《深度学习之TensorFlow》reading notes(1)——y=2x +常用资料备忘
目录
- 第一个练习 $y\approx 2\times x$
- 1. 准备数据
- 2. 搭建模型
- 3. 迭代训练
- 4. 使用模型
- 5. 改进建议
- 资料备用
围绕TensorFlow这本书进行学习
第一个练习 y ≈ 2 × x y\approx 2\times x y≈2×x
1. 准备数据
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
#生成模拟数据
train_X = np.linspace(-1, 1, 100) #-1到1之间,取100个点
train_Y = 2 * train_X + np.random.randn(*train_X.shape) * 0.3 # y=2x,但是加入了噪声
#显示模拟数据点
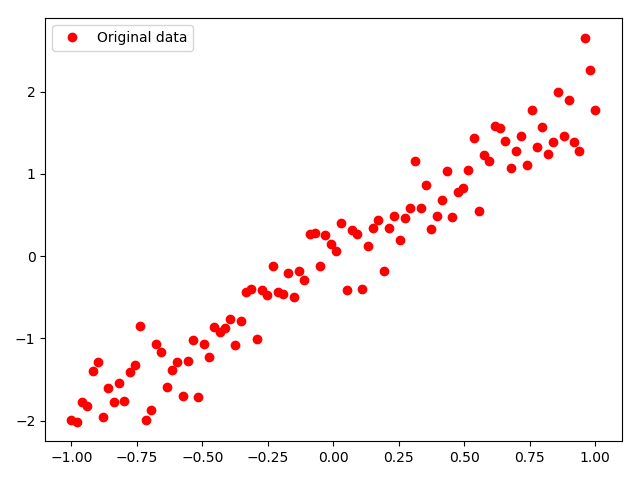
plt.plot(train_X, train_Y, 'ro', label='Original data')
plt.legend()
plt.show()
程序执行结果:就是y=2x的直线上等间隔取100个点,并在y轴方向加入一些随机扰动。
2. 搭建模型
搭建一个简单的神经元模型,输入信号x乘权重w,加上偏置b得到y。
上图对应的数学公式为:
z = ∑ i = 1 n ω i × x i + b = ω × x + b z=\sum_{i=1}^n \omega_i\times x_i +b=\omega \times x+b z=i=1∑nωi×xi+b=ω×x+b
再一次迭代过程中分为正向模型和反向模型。
其中,正向模型就是描述上图所示神经元,也就是实现上边的公式的过程;
反向过程,就是依据计算结果,对公式内 ω \omega ω和 b b b进行修正的反馈过程。
在反向过程中有加入不同的算法,本例中使用的是典型的梯度下降算法。
# 创建模型
# 占位符
X = tf.placeholder("float")
Y = tf.placeholder("float")
# 模型参数
W = tf.Variable(tf.random_normal([1]), name="weight")
b = tf.Variable(tf.zeros([1]), name="bias")
# 前向结构
z = tf.multiply(X, W)+ b
#反向优化
cost =tf.reduce_mean( tf.square(Y - z))
learning_rate = 0.01
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(cost) #Gradient descent
3. 迭代训练
# 初始化变量
init = tf.global_variables_initializer()
# 训练参数
display_step = 2
training_epochs = 20
# 启动session
with tf.Session() as sess:
sess.run(init)
# Fit all training data
for epoch in range(training_epochs):
for (x, y) in zip(train_X, train_Y):
sess.run(optimizer, feed_dict={X: x, Y: y})
#显示训练中的详细信息
if epoch % display_step == 0:
loss = sess.run(cost, feed_dict={X: train_X, Y:train_Y})
print ("Epoch:", epoch+1, "cost=", loss,"W=", sess.run(W), "b=", sess.run(b))
if not (loss == "NA" ):
plotdata["batchsize"].append(epoch)
plotdata["loss"].append(loss)
迭代结果如下图所示,可见拟合曲线从最开始的偏离比较大的情况,逐步提高拟合精度。
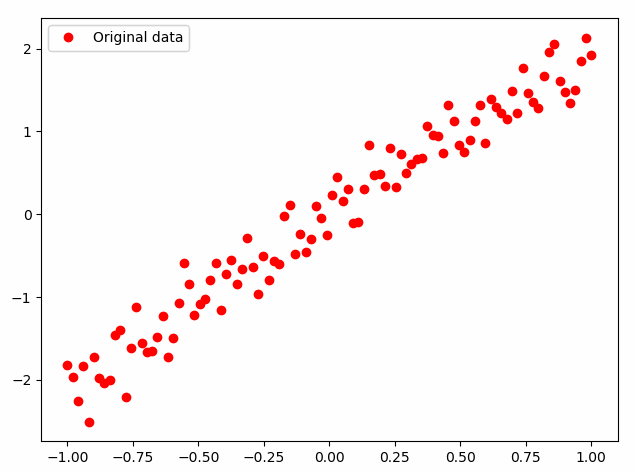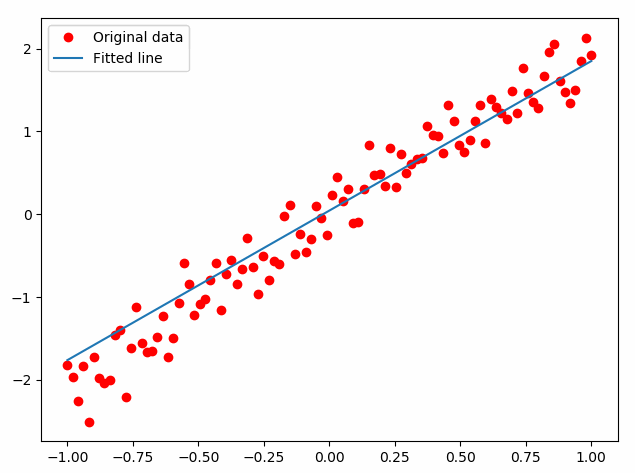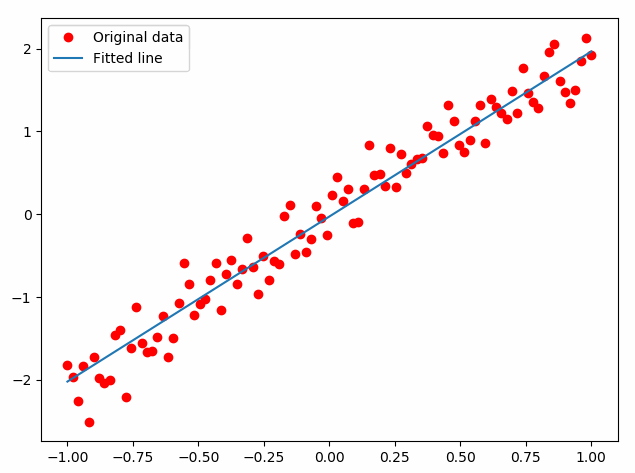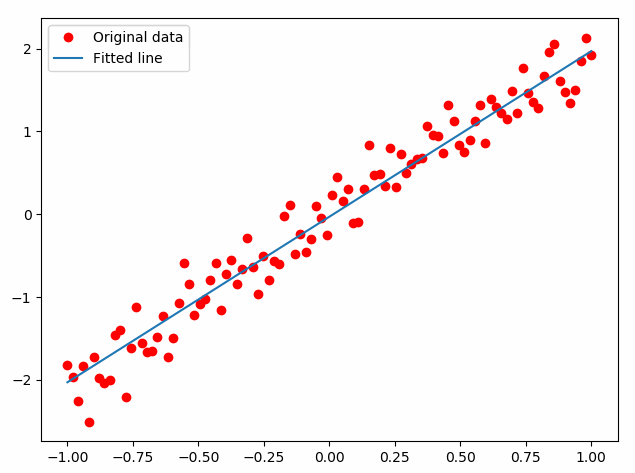
以上可以看到,通过构建神网络(在tensorflow中叫做构建“图”)。再利用已知数据对其中参数进行训练,最终得到比较好的训练结果,也就得到了预期的模型。

从loss曲线也可以看出,拟合误差逐渐降低,到第5次之后变化就不再很明显了。
4. 使用模型
使用这个模型,我们只需要给出一个x参数,通过模型求解y即可。下面程序即为测试x=0.2时,模型求得的y值。
y_result = sess.run(y, feed_dict={X:0.2})
这个程序执行的前提是在之前的with tf.Session() as sess:程序段内的。
5. 改进建议
先完结了本篇的记录,之后有两点改进想法。
- 改进learning_rate参数,现在是默认0.01,这个应该是gradient descent算法的进化速度值,如果调整为,在迭代初期比较大,迭代后期比较小,是不是可以提高迭代速度和精度。简单想法即与剩余的迭代周期相乘。
optimizer = tf.train.GradientDescentOptimizer(learning_rate*(training_epochs-epoch)).minimize(cost) #Gradient descent
- 改进绘图,将其改为二阶绘图。
z = ∑ i = 1 n ω i × x i i + b = ω 2 × x 2 + ω 1 × x + b z=\sum_{i=1}^n \omega_i\times x_i^i +b=\omega_2 \times x^2+\omega_1 \times x+b z=i=1∑nωi×xii+b=ω2×x2+ω1×x+b
本文原创连接: https://blog.csdn.net/bufanwangzi/article/details/88813061
最后附上TensorFlow这本书给的完整代码:(动图是自己改的程序,格式比较乱,就不献丑了)
# -*- coding: utf-8 -*-
"""
Created on Tue Jun 6 18:52:37 2017
"""
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
plotdata = { "batchsize":[], "loss":[] }
def moving_average(a, w=10):
if len(a) < w:
return a[:]
return [val if idx < w else sum(a[(idx-w):idx])/w for idx, val in enumerate(a)]
#生成模拟数据
train_X = np.linspace(-1, 1, 100)
train_Y = 2 * train_X + np.random.randn(*train_X.shape) * 0.3 # y=2x,但是加入了噪声
#显示模拟数据点
plt.plot(train_X, train_Y, 'ro', label='Original data')
plt.legend()
plt.show()
# 创建模型
# 占位符
X = tf.placeholder("float")
Y = tf.placeholder("float")
# 模型参数
W = tf.Variable(tf.random_normal([1]), name="weight")
b = tf.Variable(tf.zeros([1]), name="bias")
# 前向结构
z = tf.multiply(X, W)+ b
#反向优化
cost =tf.reduce_mean( tf.square(Y - z))
learning_rate = 0.01
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(cost) #Gradient descent
# 初始化变量
init = tf.global_variables_initializer()
# 训练参数
training_epochs = 20
display_step = 2
# 启动session
with tf.Session() as sess:
sess.run(init)
# Fit all training data
for epoch in range(training_epochs):
for (x, y) in zip(train_X, train_Y):
sess.run(optimizer, feed_dict={X: x, Y: y})
#显示训练中的详细信息
if epoch % display_step == 0:
loss = sess.run(cost, feed_dict={X: train_X, Y:train_Y})
print ("Epoch:", epoch+1, "cost=", loss,"W=", sess.run(W), "b=", sess.run(b))
if not (loss == "NA" ):
plotdata["batchsize"].append(epoch)
plotdata["loss"].append(loss)
print (" Finished!")
print ("cost=", sess.run(cost, feed_dict={X: train_X, Y: train_Y}), "W=", sess.run(W), "b=", sess.run(b))
#print ("cost:",cost.eval({X: train_X, Y: train_Y}))
#图形显示
plt.plot(train_X, train_Y, 'ro', label='Original data')
plt.plot(train_X, sess.run(W) * train_X + sess.run(b), label='Fitted line')
plt.legend()
plt.show()
plotdata["avgloss"] = moving_average(plotdata["loss"])
plt.figure(1)
plt.subplot(111)
plt.plot(plotdata["batchsize"], plotdata["avgloss"], 'b--')
plt.xlabel('Minibatch number')
plt.ylabel('Loss')
plt.title('Minibatch run vs. Training loss')
plt.show()
print ("x=0.2,z=", sess.run(z, feed_dict={X: 0.2}))
资料备用
TensorFlow的官方文档中文翻译(非官译):https://www.w3cschool.cn/tensorflow_python/
pythonplotlib的网址,包含很多demo:https://matplotlib.org/gallery/index.html
conda的主要命令集:https://www.jianshu.com/p/eaee1fadc1e9