论文阅读笔记:Adversarial Cross-Modal Retrivieval
文章来源:ACM MM2017
0.Pre-work
- 要解决什么问题:
现有的基于DNN的跨模态检索仅仅关注于保持配对的跨模态数据集的成对相似性,这些数据共享语义标签并且在模型学习的过程中充当输入,然而一个模态的一项数据可能存在多个语义不同的项,所以仅仅关注成对样本是远远不够的 - 用什么方法解决?
提出了一种基于对抗训练的跨模态搜索ACMR( Adversarial Cross-Modal Retriviel), Adversarial learning 是两个阶段相互作用的结果,首先,特征提取,试图在公共子空间中生成一个模态不变的表示,并模糊另一个阶段,模态分类——依据生成表示区分不同的模态;
论文进一步对特征提取施加三重约束,以最大限度地缩小来自具有相同语义标签的不同模态的所有项目的表示之间的差距,同时最大限度地扩大不同语义的图像和文本之间的距离。以此保留了底层的跨模态语义结构,确保所学习的表示在模态内是有区别的,在模态之间是不变的 - 达到了什么样的效果?
提出的ACMR方法在4个基准数据集上(3个小规模和一个相对大规模)进行了评估,并使用许多现有方法作为参考。实验结果表明,该算法在多模态检索方面的性能明显优于现有的多模态检索算法 - 存在什么问题?
1.方法
1.1问题设定
在不失一般性的情况下,我们针对双模态的跨模态表示学习:
假定有n个image-text对的实例,表示为: O = { o i } i = 1 n O= \{o_i\}_{i=1}^n O={oi}i=1n, o i = { v i , t i } o_i=\{v_i,t_i\} oi={vi,ti},vi的特征尺寸为dv ,是图像的特征向量,ti的特征尺寸是dt,是文本的特征向量,二者的特征尺寸不一样,此外,每一个oi实例分配一个语义标签向量yi= [yi1,yi2, …,yic] ∈Rc, c是语义类别的总数,假如第i个实例和第j个语义匹配,那么yij=1,否则yij=0;
Note:oi既可以属于单个语义类别也可以属于多个语义类别
我们将在实例中的所有图像特征矩阵、文本特征矩阵和标签矩阵,表示为
V = { v 1 , . . . , v n } ∈ R d v × n \mathcal{V} = \{v_1, ...,v_n\} \in \mathbb{R}^{d_v \times n} V={v1,...,vn}∈Rdv×n
T = t 1 , . . . , t n ∈ R d t × n \mathcal{T} = {t_1, ...,t_n} \in \mathbb{R}^{d_t \times n} T=t1,...,tn∈Rdt×n
Y = y 1 , . . . , y n ∈ R c × n \mathcal{Y} = {y_1, ...,y_n} \in \mathbb{R}^{c \times n} Y=y1,...,yn∈Rc×n
因为文本和图像具有典型的异构性和未知分布(或复杂分布),不能直接比较而用于跨模态搜索,为了使文本和图像可以直接比较,我们把文本和图像共同映射到一个共同子空间 S \mathcal{S} S,并记为 S V = f V ( V ; θ V ) \mathcal{S}_\mathcal{V}=f_\mathcal{V}(\mathcal{V};\theta_\mathcal{V}) SV=fV(V;θV) 和 S T = f T ( T ; θ T ) \mathcal{S}_\mathcal{T}=f_\mathcal{T}(\mathcal{T};\theta_\mathcal{T}) ST=fT(T;θT)
f V f_\mathcal{V} fV和 f V f_\mathcal{V} fV表示映射到子空间的映射函数, S V ∈ R m × n \mathcal{S}_\mathcal{V} \in \mathbb{R}^{m \times n} SV∈Rm×n和 S T ∈ R m × n \mathcal{S}_\mathcal{T} \in \mathbb{R}^{m \times n} ST∈Rm×n分别是图像到文本的变换特征
具体的说,论文所用的ACMR方法目的就是在不同的模态中学习 S \mathcal{S} S中更有效的变换特征 S V \mathcal{S}_\mathcal{V} SV和 S T \mathcal{S}_\mathcal{T} ST,我们要求 S V \mathcal{S}_\mathcal{V} SV和 S T \mathcal{S}_\mathcal{T} ST是modality-invariant 和 semantically discriminative的,但也要更好的保持数据中潜在的跨模态相似结构
1.2 Adversarial Cross-Modal Retrieval
ACMR的大致架构如下图:

论文假定已经分别从图像和文本中提取到了 V \mathcal{V} V和 T \mathcal{T} T
1.3 Modality Classify
论文要求学习出的 S V \mathcal{S}_\mathcal{V} SV和 S T \mathcal{S}_\mathcal{T} ST是在Common Subspace,也就是说希望两者有identical distribution(同分布),那就意味着要让以后的模型无法分辨出输入是Image还是Text,明显这很符合对抗训练的应用,这也就是上图中Modality Classifier所要做的,MC与Feature Projector之间形成了一个Adversary的关系,MC需要尽可能的分辨出Input是Image还是Text,如果最后MC分辨不出来了,那么就证明FP将Image和Text学习到了同一空间(中间还有其他的约束)。即,MC充当了GAN的判别器,在论文中,MC的Loss定义如下:

1.4 Feature Projector
在先前的交叉熵损失的计算中,目的仅仅是为了保证在一个子空间内各个语义配对的跨模态项的成对相关性,这还远远不够,因为正如前述,语义匹配的可能不止两项。
此外这个相关性损失不能很好的区别相同模态语义上不同的项,论文提出了一种新的FP模型,可以展现文本和图像madal-invariant映射到共同子空间的过程,分为两个部分,分别解决上面所说的两个问题:
- Label Prediction::Semantically-discriminative
- Structure Preservation: Cross-modal Similarity
Label prediction的目的在于使映射出的不同语义(Semantic)的Subspace特征可以彼此区分;Structure preservation使要确保相同语义的跨模态的Subspace特征要保持一致(modal-invariant),从下图可以体会出两者的作用和区别(每一个圆圈代表一个图像;每一个矩形代表一个文本项目;相同颜色的圆形和矩形属于相同的语义类别):
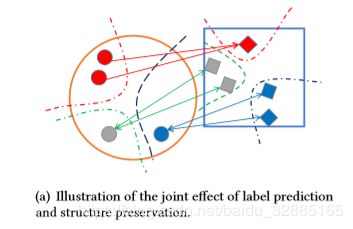

Label prediction为了解决intra-madal discriminative的问题,其损失为:

Structure Preservation:为了确保inner-madal invariant,我们希望最小化来自不同模态的所有语义相似项表示之间的差距,并且增大同模态下语义不同的项的距离,受到基于排名的跨模态检索方法的启发,论文通过制定以此为目的的triplet loss来加强嵌入子空间过程中的triplet过程,论文倾向从每一个小标记实例中进行三重采样而不是采用在整个实例空间上进行。
首先,从图像和文本的角度上看,所有来自不同模态但是具有相同标签的都被构建成coupled samples;换句话说,我们建立了 { ( v i , t i + ) } \{(v_i,t_i^+)\} {(vi,ti+)}这样的成对形式,以image作为anchor,具有相同标签的文本就作为一个正匹配, 同时建立了 { ( t i , v i + ) } \{(t_i,v_i^+)\} {(ti,vi+)}这样的成对形式,以text作为anchor,具有相同标签的image就作为一个正匹配。
其次,所有coupled 项对的映射表示 f V ( V ; θ V ) f_\mathcal{V}(\mathcal{V};\theta_\mathcal{V}) fV(V;θV) 和 f T ( T ; θ T ) f_\mathcal{T}(\mathcal{T};\theta_\mathcal{T}) fT(T;θT)的距离都采用 L 2 \mathcal{L}_2 L2番薯;
![]()
然后,我们从具有不同语义标签的不匹配image-text对中选择负样本,以构建每个语义标签 l i l_i li的triplet samples: { ( v i , t i + , t j − ) } \{(v_i,t_i^+,t_j^-)\} {(vi,ti+,tj−)}和 { ( v i , t i + , t j − ) } \{(v_i,t_i^+,t_j^-)\} {(vi,ti+,tj−)}
最后,我们计算交叉了image和text的inter-modal invariance loss, 分别以样本集 { ( v i , t i + , t j − ) } \{(v_i,t_i^+,t_j^-)\} {(vi,ti+,tj−)}和 { ( v i , t i + , t j − ) } \{(v_i,t_i^+,t_j^-)\} {(vi,ti+,tj−)}作为输入:


然后,整体的inter-madal invariance loss可以用 L i m i , V ( θ V , θ T ) \mathcal{L}_{imi, \mathcal{V}}(\theta_\mathcal{V},\theta_\mathcal{T}) Limi,V(θV,θT)和 L i m i , T ( θ V , θ T ) \mathcal{L}_{imi, \mathcal{T}}(\theta_\mathcal{V},\theta_\mathcal{T}) Limi,T(θV,θT)组合起来计算;
![]()
另外,论文引入了正则化项来防止训练的学习参数过拟合:
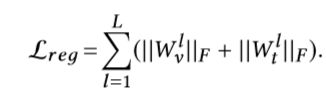
所以,FP(feature projector)的损失函数(论文中称为embedding loss)是inter-modal invariance loss和 intra-modal discrimination loss以及正则化项的组合

其中超参数 α \alpha α和 β \beta β控制两个项在总损失中所占的权重
1.5 对抗训练


2、测试
论文采用了四个数据集,前三个数据集每一个image-text对都链接了单一的一个标签,且text模态由离散的tags组成,最后一个数据集每一个image-text对都链接了多个标签,且text模态由句子组成,以下是四个数据集的比对:

2.1 实现细节
- 部署了以tanh为激活函数的三层前馈神经网络来将原始的图像和文本投射到一个共同的子空间
- 对于Modality classify ,采用三个全连接层,此外,在语义分类器和MP上采用Softmax激活。
- b a t c h s i z e = 64 , k = 5 , λ = 0.05 batchsize = 64, k = 5 ,\lambda=0.05 batchsize=64,k=5,λ=0.05,使用grid search调整 α \alpha α和 β \beta β
2.2 对比其他方法


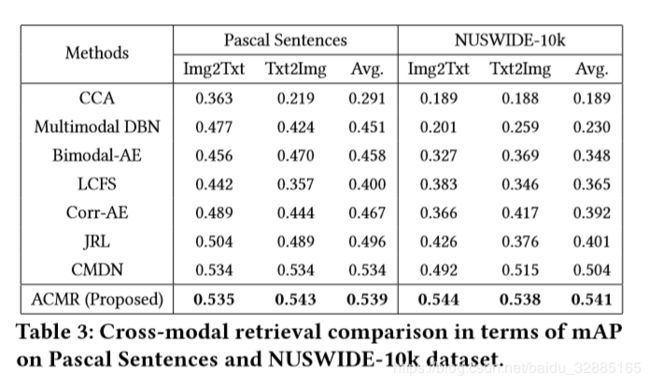

2.3 深入分析
可视化对抗学习、模型参数以及采用Label Prediction 和 Structure Preservation的组合对检索效果的影响.




算法的基本流程:基于极大-极小的对抗机制,其中包含两个算法模块,其一是模态分类器,用来区分目标的模态,另一是特征生成器,用来生成能够适应不同模态的特征表达,以迷惑模态分类器。通过这两个模块的相互对抗,提高网络的综合性能。
参考
原文:Adversarial Cross-Modal Retrivieval
知乎上关于此篇论文的笔记
CSDN:跨模态理解与检索