Okio好在哪里?

/ 今日科技快讯 /
9月17日,在支付宝开放日活动中,支付宝小程序宣布将与新浪微博在场景、产品以及平台三大层面实现全面互通。微博副总裁田利英表示,微博与支付宝小程序的互通将打造一个多端融合的生态,可以重新勾画用户内容消费服务场景,在完成资源整合的同时连接更多的服务与优质内容,实现流量更高效地变现。
/ 作者简介 /
本篇文章来自老司机MxsQ的投稿,分享了对Okio的理解,相信会对大家有所帮助!同时也感谢作者贡献的精彩文章。
MxsQ的博客地址:
https://www.jianshu.com/u/9cf1f31e1d09
/ 前言 /
与很多Android小伙伴一样,接触到Okio也是在接触Okhttp之后。在Okhttp中,每个请求通过拦截链处理,而Okio则在CallServerInterceptor中,对建立起连接的请求进行读写。刚好自己对Java原生IO也不熟,就两个一起学了。本篇文章分为三个部分,第一部分介绍IO,第二部分简要介绍Java中的IO,第三部分介绍Okio。熟悉的部分自行跳过。
/ 什么是IO /
程序与运行时数据在内存中驻留,由CPU负责执行,涉及到数据交换的地方,如磁盘、网络等,就需要IO接口。IO中涉及到输入流 Input Stream 与输出流 Output Stream的概念,用来表达数据从一端,到达另一端的过程。
Input Stream 与 Output Stream 可以以内存作为参照标准,加载到内存的,是输入流,而从内存中输出到别的地方,如磁盘、网络的,则称为输出流。比如File存于磁盘中,程序获取File数据用来进行其它操作,这是将数据读入内存中的过程,所以为输入流。
反之,程序将各种信息保存入File中,是将数据读出内存的过程,所以为输出流;再比如,网络操作,请求从客户端来到服务端,也就是数据从客户端到达了服务端,那么对于客户端,是输出流,对服务端,是输入流,响应则相反。如图:
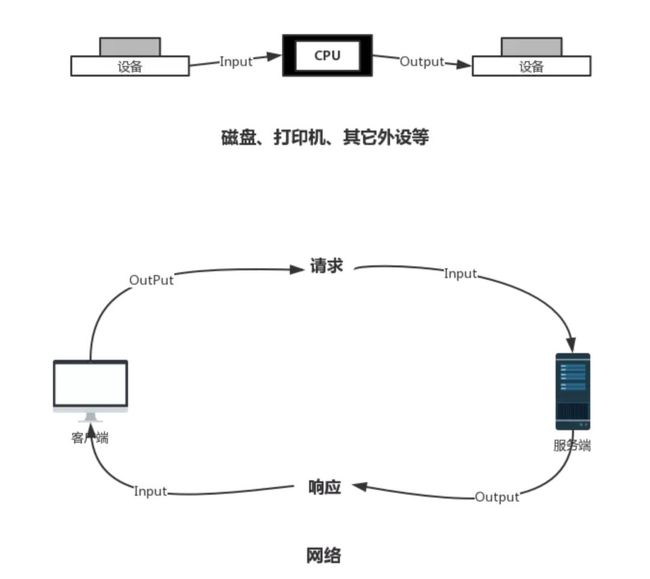
IO原理
用户态:对于操作系统而言,JVM只是一个用户进程(应用程序),处于用户态空间中,处于用户态空间的进程是不能只能操作底层的硬件(磁盘/网卡)。
系统调用:区别于用户进程调用,系统调用时操作系统级别的api,比如java IO的读取数据过程(使用缓冲区),用户程序发起读操作,导致“syscall read”系统调用,就会把数据搬入到一个buffer中;用户发起写操作,导致“syscal write”系统调用,将会把一个buffer中的数据搬出去(发送到网络中 or 写入到磁盘文件)。
内核态:用户态的进程要访问磁盘/网卡(也就是操作IO),必须通过系统调用,从用户态切换到内核态(中断,trap),才能完成。
局部性原理:操作系统在访问磁盘时,由于局部性原理,操作系统不会每次只读取一个字节(代价太大),而是借助硬件直接存储器存取(DMA)一次性读取一片(一个或者若干个磁盘块)数据。因此,就需要有一个“中间缓冲区”——即内核缓冲区。先把数据从磁盘读到内核缓冲区中,然后再把数据从内核缓冲区搬到用户缓冲区。
用户态于内核态的转化时耗时操作,甚至可能比所要执行的函数执行时间还长,应用程序进行IO操作时,应尽量减少转换操作。并且由于局部性原理,操作系统度读取数据是整片读取的,假设一片的数据为4096字节,那么0~4096字节范围内的数据,对于操作系统来说,读取时间差异是可以忽略不计的。因此,缓冲区的是为了解决速度不匹配问题。
/ Java原生IO /
Java程序自然要遵守并利用IO的特点。在Java里,输入流为InputStream的子类,输出流为OutputStream的子类,并且具体的读操作read()与写操作write(),均有具体场景下的具体子类来实现。而涉及到IO操作,就抛不开BufferedInputStream和BufferedOutputStream,前者对应输入流,后者对应输出流,这两个类是流上缓冲区的实现。
假设要将一些自定义的数据写入文件中,那构建出的输出流可能如下:
new DataOutputStream(new BufferedOutputStream(new FileOutputStream("filePath")));
其中DataOutputStream功能为转译,将数据转换成对应字节,BufferedOutputStream为缓冲,FileOutputStream则为具体输出实现,也就是调用下层API的上层触发点。实际上,输入流与输出流类似,流的构造涉及装饰模式,这样可以把想要的功能拼装起来。
IO操作涉及到的类有很多,不一一介绍,主要看BufferedInputStream与BufferedOutputStream如何实现缓冲功能。
输入流缓冲 BufferedInputStream
BufferedInputStream的读取操作有:
read():读取下一个字节
read(byte b[], int off, int len):读取一段数据到b[]中
看读取一段数据,读取下一字节的API自然能理解:
// 默认的缓冲区存储数据大小
private static int DEFAULT_BUFFER_SIZE = 8192;
// 存储缓冲区数据
protected volatile byte buf[];
// 当前缓冲区的有效数据 = count - pos
protected int count;
// 当前缓冲区读的索引位置,在pos前的数据是无效数据
protected int pos;
// 当前缓冲区的标记位置,需要配合 mark() 和 reset()使用
// mark()将pos位置索引到到markpos
// reset() 将pos值重置为markpos,当再次read()数据时,会从mark()标记的位置开始读取数据
protected int markpos = -1;
// 缓冲区可标记位置的最大值
protected int marklimit;
public synchronized int read(byte b[], int off, int len)
throws IOException
{
// 获取buf,在流关闭情况下buf被释放
getBufIfOpen();
// 检查要获取的数据(假设有),b[]是否内存得下
if ((off | len | (off + len) | (b.length - (off + len))) < 0) {
throw new IndexOutOfBoundsException();
} else if (len == 0) {
return 0;
}
int n = 0;
for (;;) {
// 读取数据到b[], nread为已读取的数量
int nread = read1(b, off + n, len - n);
// 已按照需求,将要求的数据读取到b[]
if (nread <= 0)
return (n == 0) ? nread : n;
// 记录已读取到的数据数
n += nread;
if (n >= len)
return n;
// 是BufferedInputStream装饰的输入流,BufferedInputStream只负责缓冲
InputStream input = in;
// 如果输入流已关闭或者再没有可读数据,则返回
if (input != null && input.available() <= 0)
return n;
}
}
读取操作需要通过私有函数read1()进行读取,每次读取完后,read1()都会返回int表示读取到的字节数,-1则表示没有读取或读取不到数据,这种情况直接向上返回。接着,用n记录每次读取到的数据,因为将数据读取到 b[] 很可能一次读取不满。当n满足读取需求或是再无可读取数据时,向上返回。
private int read1(byte[] b, int off, int len) throws IOException {
// 缓冲区有效数据数量
int avail = count - pos;
if (avail <= 0) {
// 进到这里说明缓冲区没有可读取的数据
// 需要读取的数据量大于缓冲区能读取的大小,使用缓冲区无意义
// 直接交给in去读取
if (len >= getBufIfOpen().length && markpos < 0) {
return getInIfOpen().read(b, off, len);
}
// 缓冲区已没有可读取的数据,对缓冲区填充
fill();
// 记录缓冲区有效数据
avail = count - pos;
// 这里说明已经读不到有效数据
if (avail <= 0) return -1;
}
// 将要读入 b[] 的数据量
int cnt = (avail < len) ? avail : len;
// 将缓冲区的数据读入 b[]
System.arraycopy(getBufIfOpen(), pos, b, off, cnt);
// 更新缓冲区索引位置,在fill()会被重重
pos += cnt;
return cnt;
}
read1()将数据读入 b[],需要是从缓冲区读取还是直接从in读取需要看具体情况。需要注意,如果要读取的数据量len大于缓冲区存储的数据量,就直接从in读取,因在在这种情况下使用缓冲策略不能带来优化。
缓冲的作用,是用来模仿CPU读取数据整块读取的习惯,在块的数据范围内,速度差异是可以不计的,因此缓冲可以拿到整块的数据,在从缓冲区中读取不超过块范围的数据,是不用经过系统调用的。而在len大于缓冲区内存储的数据量情况下,如果使用缓冲策略,不仅用不到缓冲区的优势,反而增加了系统调度次数。
read1() 读取数据可用下图表示:


剩下填充缓冲区操作fill()。
private void fill() throws IOException {
// 获取缓冲区
byte[] buffer = getBufIfOpen();
if (markpos < 0)
// 没有使用mark功能,重置pos
pos = 0;
else if (pos >= buffer.length)
if (markpos > 0) {
int sz = pos - markpos;
// 将 pos ~ markpos 之间的数据向左移动
// 移动完后数据位于 0 ~ sz,移动完后目前sz之后的数据无效
System.arraycopy(buffer, markpos, buffer, 0, sz);
pos = sz;
markpos = 0;
} else if (buffer.length >= marklimit) {
// 缓冲区容量大于可标记限制,所有数据都不要了
// mark标记也不要了
markpos = -1;
pos = 0;
} else if (buffer.length >= MAX_BUFFER_SIZE) {
// 缓冲区容量过大,抛出异常
throw new OutOfMemoryError("Required array size too large");
} else {
// 可标记区域大于缓冲区容量,对缓冲区进行扩容
int nsz = (pos <= MAX_BUFFER_SIZE - pos) ?
pos * 2 : MAX_BUFFER_SIZE;
if (nsz > marklimit)
nsz = marklimit;
byte nbuf[] = new byte[nsz];
System.arraycopy(buffer, 0, nbuf, 0, pos);
if (!bufUpdater.compareAndSet(this, buffer, nbuf)) {
throw new IOException("Stream closed");
}
buffer = nbuf;
}
// 记录count位置
count = pos;
// 向in读取数据,数量为缓冲区容量 - 当前缓冲区索引
int n = getInIfOpen().read(buffer, pos, buffer.length - pos);
// 读到有效数据,更新count
if (n > 0)
count = n + pos;
}
主要理解,从in读取缓冲数据,并更新pos和count,因为count - pos 得到缓冲区有效数据,pos则是有效数据的起点。
输出流缓冲 BufferedOutputStream
与输入流BufferedInputStream相似,输出流BufferedOutputStream同样是为了减少系统调度,只不过二者的数据走向方向相反。BufferedOutputStream接收数据并存入缓冲区,在缓冲池满或者主动调用flush()之后,触发系统调度,将缓冲池数据写出。平时可能少见触发flush()操作,在关闭输出流接口操作close()时,也会线触发flush()操作。
与分析BufferedInputStream时类似,输出流BufferedOutputStream直接看write()。
public synchronized void write(byte b[], int off, int len) throws IOException {
if (len >= buf.length) {
// 要写出的数据大于缓冲区的容量,也不用缓冲区策略
// 先将缓冲区数据写出
flushBuffer();
// 再直接通过输出流out直接将数据写出
out.write(b, off, len);
return;
}
if (len > buf.length - count) {
// 要写出的数据大于缓冲区还可写入的容量,将缓冲区数据写出
flushBuffer();
}
// 将要写出的数据写入到缓冲区
System.arraycopy(b, off, buf, count, len);
// 更新缓冲区已添加的数据容量
count += len;
}
当数据大于缓冲区容量时,不使用缓冲策略的原因和与分析写入流类似,都是尽可能少的进行系统调度,输出流缓冲写出过程可用下图表示。
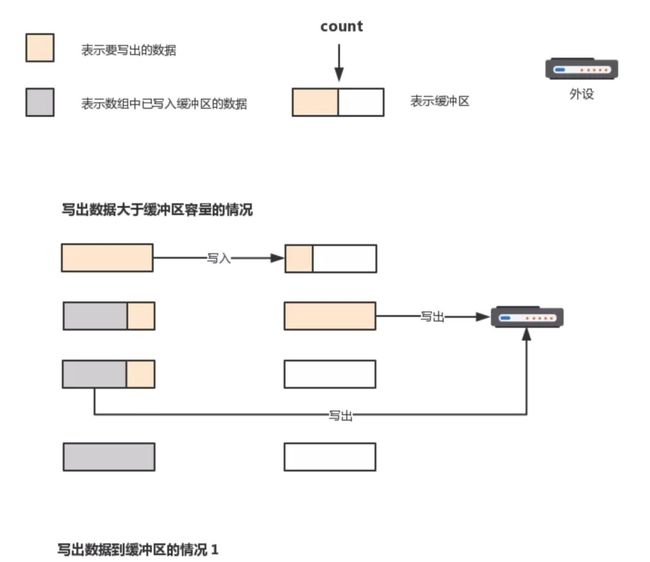
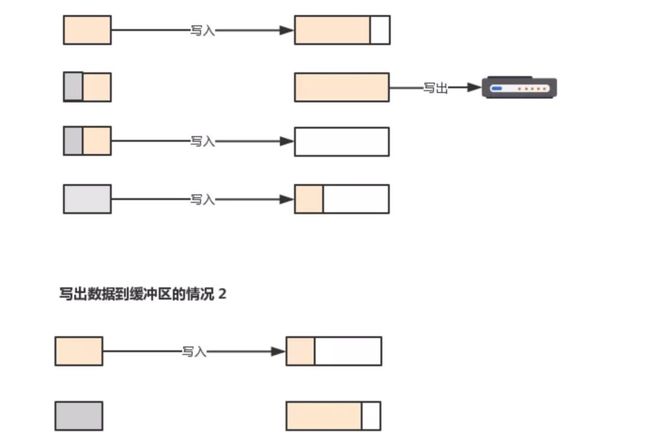
flushBuffer()就比较简单了,触发out输出流写出数据。
private void flushBuffer() throws IOException {
if (count > 0) {
out.write(buf, 0, count);
count = 0;
}
}
/ IO缓冲小结 /
IO缓冲区的存在,减少了系统调用。也就是说,如果缓冲区能满足读入/写出需求,则不需要进行系统调用,维护系统读写数据的习惯。
从上面学习的内容来看,不管是读入还是写出,缓冲区的存在必然涉及copy的过程,而如果涉及双流操作,比如从一个输入流读入,再写入到一个输出流,那么这种情况下,在缓冲存在的情况下,数据走向是:
-> 从输入流读出到缓冲区
-> 从输入流缓冲区copy到 b[]
-> 将 b[] copy 到输出流缓冲区
-> 输出流缓冲区读出数据到输出流
上面情况存在冗余copy操作,Okio应运而生。
/ Okio实现 /
在Okio里,解决了双流操作时,中间数据 b[] 存在冗余拷贝的问题。虽然这不能概括Okio的优点,但却是足够亮眼以及核心的优点。
Okio可以通过:
implementation("com.squareup.okio:okio:2.4.0")
引入,如果已引入Okttp3或者Retrofit,则无需再引入。
Okio使用Segment来作为数据存储手段。Segment 实际上也是对 byte[] 进行封装,再通过各种属性来记录各种状态。在交换时,如果可以,将Segment整体作为数据传授媒介,这样就没有具体数据的copy过程,而是交换了对应的Segment引用。Segment的数据结构如下:
final class Segment {
// 默认容量
static final int SIZE = 8192;
// 最小分享数据量
static final int SHARE_MINIMUM = 1024;
// 存储具体数据的数组
final byte[] data;
// 有效数据索引起始位置
int pos;
// 有效数据索引结束位置
int limit;
// 指示Segment是否为共享状态
boolean shared;
// 指示当前Segment是否为数据拥有者,与shared互斥
// 默认构造函数的Segment owner为true,当把数据分享
// 出去时,被分享的Segment的owner标记为false
boolean owner;
// 指向下一个Segment
Segment next;
// 指向前一个Segment
Segment prev;
}
除了用来存储具体数据的byte[]数据外,以 pos ~ limit 来标记有效的数据范围。Segment被涉及成可以被分割,在将Segment分割成两个Segment时,就会进行数据分享,即使用相同的byte[] 数组,只不过 pos ~ limit 标记不同罢了。在分享否,就需要区分个Segment是owner,哪个Segment是shared,这样,就需要对应的标志进行标记。也不难看出,Segment可以采用双向链表结构进行连接。这里不妨先看看Segment的分割函数split()。
/ Segment分割 /
public Segment split(int byteCount) {
// byteCount表示要分割出去的数据大小
// 如果byteCount大于Segment拥有的有效数据大小,抛出异常
if (byteCount <= 0 || byteCount > limit - pos) throw new IllegalArgumentException();
Segment prefix;
if (byteCount >= SHARE_MINIMUM) {
// 大于分割阀值 1024,进行数据共享
// 这个情况 prefix.pos = this.pos
prefix = new Segment(this);
} else {
// 小于分割阀值,从缓存池里换取Segment,将所需数据copy到
// 新的Segment中,这里就没有使用到共享
// 这个情况 prefix.pos = 0;
prefix = SegmentPool.take();
System.arraycopy(data, pos, prefix.data, 0, byteCount);
}
// 更新当前Segment.pos与新的Segment.limit
prefix.limit = prefix.pos + byteCount;
pos += byteCount;
// 将Segment加入到当前Segment节点的后面
prev.push(prefix);
return prefix;
}
上面的代码描述情况可以用下图表示
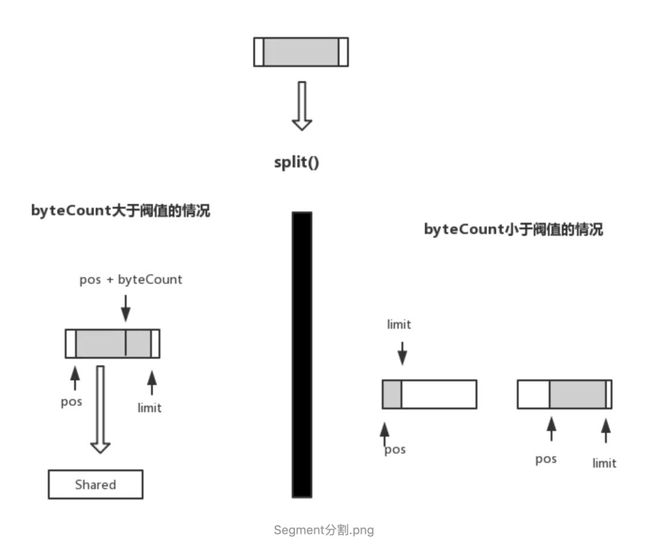
分割操作视byteCount大小,有不同选择。byteCount大于阀值时,新建Segment,并与当前的Segment共享byte[]数据,其中,当前Segment的的索引范围为[pos + byteCount] ~ [limit],新的Segmetn索引范围为[pos] ~ [pos + byteCount] ; byteCount小于阀值时,则通过copy操作,将所需数据搬运到新的Segment。
/ Segment缓存池 /
slipt()操作中可以看到缓存池SegmentPool的身影。与大多数缓存池一样,SegmentPool避免的内存的重新分配。SegmentPool存储的大小为 64 * 1024, Semgent数据存储大小为 8192,因此最多存下8个Segment。
SegmentPool复用IO操作中分配到的内存,也是得益于Segment的设计,当涉及到多流操作时,效果明显。
取操作为 take(),回收操作为 recycle() ,存储方式为单向链表,这里不多说。
/ Okio中的角色 /
说了那么多,在看看看Okio中涉及的到角色
Source和Sink
对应IO中的输入流和输出流,Source的实现类实现需read(Buffer sink, long byteCount) throws IOException; Sink的实现类实现write(Buffer source, long byteCount)。不难猜测,在Okio中以Buffer作为操作媒介,可以发挥它的最大优势。
BufferedSource 和 BufferedSink
对应IO中输入流缓冲和输出流缓冲,提供对外的API进行读写操作。
Okio
入口类,工厂类,提供source方法可以得到一个Source输入流,提供sink方法得到一个Sink输出流。两种方法可接受的入参都可为 File、Socket、InputStream / OutputStream。对每个对应的方法进行查看,Okio并没有改变各种Java 输入输出流的对应装饰对象的构造,在构造上,对于涉及到的上面说到的入参,构造起来比较方便。也能看出,Okio并没有打算改变底层的IO方式,旨在弥补原声IO框架上的不足。
Segment
这一部分开篇已现对Segment进行了介绍。除了介绍都的内容外,Segment可以以单链、双链的方式存储。提供了pop()将自己从链中删除,返回下一节点;push()将一个Segment加在自己后面,这两个对于链表的操作不做深入。既然提供了split()方法进行分割,自然也提供了compact()方法Segment进行合并,前提是用来做合并的Segment的剩余容量装得下,也不做深入。
SegmentPoll
复用Segment,前面说过,不赘述。RealBufferedSource,RealBufferdSink为BufferedSource 和 BufferedSink的实现类。
Buffer
Okio使用了Segment作为数据存储的方式,自然要提供对应的缓冲方式来操作Segment,Segment在Buffer中以双向链表形式存在。Buffer则负责此项事务。Buffer也实现了BufferedSource和BufferedSink,这是因在使用Okio提供的输入/输出缓冲时,都需要进行缓冲处理,均由Buffer来处理,这样使API对应。
TimeOut
提供超时功能,希望IO能在一定时间内进行完毕,否则视为异常。分两种情况,同步超时和异步超时。
同步超时:在每次读写中判断超时条件,因为处于同步方法,因此当IO发生阻塞时,不能及时响应。
异步超时:用单独的线程监控超时条件,如果IO发生阻塞,并且检测到超时,抛出IO异常,阻塞终止。
这部分也不做深入。
/ 缓冲实现 /
假设使用Okio复制一个文件,那么实例代码可能是这样的
/**
* 构造带缓冲的输入流
*/
Source source = null;
BufferedSource bufferedSource = null;
source = Okio.source(new File("yourFilePath"));
bufferedSource = Okio.buffer(source);
/**
* 构造带缓冲的输出流
*/
Sink sink = null;
BufferedSink bufferedSink = null;
sink = Okio.sink(new File("yourSaveFilePath"));
sink = Okio.buffer(sink);
int bufferSize = 8 * 1024; // 8kb
// 复制文件
while (!bufferedSource.exhausted()){
// 从输入流读取数据到输出流缓冲
bufferedSource.read(
bufferedSink.buffer(),
bufferSize
);
// 输出流缓冲写出
bufferedSink.emit();
}
source.close();
sink.close();
上面代码中,Okio.source() 和 Okio.sink() , Source 接收的输入流为 FileInputStream, Sink接收输出流为FileOutputStream。Okio.buffer 和 Okio.sink分别返回 RealBufferedSource, 和 RealBufferedSink,Buffer作为这两个类的成员变量存在,在实例化时初始化,这部分代码不贴出。主要看 RealBufferedSource.read()。
public long read(Buffer sink, long byteCount) throws IOException {
// 用来接收数据的Buffer 不能为空
if (sink == null) throw new IllegalArgumentException("sink == null");
// 读取数据不能为负数
if (byteCount < 0) throw new IllegalArgumentException("byteCount < 0: " + byteCount);
if (closed) throw new IllegalStateException("closed");
// 缓冲区没有数据了
if (buffer.size == 0) {
// 从输入流中读取数据
long read = source.read(buffer, Segment.SIZE);
if (read == -1) return -1;
}
// 比较 byteCount 与 缓冲中的数据容量,得到到实际要读取的数据量
long toRead = Math.min(byteCount, buffer.size);
// 从Buffer 中读取数据
return buffer.read(sink, toRead);
}
与Java原生的缓冲方式类似,都先考虑缓冲区中的数据情况,如果缓冲区中没有数据,则先向流读取数据填充缓冲区,再根据所需读取容量与实际缓冲区中存有的数据容量进行读取。这里有一点和Java原生的不同,如果byteCount的数据超出Segment的容量的话,不会直接向流读取。可以看出Okio非常希望以Segment为单位来对流数据进行操作,看接收byte[]为参数的read()的重载方法也最受这个规则。
先看source.read(buffer, Segment.SIZE)。source通过之前Okio.source()得来,见Okio.source()。
private static Source source(final InputStream in, final Timeout timeout) {
// 输入流不能为空
if (in == null) throw new IllegalArgumentException("in == null");
// 超时条件不能为空
if (timeout == null) throw new IllegalArgumentException("timeout == null");
// 匿名内部类Source
return new Source() {
public long read(Buffer sink, long byteCount) throws IOException {
// 获取的byteCount不能为负数
if (byteCount < 0) throw new IllegalArgumentException("byteCount < 0: " + byteCount);
if (byteCount == 0) return 0;
try {
// 检查是否超时
timeout.throwIfReached();
// 获取尾节点的Segment,尾节点不满足填充新数据条件则拿到新的Segment
// 也是位于尾节点
Segment tail = sink.writableSegment(1);
// 实际从in读取的数据,能看出最大不能超过 Segment.SIZE
int maxToCopy = (int) Math.min(byteCount, Segment.SIZE - tail.limit);
// 从in中读取数据到Segment.data
int bytesRead = in.read(tail.data, tail.limit, maxToCopy);
// 这里说明没有读到有效数据
if (bytesRead == -1) return -1;
// 更新索引位置
tail.limit += bytesRead;
// 更新buffer容量
sink.size += bytesRead;
return bytesRead;
} catch (AssertionError e) {
if (isAndroidGetsocknameError(e)) throw new IOException(e);
throw e;
}
}
......
};
}
从输入流中读取数据,数据存于Buffer中,位于尾节点的Segment,与前面说的一样,单次向流读出操作,大小不能超过Segment.SIZE。回到read(),在确认缓冲区有数据之后,从缓冲区中读取数据到sink,即从Buffer中读取数据到另一Buffer。
public long read(Buffer sink, long byteCount) {
// 用来接收数据的sink不能为空
if (sink == null) throw new IllegalArgumentException("sink == null");
// 接收的数据大小不能为负数
if (byteCount < 0) throw new IllegalArgumentException("byteCount < 0: " + byteCount);
if (size == 0) return -1L;
// 读取的数据不超过当前缓冲区的容量
if (byteCount > size) byteCount = size;
// 从当前缓冲区,将数据写入到另一缓冲区,即从 this,写到sink
sink.write(this, byteCount);
return byteCount;
}
public void write(Buffer source, long byteCount) {
if (source == null) throw new IllegalArgumentException("source == null");
if (source == this) throw new IllegalArgumentException("source == this");
checkOffsetAndCount(source.size, 0, byteCount);
/**
缓冲区数据从 缓冲区source 移动到 缓冲区this,
在当前的案例中,缓冲区source代表输入流缓冲数据,缓冲区this代表输出流缓冲数据
此函数源码内部有一大段注释,可以细细品味,我就不贴了
*/
while (byteCount > 0) {
if (byteCount < (source.head.limit - source.head.pos)) {
// 进到这里说明,说明source的头节点有足够的数据
// 获取当前缓冲区尾节点
Segment tail = head != null ? head.prev : null;
if (tail != null && tail.owner
&& (byteCount + tail.limit - (tail.shared ? 0 : tail.pos) <= Segment.SIZE)) {
// 尾节点不为空,并且尾可解是owner状态
// 并且尾节点能够装下byteCount数量的数据
// 将数据从source的头节点 copy 到 当前缓冲区的尾节点
source.head.writeTo(tail, (int) byteCount);
source.size -= byteCount;
size += byteCount;
return;
} else {
// 说明数据当前缓冲区尾节点不能存下byteCount大小的数据
// 将source头节点的Segment分割,byteCount过阀值则共享,否则拷贝
// 共享过程则不用copy
source.head = source.head.split((int) byteCount);
}
}
/**
将source缓冲区的头节点pop,加入到当前缓冲区
*/
Segment segmentToMove = source.head;
long movedByteCount = segmentToMove.limit - segmentToMove.pos;
source.head = segmentToMove.pop();
if (head == null) {
// 进到这里说明当前缓冲区没有数据,将segmentToMove作为头节点
head = segmentToMove;
head.next = head.prev = head;
} else {
// 进到这里则是将segmentToMove放到链表尾部
Segment tail = head.prev;
tail = tail.push(segmentToMove);
tail.compact();
}
/**
更新缓冲区大小,已经还需的byteCount数量
*/
source.size -= movedByteCount;
size += movedByteCount;
byteCount -= movedByteCount;
}
}
Buffer.write()方法,将数据从一个缓冲区移动到另一个缓冲区,根据不同情况来决定是进行copy或者是引用的引动,沿用上面代码的source表示为来源缓冲区,this表示为当前缓冲区,则source到this的过程为:
假设source头节点有足够的数据,当this的尾节点能装得下是,将数据copy入this的尾节点;当this的尾节点装不下时,将source头节点数据进行slipt()操作,this需要的数据会被分割在source的Segment链表里并成为新的头节点,再将source的头节点pop出,push到this的尾节点
假设source头节点没有足够的数据,说明整个头节点都要移动出去。当this内无数据时,将source头节点pop,成为this的头节点;当this内有数据时,将source头节点pop,push到this的尾节点
上述出现的情况可以用下图表达:
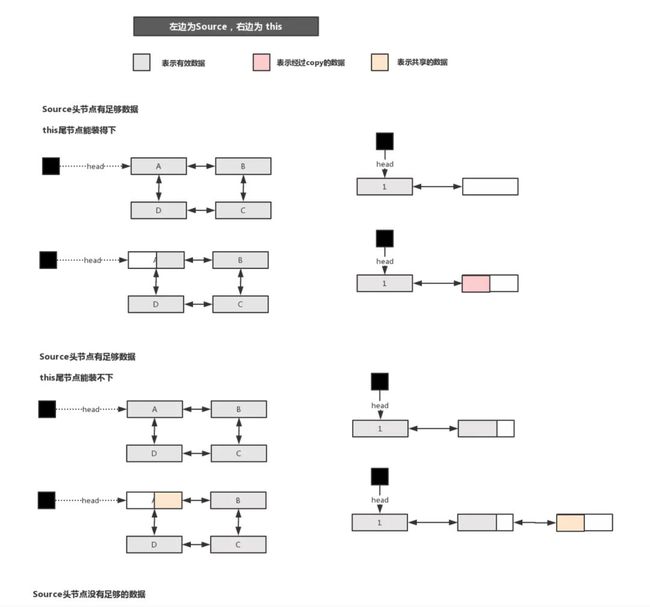
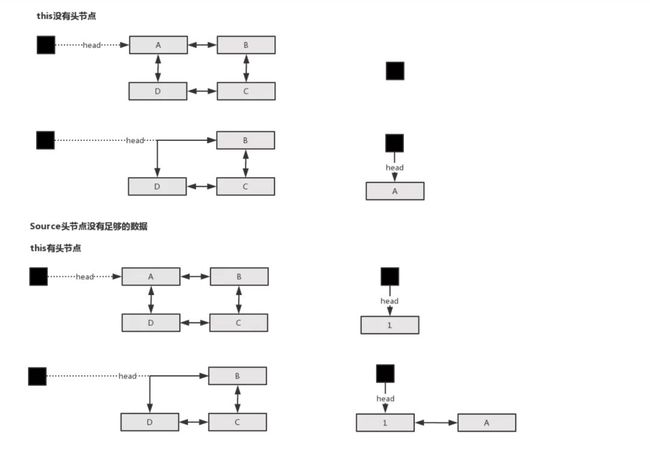
经过Buffer.write()操作,也就把数据从一个缓冲区,移动到了另一个缓冲区。对应当前的案例,则是从文件输入流缓冲区拿数据,读出到文件输出缓冲区。
/ 其它 /
Okio最亮眼的操作,就是设计出了Segment存储数据,通过Buffer进行缓冲管理,并在Buffer.write()则里,通过移动引用而不是真实数据,是减少数据copy进而交换数据的关键。
上面分析了RealBufferedSource,而RealBufferedSink也是同样的道理,只是方向相反,缓冲数据存储依然离不开Segment和Buffer,RealBufferedSink拿到数据后,再通过emit()将数据写出到输出流,RealBufferedSink拿到的sink的操作,可以通过Okio.sink()拿到的匿名内部类Sink()查看,分析方法类似。相较于Java原生IO的缓冲方案,双流操中,或者说以Buffer来代替 写入/写出 的 byte[],减少了copy的过程,通过Segment的移动达到目的。
此外,Okio的写入/写出操作,也可以像原生那样,接受byte[]参数,或者直接获取下一个数据,这种情况时,则于原生相似,需要时一样依赖copy,不再有减少copy的优势。并且,Okio接口也更友好,如之前说原生实现向文件写入自定义数据时,需要Data的流类型进行转译,自身就封装了这样的操作。TimeOut 方案就不深入了,篇幅过长,自行查阅,优点但非必要核心点。
/ 总结 /
Okio核心竞争力为,增强了流于流之间的互动,使得当数据从一个缓冲区移动到另一个缓冲区时,可以不经过copy能达到:
以Segment作为存储结构,真实数据以类型为byte[]的成员变量data存在,并用其它变量标记数据状态,在需要时,如果可以,移动Segment引用,而非copy data数据
Segment在Segment线程池中以单链表存在以便复用,在Buffer中以双向链表存在存储数据,head指向头部,是最老的数据
Segment能通过slipt()进行分割,可实现数据共享,能通过compact()进行合并。由Buffer来进行数据调度,基本遵守 “大块数据移动引用,小块数据进行copy” 的思想
Source 对应输入流,Sink 对应输出流
TimeOut 以达到在期望时间内完成IO操作的目的,同步超时在每次IO操作中检查耗时,异步超时开启另一线程间隔时间检查耗时
Okio并没有打算优化底层IO方式以及替代原生IO方式,Okio优化了缓冲策略以减轻内存压力和性能消耗,并且对于部分IO场景,提供了更友好的API,而更多的IO场景,该记的还得记。
推荐阅读:
欢迎关注我的公众号
学习技术或投稿
![]()
长按上图,识别图中二维码即可关注