聚类 Cluster
聚类算法评价指标
聚类性能度量可以分为两类:
- 一类是将聚类结果与某个“参考模型”进行比较,称为“外部指标”(external index)
- 一类是直接考察聚类结果而不利用任何参考模型,称为“内部指标”(internal index)
对于
外部指标
对数据集 D = { x 1 , x 2 , . . . , x m } D=\{x_1,x_2,...,x_m\} D={x1,x2,...,xm},假定通过聚类算法将样本局为 C = { C 1 , C 2 , . . . C k } C=\{C_1,C_2,...C_k\} C={C1,C2,...Ck},将参考模型给出的簇划分为 C ∗ = { C 1 ∗ , C 2 ∗ , . . . , C S ∗ } C_*=\{C_1^*,C_2^*,...,C_S^*\} C∗={C1∗,C2∗,...,CS∗}。
相应的,另 λ \lambda λ与 λ ∗ \lambda^* λ∗分别表示与 C C C和 C ∗ C^* C∗对应的簇标记向量。将样本两两配对考虑,有如下定义: a = ∣ S 1 ∣ , S 1 = { ( x i , x j ) ∣ λ i = λ j , λ i ∗ = λ j ∗ , i < j } a=|S_1|,S_1=\{(x_i,x_j)|\lambda_i=\lambda_j,\lambda_i^*=\lambda_j^*,i<j\} a=∣S1∣,S1={(xi,xj)∣λi=λj,λi∗=λj∗,i<j} b = ∣ S 2 ∣ , S 2 = { ( x i , x j ) ∣ λ i = λ j , λ i ∗ ≠ λ j ∗ , i < j } b=|S_2|,S_2=\{(x_i,x_j)|\lambda_i=\lambda_j,\lambda_i^*\neq\lambda_j^*,i<j\} b=∣S2∣,S2={(xi,xj)∣λi=λj,λi∗̸=λj∗,i<j} c = ∣ S 3 ∣ , S 3 = { ( x i , x j ) ∣ λ i ≠ λ j , λ i ∗ = λ j ∗ , i < j } c=|S_3|,S_3=\{(x_i,x_j)|\lambda_i\neq\lambda_j,\lambda_i^*=\lambda_j^*,i<j\} c=∣S3∣,S3={(xi,xj)∣λi̸=λj,λi∗=λj∗,i<j} d = ∣ S 4 ∣ , S 4 = { ( x i , x j ) ∣ λ i ≠ λ j , λ i ∗ ≠ λ j ∗ , i < j } d=|S_4|,S_4=\{(x_i,x_j)|\lambda_i\neq\lambda_j,\lambda_i^*\neq\lambda_j^*,i<j\} d=∣S4∣,S4={(xi,xj)∣λi̸=λj,λi∗̸=λj∗,i<j}其中:
集合 S 1 S_1 S1表示包含了在 C C C中属于相同的簇并且在 C ∗ C^* C∗中也属于相同的簇的样本;
集合 S 2 S_2 S2表示包含了在 C C C中属于相同的簇但在 C ∗ C^* C∗中不属于相同的簇的样本;
……以此类推……
对每个样本对 ( x i , x j ) ( i < j ) (x_i,x_j)(i<j) (xi,xj)(i<j)仅能出现在一个集合中,因此有 a + b + c + d = C m 2 = m ( m − 1 ) 2 a+b+c+d=C_m^2=\frac{m(m-1)}{2} a+b+c+d=Cm2=2m(m−1)基于以上定义,对无监督聚类算法的聚类结果有如下性能度量指标:
- Jaccard系数(accard Coefficient,JCI) J C I = a a + b + c JCI=\frac{a}{a+b+c} JCI=a+b+ca所有属于同一类的样本对,同时在 C C C, C ∗ C^∗ C∗中隶属于同一类的样本对的比例。
- FM指数(Fowlkes and Mallows Index,FMI) F M I = a a + b ⋅ a a + c FMI=\sqrt{\frac{a}{a+b}·\frac{a}{a+c}} FMI=a+ba⋅a+ca在 C C C中属于同一类的样本对中,同时属于 C C C和 C ∗ C^∗ C∗的样本对的比例为 p 1 p_1 p1;在 C ∗ C^∗ C∗中属于同一类的样本对中,同时属于 C C C和 C ∗ C^* C∗的样本对的比例为 p 2 p_2 p2,FMI就是 p 1 p_1 p1和 p 2 p_2 p2的几何平均。
- Rand指数(Rand Index,RI) R I = 2 ( a + d ) m ( m − 1 ) RI=\frac{2(a+d)}{m(m-1)} RI=m(m−1)2(a+d)很显然,上述性能度量指标的取值都在 [ 0 , 1 ] [0,1] [0,1]之间,并且取值越大越好。
内部指标
对于聚类结果 C = { C 1 , C 2 , . . . , C k } C=\{C_1,C_2,...,C_k\} C={C1,C2,...,Ck},作如下定义: a v g ( C ) = 2 ∣ C ∣ ( ∣ C ∣ − 1 ) ∑ 1 ⩽ i ⩽ j ⩽ ∣ C ∣ d i s t ( x i , x j ) avg(C)=\frac{2}{|C|(|C|-1)}\sum_{1\leqslant i\leqslant j \leqslant |C|}dist(x_i,x_j) avg(C)=∣C∣(∣C∣−1)21⩽i⩽j⩽∣C∣∑dist(xi,xj) d i a m ( C ) = max 1 ⩽ i ⩽ j ⩽ ∣ C ∣ d i s t ( x i , x j ) diam(C)=\max_{1\leqslant i\leqslant j \leqslant |C|}dist(x_i,x_j) diam(C)=1⩽i⩽j⩽∣C∣maxdist(xi,xj) d m i n ( C i , C j ) = min x i ∈ C i , x j ∈ C j d i s t ( x i , x j ) d_{min}(C_i,C_j)=\min_{x_i \in C_i,x_j \in C_j}dist(x_i,x_j) dmin(Ci,Cj)=xi∈Ci,xj∈Cjmindist(xi,xj) d c e n ( C i , C j ) = d i s t ( μ i , μ j ) d_{cen}(C_i,C_j)=dist(\mu_i,\mu_j) dcen(Ci,Cj)=dist(μi,μj)其中
a v g ( C ) avg(C) avg(C)表示质心, ∣ C ∣ |C| ∣C∣表示簇内样本的个数,即 ∣ C ∣ = k |C|=k ∣C∣=k;
d i a m ( C ) diam(C) diam(C)表示簇 C C C内样本之间的最大距离;
d m i n ( C i , C j ) d_{min}(C_i,C_j) dmin(Ci,Cj)表示簇 C i C_i Ci与簇 C j C_j Cj之间的最小距离;
d i s t ( x i , x j ) dist(x_i,x_j) dist(xi,xj)用于计算两个样本之间的距离;
μ \mu μ代表簇 C C C的样本中心。
基于上述定义,得到如下考量聚类性能的内部指标:
- DB指数( Davies-Bouldin Index,DBI) D B I = 1 k max j ≠ i ( a v g ( C i ) + a v g ( C j ) d c e n ( μ i , μ j ) ) DBI=\frac{1}{k}\max_{j \neq i}(\frac{avg(C_i)+avg(C_j)}{d_{cen}(\mu_i, \mu_j)}) DBI=k1j̸=imax(dcen(μi,μj)avg(Ci)+avg(Cj))DBI的值越小越好
- Dunn指数(Dunn Index,DI) D I = min 1 ⩽ i ⩽ k { min j ≠ i ( d m i n ( C i , C j ) max 1 ⩽ l ⩽ k d i a m ( C l ) ) } DI=\min_{1\leqslant i \leqslant k}\{\min_{j \neq i}(\frac{d_{min}(C_i,C_j)}{\max_{1\leqslant l \leqslant k}diam(C_l)})\} DI=1⩽i⩽kmin{j̸=imin(max1⩽l⩽kdiam(Cl)dmin(Ci,Cj))}DI的值越大越好
距离度量
聚类算法的一个重要的度量目标是表示两个样本点之间的相似程度:距离越近,相似程度越高;距离越远,相似程度越低。
常用的距离度量方式:
- 闵可夫斯基距离;
- 欧氏距离;
- 曼哈顿距离;
- 切比雪夫距离;
- 余弦距离
其中最重要的是闵可夫斯基距离,闵可夫斯基距离是一类距离的定义。
对于 n n n维空间中的两个点 x ( x 1 , x 2 , . . . , x n ) x(x_1,x_2,...,x_n) x(x1,x2,...,xn)和 y ( y 1 , y 2 , . . . , y n ) y(y_1,y_2,...,y_n) y(y1,y2,...,yn), x x x、 y y y两点之间的闵可夫斯基距离表示为: d x y = ∑ k = 1 n ( x k − y k ) p p d_{xy}= \sqrt[p]{\sum_{k=1}^n(x_k-y_k)^p} dxy=pk=1∑n(xk−yk)p其中 p p p是一个可变参数。
- 当 p = 1 p=1 p=1时,称为 曼哈顿距离 d x y = ∑ k = 1 n ∣ x k − y k ∣ d_{xy}=\sum_{k=1}^n\vert{x_k-y_k}\vert dxy=k=1∑n∣xk−yk∣
- 当 p = 2 p=2 p=2时,称为 欧式距离 d x y = ∑ k = 1 n ( x k − y k ) 2 d_{xy}=\sqrt{\sum_{k=1}^n(x_k-y_k)^2} dxy=k=1∑n(xk−yk)2
- 当 p = ∞ p=\infty p=∞时,称为 切比雪夫距离
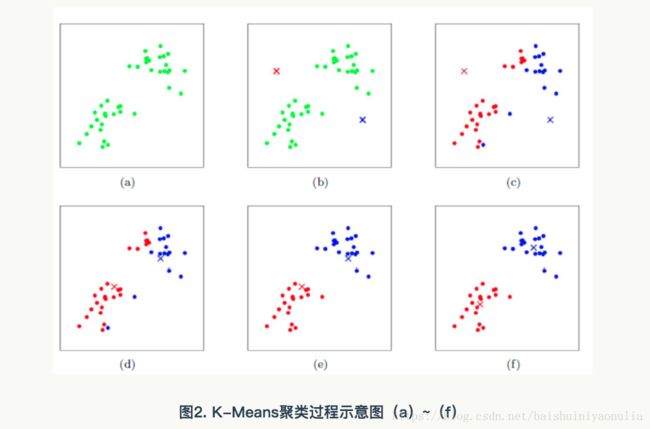
K-Means算法
对给定的样本集 D = { x 1 , x 2 , . . . , x m } D=\{x_1,x_2,...,x_m\} D={x1,x2,...,xm},k均值算法根据聚类结果划分 C = { C 1 , C 2 , . . . , C k } C=\{C_1,C_2,...,C_k\} C={C1,C2,...,Ck}
最小化平方误差: M S E = ∑ i = 1 k ∑ x ∈ C i ∣ ∣ x − u i ∣ ∣ 2 2 MSE=\sum_{i=1}^k \sum_{x \in C_i}||x-u_i||_2^2 MSE=i=1∑kx∈Ci∑∣∣x−ui∣∣22其中 u i = 1 ∣ C i ∣ ∑ x ∈ C i x u_i=\frac{1}{|C_i|}\sum_{x \in C_i}x ui=∣Ci∣1∑x∈Cix是类 C i C_i Ci的均值向量。
MSE刻画了簇类样本围绕簇均值向量的紧密程度,越小代表样本距簇均值中心越靠近。
但最优化上式的值是一个NP难的问题,因为要精确地找到它的最优解需要对样本集 D D D的所有划分情况进行一一列举。
因此,K-Means算法最终采用的是贪心的策略,通过迭代优化的方式来近似求解最优MES值。
算法流程如下:
有样本集 D = { x 1 , x 2 , . . . , x m } D=\{x_1,x_2,...,x_m\} D={x1,x2,...,xm},最终聚类的类别数 k k k,最大迭代轮数 n n n,前后两次迭代计算出的类标中心的距离 ϵ \epsilon ϵ
1、随机选择 k k k个样本点作为类标中心
2、计算每个样本点到所有类标中心点的距离;
3、将所有样本点划分到距离最近的类标中心所在的类标;
4、重新计算每个类的类标中心;
5、重复步骤2-4,直到两次迭代计算出的类标中心不发生变化或发生的变化小于 ϵ \epsilon ϵ或者达到指定的最大迭代次数 n n n。
密度聚类算法之 DBSCAN
基于密度的聚类(Density_Based Clustering)方法主要考虑的是样本分布的紧密程度,这里的紧密程度主要是用样本间的距离来衡量的。
通常情况下,密度聚类算法从样本密度的角度来考察样本之间的可连续性,并基于可连续性样本不断地扩展簇以获得最终的聚类结果。
DBSCAN是一种著名的密度聚类算法,它基于一组"领域"参数( ϵ , m p s \epsilon,mps ϵ,mps)来刻画样本分布的紧密程度。
对给定样本集 D = { x 1 , x 2 , . . . , x m } D=\{x_1,x_2,...,x_m\} D={x1,x2,...,xm}进行如下定义:
- ϵ \epsilon ϵ 领域
对于样本集 D D D中的样本点 x i x_i xi,它的 ϵ \epsilon ϵ领域定义为与 x i x_i xi距离不大于 ϵ \epsilon ϵ的样本的集合,即 N ϵ ( x i ) = { x ∈ D ∣ d i s t ( x , x i ) ⩽ ϵ } N_\epsilon(x_i)=\{x \in D|dist(x,x_i) \leqslant \epsilon\} Nϵ(xi)={x∈D∣dist(x,xi)⩽ϵ} - 核心对象
如果样本 x x x的 ϵ \epsilon ϵ领域内至少包含 m p s mps mps个样本,即 ∣ N ϵ ( x i ) ∣ ⩾ m p s |N_\epsilon(x_i)| \geqslant mps ∣Nϵ(xi)∣⩾mps则称 x x x为核心对象 - 密度直达
如果 x i x_i xi是一个核心对象,并且 x j x_j xj位于它的 ϵ \epsilon ϵ领域内
,那么我们称 x j x_j xj与 x i x_i xi密度直达 - 密度可达
对于任意两个不同的样本点 x i x_i xi与 x j x_j xj,如果存在样本序列 p 1 , p 2 , . . . p n p_1,p_2,...p_n p1,p2,...pn,其中 p 1 = x i 、 p n = x j p_1=x_i、p_n=x_j p1=xi、pn=xj,且 p i + 1 p_{i+1} pi+1由 p i , i = 1 , 2 , . . . , n − 1 p_i,i=1,2,...,n-1 pi,i=1,2,...,n−1密度直达,则称 x i x_i xi与 x j x_j xj密度可达。 - 密度相连
对于任意的两个不同样本点 x i x_i xi与 x j x_j xj,如果存在第三个样本点 x k x_k xk使得 x i x_i xi与 x j x_j xj均由 x k x_k xk密度可达,则称 x i x_i xi与 x j x_j xj密度相连。
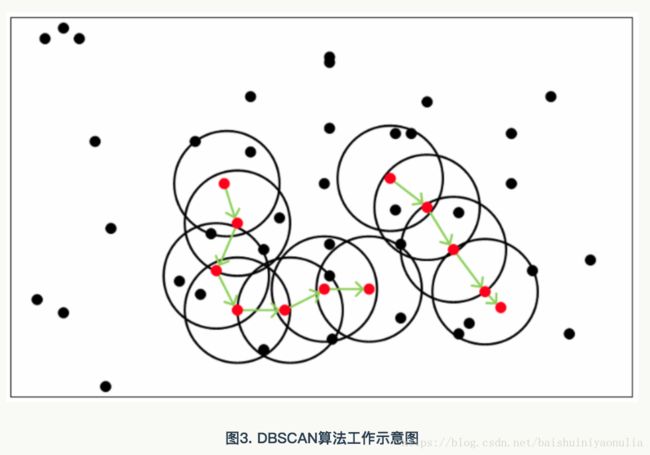
其中:
红点表示核心对象;黑色圆圈表示核心对象的 ϵ \epsilon ϵ领域;绿色箭头表示密度直达;绿色箭头的连线表示密度相连;绿色连线上任意两点都是密度可达。
基于以上概念的定义,那么DBSCAN中簇的定义就十分简单了:
由密度可达关系导出的最大密度相连的样本合集,即为我们最终聚类的一个簇。
形式化的定义如下:给定领域参数 ( ϵ , m p s ) (\epsilon, mps) (ϵ,mps),簇 C ⊆ D C \subseteq D C⊆D的非空样本子集有如下性质:
- 连接性(Connectivity)
对任意样本 x i ∈ C x_i \in C xi∈C与 x j ∈ C x_j \in C xj∈C有 x i x_i xi与 x j x_j xj密度相连; - 最大性(Maximality)
x i ∈ C x_i \in C xi∈C,且 x j x_j xj由 x i x_i xi有 z j ∈ C z_j \in C zj∈C
找出簇样本合集:
DBSCAN方法任意选择一个没有类别的核心对象作为种子(Seed),然后找到所有这个核心对象的密度可达样本集合,即为一个聚类簇。
接着继续选择另一个没有类别的核心对象去寻找密度可达的样本合集,这样就得到了另一个聚类簇。
不断循环下去,直到使用核心对象都有类别为止。
算法形式化的描述如下:

层次聚类算法之 AGNES
层次聚类(Hierarchical Clustering)是聚类算法家族中的重要的成员,它通过合并和分裂构建树状的类簇。对数据的划分主要有两种方式: 自顶向下 的分裂和 自底向上 的聚合。每棵树的根是一个聚集所有样本的独有的类。
AGNES是一种采用自底向上聚合策略的层次聚类算法。它先将数据集中的每个样本看成是一个初始的聚类簇,然后在算法运行的每一步中找出距离最近的两个簇进行合并。该过程不断重复,直至达到预设的聚类簇的个数。
因此,这里的关键又是如何计算两个聚类簇之间的距离。
关于计算两个聚类簇 C i 、 C j C_i、C_j Ci、Cj之间的距离,有如下四个定义式: d m i n ( C i , C j ) = min x i ∈ C i , x j ∈ C j d i s t ( x i , x j ) d_{min}(C_i,C_j)=\min_{x_i \in C_i,x_j \in C_j}dist(x_i,x_j) dmin(Ci,Cj)=xi∈Ci,xj∈Cjmindist(xi,xj) d m a x ( C i , C j ) = max x i ∈ C i , x j ∈ C j d i s t ( x i , x j ) d_{max}(C_i,C_j)=\max_{x_i \in C_i,x_j \in C_j}dist(x_i,x_j) dmax(Ci,Cj)=xi∈Ci,xj∈Cjmaxdist(xi,xj) d a v g ( C i , C j ) = 1 ∣ C i ∣ ∣ C j ∣ ∑ x i ∈ C i ∑ x j ∈ C j d i s t ( x i , x j ) d_{avg}(C_i,C_j)=\frac{1}{|C_i||C_j|}\sum_{x_i \in C_i}\sum_{x_j \in C_j}dist(x_i,x_j) davg(Ci,Cj)=∣Ci∣∣Cj∣1xi∈Ci∑xj∈Cj∑dist(xi,xj) d a v g ′ ( C i , C j ) = d i s t ( x i ^ , x j ^ ) , x i ^ = 1 ∣ C i ∣ ∑ k = 1 ∣ C i ∣ x k , x j ^ = 1 ∣ C j ∣ ∑ k = 1 ∣ C j ∣ x k d'_{avg}(C_i,C_j)=dist(\hat{x_i},\hat{x_j}),\hat{x_i}=\frac{1}{|C_i|}\sum_{k=1}^{|C_i|}x_k,\hat{x_j}=\frac{1}{|C_j|}\sum_{k=1}^{|C_j|}x_k davg′(Ci,Cj)=dist(xi^,xj^),xi^=∣Ci∣1k=1∑∣Ci∣xk,xj^=∣Cj∣1k=1∑∣Cj∣xk在具体的应用中,为了防止噪声点的影响,一般选择后两种距离度量方法。
AGNES聚类算法的形式化描述如下:
算法输入:
- 训练集 D = { x 1 , x 2 , . . . , x m } D=\{x_1,x_2,...,x_m\} D={x1,x2,...,xm}
- 类簇距离度量公式: d ( C i , C j ) d(C_i,C_j) d(Ci,Cj)
- 聚类簇数目: k k k
算法输出:
- 聚类结果划分: C = { C 1 , C 2 , . . . , C k } C=\{C_1,C_2,...,C_k\} C={C1,C2,...,Ck}
详细步骤:
for i = 1, 2,..., m:
C_i = {x_i}
end for
for i = 1, 2,..., m:
for j = i, i+1,..., m:
D(i, j)=d(C_i, C_j)
D(j, i)=D(i, j)
end for
end for
// 初始化当前聚类簇数目
K = m
while K > k:
find nearest class C_x C_y
C_x = C_x cap C_y // merge into C_x
for i = y+1, y+2,..., K:
C_{i-1} = C_i
end for
delete row y and col y in D
for j = 1, 2,..., K-1:
D(x, j) = d(C_x, C_j)
end for
K = K - 1
end while