Python中小知识点汇总(常期更新)
容易出错的几个点:编码问题、在使用函数时需要特别注意有没有返回值、在遍历list或dict等数据结构时,没有迭代。
1.a、a+、r+、w+区别
https://blog.csdn.net/ztf312/article/details/47259805
w新建只写,w+新建读写,二者都会将文件内容清零
(以w方式打开,不能读出。w+可读写)
w+与r+区别:
r+:可读可写,若文件不存在,报错;w+: 可读可写,若文件不存在,创建
(a:附加写方式打开,不可读;a+: 附加读写方式打开)
2. python 中的main
https://www.cnblogs.com/lvxiuquan/archive/2012/07/09/2582437.html
3.sys.stdout.flush() 刷新输出
https://blog.csdn.net/qq_20603001/article/details/62887099
可以用在网络程序中多线程程序,多个线程后台运行,同时要能在屏幕上实时看到输出信息。
4.异常相关的介绍
http://www.runoob.com/python/python-exceptions.html
5.logging模块
https://www.jianshu.com/p/feb86c06c4f4
6.Python 中得到当前日期的前|后几天

7. 字符串格式化
http://www.cnblogs.com/vamei/archive/2013/03/12/2954938.html (传统的%s之类的方法)
https://www.cnblogs.com/benric/p/4965224.html(使用{}.format()的方法超酷的)
8.列表的extend方法
http://www.runoob.com/python/att-list-extend.html
extend() 函数用于在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表)。
列表的reverse方法,用于反向列表中元素。
http://www.runoob.com/python/att-list-reverse.html
9.类class中_init_函数以及参数self
https://blog.csdn.net/LY_ysys629/article/details/54893185
10.文件I/O系统
http://www.runoob.com/python/python-files-io.html
11.编码和解码
https://www.cnblogs.com/linjiqin/p/3674825.html

很多莫名其妙的问题,最后都是编码问题,所以首先check编码和解码。
12. time 和 datetime的区别和联系
http://gracece.com/2014/10/the-distinction-between-date-and-datetime-in-python/
http://www.wklken.me/posts/2015/03/03/python-base-datetime.html#datetime-timetuple
13.python2.7中的urllib和urllib2的学习
https://www.cnblogs.com/wly923/archive/2013/05/07/3057122.html
http://zhuoqiang.me/python-urllib2-usage.html
常用的就是 urllib2.urlopen(url, timeout=100)
14. 在使用urllib2.urlopen(url).read()时没有设置超时时间,导致不返回结果,程序卡死了。
解决方法:设置retry
参考:https://www.168seo.cn/python/23889.html
timeout中的时间单位为秒。

第二种要安装retry库,亲测没有第一种好用:
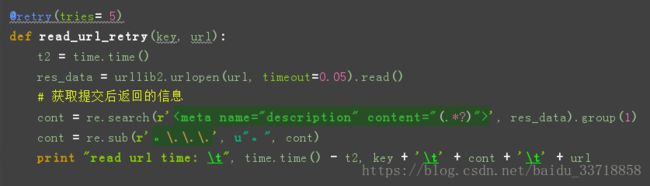
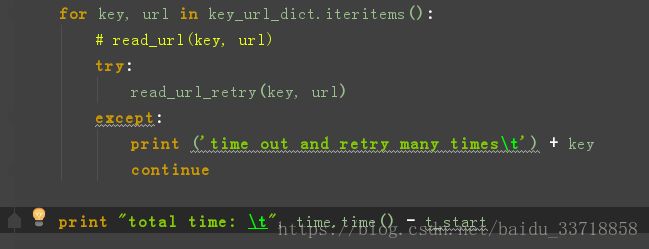
15. python 下产生md5
MD5的全称是Message-Digest Algorithm 5(信息-摘要算法)。128位长度。目前MD5是一种不可逆算法。
具有很高的安全性。它对应任何字符串都可以加密成一段唯一的固定长度的代码。
http://www.cnblogs.com/the4king/archive/2012/02/06/2340660.html (这篇文章讲了md5和sha1,并讲了用python中的内置的hashlib模块来实现md5和sha1算法)
http://outofmemory.cn/code-snippet/939/python-liangzhong-produce-md5-method (生成md5的两种方法,推荐第二种)


16.xmltodict, xml的解析
可以将xml变成一个类似于json的格式,非常方便,使用Demo如下:
https://pythonguidecn.readthedocs.io/zh/latest/scenarios/xml.html

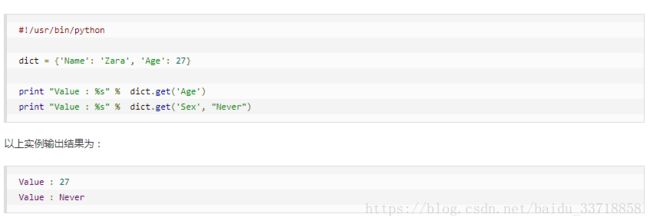
17.dict的get()方法
Python 字典(Dictionary) get() 函数返回指定键的值,如果值不在字典中返回默认值。Demo来自菜鸟。
18.Python中re的match、search、findall、finditer区别
https://blog.csdn.net/djskl/article/details/44357389
19.dict 和collections.defaultdict的异同
https://juejin.im/post/5b0d7f795188251597548e7c (这篇讲字典和集合讲得很好)
这里的defaultdict(function_factory)构建的是一个类似dictionary的对象,其中keys的值,自行确定赋值,但是values的类型,是function_factory的类实例,而且具有默认值。比如default(int)则创建一个类似dictionary对象,里面任何的values都是int的实例,而且就算是一个不存在的key, d[key] 也有一个默认值,这个默认值是int()的默认值0.
https://blog.csdn.net/kyi_zhu123/article/details/80203118 (讲了dict 和collections.defaultdict的区别)
简单来说,如果get dict中的不存在的key,会报错,但是get defaultdict中不存在的key,会返回默认值。
20.顺便说一下xml、html等的区别
老看到这些概念,今天把他们搞清楚。一般xml是可以自己定义schema,然后将schema告诉相关方,让他们写数据或者读数据的。
https://www.jianshu.com/p/5f5ebefd0cbe (写得比较有意思)
https://www.jianshu.com/p/e7fafe21028d(写得很清晰)


21.OrderedDict的用法
实现了对字典对象中元素的排序。
https://blog.csdn.net/u013066730/article/details/58120817 (这个博客介绍得非常清楚了)
同样是保存了ABC三个元素,但是使用OrderedDict会根据放入元素的先后顺序进行排序。由于进行了排序,所以OrderedDict对象的字典对象,如果其顺序不同那么Python也会把他们当做是两个不同的对象。
22.list 和str 的相互转换
https://blog.csdn.net/roytao2/article/details/53433373 (重点使用了list转str的,亲测有效)

如果list为[],使用",".join(list)打印的结果也为空,len为0。
23.dict 和str转换,针对dict中有中文的str转换,变成json格式。
https://blog.csdn.net/lluozh2015/article/details/75092877
24. os.path 模块使用
https://www.cnblogs.com/wuxie1989/p/5623435.html (详见此博客,很清晰地说明了常见的几个函数)




25.input()和raw_input()的区别,input()调用了raw_input()来实现,raw_input()读入的是字符串,input()读入的是将字符串str当成有效的表达式来求值并返回计算结果。
raw_input()在做笔试题读输入时经常用到。做笔试题的时候先写接口,再写实现函数,不然如果时间来不及会很尴尬。
https://www.cnblogs.com/pizitai/p/6476362.html (这篇博客特别详细的写了raw_input()和input()的区别,并详细说明了如何读入各种形式的数据)
https://www.cnblogs.com/dadadechengzi/p/6149930.html (现在用到的不多,没有仔细看,之后再看)
这篇博客写了eval的一些使用方法,eval就是将字符串当成有效的表达式来求值并返回计算结果。因为input()函数的代码为:
def input(prompt):
return (eval(raw_input(prompt)))
26.字符串分割方法,split()函数。路径分割方法,os.path.split()函数。
https://www.cnblogs.com/hjhsysu/p/5700347.html (这篇博客挺细致的讲了这两个split)
split()返回的是一个list,可以通过索引取指定的分割后的字符串。
str.split(str="",num=string.count(str))[n]
num:表示分割次数。如果存在参数num,则仅分隔成 num+1 个子字符串,并且每一个子字符串可以赋给新的变量
[n]:表示选取第n个分片。
os.path.split():按照路径将文件名和路径分割开,如果给定的是个目录,则会返回目录和空文件名。
27.Python中的运算符
python算数运算符包括:+、-、*、**、/、//、%
| +: 加法运算 -: 减法运算 *: 乘法运算 **: 幂运算 /: 除法运算(如果有小数则返回结果为小数,如果都为整数则返回结果为整数) //: 整除,取整数部分 %: 取余 |
28.内建函数,sorted()
https://www.cnblogs.com/brad1994/p/6697196.html (讲了sorted函数对一维和多维数据排序的方法)
主要的区别在于,list.sort()是对已经存在的列表进行操作,进而可以改变进行操作的列表。而内建函数sorted返回的是一个新的list,而不是在原来的基础上进行的操作。
29. map 函数
30. zip函数
31. python 中的not关键字
https://blog.csdn.net/Evan123mg/article/details/50174669
在python中not是逻辑判断词,用于布尔型True和False,not True为False,not False为True,以下是几个常用的not的用法:
(1) not与逻辑判断句if连用,代表not后面的表达式为False的时候,执行冒号后面的语句。
(2) 判断元素是否在列表或者字典中,if a not in b,a是元素,b是列表或字典,这句话的意思是如果a不在列表b中,那么就执行冒号后面的语句
not x 意思相当于 if x is false, then True, else False
代码中经常会有变量是否为None的判断,有三种主要的写法:
第一种是`if x is None`;
第二种是 `if not x:`;
第三种是`if not x is None`(这句这样理解更清晰`if not (x is None)`) 。
在python中 None, False, 空字符串"", 0, 空列表[], 空字典{}, 空元组()都相当于False 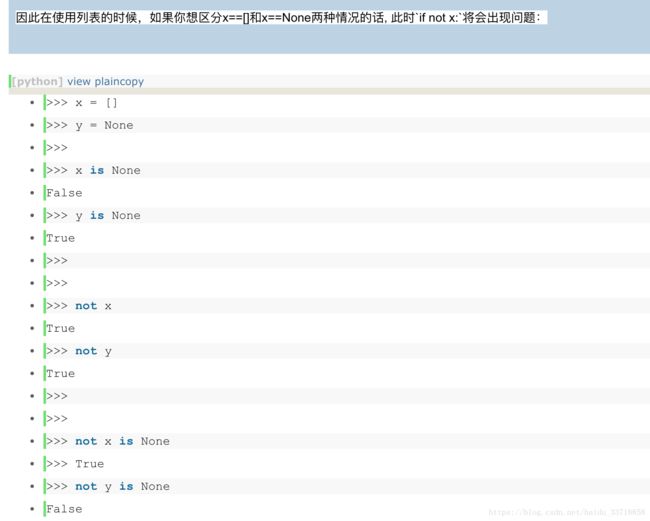
也许你是想判断x是否为None,但是却把`x==[]`的情况也判断进来了,此种情况下将无法区分。 对于习惯于使用if not x这种写法的pythoner,必须清楚x等于None, False, 空字符串"", 0, 空列表[], 空字典{}, 空元组()时对你的判断没有影响才行。 而对于`if x is not None`和`if not x is None`写法,很明显前者更清晰,而后者有可能使读者误解为`if (not x) is None`,因此推荐前者,同时这也是谷歌推荐的风格 。
32.round(x [,n])函数
round() 方法返回浮点数x的四舍五入值。
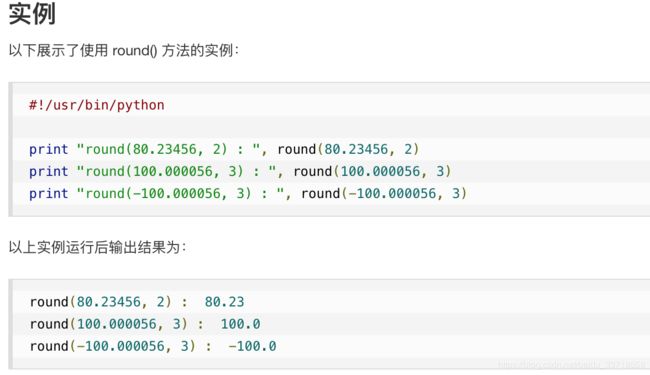
32. 解决UnicodeDecodeError: ‘ascii’ codec can’t decode byte 0xe5 in position 108: ordinal not in range(128)
https://blog.csdn.net/mindmb/article/details/7898528
import sys
reload(sys)
sys.setdefaultencoding('utf8')33. time strftime()方法
import time
run_date = time.strftime("%Y%m%d%H")
run_date
输出:
'2019072216'
34. 控制台运行py脚本时, python xxx.py 1>out.txt 2>err.log
(0-> stdin, 1->stdout, 2->stderr)