【目标检测】YOLOv3: An Incremental Improvement
PASCAL VOC 数据集:https://blog.csdn.net/baidu_27643275/article/details/82754902
yolov1阅读笔记:https://blog.csdn.net/baidu_27643275/article/details/82789212
yolov1源码解析:https://blog.csdn.net/baidu_27643275/article/details/82794559
yolov2阅读笔记:https://blog.csdn.net/baidu_27643275/article/details/82859273
YOLOv2–k_means方法:
https://blog.csdn.net/baidu_27643275/article/details/88673185
yolo_weights_convert:https://blog.csdn.net/baidu_27643275/article/details/83189124
yolov3源码:https://github.com/1273545169/object-detection/tree/master/yolo_v3
目标检测论文集:
https://blog.csdn.net/u013066730/article/details/82460392
yolov3在yolov2基础上主要做了两大改进:FPN和ResNet,性能极佳。
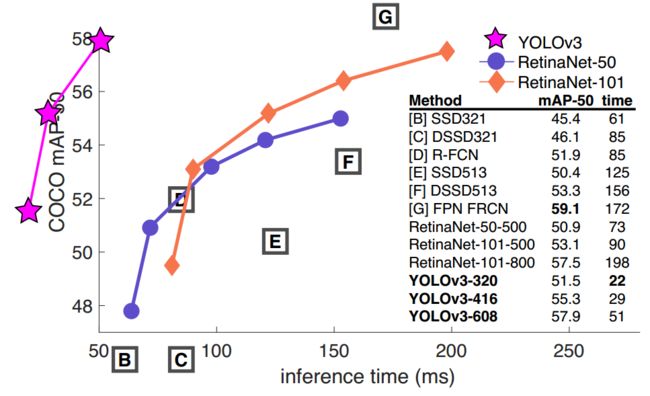
yolov3改进策略:
1、Class Prediciton
用Sigmoid代替Softmax,这个改进主要是用于多标签分类。Softmax可以用于多分类问题,但是类别之间必须互斥,也就是一个目标只有一个标签。但实际应用中,标签可能重叠(如:人和女人),一个物体有多个标签。所以使用Sigmoid代替,训练时loss函数使用binary cross-entropy loss
2、Feature Extractor
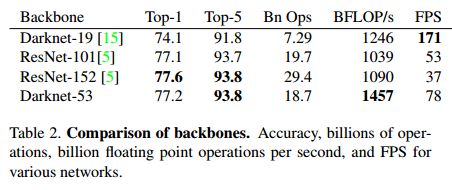
(1)yolov3使用darknet-53来提取特征,网络中使用3×3和1×1的卷积以及residual块;
(2)darknet-53中没有pooling层,而是用步长为2的卷积层代替,避免了信息丢失;
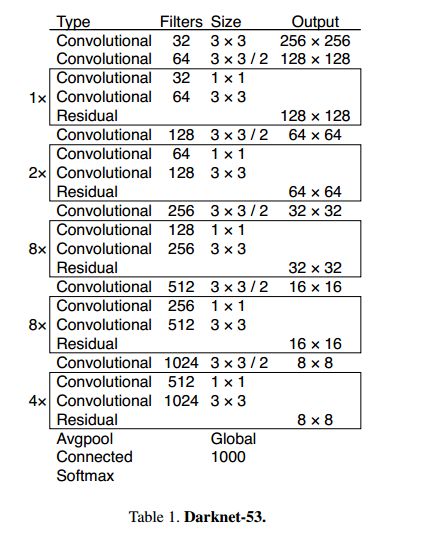
(3)网络有53层,深度增加,网络的非线性增强,可以处理更多更丰富的空间特征,增加特征多样性。
 。
。
3、Prediction Across Scales
(1)检测网络部分,作者参考了FPN(feature pyramid networks)的思想。用非线性插值方法上采样了两次,获得了3个不同大小的feature maps,每个feature map预测3个anchor boxes。
(2) 由深层、语义特征丰富的负责预测大物体(分配大anchor);浅层、几何特征丰富的负责预测小物体(分配小anchor)。
(3)yolov3在小物体识别上性能很好,可是在大物体和中等物体上性能相对较差。
(就目前来说这种策略对检测小物体已经做到头了,想要再改进,可能要换思路了,如果一味地增大输入尺寸显然是不合理的)
4、Detection Network
YOLOv3在三个不同分辨率的feature map上运行检测网络,最后得到scale1、scale2、scale3三个检测结果。
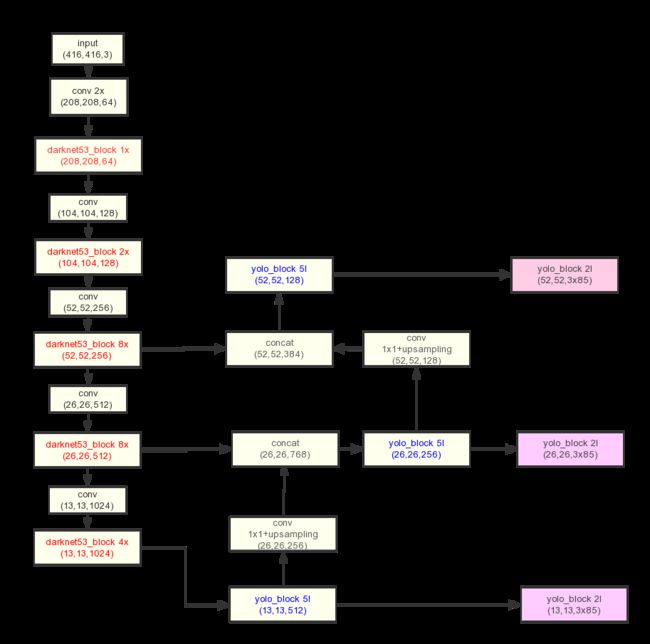
The 13 x 13 layer is responsible for detecting large objects, whereas the 52 x 52 layer detects the smaller objects, with the 26 x 26 layer detecting medium objects.
scale1、scale2、scale3可能对某一个目标都进行了预测,某个目标有多个预测框。在test中,通过运行nms可对预测框进行筛选,最后一个目标只有一个预测框。
5、yolo3 的tensorflow实现:
yolo3实现推荐阅读:Implementing YOLO v3 in Tensorflow (TF-Slim)
darknet53中resdual block的实现
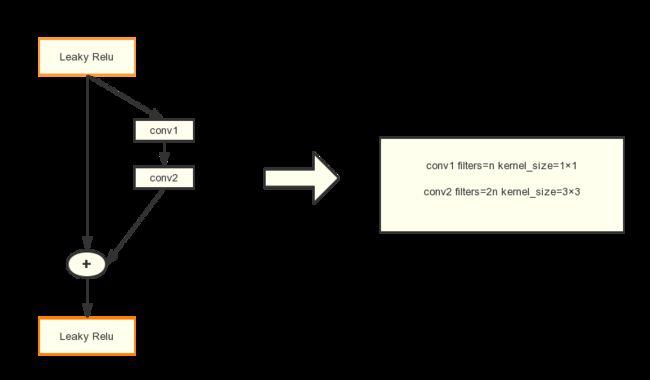
def _darknet53_block(inputs, filters):
shortcut = inputs
inputs = _conv2d_fixed_padding(inputs, filters, 1)
inputs = _conv2d_fixed_padding(inputs, filters * 2, 3)
inputs = inputs + shortcut
return inputs
darknet53的实现
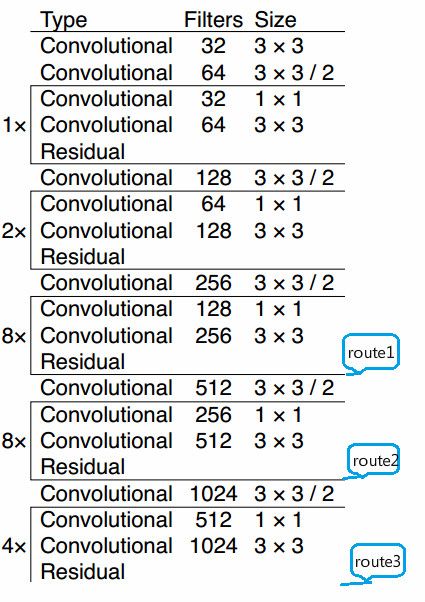
def darknet53(inputs):
"""
Builds Darknet-53 model.
"""
inputs = _conv2d_fixed_padding(inputs, 32, 3)
inputs = _conv2d_fixed_padding(inputs, 64, 3, strides=2)
inputs = _darknet53_block(inputs, 32)
inputs = _conv2d_fixed_padding(inputs, 128, 3, strides=2)
for i in range(2):
inputs = _darknet53_block(inputs, 64)
inputs = _conv2d_fixed_padding(inputs, 256, 3, strides=2)
for i in range(8):
inputs = _darknet53_block(inputs, 128)
route_1 = inputs
inputs = _conv2d_fixed_padding(inputs, 512, 3, strides=2)
for i in range(8):
inputs = _darknet53_block(inputs, 256)
route_2 = inputs
inputs = _conv2d_fixed_padding(inputs, 1024, 3, strides=2)
for i in range(4):
inputs = _darknet53_block(inputs, 512)
return route_1, route_2, route_3
检测网络的实现
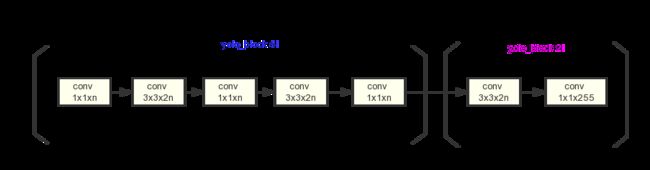
def _yolo_block(inputs, filters, num_classes):
inputs = _conv2d_fixed_padding(inputs, filters, 1)
inputs = _conv2d_fixed_padding(inputs, filters * 2, 3)
inputs = _conv2d_fixed_padding(inputs, filters, 1)
inputs = _conv2d_fixed_padding(inputs, filters * 2, 3)
inputs = _conv2d_fixed_padding(inputs, filters, 1)
route = inputs
inputs = _conv2d_fixed_padding(inputs, filters * 2, 3)
scale = slim.conv2d(inputs, 3 * (5 + num_classes), 1, stride=1, normalizer_fn=None,
activation_fn=None, biases_initializer=tf.zeros_initializer())
return route, scale
def yolo_v3(inputs, num_classes, is_training=False, data_format='NHWC', reuse=False):
"""
Creates YOLO v3 model.
:param inputs: a 4-D tensor of size [batch_size, height, width, channels].
Dimension batch_size may be undefined. The channel order is RGB.
:param num_classes: number of predicted classes.
:param is_training: whether is training or not.
:param data_format: data format NCHW or NHWC.
:param reuse: whether or not the network and its variables should be reused.
:return:
"""
# set batch norm params
batch_norm_params = {
'decay': _BATCH_NORM_DECAY,
'epsilon': _BATCH_NORM_EPSILON,
'scale': True,
'is_training': is_training,
'fused': None, # Use fused batch norm if possible.
}
# Set activation_fn and parameters for conv2d, batch_norm.
with slim.arg_scope([slim.conv2d, slim.batch_norm, _fixed_padding], reuse=reuse):
with slim.arg_scope([slim.conv2d], normalizer_fn=slim.batch_norm, normalizer_params=batch_norm_params,
biases_initializer=None, activation_fn=lambda x: tf.nn.leaky_relu(x, alpha=_LEAKY_RELU)):
with tf.variable_scope('darknet-53'):
route_1, route_2, inputs = darknet53(inputs)
with tf.variable_scope('yolo-v3'):
# feature map1 大目标,大anchor
route, scale1 = _yolo_block(inputs, 512, num_classes)
# feature map2 中目标,中anchor
inputs = _conv2d_fixed_padding(route, 256, 1)
upsample_size = route_2.get_shape().as_list()
inputs = _upsample(inputs, upsample_size)
inputs = tf.concat([inputs, route_2], axis=-1)
route, scale2 = _yolo_block(inputs, 256, num_classes)
# feature map3 小目标,小anchor
inputs = _conv2d_fixed_padding(route, 128, 1)
upsample_size = route_1.get_shape().as_list()
inputs = _upsample(inputs, upsample_size)
inputs = tf.concat([inputs, route_1], axis=-1)
_, scale3 = _yolo_block(inputs, 128, num_classes)
scale = [scale1, scale2, scale3]
return scale
网络完整实现如下:
# -*- coding: utf-8 -*-
import numpy as np
import tensorflow as tf
from tensorflow.contrib import slim
from yolo3.config import _ANCHORS
_BATCH_NORM_DECAY = 0.9
_BATCH_NORM_EPSILON = 1e-05
_LEAKY_RELU = 0.1
def darknet53(inputs):
"""
Builds Darknet-53 model.
"""
inputs = _conv2d_fixed_padding(inputs, 32, 3)
inputs = _conv2d_fixed_padding(inputs, 64, 3, strides=2)
inputs = _darknet53_block(inputs, 32)
inputs = _conv2d_fixed_padding(inputs, 128, 3, strides=2)
for i in range(2):
inputs = _darknet53_block(inputs, 64)
inputs = _conv2d_fixed_padding(inputs, 256, 3, strides=2)
for i in range(8):
inputs = _darknet53_block(inputs, 128)
route_1 = inputs
inputs = _conv2d_fixed_padding(inputs, 512, 3, strides=2)
for i in range(8):
inputs = _darknet53_block(inputs, 256)
route_2 = inputs
inputs = _conv2d_fixed_padding(inputs, 1024, 3, strides=2)
for i in range(4):
inputs = _darknet53_block(inputs, 512)
return route_1, route_2, inputs
def _conv2d_fixed_padding(inputs, filters, kernel_size, strides=1):
if strides > 1:
# # we just need to pad with one pixel, so we set kernel_size = 3
# inputs = tf.pad(inputs, [[0, 0], [0, 2],
# [0, 2], [0, 0]])
inputs = _fixed_padding(inputs, kernel_size)
inputs = slim.conv2d(inputs, filters, kernel_size, stride=strides, padding=('SAME' if strides == 1 else 'VALID'))
return inputs
def _darknet53_block(inputs, filters):
shortcut = inputs
inputs = _conv2d_fixed_padding(inputs, filters, 1)
inputs = _conv2d_fixed_padding(inputs, filters * 2, 3)
inputs = inputs + shortcut
return inputs
@tf.contrib.framework.add_arg_scope
def _fixed_padding(inputs, kernel_size, *args, mode='CONSTANT', **kwargs):
"""
Pads the input along the spatial dimensions independently of input size.
Args:
inputs: A tensor of size [batch, channels, height_in, width_in] or
[batch, height_in, width_in, channels] depending on data_format.
kernel_size: The kernel to be used in the conv2d or max_pool2d operation.
Should be a positive integer.
data_format: The input format ('NHWC' or 'NCHW').
mode: The mode for tf.pad.
Returns:
A tensor with the same format as the input with the data either intact
(if kernel_size == 1) or padded (if kernel_size > 1).
"""
pad_total = kernel_size - 1
pad_beg = pad_total // 2
pad_end = pad_total - pad_beg
padded_inputs = tf.pad(inputs, [[0, 0], [pad_beg, pad_end],
[pad_beg, pad_end], [0, 0]])
return padded_inputs
def _yolo_block(inputs, filters, num_classes):
inputs = _conv2d_fixed_padding(inputs, filters, 1)
inputs = _conv2d_fixed_padding(inputs, filters * 2, 3)
inputs = _conv2d_fixed_padding(inputs, filters, 1)
inputs = _conv2d_fixed_padding(inputs, filters * 2, 3)
inputs = _conv2d_fixed_padding(inputs, filters, 1)
route = inputs
inputs = _conv2d_fixed_padding(inputs, filters * 2, 3)
scale = slim.conv2d(inputs, 3 * (5 + num_classes), 1, stride=1, normalizer_fn=None,
activation_fn=None, biases_initializer=tf.zeros_initializer())
return route, scale
# 采用最近邻插值算法进行上采样
def _upsample(inputs, out_shape):
inputs = tf.image.resize_nearest_neighbor(inputs, (out_shape[1], out_shape[2]))
inputs = tf.identity(inputs, name='upsampled')
return inputs
def yolo_v3(inputs, num_classes, is_training=False, data_format='NHWC', reuse=False):
"""
Creates YOLO v3 model.
:param inputs: a 4-D tensor of size [batch_size, height, width, channels].
Dimension batch_size may be undefined. The channel order is RGB.
:param num_classes: number of predicted classes.
:param is_training: whether is training or not.
:param data_format: data format NCHW or NHWC.
:param reuse: whether or not the network and its variables should be reused.
:return:
"""
# set batch norm params
batch_norm_params = {
'decay': _BATCH_NORM_DECAY,
'epsilon': _BATCH_NORM_EPSILON,
'scale': True,
'is_training': is_training,
'fused': None, # Use fused batch norm if possible.
}
# Set activation_fn and parameters for conv2d, batch_norm.
with slim.arg_scope([slim.conv2d, slim.batch_norm, _fixed_padding], reuse=reuse):
with slim.arg_scope([slim.conv2d], normalizer_fn=slim.batch_norm, normalizer_params=batch_norm_params,
biases_initializer=None, activation_fn=lambda x: tf.nn.leaky_relu(x, alpha=_LEAKY_RELU)):
with tf.variable_scope('darknet-53'):
route_1, route_2, inputs = darknet53(inputs)
with tf.variable_scope('yolo-v3'):
# feature map1 大目标,大anchor
route, scale1 = _yolo_block(inputs, 512, num_classes)
# feature map2 中目标,中anchor
inputs = _conv2d_fixed_padding(route, 256, 1)
upsample_size = route_2.get_shape().as_list()
inputs = _upsample(inputs, upsample_size)
inputs = tf.concat([inputs, route_2], axis=-1)
route, scale2 = _yolo_block(inputs, 256, num_classes)
# feature map3 小目标,小anchor
inputs = _conv2d_fixed_padding(route, 128, 1)
upsample_size = route_1.get_shape().as_list()
inputs = _upsample(inputs, upsample_size)
inputs = tf.concat([inputs, route_1], axis=-1)
_, scale3 = _yolo_block(inputs, 128, num_classes)
scale = [scale1, scale2, scale3]
return scale
总结
network in network 引入global average pooling代替全连接层
Fully Convolutional Networks for Semantic Segmentation
(1)把卷积层->全连接层看成卷积层->卷积层
(2)全连接层->全连接层看成1×1卷积层->1×1卷积层
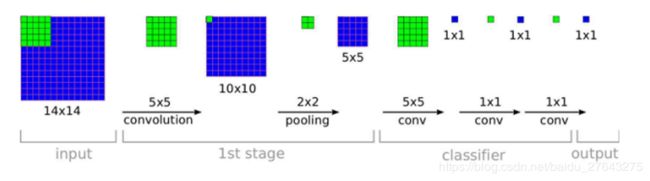
趋势: 全连接层和池化层逐渐被卷积层代替
在yolo系列中充分体现了上述趋势:
yolov1使用卷积层、池化层、全连接层
yolov2使用卷积层和池化层。全连接层被卷积层代替(最后输出部分是3×3卷积+1×1卷积)
yolov3中只有卷积层。池化层被卷积层(3×3的卷积,stride=2)代替。
参考:
https://towardsdatascience.com/yolo-v3-object-detection-53fb7d3bfe6b
https://itnext.io/implementing-yolo-v3-in-tensorflow-tf-slim-c3c55ff59dbe
https://github.com/maiminh1996/YOLOv3-tensorflow