提高駕駛技術:用GAN去除(愛情)動作片中的馬賽克和衣服
作爲一名久經片場的老司機,早就想寫一些探討駕駛技術的文章。這篇就介紹利用生成式對抗網絡(GAN)的兩個基本駕駛技能:
1) 去除(愛情)動作片中的馬賽克
2) 給(愛情)動作片中的女孩穿(tuo)衣服
生成式模型
上一篇《用GAN生成二維樣本的小例子》中已經簡單介紹了GAN,這篇再簡要回顧一下生成式模型,算是補全一個來龍去脈。
生成模型就是能夠產生指定分佈數據的模型,常見的生成式模型一般都會有一個用於產生樣本的簡單分佈。例如一個均勻分佈,根據要生成分佈的概率密度函數,進行建模,讓均勻分佈中的樣本經過變換得到指定分佈的樣本,這就可以算是最簡單的生成式模型。比如下面例子:
圖中左邊是一個自定義的概率密度函數,右邊是相應的1w個樣本的直方圖,自定義分佈和生成這些樣本的代碼如下:
from functools import partial
import numpy
from matplotlib import pyplot
# Define a PDF
x_samples = numpy.arange(-3, 3.01, 0.01)
PDF = numpy.empty(x_samples.shape)
PDF[x_samples < 0] = numpy.round(x_samples[x_samples < 0] + 3.5) / 3
PDF[x_samples >= 0] = 0.5 * numpy.cos(numpy.pi * x_samples[x_samples >= 0]) + 0.5
PDF /= numpy.sum(PDF)
# Calculate approximated CDF
CDF = numpy.empty(PDF.shape)
cumulated = 0
for i in range(CDF.shape[0]):
cumulated += PDF[i]
CDF[i] = cumulated
# Generate samples
generate = partial(numpy.interp, xp=CDF, fp=x_samples)
u_rv = numpy.random.random(10000)
x = generate(u_rv)
# Visualization
fig, (ax0, ax1) = pyplot.subplots(ncols=2, figsize=(9, 4))
ax0.plot(x_samples, PDF)
ax0.axis([-3.5, 3.5, 0, numpy.max(PDF)*1.1])
ax1.hist(x, 100)
pyplot.show()
對於一些簡單的情況,我們會假設已知有模型可以很好的對分佈進行建模,缺少的只是合適的參數。這時候很自然只要根據觀測到的樣本,學習參數讓當前觀測到的樣本下的似然函數最大,這就是最大似然估計(Maximum Likelihood Estimation):
![]()
MLE是一個最基本的思路,實踐中用得很多的還有KL散度(Kullback–Leibler divergence),假設真實分佈是P,採樣分佈是Q,則KL散度爲:
![]()
從公式也能看出來,KL散度描述的是兩個分佈的差異程度。換個角度來看,讓產生的樣本和原始分佈接近,也就是要讓這倆的差異減小,所以最小化KL散度就等同於MLE。從公式上來看的話,我們考慮把公式具體展開一下:
公式的第二項就是熵,先不管這項,用H(P)表示。接下來考慮一個小trick:從Q中抽樣n個樣本{x1, x2, ..., xn},來估算P(x)的經驗值(empirical density function):
![]()
其中 δ() 是狄拉克 δ 函數,把這項替換到上面公式的P(x):
因爲是離散的採樣值,所以
![]()
中只有 x=xi 的時候狄拉克 δ 函數才爲1,所以考慮 x=xi 時這項直接化爲 1:
![]()
第一項正是似然的負對數形式。
說了些公式似乎跑得有點遠了,其實要表達還是那個簡單的意思:通過減小兩個分佈的差異可以讓一個分佈逼近另一個分佈。仔細想想,這正是GAN裏面adversarial loss的做法。
很多情況下我們面臨的是更爲複雜的分佈,比如上篇文章中的例子,又或是實際場景中更復雜的情況,比如生成不同人臉的圖像。這時候,作爲具有universal approximation性質的神經網絡是一個看上去不錯的選擇[1]:
所以雖然GAN裏面同時包含了生成網絡和判別網絡,但本質來說GAN的目的還是生成模型。從生成式模型的角度,Ian Goodfellow總結過一個和神經網絡相關生成式方法的「家譜」[1]:
在這其中,當下最流行的就是 GAN 和 Variational AutoEncoder(VAE),兩種方法的一個簡明示意如下[3]:
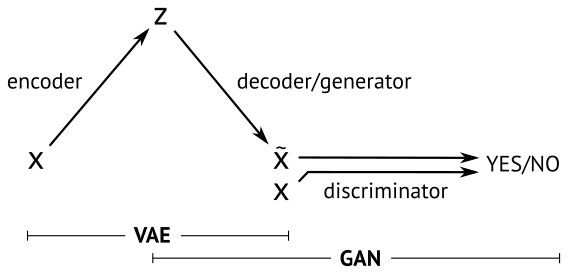
本篇不打算展開講什麼是VAE,不過通過這個圖,和名字中的autoencoder也大概能知道,VAE中生成的loss是基於重建誤差的。而只基於重建誤差的圖像生成,都或多或少會有圖像模糊的缺點,因爲誤差通常都是針對全局。比如基於MSE(Mean Squared Error)的方法用來生成超分辨率圖像,容易出現下面的情況[4]:
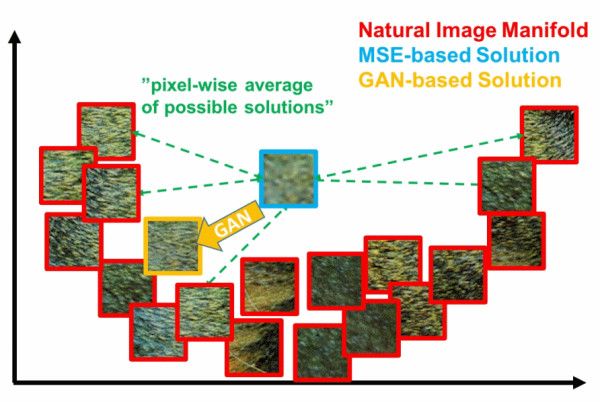
在這個二維示意中,真實數據分佈在一個U形的流形上,而MSE系的方法因爲loss的形式往往會得到一個接近平均值所在的位置(藍色框)。
GAN在這方面則完爆其他方法,因爲目標分佈在流形上。所以只要大概收斂了,就算生成的圖像都看不出是個啥,清晰度常常是有保證的,而這正是去除女優身上馬賽克的理想特性!
馬賽克->清晰畫面:超分辨率(Super Resolution)問題
說了好些鋪墊,終於要進入正題了。首先明確,去馬賽克其實是個圖像超分辨率問題,也就是如何在低分辨率圖像基礎上得到更高分辨率的圖像:

視頻中超分辨率實現的一個套路是通過不同幀的低分辨率畫面猜測超分辨率的畫面,有興趣瞭解這個思想的朋友可以參考我之前的一個答案:如何通過多幀影像進行超分辨率重構?
不過基於多幀影像的方法對於女優身上的馬賽克並不是很適用,所以這篇要講的是基於單幀圖像的超分辨率方法。
SRGAN
說到基於GAN的超分辨率的方法,就不能不提到SRGAN[4]:《Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network》。這個工作的思路是:基於像素的MSE loss往往會得到大體正確,但是高頻成分模糊的結果。所以只要重建低頻成分的圖像內容,然後靠GAN來補全高頻的細節內容,就可以了:
這個思路其實和最早基於深度網絡的風格遷移的思路很像(有興趣的讀者可以參考我之前文章 瞎談CNN:通過優化求解輸入圖像 的最後一部分),其中重建內容的content loss是原始圖像和低分辨率圖像在VGG網絡中的各個ReLU層的激活值的差異:
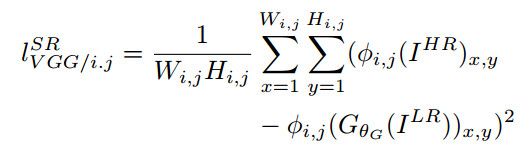
生成細節adversarial loss就是GAN用來判別是原始圖還是生成圖的loss:
把這兩種loss放一起,取個名叫perceptual loss。訓練的網絡結構如下:
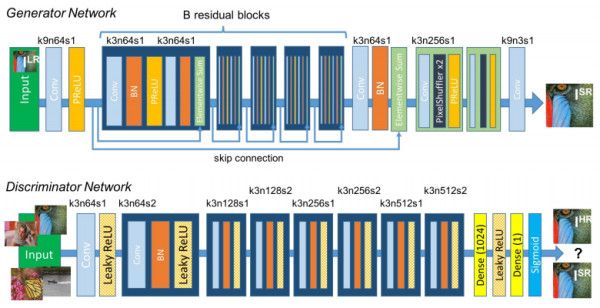
正是上篇文章中講過的C-GAN,條件C就是低分辨率的圖片。SRGAN生成的超分辨率圖像雖然PSNR等和原圖直接比較的傳統量化指標並不是最好,但就視覺效果,尤其是細節上,勝過其他方法很多。比如下面是作者對比bicubic插值和基於ResNet特徵重建的超分辨率的結果:

可以看到雖然很多細節都和原始圖片不一樣,不過看上去很和諧,並且細節的豐富程度遠勝於SRResNet。這些栩栩如生的細節,可以看作是GAN根據學習到的分佈信息「聯想」出來的。
對於更看重「看上去好看」的超分辨率應用,SRGAN顯然是很合適的。當然對於一些更看重重建指標的應用,比如超分辨率恢復嫌疑犯面部細節,SRGAN就不可以了。
pix2pix
雖然專門用了一節講SRGAN,但本文用的方法其實是pix2pix[5]。這項工作剛在arxiv上發佈就引起了不小的關注,它巧妙的利用GAN的框架解決了通用的Image-to-Image translation的問題。舉例來說,在不改變分辨率的情況下:把照片變成油畫風格;把白天的照片變成晚上;用色塊對圖片進行分割或者倒過來;爲黑白照片上色;…每個任務都有專門針對性的方法和相關研究,但其實總體來看,都是像素到像素的一種映射啊,其實可以看作是一個問題。這篇文章的巧妙,就在於提出了pix2pix的方法,一個框架,解決所有這些問題。方法的示意圖如下:
就是一個Conditional GAN,條件C是輸入的圖片。除了直接用C-GAN,這項工作還有兩個改進:
1)利用U-Net結構生成細節更好的圖片[6]
U-Net是德國Freiburg大學模式識別和圖像處理組提出的一種全卷積結構。和常見的先降採樣到低維度,再升採樣到原始分辨率的編解碼(Encoder-Decoder)結構的網絡相比,U-Net的區別是加入skip-connection,對應的feature maps和decode之後的同樣大小的feature maps按通道拼(concatenate)一起,用來保留不同分辨率下像素級的細節信息。U-Net對提升細節的效果非常明顯,下面是pix2pix文中給出的一個效果對比:
可以看到,各種不同尺度的信息都得到了很大程度的保留。
2)利用馬爾科夫性的判別器(PatchGAN)
pix2pix和SRGAN的一個異曲同工的地方是都有用重建解決低頻成分,用GAN解決高頻成分的想法。在pix2pix中,這個思想主要體現在兩個地方。一個是loss函數,加入了L1 loss用來讓生成的圖片和訓練的目標圖片儘量相似,而圖像中高頻的細節部分則交由GAN來處理:
還有一個就是 PatchGAN,也就是具體的GAN中用來判別是否生成圖的方法。PatchGAN的思想是,既然GAN只負責處理低頻成分,那麼判別器就沒必要以一整張圖作爲輸入,只需要對NxN的一個圖像patch去進行判別就可以了。這也是爲什麼叫Markovian discriminator,因爲在patch以外的部分認爲和本patch互相獨立。
具體實現的時候,作者使用的是一個NxN輸入的全卷積小網絡,最後一層每個像素過sigmoid輸出爲真的概率,然後用BCEloss計算得到最終loss。這樣做的好處是因爲輸入的維度大大降低,所以參數量少,運算速度也比直接輸入一張快,並且可以計算任意大小的圖。作者對比了不同大小patch的結果,對於256x256的輸入,patch大小在70x70的時候,從視覺上看結果就和直接把整張圖片作爲判別器輸入沒什麼區別了:

生成帶局部馬賽克的訓練數據
利用pix2pix,只要準備好無碼和相應的有碼圖片就可以訓練去馬賽克的模型了,就是這麼簡單。那麼問題是,如何生成有馬賽克的圖片?
有毅力的話,可以手動加馬賽克,這樣最爲精準。這節介紹一個不那麼準,但是比隨機強的方法:利用分類模型的激活區域進行自動馬賽克標註。
基本思想是利用一個可以識別需要打碼圖像的分類模型,提取出這個模型中對應類的CAM(Class Activation Map)[7],然後用馬賽克遮住響應最高的區域即可。這裏簡單說一下什麼是CAM,對於最後一層是全局池化(平均或最大都可以)的CNN結構,池化後的feature map相當於是做了個加權相加來計算最終的每個類別進入softmax之前的激活值。CAM的思路是,把這個權重在池化前的feature map上按像素加權相加,最後得到的單張的激活圖就可以攜帶激活當前類別的一些位置信息,這相當於一種弱監督(classification-->localization):
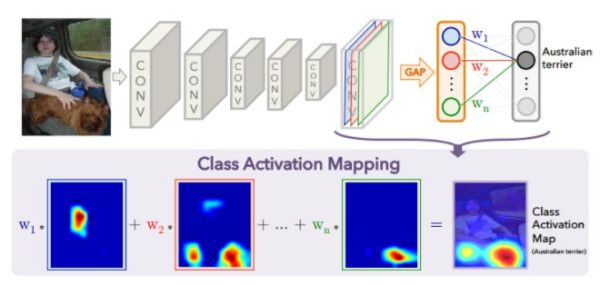
上圖是一個CAM的示意,用澳洲梗類別的CAM,放大到原圖大小,可以看到小狗所在的區域大致是激活響應最高的區域。
那麼就缺一個可以識別XXX圖片的模型了,網上還恰好就有個現成的,yahoo於2016年發佈的開源色情圖片識別模型 Open NSFW(Not Safe For Work),鏈接如下:
http://t.cn/RceUCu0
CAM的實現並不難,結合Open NSFW自動打碼的代碼和使用放在了這裏:
http://t.cn/Rop9Ak6
(成功打碼的)效果差不多是下面這樣子:

去除(愛情)動作片中的馬賽克
這沒什麼好說的了,一行代碼都不用改,只需要按照前面的步驟把數據準備好,然後按照pix2pix官方的使用方法訓練就可以了:
Torch版pix2pix:
http://t.cn/RfoJxZF
pyTorch版pix2pix(Cycle-GAN二合一版):
http://t.cn/RXJHrUV
從D盤裏隨隨便便找了幾千張圖片,用來執行了一下自動打碼和pix2pix訓練(默認參數),效果是下面這樣:
什麼?你問說好給女優去馬賽克呢?女優照片呢?
還是要說一下,在真人照片上的效果比蘑菇和花強。
對偶學習(Dual Learning)
去馬賽克已經講完了,接下來就是給女孩穿(tuo)衣服了,動手之前,還是先講一下鋪墊:對偶學習 和 Cycle-GAN。
對偶學習是MSRA於2016年提出的一種用於機器翻譯的增強學習方法[8],目的是解決海量數據配對標註的難題,個人覺得算是一種弱監督方法(不過看到大多數文獻算作無監督)。以機器翻譯爲例,對偶學習基本思想如下圖[9]:
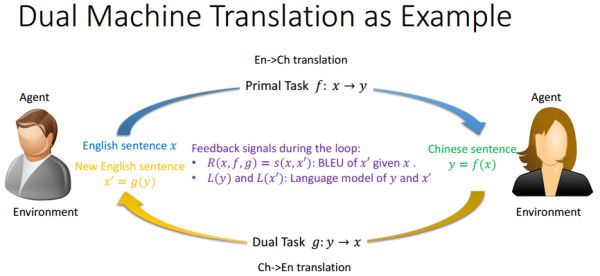
左邊的灰衣男只懂英語,右邊的黑衣女只懂中文,現在的任務就是,要學習如何翻譯英語到中文。對偶學習解決這個問題的思路是:給定一個模型 f :x-y 剛開始無法知道f翻譯得是否正確,但是如果考慮上 f 的對偶問題 g:y-x,那麼我可以嘗試翻譯一個英文句子到中文,再翻譯回來。這種轉了一圈的結果 x'=g(f(x)),灰衣男是可以用一個標準(BLEU)判斷 x' 和 x 是否一個意思,並且把結果的一致性反饋給這兩個模型進行改進。同樣的,從中文取個句子,這樣循環翻譯一遍,兩個模型又能從黑衣女那裏獲取反饋並改進模型。其實這就是強化學習的過程,每次翻譯就是一個action,每個action會從環境(灰衣男或黑衣女)中獲取reward,對模型進行改進,直至收斂。
也許有的人看到這裏會覺得和上世紀提出的Co-training很像,這個在知乎上也有討論:
如何理解劉鐵巖老師團隊在NIPS 2016上提出的對偶學習(Dual Learning)?
個人覺得還是不一樣的,Co-Training是一種multi-view方法,比如一個輸入x,如果看作是兩個拼一起的特徵x=(x1, x2),並且假設 x1 和 x2 互相獨立,那麼這時候訓練兩個分類器 f1() 和 f2() 對於任意樣本 x 應該有f1(x1)=f2(x2)。這對沒有標註的樣本是很有用的,相當於利用了同一個樣本分類結果就應該一樣的隱含約束。所以Co-Training的典型場景是少量標註+大量未標註的半監督場景。並且f1和f2其實是兩個不同,但是domain指向相同的任務。而Dual Learning中 f 和 g 是對偶任務,利用的隱含約束是 x-y-x 的cycle consistency。對輸入的特徵也沒有像Co-Training有那麼明確的假設,學習方法上也不一樣,Dual Learning算是強化學習。
CycleGAN和未配對圖像翻譯(Unpaired Image-to-Image Translation)
CycleGAN,翻譯過來就是:輪着幹,是結合了對偶學習和GAN一個很直接而巧妙的想法[10],示意圖如下:
X和Y分別是兩種不同類型圖的集合,比如穿衣服的女優和沒穿衣服的女優。所以給定一張穿了衣服的女優,要變成沒穿衣服的樣子,就是個圖片翻譯問題。CycleGAN示意圖中(b)和(c)就是Dual Learning:
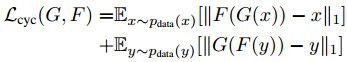
在Dual Learning基礎上,又加入了兩個判別器D_X和D_Y用來進行對抗訓練,讓翻譯過來的圖片儘量逼近當前集合中的圖片:
全考慮一起,最終的loss是:
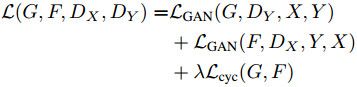
也許有人會問,那不加cycle-consistency,直接用GAN學習一個X\rightarrow Y的映射,讓生成的Y的樣本儘量畢竟Y裏本身的樣本可不可以呢?這個作者在文中也討論了,會產生GAN訓練中容易發生的mode collapse問題。mode collapse問題的一個簡單示意如下[1]:
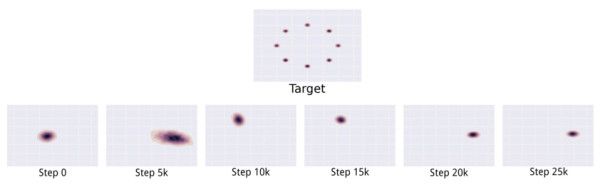
上邊的是真實分佈,下邊的是學習到的分佈,可以看到學習到的分佈只是完整分佈的一部分,這個叫做partial mode collapse,是訓練不收斂情況中常見的一種。如果是完全的mode collapse,就是說生成模型得到的都是幾乎一樣的輸出。而加入Cycle-consistency會讓一個domain裏不同的樣本都儘量映射到另一個domain裏不同的地方,理想情況就是雙射(bijection)。直觀來理解,如果通過X\rightarrow Y都映射在Y中同一個點,那麼這個點y通過Y\rightarrow X映射回來顯然不可能是多個不同的x,所以加入cycle-consistency就幫助避免了mode collapse。這個問題在另一篇和CycleGAN其實本質上沒什麼不同的方法DiscoGAN中有更詳細的討論[11],有興趣的話可以參考。
有一點值得注意的是,雖然名字叫CycleGAN,並且套路也和C-GAN很像,但是其實只有adversarial,並沒有generative。因爲嚴格來說只是學習了X\rightarrow Y和Y\rightarrow X的mapping,所謂的generative network裏並沒有隨機性。有一個和CycleGAN以及DiscoGAN其實本質上也沒什麼不同的方法叫DualGAN[12],倒是通過dropout把隨機性加上了。不過所有加了隨機性產生的樣本和原始樣本間的cycle-consistency用的還是l1 loss,總覺得這樣不是很對勁。當然現在GAN這麼熱門,其實只要是用了adversarial loss的基本都會取個名字叫XXGAN,也許是可以增加投稿命中率。
另外上節中提到了Co-Training,感覺這裏也應該提一下CoGAN[13],因爲名字有些相似,並且也可以用於未配對的圖像翻譯。CoGAN的大體思想是:如果兩個Domain之間可以互相映射,那麼一定有一些特徵是共有的。比如男人和女人,雖然普遍可以從長相區分,但不變的是都有兩個眼睛一個鼻子一張嘴等等。所以可以在生成的時候,把生成共有特徵和各自特徵的部分分開,示意圖如下:
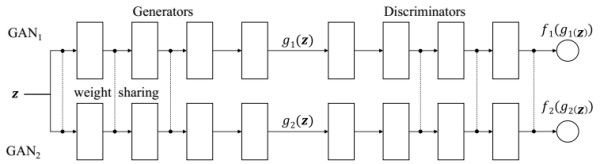
其實就是兩個GAN結構,其中生成網絡和判別網絡中比較高層的部分都採用了權值共享(虛線相連的部分),沒有全職共享的部分分別處理不同的domain。這樣每次就可以根據訓練的domain生成一個樣本在兩個domain中不同的對應,比如戴眼鏡和沒戴眼鏡:

分別有了共有特徵和各自domain特徵,那麼做mapping的思路也就很直接了[14]:
在GAN前邊加了個domain encoder,然後對每個domain能得到三種樣本給判別器區分:直接採樣,重建採樣,從另一個domain中transfer後的重建採樣。訓練好之後,用一個domain的encoder+另一個domain的generator就很自然的實現了不同domain的轉換。用在圖像翻譯上的效果如下:

還有個巧妙的思路,是把CoGAN拆開,不同domain作爲C-GAN條件的更加顯式的做法[15]:
第一步用噪聲Z作爲和domain無關的共享表徵對應的latent noise,domain信息作爲條件C訓練一個C-GAN。第二步,訓練一個encoder,利用和常見的encode-decode結構相反的decode(generate)-encode結構。學習好的encoder可以結合domain信息,把輸入圖像中和domain無關的共享特徵提取出來。第三步,把前兩步訓練好的encoder和decoder(generator)連一起,就可以根據domain進行圖像翻譯了。
CoGAN一系的方法雖然結構看起來更復雜,但個人感覺理解起來要比dual系的方法更直接,並且有latent space,可解釋性和屬性對應也好一些。
又扯遠了,還是回到正題:
給女優穿上衣服
其實同樣沒什麼好說的,Cycle-GAN和pix2pix的作者是一撥人,文檔都寫得非常棒,準備好數據,分成穿衣服的和沒穿衣服的兩組,按照文檔的步驟訓練就可以:
Torch版Cycle-GAN:
http://t.cn/R6pEHV5
pyTorch版Cycle-GAN(pix2pix二合一版):
http://t.cn/RXJHrUV
Cycle-GAN收斂不易,我用了128x128分辨率訓練了各穿衣服和沒穿衣服的女優各一千多張,同樣是默認參數訓練了120個epoch,最後小部分成功「穿衣服」的結果如下:
雖然都有些突兀,但好歹是穿上衣服了。注意馬賽克不是圖片裏就有的,是我後來加上去的。
那麼,脫衣服的例子在哪裏?
參考文獻
[1] I. Goodfellow. Nips 2016 tutorial: Generative adversarial networks. arXiv preprint arXiv:1701.00160, 2016.
[2] A. B. L. Larsen, S. K. S?nderby, Generating Faces with Torch. Torch | Generating Faces with Torch
[3] A. B. L. Larsen, S. K. S?nderby, H. Larochelle, and O. Winther. Autoencoding beyond pixels using a learned similarity metric. In ICML, pages 1558–1566, 2016.
[4] C. Ledig, L. Theis, F. Huszar, J. Caballero, A. Aitken, A. Tejani, J. Totz, Z. Wang, and W. Shi. Photo-realistic single image super-resolution using a generative adversarial network. arXiv:1609.04802, 2016.
[5] P. Isola, J.-Y. Zhu, T. Zhou, and A. A. Efros. Image-to-image translation with conditional adversarial networks. arxiv, 2016.
[6] O. Ronneberger, P. Fischer, and T. Brox. U-net: Convolutional networks for biomedical image segmentation. In MICCAI, pages 234–241. Springer, 2015.
[7] B. Zhou, A. Khosla, A. Lapedriza, A. Oliva, and A. Torralba. Learning deep features for discriminative localization. arXiv preprint arXiv:1512.04150, 2015.
[8] He, D., Xia, Y., Qin, T., Wang, L., Yu, N., Liu, T.-Y., and Ma, W.-Y. (2016a). Dual learning for machine translation. In the Annual Conference on Neural Information Processing Systems (NIPS), 2016.
[9] Tie-Yan Liu, Dual Learning: Pushing the New Frontier of Artificial Intelligence, MIFS 2016
[10] J.-Y. Zhu, T. Park, P. Isola, and A. A. Efros. Unpaired image-to-image translation using cycle-consistent adversarial networkss. arXiv preprint arXiv:1703.10593, 2017.
[11] T. Kim, M. Cha, H. Kim, J. Lee, and J. Kim. Learning to Discover Cross-Domain Relations with Generative Adversarial Networks. ArXiv e-prints, Mar. 2017.
[12] Z. Yi, H. Zhang, P. T. Gong, et al. DualGAN: Unsupervised dual learning for image-to-image translation. arXiv preprint arXiv:1704.02510, 2017.
[13] M.-Y. Liu and O. Tuzel. Coupled generative adversarial networks. In Advances in Neural Information Processing Systems (NIPS), 2016.
[14] M.-Y. Liu, T. Breuel, and J. Kautz. Unsupervised image-to-image translation networks. arXiv preprint arXiv:1703.00848, 2017.
[15] Dong, H., Neekhara, P., Wu, C., Guo, Y.: Unsupervised image-to-image translation with generative adversarial networks. arXiv preprint arXiv:1701.02676, 2017.