标
![[机器学习实战] 阅读第五章_第4张图片](http://img.e-com-net.com/image/info8/7d070a3717d64c4b935291e5652d82b3.jpg)
*超参数C的原理:
![[机器学习实战] 阅读第五章_第5张图片](http://img.e-com-net.com/image/info8/85326233a4844b50bb2ecf1b4ae7f5e1.jpg)
公式5-4:软间隔线性SVM分类器目标
![[机器学习实战] 阅读第五章_第6张图片](http://img.e-com-net.com/image/info8/04bac50100564331bda9077c926d7343.jpg)
4.3 二次规划
硬间隔和软间隔问题都属于线性约束的凸二次优化问题。这类问题被称为二次规划(QP)问题。要解决二次规划问题有很多现成的求解器,使用到的技术各不相同,这些不在本书的讨论范围之内。公式5-5给出的是问题的一般形式。
公式5-5:二次规划问题
![[机器学习实战] 阅读第五章_第7张图片](http://img.e-com-net.com/image/info8/f094afa7ae6541b0a05194395a6d164b.jpg)