计算机视觉中attention机制的理解
一、前言&简介
对于attention机制的理解,在看了attention is all you need文章和参考网上一些文章之后,做一个简单的理解和总结。
在 attention is all you need 的这篇文章中给出了在nlp中使用注意力机制的一个解决思路。文章提出,以往nlp里大量使用RNN结构和encoder-decoder结构,RNN及其衍生网络的缺点就是慢,问题在于前后隐藏状态的依赖性,无法实现并行,而文章提出的”Transformer”完全摒弃了RNN和CNN,完全依赖注意力机制,挖掘输入和输出之间的关系,这样做最大的好处是能够并行计算了,并且效果也不错。在文章的最后,作者给出了这么一段话:

作者说后面的工作会将注意力机制应用到图像,音视频方面,所以对于视觉上注意力机制的应用,我们只能参考一些论文来理解,这篇文章提出的结构我们也可以参考一下:
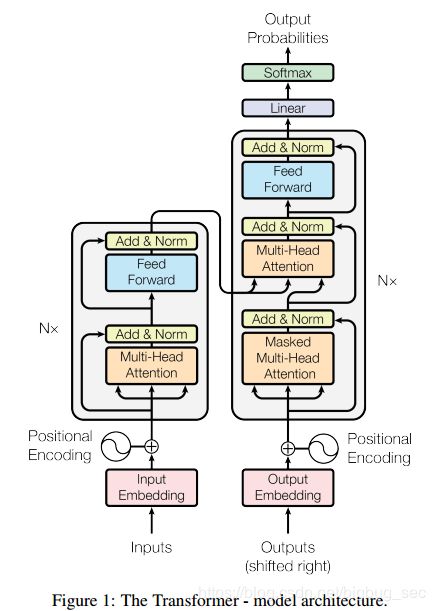
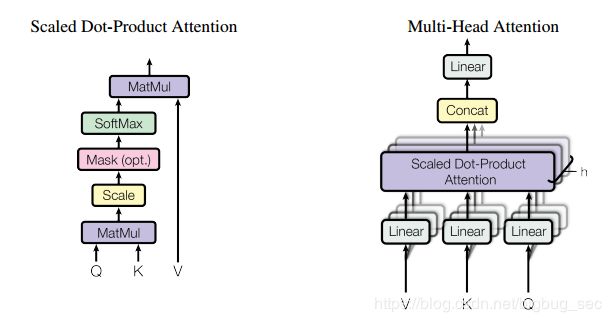
接下来说一下在计算机视觉中的注意力机制。
注意力机制(Attention Mechanism)源于对人类视觉的研究。在认知科学中,由于信息处理的瓶颈,人类会选择性地关注所有信息的一部分,同时忽略其他可见的信息。上述机制通常被称为注意力机制。人类视网膜不同的部位具有不同程度的信息处理能力,即敏锐度(Acuity),只有视网膜中央凹部位具有最强的敏锐度。为了合理利用有限的视觉信息处理资源,人类需要选择视觉区域中的特定部分,然后集中关注它。例如,人们在阅读时,通常只有少量要被读取的词会被关注和处理。综上,注意力机制主要有两个方面:
- 决定需要关注输入的哪部分。
- 分配有限的信息处理资源给重要的部分。
在计算机视觉领域,注意力机制被引入来进行视觉信息处理。注意力是一种机制,或者方法论,并没有严格的数学定义。比如,传统的局部图像特征提取、显著性检测、滑动窗口方法等都可以看作一种注意力机制。在神经网络中,注意力模块通常是一个额外的神经网络,能够硬性选择输入的某些部分,或者给输入的不同部分分配不同的权重。本文的注意力机制主要指代神经网络中的注意力机制。
二、注意力机制研究简介
2.1 简介
在深度学习发展的今天,搭建能够具备注意力机制的神经网络则开始显得更加重要,一方面是这种神经网络能够自主学习注意力机制,另一方面则是注意力机制能够反过来帮助我们去理解神经网络看到的世界。
近几年来,深度学习与视觉注意力机制结合的研究工作,大多数是集中于使用掩码(mask)来形成注意力机制。掩码的原理在于通过另一层新的权重,将图片数据中关键的特征标识出来,通过学习训练,让深度神经网络学到每一张新图片中需要关注的区域,也就形成了注意力。
2.2 分类
注意力机制可以分为四类:基于输入项的柔性注意力(Item-wise Soft Attention)、基于输入项的硬性注意力(Item-wise Hard Attention)、基于位置的柔性注意力(Location-wise Soft Attention)、基于位置的硬性注意力(Location-wise Hard Attention)。
对于基于项的注意力和基于位置的注意力,它们的输入形式是不同的。基于项的注意力的输入需要是包含明确的项的序列,或者需要额外的预处理步骤来生成包含明确的项的序列(这里的项可以是一个向量、矩阵,甚至一个特征图)。而基于位置的注意力则是针对输入为一个单独的特征图设计的,所有的目标可以通过位置指定。
总的来说,一种是软注意力(soft attention),另一种则是强注意力(hard attention)。
软注意力的关键点在于,这种注意力更关注区域或者通道,而且软注意力是确定性的注意力,学习完成后直接可以通过网络生成,最关键的地方是软注意力是可微的,这是一个非常重要的地方。可以微分的注意力就可以通过神经网络算出梯度并且前向传播和后向反馈来学习得到注意力的权重。
强注意力与软注意力不同点在于,首先强注意力是更加关注点,也就是图像中的每个点都有可能延伸出注意力,同时强注意力是一个随机的预测过程,更强调动态变化。当然,最关键是强注意力是一个不可微的注意力,训练过程往往是通过增强学习(reinforcement learning)来完成的。
2.3 模型结构简介
为了更清楚地介绍计算机视觉中的注意力机制,这篇文章将从注意力域(attention domain)的角度来分析几种注意力的实现方法。其中主要是三种注意力域,空间域(spatial domain),通道域(channel domain),混合域(mixed domain)。
还有另一种比较特殊的强注意力实现的注意力域,时间域(time domain),但是因为强注意力是使用reinforcement learning来实现的,训练起来有所不同。
(1) 空间域
设计思路:
Spatial Transformer Networks(STN)模型是15年NIPS上的文章,这篇文章通过注意力机制,将原始图片中的空间信息变换到另一个空间中并保留了关键信息。这篇文章的思想非常巧妙,因为卷积神经网络中的池化层(pooling layer)直接用一些max pooling 或者average pooling 的方法,将图片信息压缩,减少运算量提升准确率。但是这篇文章认为之前pooling的方法太过于暴力,直接将信息合并会导致关键信息无法识别出来,所以提出了一个叫空间转换器(spatial transformer)的模块,将图片中的的空间域信息做对应的空间变换,从而能将关键的信息提取出来。
(2) 通道域
设计思路:
通道域的注意力机制原理很简单,我们可以从基本的信号变换的角度去理解。信号系统分析里面,任何一个信号其实都可以写成正弦波的线性组合,经过时频变换之后,时域上连续的正弦波信号就可以用一个频率信号数值代替了。
在卷积神经网络中,每一张图片初始会由(R,G,B)三通道表示出来,之后经过不同的卷积核之后,每一个通道又会生成新的信号,比如图片特征的每个通道使用64核卷积,就会产生64个新通道的矩阵(H,W,64),H,W分别表示图片特征的高度和宽度。每个通道的特征其实就表示该图片在不同卷积核上的分量,类似于时频变换,而这里面用卷积核的卷积类似于信号做了傅里叶变换,从而能够将这个特征一个通道的信息给分解成64个卷积核上的信号分量。既然每个信号都可以被分解成核函数上的分量,产生的新的64个通道对于关键信息的贡献肯定有多有少,如果我们给每个通道上的信号都增加一个权重,来代表该通道与关键信息的相关度的话,这个权重越大,则表示相关度越高,也就是我们越需要去注意的通道了。
可参考 SENet模型结构。
(3) 混合域
了解前两种注意力域的设计思路后,简单对比一下。首先,空间域的注意力是忽略了通道域中的信息,将每个通道中的图片特征同等处理,这种做法会将空间域变换方法局限在原始图片特征提取阶段,应用在神经网络层其他层的可解释性不强。
而通道域的注意力是对一个通道内的信息直接全局平均池化,而忽略每一个通道内的局部信息,这种做法其实也是比较暴力的行为。所以结合两种思路,就可以设计出混合域的注意力机制模型
三、总结
关于模型优化,注意力机制通常由一个连接在原神经网络之后的额外的神经网络实现,整个模型仍然是端对端的,因此注意力模块能够和原模型一起同步训练。对于柔性注意力,注意力模块对其输入是可微的,所以整个模型仍可用梯度方法来优化。而硬性注意力机制要做出硬性的决定,离散地选择其输入的一部分,这样整个系统对于输入不再是可微的。所以强化学习中的一些技术被用来优化包含硬性注意力的模型。
总之,注意力机制能够帮助模型选择更好的中间特征。目前attention的套路还是很固定的,主要的关键点是如何结合具体问题,设计出你所要关心的attention结构。
参考:
- https://cloud.tencent.com/developer/news/247227
- https://zhuanlan.zhihu.com/p/32928645
- https://blog.csdn.net/yideqianfenzhiyi/article/details/79422857
- https://blog.csdn.net/bvl10101111/article/details/78470716