制作 .tfrecord文件与numpy基础知识
目录
1.numpy.ndarray.tobytes
2.存数据:tf.train.Example tf协议缓冲区
3. 用mnist数据集制作.tfrecord文件:
4. 读数据:4中Iterator
4.1 Dataset 和 Iterator 的关系
4.2 一次性水管,单次 Iterator
4.3 可以定制的水管,可初始化的 Iterator
4.4 能够接不同水池的水管,可重新初始化的 Iterator
4.5 水管的转换器,可馈送的 Iterator
5 总结
6 参考
1.numpy.ndarray.tobytes
ndarray.tobytes(order='C')
Construct Python bytes containing the raw data bytes in the array.
Constructs Python bytes showing a copy of the raw contents of data memory. The bytes object can be produced in either ‘C’ or ‘Fortran’, or ‘Any’ order (the default is ‘C’-order). ‘Any’ order means C-order unless the F_CONTIGUOUS flag in the array is set, in which case it means ‘Fortran’ order.
New in version 1.9.0.
| Parameters: | order : {‘C’, ‘F’, None}, optional Order of the data for multidimensional arrays: C, Fortran, or the same as for the original array. |
|---|---|
| Returns: | s : bytes Python bytes exhibiting a copy of a’s raw data. |
import numpy as np
x = np.array([[0, 1], [2, 3]])
s = x.tobytes()
s1 = x.tobytes('F')
print(s)
print(len(s))
print(type(s))
print('++++++')
print(s1)
print(len(s))
print(type(s1))
out:
b'\x00\x00\x00\x00\x00\x00\x00\x00\x01\x00\x00\x00\x00\x00\x00\x00\x02\x00\x00\x00\x00\x00\x00\x00\x03\x00\x00\x00\x00\x00\x00\x00'
32
++++++
b'\x00\x00\x00\x00\x00\x00\x00\x00\x02\x00\x00\x00\x00\x00\x00\x00\x01\x00\x00\x00\x00\x00\x00\x00\x03\x00\x00\x00\x00\x00\x00\x00'
32
# 由此可见,‘C’是按照行顺序即0,1,2,3转化字节数组
# ‘F'只按照列顺序即0,2,1,3转化为字节数字 2.存数据:tf.train.Example tf协议缓冲区
tf.train.Example tf协议缓冲区的定义:
message Example {
Features features = 1;
};
message Features{
map featrue = 1;
};
message Feature{
oneof kind{
BytesList bytes_list = 1;
FloatList float_list = 2;
Int64List int64_list = 3;
}
};
# Features里面就是一个 字典(或者map)
map的key必须是字符串
map的value是tf.train.Feature
#BytesList, FloatList, Int54List
例如:我们可以将图片转换为字符串进行存储,
图像对应的类别标号作为整数存储,
回归任务的ground-truth可以作为浮点数存储。
通过后面的代码我们会对tfrecord的这种字典形式有更直观的认识。 tf.train.Example的官方源码:https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/example/example.proto
3. 用mnist数据集制作.tfrecord文件:
project目录结构

import tensorflow as tf
import os
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets(train_dir='./data',one_hot=True)
import numpy as np
# 在当前路径创建一个path目录,创建‘data.tfrecords'文件
writer = tf.python_io.TFRecordWriter(os.getcwd() + os.sep + 'data' + os.sep + 'mnist.tfrecords')
for img,label in zip(mnist.train.images,mnist.train.labels):
# 转化为字节数组
img_raw = img.tobytes()
label = np.argmax(label)
example = tf.train.Example(
features=tf.train.Features(
feature={
'img':tf.train.Feature(bytes_list=tf.train.BytesList(value=[img_raw])),
'label':tf.train.Feature(int64_list=tf.train.Int64List(value=[label]))
}
)
)
writer.write(example.SerializeToString())
writer.close()3.1 解析 tf.train.Example()
import tensorflow as tf
import os
import numpy as np
from PIL import Image
# 返回解析函数
def get_record_parser():
def parse(example):
features = tf.parse_single_example(
example,features={
'img':tf.FixedLenFeature([], tf.string),
'label':tf.FixedLenFeature([], tf.int64)
}
)
image = tf.reshape(tf.decode_raw(features['img'],tf.int32),[784])
label = features['label']
return image,label
return parse
def get_batch_dataset(record_file, parser):
num_threads = tf.constant(5, dtype=tf.int32)
# num_parallel_calls用多个线程解析
# 每次shuffle的大小
# 当repeat()中没有参数,表示无限的重复数据集(训练集中有55000个样本).但repeat(2)时,相当于重复2遍数据集(即epoch=2)
# 这里选择无限重复数据集
# batch(55)表示batch_size = 55
dataset = tf.data.TFRecordDataset(record_file).map(
parser, num_parallel_calls=num_threads).shuffle(1000).repeat().batch(55)
return dataset
record_file = os.getcwd() + os.sep + 'data' + os.sep + 'mnist.tfrecords'
parser = get_record_parser()
dataset = get_batch_dataset(record_file, parser)
iterator = dataset.make_one_shot_iterator()
next_element = iterator.get_next()
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
# 由于repeat(),因此可以用100 0000
for i in range(1000000):
batch = sess.run(next_element)
if i==0:
print(len(batch))
print(type(batch))
print(len(batch[0]))
print(type(batch[0]))
print(len(batch[0][0]))
print(type(batch[0][0]))
# 将batch中的第一个样本变成图片
arr = np.reshape(batch[0][0],[28,28])
img = Image.fromarray(arr)
img.show()
print(len(batch[1]))
print(batch[1])
print("==============================")
if i % 100000 == 0 :
print(i)
out:
2
55
784
55
[3 9 3 5 2 1 2 0 6 2 7 7 9 1 3 2 6 2 0 0 6 4 6 9 6 1 4 8 3 0 5 0 9 5 7 3 4
3 4 5 4 6 8 9 7 6 9 9 6 0 7 7 4 0 5]
==============================
0
10000
20000
30000
40000
50000
60000
70000
80000
90000
![]()
从以上可以看书出:
1. 每一个batch是一个
2. 第一个元素是一个数组55×784. 第二个元素是label :55
4. 读数据:4中Iterator
首先声明以下关于Iterator的内容转载:https://blog.csdn.net/briblue/article/details/80962728
tensorflow 现在将 Dataset 作为首选的数据读取手段,而 Iterator 是 Dataset 中最重要的概念。
4.1 Dataset 和 Iterator 的关系
在文章开始之前,首先得对 Dataset 和 Iterator 有一个感性的认识。
Dataset 是数据集,Iterator 是对应的数据集迭代器。
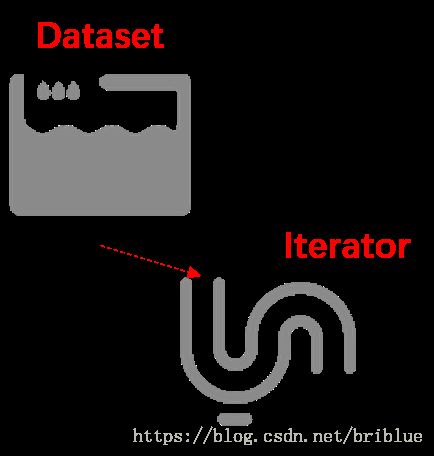
如果 Dataset 是一个水池的话,那么它其中的数据就好比是水池中的水,Iterator 你可以把它当成是一根水管。在 Tensorflow 的程序代码中,正是通过 Iterator 这根水管,才可以源源不断地从 Dataset 中取出数据。但为了应付多变的环境,水管也需要变化,Iterator 也有许多种类。
4.2 一次性水管,单次 Iterator
创建单次迭代器,非常的简单,只需要调用 Dataset 对象相应的方法。
make_one_shot_iterator()这个方法会返回一个 Iterator 对象。
而调用 iterator 的 get_next() 就可以轻松地取出数据了。
import tensorflow as tf
dataset = tf.data.Dataset.range(5)
iterator = dataset.make_one_shot_iterator()
with tf.Session() as sess:
while True:
try:
print(sess.run(iterator.get_next()))
except tf.errors.OutOfRangeError:
break
out:
0
1
2
3
4上面的代码非常简单,首先创建了一个包含 0 到 4 的数据集。然后,创建了一个单次迭代器。通过循环调用 get_next() 方法就可以将数据取出。需要注意的是,通常用 try-catch 配合使用,当 Dataset 中的数据被读取完毕的时候,程序会抛出异常,获取这个异常就可以从容结束本次数据的迭代。
然而, 这种iterator 是单次的迭代器,不支持动态的数据集,它比较单纯,它不支持参数化。
什么是参数化呢?你可以理解为单次的 Iterator 认死理,它需要 Dataset 在程序运行之前就确认自己的大小,但我们都知道 Tensorflow 中有一种 feeding 机制,它允许我们在程序运行时再真正决定我们需要的数据,很遗憾,单次的 Iterator 不能满足这要的要求。
4.3 可以定制的水管,可初始化的 Iterator
单次 Iterator 无法满足参数化的要求,但有其他类型的 Iterator 可以完成这个目标。
先看一段代码,问问自己,你觉得它能正常运行吗?
def initialable_test():
numbers = tf.placeholder(tf.int64,shape=[])
dataset = tf.data.Dataset.range(numbers)
iterator = dataset.make_one_shot_iterator()
with tf.Session() as sess:
while True:
try:
print(sess.run(iterator.get_next(),feed_dict={numbers:5}))
except tf.errors.OutOfRangeError:
break- 答案是否定的,程序会报错。
ValueError: Cannot capture a placeholder (name:Placeholder, type:Placeholder) by value.- 原因,我前面刚刚有讲过。
不过,我们可以这样改写代码:
def initialable_test():
numbers = tf.placeholder(tf.int64,shape=[])
dataset = tf.data.Dataset.range(numbers)
# iterator = dataset.make_one_shot_iterator()
iterator = dataset.make_initializable_iterator()
with tf.Session() as sess:
sess.run(iterator.initializer,feed_dict={numbers:5})
while True:
try:
print(sess.run(iterator.get_next()))
except tf.errors.OutOfRangeError:
break
sess.run(iterator.initializer,feed_dict={numbers:6})
while True:
try:
print(sess.run(iterator.get_next()))
except tf.errors.OutOfRangeError:
break
- 0
- 1
- 2
- 3
- 4
- 0
- 1
- 2
- 3
- 4
- 5
- 运行程序,结果就是打印了 01234,012345 相信大家可以很容易明白发生了什么。
跟单次 Iterator 的代码只有 2 处不同。
1、创建的方式不同,iterator.make_initialnizer()。
2、每次重新初始化的时候,都要调用sess.run(iterator.initializer)
你可以这样理解,Dataset 这个水池连续装了 2 次水,每次水量不一样,但可初始化的 Iterator 很好地处理了这件事情,但需要注意的是,这个时候 Iterator 还是面对同一个 Dataset。
4.4 能够接不同水池的水管,可重新初始化的 Iterator
有时候,需要一个 Iterator 从不同的 Dataset 对象中读取数值。Tensorflow 针对这种情况,提供了一个可以重新初始化的 Iterator,它的用法相对而言,比较复杂,但好在不是很难理解。
num_train = tf.placeholder(tf.int64, shape=[])
num_val = tf.placeholder(tf.int64, shape=[])
training_data = tf.data.Dataset.range(num_train)
validation_data = tf.data.Dataset.range(num_val)
iterator = tf.data.Iterator.from_structure(training_data.output_types,
training_data.output_shapes)
train_op = iterator.make_initializer(training_data)
validation_op = iterator.make_initializer(validation_data)
next_element = iterator.get_next()
with tf.Session() as sess:
for _ in range(3):
sess.run(train_op,feed_dict={num_train:10})
for _ in range(3):
print(sess.run(next_element))
print('===========')
sess.run(validation_op,feed_dict={num_val:15})
for _ in range(2):
print(sess.run(next_element))
print('===========')- 它的运行结果如下:
0
1
2
===========
0
1
===========
0
1
2
===========
0
1
===========
0
1
2
===========
0
1
===========核心代码其实只有 3 行。
iterator = tf.data.Iterator.from_structure(training_data.output_types,
training_data.output_shapes)
train_op = iterator.make_initializer(training_data)
validation_op = iterator.make_initializer(validation_data)
- Iterator 可以接多个水池里面的水,但是要求这水池里面的水是同样的品质。
也就是,多个 Dataset 中它们的元素数据类型和形状应该是一致的。
通过 from_structure() 统一规格,后面的 2 句代码可以看成是 2 个水龙头,它们决定了放哪个水池当中的水。

但是每次 Iterator 切换时,数据都从头开始打印了。如果,不想这种情况发生,就需要接下来介绍的另外一种 Iterator。
4.5 水管的转换器,可馈送的 Iterator
Tensorflow 最美妙的一个地方就是 feeding 机制,它决定了很多东西可以在程序运行时,动态填充,这其中也包括了 Iterator。不同的 Dataset 用不同的 Iterator,然后利用 feeding 机制,动态决定,听起来就很棒,不是吗?我们都知道,无论是在机器学习还是深度学习当中,训练集、验证集、测试集是大家绕不开的话题,但偏偏它们要分离开来,偏偏它们的数据类型又一致,所以,经常我们要写同样的重复的代码。
复用,是软件开发中一个重要的思想。
可馈送的 Iterator 一定程度上可以解决重复的代码,同时又将训练集和验证集的操作清晰得分离开来。
train_data = tf.data.Dataset.range(100).map(
lambda x : x + 15
)
val_data = tf.data.Dataset.range(20)
handle = tf.placeholder(tf.string,shape=[])
iterator = tf.data.Iterator.from_string_handle(
handle,train_data.output_types,train_data.output_shapes)
next_element = iterator.get_next()
train_op = train_data.make_one_shot_iterator()
validation_op = val_data.make_initializable_iterator()
with tf.Session() as sess:
train_iterator_handle = sess.run(train_op.string_handle())
val_iterator_handle = sess.run(validation_op.string_handle())
for _ in range(3):
for _ in range(2):
print(sess.run(next_element,feed_dict={handle:train_iterator_handle}))
print('======')
sess.run(validation_op.initializer)
for _ in range(5):
print(sess.run(next_element,feed_dict={handle:val_iterator_handle}))
print('======')
out:
15
16
======
0
1
2
3
4
======
17
18
======
0
1
2
3
4
======
19
20
======
0
1
2
3
4
======
- 看起来跟前面以小节的代码没有多大区别。核心代码如下:
handle = tf.placeholder(tf.string,shape=[])
iterator = tf.data.Iterator.from_string_handle(
handle,train_data.output_types,train_data.output_shapes)
train_iterator_handle = sess.run(train_op.string_handle())
val_iterator_handle = sess.run(validation_op.string_handle())
它是通过一个 string 类型的 handle 实现的。
注意:1.这种迭代器数据集已经订好了,我也不知道怎么通过初始化的方式创建数据集。
2. 只知道handdle是句柄,类似于门的把手,在深一点就不清楚了。 string_handle() 方法返回的是一个 Tensor,只有运行一个 Tensor 才会返回 string 类型的 handle。不然,程序会报错。 
如果用图表的形式加深理解的话,那就是可馈送 Iterator 的方式,可以自主决定用哪个 Iterator,就好比不同的水池有不同的水管,不需要用同一根水管接到不同的水池当中去了。
可馈送的 Iterator 和可重新初始化的 Iterator 非常相似,但是,可馈送的 Iterator 在不同的 Iterator 切换的时候,可以做到不从头开始。
5 总结
相信阅读到这里,你已经明白了这 4 中 Iterator 的用法了。
1、 单次 Iterator ,它最简单,但无法重用,无法处理数据集参数化的要求。
2、 可以初始化的 Iterator ,它可以满足 Dataset 重复加载数据,满足了参数化要求。
3、可重新初始化的 Iterator,它可以对接不同的 Dataset,也就是可以从不同的 Dataset 中读取数据。
4、可馈送的 Iterator,它可以通过 feeding 的方式,让程序在运行时候选择正确的 Iterator,它和可重新初始化的 Iterator 不同的地方就是它的数据在不同的 Iterator 切换时,可以做到不重头开始读取数据。
终上所述,在真实的神经网络训练过程当中,可馈送的 Iterator 是最值得推荐的方式。
6 参考
https://blog.csdn.net/u010358677/article/details/70544241
iterator:重点推荐https://blog.csdn.net/briblue/article/details/80962728