Java面经总结
线程安全
1.什么是不安全?
1.1 不同线程,对同一资源的访问或修改。
1.2 原子性 JVM规范定义了线程对主存的操作指令:read,load,use,assign,store,write
1.3 可见性------------------------------------------------volatile,final,synchronized,
1.4 有序性-------------read-load,从主存加载数据到线程自己的工作内存中,即保留一个副本,assign,修改之后, 变量副本会同步到主存储区(store- write),何时同步不一定,导致最后在内存中的值不是想象中的。
2.为什么会产生?
1. CPU高速缓存
2、主内存
3.如何避免?
1.强同步:synchronized 关键字。 当一段代码会修改共享变量,这一段代码成为互斥区或临界区,用synchronized标识起来,共享对象作为锁,否则没有意义。
每个锁对象都有两个队列,一个是就绪队列,一个是阻塞队列,就绪队列存储了将要获得锁的线程,阻塞队列存储了被阻塞的线程,当一个被线程被唤醒 (notify)后,才会进入到就绪队列,等待cpu的调度
一个线程执行临界区代码过程如下:
1 获得同步锁
2 清空工作内存
3 从主存拷贝变量副本到工作内存
4 对这些变量计算
5 将变量从工作内存写回到主存
6 释放锁
2.生产者/消费者模式
lock.wait -----释放锁,
lock.notify ----通知lock中阻塞队列里面的某个线程,进入就绪队列。
lcok.notifyAll ---通知所有阻塞队列里的线程。
3.volitle
对变量修改回写到内存,相当于 (store- write)
防止指令重排
4.共享对象不可变
5.原子操作,原子类,底层CAS实现,但是会导致缓存一致性流量,bus风暴,性能降低
MESI协议实现,
底层实现:
1.read,load,assign,use,store,write (底层原子操作)
2.lock,unlock.开放api给用户用,字节码为monitorenter,monitorexit (Syncronized 关键字的底层)
其实是对象头,包含一个锁的位置:
对象头:
http://blog.csdn.net/hsuxu/article/details/9472371

包含,锁的升级,可升不可降
各种锁:
1. ReentrantLock
在同步竞争不激烈时用synchronized,激烈时用ReentrantLock
ReentrantLock提供了lockInterruptibly()方法可以优先考虑响应中断,而不是像synchronized那样不响应interrupt()操作
同一个线程,持有锁,可以重新获取该锁,即重进入,避免了死锁,内部实现有一个计数器和一个标志位,标志占有的线程。
需要手动释放锁
2.synchronized + 内部锁,或叫互斥锁,会阻塞或等待,直到获取锁,无法重进入,产生死锁
+static 类锁
3.公平锁,非公平锁
公平锁是指多个线程在等待同一个锁时,必须按照申请锁的先后顺序来一次获得锁。
4.自旋锁
线程执行一个忙循环(自旋),等待其他线程释放锁。
5.其他

并发工具
一.CountDownLatch用法
await()
await(long timeout,TimeUnit unit)
countDown();
二.CyclicBarrier用法
await()
await(long timeout,TimeUnit unit)
第一个版本比较常用,用来挂起当前线程,直至所有线程都到达barrier状态再同时执行后续任务;
第二个版本是让这些线程等待至一定的时间,如果还有线程没有到达barrier状态就直接让到达barrier的线程执行后续任务。
三.Semaphore用法
1
2
3
4
public void acquire() throws InterruptedException { } //获取一个许可
public void acquire(int permits) throws InterruptedException { } //获取permits个许可
public void release() { } //释放一个许可
public void release(int permits) { } //释放permits个许可
控制资源能够被多少线程访问,类似于锁。
class 加载
双亲委派模型的工作流程是:如果一个类加载器收到了类加载的请求,它首先不会自己去尝试加载这个类,而是把请求委托给父加载器去完成,依次向上,因此,所有的类加载请求最终都应该被传递到顶层的启动类加载器中,只有当父加载器在它的搜索范围中没有找到所需的类时,即无法完成该加载,子加载器才会尝试自己去加载该类。
c++——-> bootstrap classloader ———->extension classloader —-> application classloader ——–>selfdefined classloader
垃圾回收

1. new Object --> eden , if not enough ---> YoungGC(Minor GC)
2. Survivor Mem not enough ---> YoungGC(Major GC : Old Generation)
3. Old Generation Mem not enough ---> Full GC (Old: CMS)
引用算法:
引用分类:强,软,弱,虚
1.引用计数, 存在循环引用
2.可达性分析算法,即判断一个对象能否到达GC-roots,GC-roots:
虚拟机栈(栈帧中的本地变量表)中引用的对象。
方法区中类静态属性引用的对象。
方法区中常量引用的对象。
本地方法栈中JNI(即一般说的Native方法)引用的对象。
垃圾收集算法:
1.标记-清除 ,直接清除当前位置。
2.复制算法 即复制到另一半,然后回收另一半,一块大eden区,两块小survivor区,将eden区中存活的复制到一块空的survivor区,清理eden和第一个survivor
3.标记-整理,然所有存活对象移动到另一端,清除另一端。
4.分代收集
5.hot-spot的实现:
各个收集器。采用不同的垃圾收集算法
5.1 serial 收集器,单线程,新生代收集器,标记-整理
5.2 ParNew,多线程的serial。
5.3 Parallel Scavenge,新生代,复制算法。
5.4 serial-old
5.5 ParalleOld
5.6 CMS,很短暂的停顿。不会stop the world,标记-清除
eden----> survivor--->old---->perm
年龄,大对象,往后放6.G1收集器,牛逼,即 将jvm的堆区,划分为大小相等的region,remembered Set (referrence counting)
分为以下4各阶段:
初始标记(GCroots)
并发标记
最终标记
筛选回收1 .分代收集:仍然有分代的概念,不需要其他收集器配合,独立管理整个GC堆。
2 .空间整合:从整体看,是基于“标记-整理”算法实现的,从局部(两个Region之间)看是基于“复 制”算法的。在运行期间不会产生内存碎片。
3 .可预测的停顿:G1跟踪各个Region里垃圾堆积值的价值大小,维护一个优先级队列,每次根据允许 的时间,优先回收价值最大的Region。(这也是Garbage First的由来)虚拟机GC参数设置
http://unixboy.iteye.com/blog/174173
-Xms
-Xmx JVM 最大内存
-Xmn 年轻代大小
-XX:SuvirorRatio=8 eden:survivor = 8:1
-XX:PretenureSizeThreshold 设置大对象阈值,超过,则直接分配到老年代 只对 parnew 和Serail 收集器有效
-XX:MaxPretenuringThreshold 设置晋升old的阈值 即age的max
-XX:+UseParNewGC:
-XX:+UseG1GC
eden --> survivor age:1
minor GC, age ++
if age >= 15 ----> Old Generation
Class:

1.Magic Num :0xCAFFEBABE
2.constant_pool :
1. literal
2. reference name
底层进阶:
线程实现
1.使用内核线程实现(KLT)。由内核分配,内核Scheduler调度。 但一般用LWP(轻量级进程),即KLT的一种接口。(user mode ,kernel mode切换消耗资源)

2.使用用户线程实现

3.LWP和用户线程混合
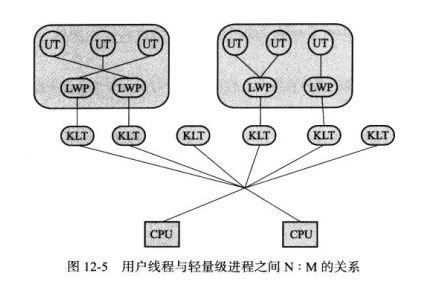
SunJdk中用LWP(win,linux)
线程调度(java,抢占式)

常见集合原理源码
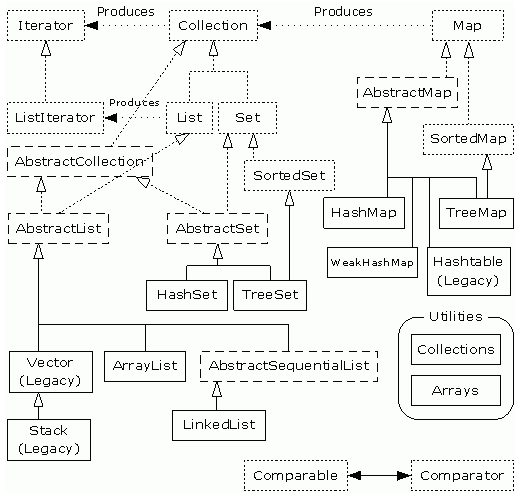
Map系: HashMap,LinkedHashMap,TreeMap, WeakHashMap, EnumMap,ConcurrentHashMap
List系:ArrayList, LinkedList, Vector, Stack
Set系:HashSet, LinkedHashSet, TreeSet