【Python】聚类算法应用 -- 广告投放效果的离线评估
简要说明
同样是在实习期间做的,由于公司去年在广告的投放上高达10亿!!(黑脸=_=!),其中SEM的投放占比不小,投了四个:baidu、360、搜狗和神马,其中前三个是WAP和PC端都有投,神马只投了WAP端。所以我想对历史投放效果数据进行一下挖掘分析,看是否能找出一些有价值的东西,降低投放成本。昨天参加的一个数据分析峰会记得一嘉宾也这样说过:数据挖掘与分析的最重要的不是你的报表、图表多么得漂亮,而是你挖掘出的规律或结果能为公司业务带来多少价值。
数据 – 挖掘与分析 – 价值!
调用SQL获取所需数据
这里,我写了一个类以获取相应的数据。
- city:传入城市名称
- start_time:传入所需数据集的开始时间
- end_time:传入所需数据集的结束时间
- platform:传入平台id(1为PC,2为WAP),default value=None,即数据集是获取汇总数据
engine_type:传入引擎id(1为百度、2为搜狗、3为360、4为神马), default value=None,即数据集是获取汇总的数据
OK,Talk is easy,show the code!我直接贴上我的代码吧:
# coding:utf-8
import pandas as pd
import pymysql, datetime
from pandas.io.sql import read_sql
class AD_Statistics_Select:
def __init__(self, city, start_time, end_time, platform=None, engine_type=None):
self.city = city
self.start_time = start_time
self.end_time = end_time
self.platform = platform
self.engine_type = engine_type
self.df = self.SqlToDataframe()
self.keyword_list = self.df['keyword']
def SqlToDataframe(self):
## 连接到数据库
# 这里我隐去了详细的sql的host、用户、密码等详细信息,望大家理解
into_db = ['host', 'user','password', 'database', 'port', 'charset']
cnxn = pymysql.connect(host=into_db[0], user=into_db[1],
passwd=into_db[2], db=into_db[3],
port=int(into_db[4]), charset=into_db[5])
# 下面我也隐去了表名,请大家理解哈~
if self.platform == None and self.engine_type == None:
sql = "SELECT keyword, COUNT(DISTINCT log_date) AS date_count, SUM(present) AS present_total, \
SUM(click) AS click_total, SUM(click)/SUM(present) AS CTR, SUM(uv) AS uv_total, \
AVG(IF(price>0, price, NULL)) AS price_avg, AVG(replace(position,'\r','')) AS position_avg, \
COUNT(DISTINCT IF(click>0,log_date,NULL)) AS clicked_num \
FROM *表名* \
WHERE log_date BETWEEN '{}' AND '{}' \
AND city = '{}' \
GROUP BY 1 \
ORDER BY 1".format(self.start_time, self.end_time, self.city)
## 大家注意一下 ##
## 在SQL查询语句这块,由于多行存在,文章可能会显示的语法格式有些错误,但是在编辑器中是没问题的!##
if self.platform != None and self.engine_type == None:
sql = "SELECT keyword, COUNT(DISTINCT log_date) AS date_count, SUM(present) AS present_total, \
SUM(click) AS click_total, SUM(click)/SUM(present) AS CTR, SUM(uv) AS uv_total, \
AVG(IF(price>0, price, NULL)) AS price_avg, AVG(replace(position,'\r','')) AS position_avg, \
COUNT(DISTINCT IF(click>0,log_date,NULL)) AS clicked_num\
FROM *表名* \
WHERE log_date BETWEEN '{}' AND '{}' \
AND city = '{}' \
AND platform = '{}' \
GROUP BY 1 \
ORDER BY 1".format(self.start_time, self.end_time, self.city, self.platform)
if self.platform == None and self.engine_type != None:
sql = "SELECT keyword, COUNT(DISTINCT log_date) AS date_count, SUM(present) AS present_total, \
SUM(click) AS click_total, SUM(click)/SUM(present) AS CTR, SUM(uv) AS uv_total, \
AVG(IF(price>0, price, NULL)) AS price_avg, AVG(replace(position,'\r','')) AS position_avg, \
COUNT(DISTINCT IF(click>0,log_date,NULL)) AS clicked_num\
FROM *表名* \
WHERE log_date BETWEEN '{}' AND '{}' \
AND city = '{}' \
AND engine_type = '{}' \
GROUP BY 1 \
ORDER BY 1".format(self.start_time, self.end_time, self.city, self.engine_type)
if self.platform != None and self.engine_type != None:
sql = "SELECT keyword, COUNT(DISTINCT log_date) AS date_count, SUM(present) AS present_total, \
SUM(click) AS click_total, SUM(click)/SUM(present) AS CTR, SUM(uv) AS uv_total, \
AVG(IF(price>0, price, NULL)) AS price_avg, AVG(replace(position,'\r','')) AS position_avg, \
COUNT(DISTINCT IF(click>0,log_date,NULL)) AS clicked_num\
FROM *表名* \
WHERE log_date BETWEEN '{}' AND '{}' \
AND city = '{}' \
AND platform = '{}' \
AND engine_type = '{}' \
GROUP BY 1 \
ORDER BY 1".format(self.start_time, self.end_time, self.city, self.platform, self.engine_type)
## 使用pd接口一步到位啊!! ##
try:
frame = read_sql(sql, cnxn)
except Exception:
frame = pd.DataFrame([])
return frame
这里只提醒一点的是:
由于后面会对数据进行很多操作,所以SQL查询获得的数据集直接利用pd的read_sql(刚开始我还自己傻傻地获取,特地增加了一些处理才使之转成dataframe)得到dataframe。所以啊,好好利用大神们已经造好的轮子很重要!
简单的描述以及展现函数
当然,这一步其实是最基本的数据特征描述以及展现,但是从某些特征我们其实是可以获取很多有价值的信息的,所以这一步必不可少!
这里,我也写了一个类进行相应的数据处理,该类继承了AD_Statistics_Select,所有其父类的city、engine_type、platform等信息是全部继承下来的。
- 对keyword按照CTR进行排序:
class AD_Statistics(AD_Statistics_Select):
def keyword_SortBy_CTR(self, keyword, detail=False, **kwargs):
"""
输入需要查询的关键词,默认返回按照转化率排序得出的排序结果
以及转化率、平均单价、平均投放位置信息;
如果需要输出所有字段信息,则设置`detail=True`
param
========
keyword:必须;输入的需要查询的关键词
detail:逻辑变量,默认为False;是否需要输出该关键词的所有字段信息
df:是否输入dataframe,默认为所有未筛选过的数据
return
========
该关键词按照转化率的排序结果
"""
if 'df' in kwargs.keys():
df = kwargs['df'].sort_values('CTR', ascending=False)
else:
df = self.df.sort_values('CTR', ascengding=False)
df.index = range(1, len(df) + 1)
if detail:
return df.loc[df['keyword'] == keyword, df.columns]
return df.loc[df['keyword'] == keyword, ['CTR', 'price_avg', 'position_avg']]- 对keyword按照present进行排序:
def keyword_SortBy_present(self, keyword, detail=False, **kwargs):
"""
输入需要查询的关键词,默认返回按照展现次数排序得出的排序结果
以及转化率、平均单价、平均投放位置信息;
如果需要输出所有字段信息,则设置`detail=True`
param
========
keyword:必须;输入的需要查询的关键词
detail:逻辑变量,默认为False;是否需要输出该关键词的所有字段信息
df:是否输入dataframe,默认为所有未筛选过的数据
return
========
该关键词按照展现次数的排序结果
"""
if 'df' in kwargs.keys():
df = kwargs['df'].sort_values('present_total', ascending=False)
else:
df = self.df.sort_values('present_total', ascending=False)
df.index = range(1, len(df) + 1)
if detail:
return df.loc[df['keyword'] == keyword, df.columns]
return df.loc[df['keyword'] == keyword, ['CTR', 'price_avg', 'position_avg']]- 对keyword按照click进行排序:
def keyword_SortBy_click(self, keyword, detail=False, **kwargs):
"""
输入需要查询的关键词,默认返回按照点击次数排序得出的排序结果
以及转化率、平均单价、平均投放位置信息;
如果需要输出所有字段信息,则设置`detail=True`
param
========
keyword:必须;输入的需要查询的关键词
detail:逻辑变量,默认为False;是否需要输出该关键词的所有字段信息
df:是否输入dataframe,默认为所有未筛选过的数据
return
========
该关键词按照点击次数的排序结果
"""
if 'df' in kwargs.keys():
df = kwargs['df'].sort_values('click_total', ascending=False)
else:
df = self.df.sort_values('click_total', ascengding=False)
df.index = range(1, len(df) + 1)
if detail:
return df.loc[df['keyword'] == keyword, df.columns]
return df.loc[df['keyword'] == keyword, ['CTR', 'price_avg', 'position_avg']]- 下面几个top函数不用看,其实对前面对应的函数返回值再取head即可:
def present_top(self, n=100):
"""
返回展现量前n位的keyword数据,n默认为100
"""
return self.df.sort_values('present_total', ascending=False).head(n)
def click_top(self, n=100):
"""
返回点击量前n位的keyword数据,n默认为100
"""
return self.df.sort_values('click_total', ascending=False).head(n)
def price_top(self, n=100):
"""
返回price_avg前n位的keyword数据,n默认为100
"""
return self.df.sort_values('price_avg', ascending=False).head(n)
def date_count_top(self, n=100):
"""
返回点击天数前n位的keyword数据,n默认为100
"""
return self.df.sort_values('click_total', ascending=False).head(n)
def CTR_top(self, n=100):
"""
返回点击率前n位的keyword数据,n默认为100
"""
return self.df.sort_values('CTR', ascending=False).head(n)- 由于数据很稀疏,可以写个根据是否有click进行筛选的函数(可以不用看=_=!):
def click_none(self):
# 返回关键词里没有点击量的
return self.df[self.df['click_total'] == 0]
def click_not_none(self):
# 返回关键词里有点击量的
return self.df[self.df['click_total'] != 0]
### 简单展现一下 ###
def show_click_none(self):
show_df = self.click_none()
show_df['present_avg'] = show_df['present_total'] / show_df['date_count']
p = ggplot(aes(x='date_count',y='present_avg'), data=show_df) + geom_point()
p.show()
def show_click_not_none(self):
#show_df = self.click_top()
show_df = self.click_not_none()
show_df['present_avg'] = show_df['present_total'] / show_df['date_count']
p = ggplot(aes(x='date_count',y='present_avg'), data=show_df) + geom_point()
p.show()这里我再补充一下,我获取的训练数据的具体参数信息:
- start_time:2017-05-01
- end_time:2017-07-20
- platform:汇总数据
- engine_type:汇总数据
- city:我选择的是成交量前十的城市
我大概说一下,从keyword的click数据就可以看出,每个city的keyword大概在八、九千,有的在1万以上,大概每个城市累积贡献80%点击量以上的只有少量关键词(100来词,甚至只有几十个词)。不信?数据说话:
def click_part(self, before=0.81):
# 返回一个tuple
# 点击量before前的dataframe,before到1.0的dataframe,1.0(也即无点击的)的dataframe
click_df = self.df.sort_values('click_total', ascending=False)
add_rate = []
s = click_df['click_total'].sum()
for i in range(1, len(click_df)+1):
add_rate.append(click_df['click_total'][0:i].sum() / s)
click_df['c_add_rate'] = add_rate
#click_df['rate'] = click_df['click_total'] / click_df['click_total'].sum()
#click_df['rank'] = range(1, len(click_df)+1)
#click_df.head(200).plot('rank', 'add_rate', kind='line')
return click_df[click_df['c_add_rate'] < before], click_df[(click_df['c_add_rate']>0.81)&(click_df['c_add_rate']<1.0)], click_df[click_df['c_add_rate'] == 1.0]由于现在我关注的是贡献最多点击的那些词(其实市场部那边也是这样回复我的,他们着重关注的是前面的那些重点词~),而SEM这块是按照点击收费的,故在点击成本这块儿,点击越多,公司其竞价广告付费也越多。所以我分析的是累积贡献了80%的那些词。
指标构建
为了分析竞价price与最终点击率CTR之间的相关关系,我引入了一个中间变量–position;其实我们可以直观感受到,price越高,position值越大(position值越大,越靠后),而position越大,其带来的CTR越低。所以我构建了price-position皮尔逊系数以及position-CTR皮尔逊系数。
- 为了得到keyword所对应的皮尔逊系数值,我在类AD_Statistics_Select中添加了一个获取keyword详细信息的函数keyword_detail():
def keyword_detail(self, keyword):
# 如上,隐去了SQL连接相关信息
into_db = []
cnxn = pymysql.connect(host=into_db[0], user=into_db[1],
passwd=into_db[2], db=into_db[3],
port=int(into_db[4]), charset=into_db[5])
## 同样,大家注意一下 ##
## 这块儿SQL查询语句显示出来可能会出现语法错误,但在编辑器中是没问题的 ##
if self.platform == None and self.engine_type == None:
sql = "SELECT keyword, CAST(REPLACE(position, '\r', '') AS DECIMAL(4,2)) AS position, click/present AS CTR , price \
FROM *表名* \
WHERE log_date BETWEEN '{}' AND '{}' \
AND city = '{}' \
AND click <> 0 \
AND present <> 0 \
AND keyword = '{}' \
AND click < present \
ORDER BY 1".format(self.start_time, self.end_time, self.city, keyword)
if self.platform != None and self.engine_type == None:
sql = "SELECT keyword, CAST(REPLACE(position, '\r', '') AS DECIMAL(4,2)) AS position, click/present AS CTR , price \
FROM *表名* \
WHERE log_date BETWEEN '{}' AND '{}' \
AND city = '{}' \
AND click <> 0 \
AND present <> 0 \
AND platform = '{}' \
AND keyword = '{}' \
AND click < present \
ORDER BY 1".format(self.start_time, self.end_time, self.city, self.platform, keyword)
if self.platform == None and self.engine_type != None:
sql = "SELECT keyword, CAST(REPLACE(position, '\r', '') AS DECIMAL(4,2)) AS position, click/present AS CTR , price \
FROM *表名* \
WHERE log_date BETWEEN '{}' AND '{}' \
AND city = '{}' \
AND click <> 0 \
AND present <> 0 \
AND engine_type = '{}' \
AND keyword = '{}' \
AND click < present \
ORDER BY 1".format(self.start_time, self.end_time, self.city, self.engine_type, keyword)
if self.platform != None and self.engine_type != None:
sql = "SELECT keyword, CAST(REPLACE(position, '\r', '') AS DECIMAL(4,2)) AS position, click/present AS CTR , price \
FROM *表名* \
WHERE log_date BETWEEN '{}' AND '{}' \
AND city = '{}' \
AND click <> 0 \
AND present <> 0 \
AND platform = '{}' \
AND engine_type = '{}' \
AND keyword = '{}' \
AND click < present \
ORDER BY 1".format(self.start_time, self.end_time, self.city, self.platform,self.engine_type, keyword)
try:
keyword_detail_frame = read_sql(sql, cnxn)
except Exception:
keyword_detail_frame = pd.DataFrame([])
return keyword_detail_frame- 获取到keyword详细信息之后,由于在SQL 查询中已经对异常的click、present以及position值进行了筛选,故我们直接构建其皮尔逊相关系数:
def pearson_points(self, keyword_df):
# 返回keyword的position-price的皮尔逊相关系数以及对应的P值,position-CTR的皮尔逊相关系数以及对应的P值,price-CTR的皮尔逊相关系数以及对应的P值
grouped_by_position = keyword_df.groupby('position') # groupby
avg_grouped_by_position = grouped_by_position['CTR', 'price'].agg([np.mean]) # 求均值
avg_grouped_by_position['position'] = avg_grouped_by_position.index # 加index
array_position = np.array(avg_grouped_by_position['position'])
array_price = np.array(avg_grouped_by_position['price']).reshape(len(array_position), )
array_CTR = np.array(avg_grouped_by_position['CTR']).reshape(len(array_position), )
p_p = pearsonr(array_position, array_price)
po_C = pearsonr(array_position, array_CTR)
pr_C = pearsonr(array_price, array_CTR)
return [keyword_df['keyword'][0], p_p[0], p_p[1], po_C[0], po_C[1], pr_C[0], pr_C[1]]- 同时,可以增加一个展现函数,展现keyword的price-position信息、position-CTR信息以及最终要求的price-CTR信息:
def keyword_show(self, keyword_df):
"""
根据keyword绘出其price-position、CTR-position以及price-CTR的关系图
"""
grouped_by_position = keyword_df.groupby('position') # groupby
avg_grouped_by_position = grouped_by_position['CTR', 'price'].agg([np.mean]) # 求均值
avg_grouped_by_position['position'] = avg_grouped_by_position.index
array_position = np.array(avg_grouped_by_position['position'])
array_price = np.array(avg_grouped_by_position['price']).reshape(len(array_position), )
array_CTR = np.array(avg_grouped_by_position['CTR']).reshape(len(array_position), )
fig = plt.figure()
fig.suptitle(u'%s' % keyword_df['keyword'][0], fontproperties=font)
ax1 = fig.add_subplot(2, 2, 1)
p_p = pearsonr(array_position, array_price)
ax1.set_title(u'pearson系数:%s,伴随P值:%s' % (p_p[0], p_p[1]), fontproperties=font)
ax2 = fig.add_subplot(2, 2, 3)
po_C = pearsonr(array_position, array_CTR)
ax2.set_title(u'pearson系数:%s,伴随P值:%s' % (po_C[0], po_C[1]), fontproperties=font)
ax3 = fig.add_subplot(1, 2, 2)
pr_C = pearsonr(array_price, array_CTR)
ax3.set_title(u'pearson系数:%s,伴随P值:%s' % (pr_C[0], pr_C[1]), fontproperties=font)
avg_grouped_by_position.plot(x='position', y='price', kind='scatter', ax=ax1, figsize=(12, 6),
alpha=0.5, color='#33CC99', sharex=True)
avg_grouped_by_position.plot(x='position', y='CTR', kind='scatter', ax=ax2, figsize=(12, 6),
alpha=0.5, color='#FF3366')
avg_grouped_by_position.plot(x='price', y='CTR', kind='scatter', ax=ax3, alpha=0.5, color='#FF4500')
return plt- 遍历展现:
def keyword_list_show(self, keyword_list):
# yield返回在list中每一个keyword的可视化图
for i in keyword_list:
keyword_df = self.keyword_detail(i)
yield self.keyword_show(keyword_df)- 我们已经定义了对每个keyword求其对应pearson系数的函数,接下来就是获取累积贡献了80%点击的那些词的对应系数。比较简单,求得一个keywords list,遍历即可:
def keyword_list_pearson(self, keyword_list):
# 返回list中每一个keyword的详细pearson系数及伴随P值信息
result = []
for i in keyword_list:
keyword_df = self.keyword_detail(str(i.encode('utf-8')))
result.append(self.pearson_points((keyword_df)))
pp_df = pd.DataFrame(result)
pp_df.columns = [u'keyword', u'position-price_pearson', u'position-price_pvalue', u'position-CTR_pearson', u'position-CTR_pvalue', u'price-CTR_pearson', u'price-CTR_pvalue']
# pp_df.to_csv('keywords_pearson_point/%s-pearson.csv') % self.city
return pp_dfK-Means算法训练
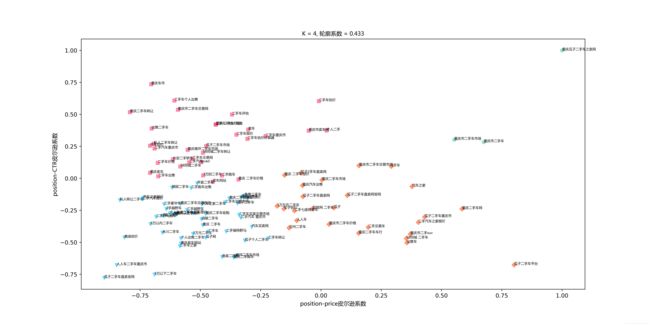
得到了所需keywords的pearson系数相关信息后,接下来最重要的一步便是模型的构建及训练。由于keyword是无标签的,所以我采用了无监督学习中最典型的K-Means聚类算法进行训练,并给出其最终分类结果。
首先,对这些词进行聚类算法分析的两个维度是:price-position pearson相关系数和position-CTR pearson相关系数。
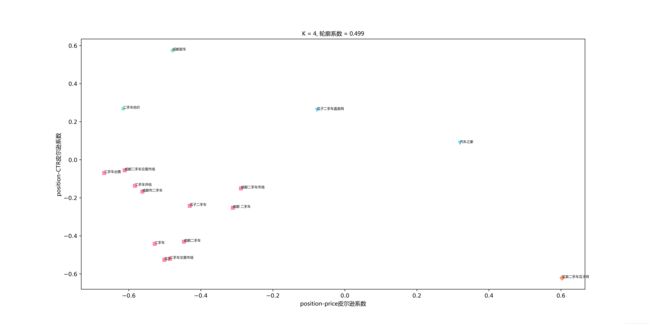
其次,最重要的一步便是K值的确定,根据博文http://blog.csdn.net/buracag_mc/article/details/75727895中所介绍的方法,我们根据肘部法则确定的K值为4,K=4也是符合我们的直观感受的。其实我们不妨大胆猜测一下分类结果:
第一类:price-position和position-CTR pearson系数均为负,这类是跟我们主观感受相符合的,应该大部分集中在这儿;
第二类:price-position和position-CTR pearson系数均为正,这类完全与我们主观感受不相符合的,数量应该很少;
第三、四类:price-position和position-CTR pearson系数一正一负,这类词是我们分析的目标词,需要尝试进行竞价调整的;
code
def keyword_pearson_kmeans(self, keyword_list):
## 聚类训练
## 将结果可视化
pp_df = self.keyword_list_pearson(keyword_list)
df_train = np.array(pp_df[['position-price_pearson', 'position-CTR_pearson']])
kmeans_model = KMeans(n_clusters=4).fit(df_train)
# print kmeans_model.labels_:每个点对应的标签值
colors = ['#33CC99', '#FF3366', '#FF4500', '#00BFFF'] # 颜色
markers = ['o', 's', 'D', 'v'] # 数据标识
plt.figure(figsize=(16, 8))
## 将每个点画出
for i, l in enumerate(kmeans_model.labels_):
plt.plot(df_train[i][0], df_train[i][1], color=colors[l],
marker=markers[l], ls='None', alpha=0.5)
plt.text(df_train[i][0], df_train[i][1], '%s' % pp_df['keyword'][i], fontproperties=font, fontsize=6)
plt.title(u'K = 4, 轮廓系数 = %.03f' %
metrics.silhouette_score(df_train, kmeans_model.labels_, metric='euclidean')
, fontproperties=font)
plt.xlabel(u'position-price皮尔逊系数', fontproperties=font)
plt.ylabel(u'position-CTR皮尔逊系数', fontproperties=font)
plt.savefig('ad_kmeans1.png', dpi=500)
plt.show()训练结果
OK,最终训练结果怎样,我们贴上图表说话:
if __name__ == "__main__":
'''
## 交互输入 ##
city = raw_input(u'请输入需要查询的城市:')
start_time = raw_input(u'请输入开始时间:')
end_time = raw_input(u'请输入结束时间:')
f_p = lambda a: None if a == '' else a
platform = f_p(raw_input(u"""请输入平台id:
其中,1为PC,2位WAP;直接enter则默认为所有平台"""))
f_e = lambda a: None if a == '' else a
engine_type = f_e(raw_input(u"""请输入搜索引擎id:
其中,1为baidu,2为sougou,3为360,4为shenma;直接enter则默认为所有搜索引擎"""))
'''对深圳市的训练结果
接下来是多图预警啊!!
AD_STA = AD_Statistics('深圳', '2017-05-01', '2017-07-20')
df = AD_STA.SqlToDataframe()
ret = AD_STA.click_part()
print AD_STA.keyword_pearson_kmeans(ret[0]['keyword'])
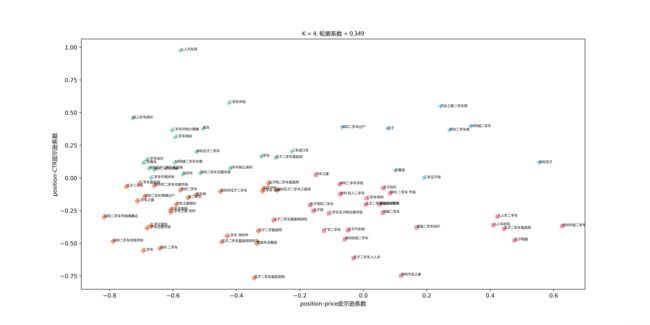
这里我上传的图片看起来可能不是很清楚,但不妨碍我们从中获取到的重要信息,关键词聚成了四类,是比较符合刚才的猜测的
第一类,price-position和position-CTR pearson系数均为负,包含了大部分广告关键词。
第二类:price-position和position-CTR pearson系数均为正,仅有少量广告关键词;
第三、四类:price-position和position-CTR pearson系数一正一负,这类词是我们分析的目标词,需要尝试进行竞价调整的;
我们再看一下,最后两类词到底有哪些:
- price-position pearson系数为正,position-CTRpearson系数为负

# 前面定义了一个函数
'''
def keyword_list_show(self, keyword_list):
# yield返回在list中每一个keyword的可视化图
for i in keyword_list:
keyword_df = self.keyword_detail(i)
yield self.keyword_show(keyword_df)
'''
# 构建一个keyword的list即可
# keyword_list = ['', '', '',...]
pictures = AD_STA.keyword_list_show(keyword_list)
for i in pictures:
print i.show()再看各个词的详细表现:
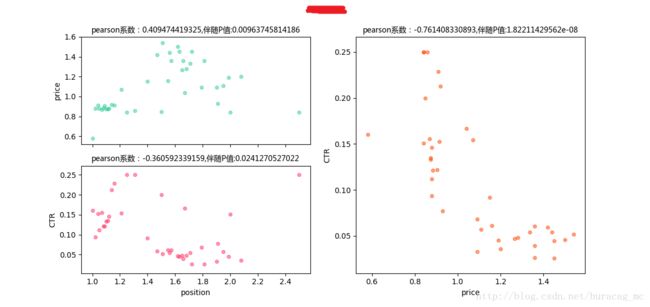
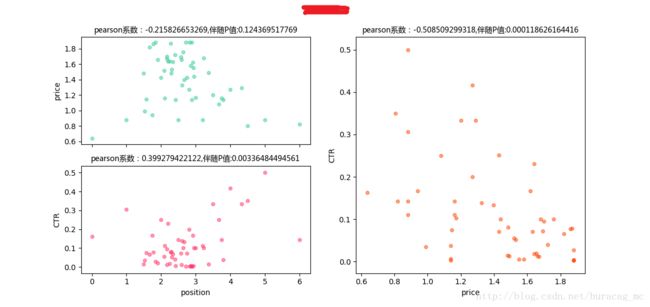
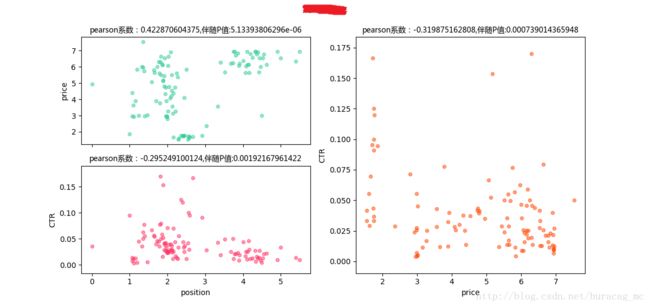
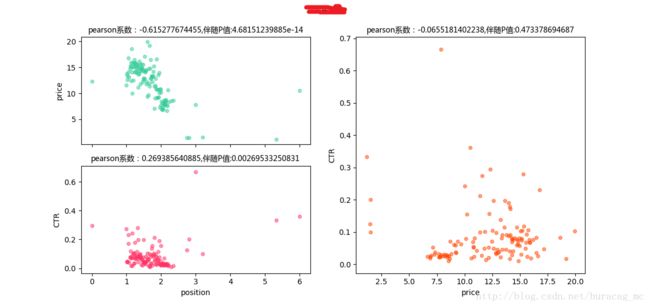
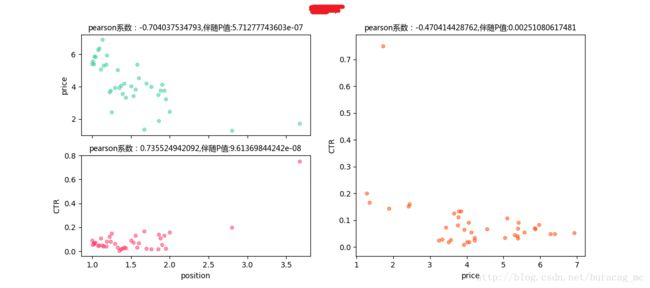
可以看到,这类词的price与CTR之间是不呈现正相关关系的,甚至有的词是存在着负相关关系!所以我们可以对这部分词降低其竞价,验证是否对CTR有显著性影响
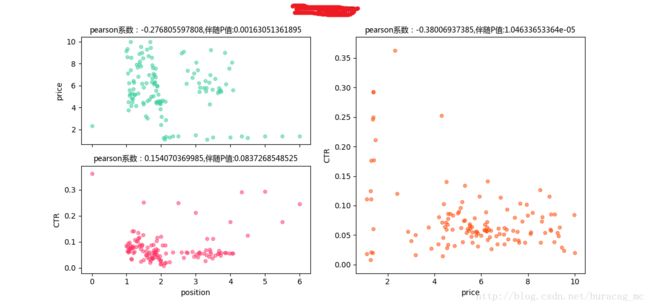
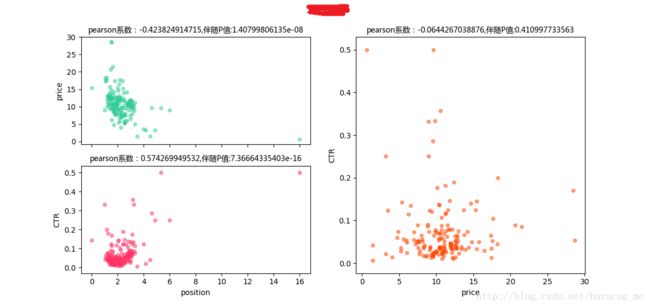
- price-position pearson系数为负,position-CTRpearson系数为正

再看各个词的详细表现:
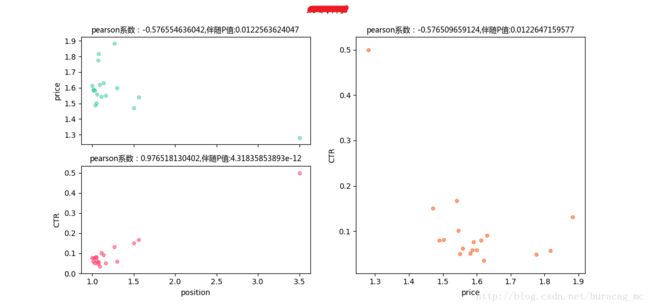
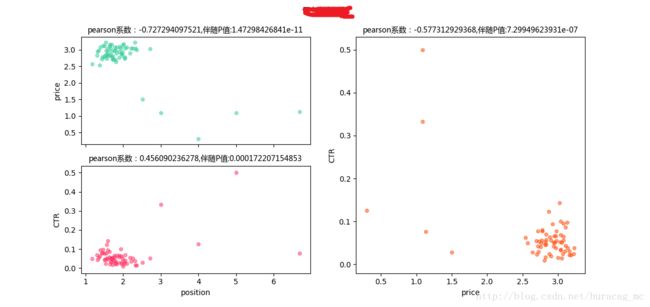
对重庆市的训练
由于篇幅所限,下面我不再赘述,仅对每种情况输出一张图以示说明即可。
- price-position pearson系数为正,position-CTRpearson系数为负
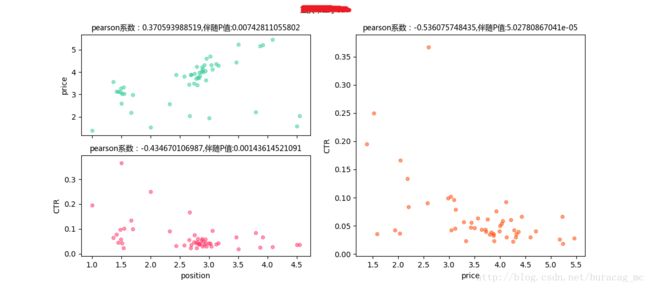
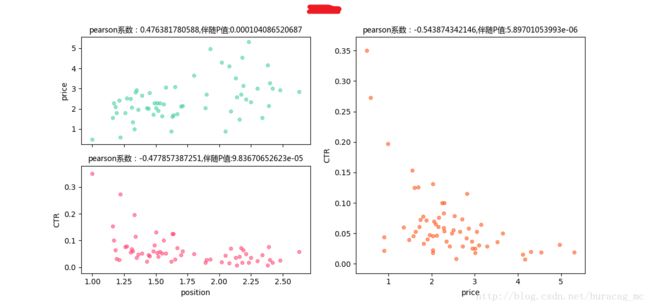
- price-position pearson系数为负,position-CTRpearson系数为正
对成都市的训练结果
- price-position pearson系数为正,position-CTRpearson系数为负
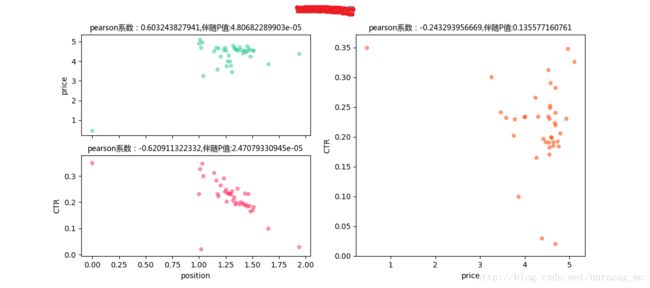
- price-position pearson系数为负,position-CTRpearson系数为正