【python】Python2.7爬虫+Fiddler 爬取快手APP的短视频
【原创内容,转载需作者同意】
近期学习机器学习,需要用到小视频,想爬取快手,抖音上的热门小视频,没用过这些APP,以为有网页版,没想到只有APP,无奈只能通过Fiddler进行手机抓包再爬取。过程还是比较简单的,但是属于半自动爬取,因为快手的url里有sig签名参数,3.97版本以上的快手据说采用的so加密,很难破解,所以无法让程序去自动翻页。我不是这方面的专家,所以只能采取笨办法:手动抓取100页的url,存储到文本文件,再让程序去自动读取文件。具体方法如下:
工具:Python2.7+Fiddler
1.Fiddler下载安装,这个不多说了,按照指示一步步来就好了。
2.Fiddler配置

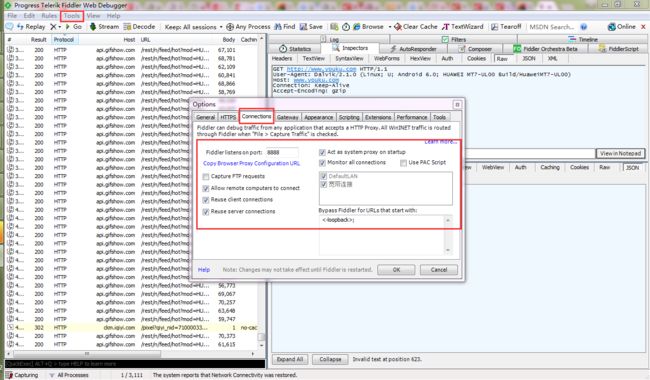
按这样设置好了之后会弹出一个对话框,点确定就好。端口选的8888,要确定该端口没有被占用,若被占用可换一个端口。
3.手机设置
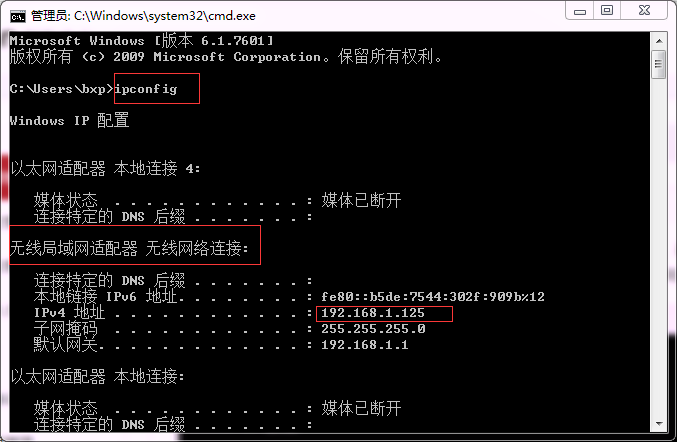
让手机和电脑处于同一网段,比如让手机和电脑连接同一个WiFi就行。在手机浏览器中输入网址: 电脑IP:端口号。电脑IP可通过cmd窗口查到,如下图,端口号就是上一步设置的8888。所以我的网址是:192.168.1.125:8888
输入网址后跳出如下页面:

点击红框中的连接,会开始下载证书:

证书名称随便写,最后点击确定就好了。安装成功之后通知栏会显示受到不明第三方监控,这样就代表成功啦。
最后一步,到手机的WLAN设置里,点击当前所连接的wifi修改网络,如下图所示:

4.手机抓包
可以开始抓包了,打开快手APP,Fiddler会快速显示很多信息,这些都是手机传送或者接收到的信息。可以逐个包点开,以json形式查看是否是我们需要的内容,如下图所示:

这时可以看到,有一个包里显示了很多信息,包括视频的标题,发布者,再往下拉,发现里面包含很多叫做“main_mv_url"的标签,复制其中一个标签后的url到浏览器,发现浏览器下载了一个mp4格式的视频,点开视频,就是我们需要的。为了让列表中只显示我们需要的包,让视图更清晰,可以用过滤器,只显示URL中含/rest/n/feed/的内容
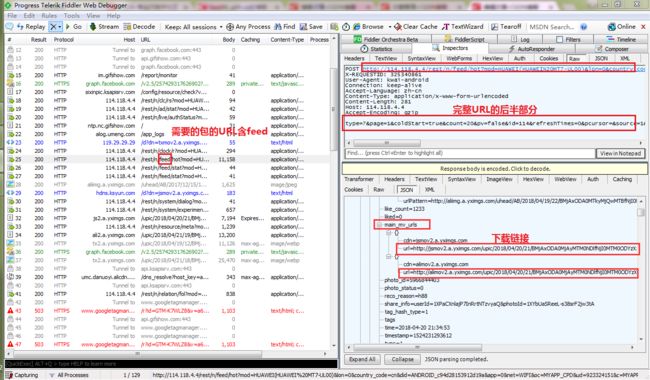
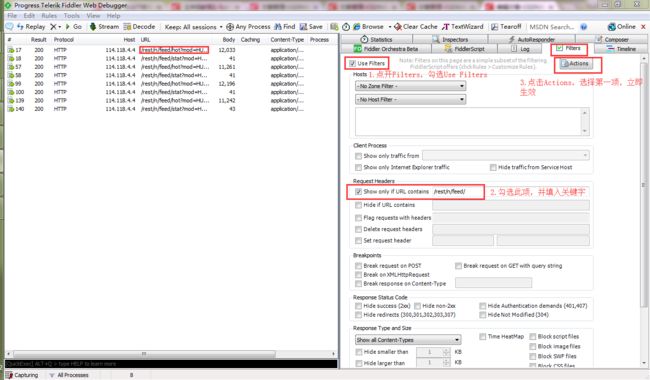
回到Fiddler,看之前那个包的头(Fiddler右上窗口),上面有个url,可以复制到浏览器会发现打开的不是和Fiddler右下角一样的json界面,而是显示服务器繁忙,因为这个url是不完整的。注意右上窗口最后一行有个“type=......”这其实是完整url的后半部分,要把它拼接到第一行POST url的后面,并且以&连接。把完整的url再复制到浏览器,得到和Fiddler右下窗口类似的内容(不是完全一样,因为视频内容会更新),ok。

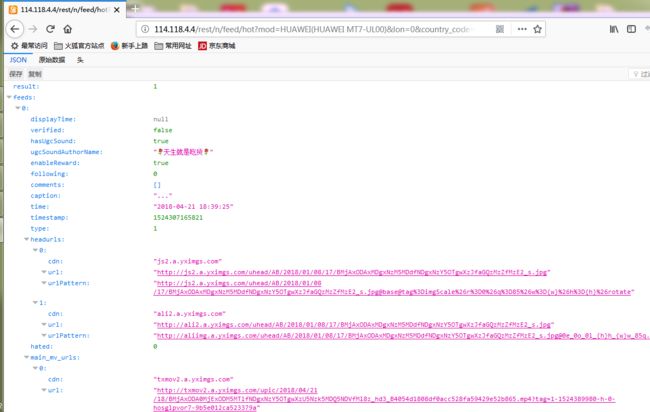
再观察“type=...”这串字符,可以多抓几个包对比一下,发现count后面跟着的数字是不一样的,即每个json里所含视频个数不一样。平均每个json中含有20个视频的下载链接。page后面的数字就代表页数,在快手界面不断的往下滑,隔一小段时间会有另一个包,可以发现page后的数字是递增的。__NStokensig和sig后跟的一串数字是没有规律可循的,要破解快手APP的代码才能知晓。所以无法掌握每个json的url变化规律,所以若是要抓取20个以上的视频,只能通过在快手app页面上往下滑动,抓包,copy完整的url到文本文件再用程序进行下载。我一共是抓了106个包,用了半小时不到,所以其实是很快的,最后能获取有2000多个视频,。
5.程序代码
程序很简单,加了日志功能来记录每个视频的题目和url和下载进度。有时候可能遇到某个下载链接有问题,所以程序可能卡在那里,因为我没有做超时处理,所以这时需要停止程序并修改一下page和video_count的值继续下载。当然这种情况比较少,我下载了2000个视频就遇到2次。最后记得每个视频下载完毕用time.sleep()挂起几秒钟,不然访问太快可能会被封哦。
#-*- coding: UTF-8 -*-
import urllib
import os
import time
import re
import logging
def kuishou_video():
logger = logging.getLogger('mylogger')#日志
logger.setLevel(logging.DEBUG)
fh = logging.FileHandler('download.log')
fh.setLevel(logging.INFO)
formatter = logging.Formatter('%(asctime)s %(levelname)-8s:%(message)s')#日志格式
fh.setFormatter(formatter)
logger.addHandler(fh)
file_path = 'url.txt'#每个json的url储存文档
if not os.path.isfile(file_path):
raise TypeError(file_path + "dose not exit!")
file_object = open(file_path).read().split('\n')
page = 1#记录是第几个url
video_count = 0#记录视频个数
for video_url in file_object:
print 'page:', page
video_url = 'http://api.gifshow.com/rest/n/feed/hot?mod=HUAWEI(HUAWEI%20MT7-UL00)&lon=118.795988&country_code=' \
'cn&did=ANDROID_c94d28153912d19a&app=0&net=WIFI&oc=MYAPP_CPD&ud=923324151&c=MYAPP_CPD&sys=ANDROID_6.0' \
'&appver=5.6.2.5992&ftt=&language=zh-cn&iuid=DuuYVvoNUPJfAxpfJFm0oqXDF1lM%2Bg4Ywr7jRjQJBiXTYZbA86EeRTX' \
'f2vOmmKZ0sdJWm1JnRnY3XZpmCxy3irZw&lat=31.937867&ver=5.6&max_memory=192&' + video_url
req = urllib.urlopen(video_url).read()
video_title_reg = re.compile(r'"caption":"(.+?)"')#视频标题
name_item = re.findall(video_title_reg, req)
download_url_reg = re.compile(r'"main_mv_urls":.+?"url".+?"url":"(.+?)"')#下载链接
url_item = re.findall(download_url_reg, req)#每个page中可下载视频链接列表
for index in range(video_count, len(url_item) + video_count):
print len(url_item), index, "name:", name_item[index - video_count], " url:", url_item[
index - video_count]#打印信息到控制台
urllib.urlretrieve(url_item[index - video_count], 'E:\\video\\kuaishou\\%s.mp4' % index)
logger.info('page ' + str(page) + ' has ' + str(len(url_item)) + ' videos' + '\n' + 'index: ' + str(index)
+ '\n' + 'title: ' +str(name_item[index - video_count]) + '\n' + 'url:' +
str(url_item[index - video_count]) + '\n')#打印信息到日志
time.sleep(10)#每下载一个视频后挂起十秒钟
print '#################################################'
page = page + 1
video_count = video_count + len(url_item)
控制台:
日志:
下载的视频: