深度解读DeepMind新作:史上最强GAN图像生成器—BigGAN


在碎片化阅读充斥眼球的时代,越来越少的人会去关注每篇论文背后的探索和思考。
在这个栏目里,你会快速 get 每篇精选论文的亮点和痛点,时刻紧跟 AI 前沿成果。
点击本文底部的「阅读原文」即刻加入社区,查看更多最新论文推荐。
这是 PaperDaily 的第 110 篇文章本期推荐的论文笔记来自 PaperWeekly 社区用户 @TwistedW。由 DeepMind 带来的 BigGAN 可谓是笔者见过最好的 GAN 模型了,这里的 Big 不单单是指模型参数和 Batch 的大,似乎还在暗示让人印象深刻,文章也确实做到了这一点。
文章的创新点是将正交正则化的思想引入 GAN,通过对输入先验分布 z 的适时截断大大提升了 GAN 的生成性能,在 ImageNet 数据集下 Inception Score 竟然比当前最好 GAN 模型 SAGAN 提高了 100 多分(接近 2 倍),简直太秀了。
如果你对本文工作感兴趣,点击底部阅读原文即可查看原论文。
关于作者:武广,合肥工业大学硕士生,研究方向为图像生成。
■ 论文 | Large Scale GAN Training for High Fidelity Natural Image Synthesis
■ 链接 | https://www.paperweekly.site/papers/2366
■ 作者 | Andrew Brock / Jeff Donahue / Karen Simonyan
丰富的背景和纹理图像的生成是各类生成模型追求的终极目标,ImageNet 的生成已然成为检验生成模型好坏的一个指标。
在各类生成模型中,GAN 是这几年比较突出的,18 年新出的 SNGAN [1]、SAGAN [2] 让 GAN 在 ImageNet 的生成上有了长足的进步,其中较好的 SAGAN 在 ImageNet 的128x128 图像生成上的 Inception Score (IS) [3] 达到了 52 分。BigGAN 在 SAGAN 的基础上一举将 IS 提高了 100 分,达到了 166 分(真实图片也才 233 分),可以说 BigGAN 是太秀了,在 FID [4] 指标上也是有很大的超越。
论文引入
BigGAN 现在已经挂在了 arXiv 上,在此之前,BigGAN 正处于 ICLR 2019 的双盲审阶段,大家也都在猜测 BigGAN 这样的大作是谁带来的。现在根据 arXiv 上的信息,这篇文章的作者是由英国赫瑞瓦特大学的 Andrew Brock 以及 DeepMind 团队共同带来。
拿到这篇论文看了一下摘要,我的第一反应是假的吧?What?仔细阅读,对比了实验才感叹 GAN 已经能做到这种地步了!我们来看一下由 BigGAN 生成的图像:

是不是觉得生成的太逼真了,的确如此,图像的背景和纹理都生成的如此逼真真的是让人折服。其实我更想说,BigGAN 做的这么优秀有点太秀了吧!好了,我们进入正题。
随着 GAN、VAE 等一众生成模型的发展,图像生成在这几年是突飞猛进,14 年还在生成手写数字集,到 18 年已经将 ImageNet 生成的如此逼真了。
这中间最大的贡献者应该就是 GAN 了,GAN 的对抗思想让生成器和判别器在博弈中互相进步,从而生成的图像清晰逼真。SAGAN 已经将 ImageNet 在生成上的 IS 达到了 52 分,在定性上我感觉 SAGAN 已经把 ImageNet 生成的可以看了,我认为已经很优秀了。BigGAN 的生成让我只能用折服来感叹,BigGAN 为啥能实现这么大的突破?
其中一个很大的原因就是 BigGAN 如它题目 Large Scale GAN Training for High Fidelity Natural Image Synthesis 描述的 Large Scale,在训练中 Batch 采用了很大的 Batch,已经达到了 2048(我们平常训练 Batch 正常都是 64 居多),在卷积的通道上也是变大了,还有就是网络的参数变多了,在 2048 的 Batch 下整个网络的参数达到了接近 16 亿(看了一下自己还在用的 GTX 1080 突然沉默了)。
这个就是 BigGAN 之所以称为 BigGAN 的原因,我想 BigGAN 的题目不仅仅在说明网络的庞大,还想暗示这篇文章会给人带来很大的印象,确实我是被“吓”到了。 这么大的提升当然不可能是一味的增大 Batch 和网络参数能实现的,其中包括了 Batch 的加大、先验分布 z 的适时截断和处理、模型稳定性的控制等,我们在后续展开说明。
按照原文,总结一下 BigGAN 的贡献:
通过大规模 GAN 的应用,BigGAN 实现了生成上的巨大突破;
采用先验分布 z 的“截断技巧”,允许对样本多样性和保真度进行精细控制;
在大规模 GAN 的实现上不断克服模型训练问题,采用技巧减小训练的不稳定。
BigGAN提升生成之路
BigGAN 在 SAGAN 的基础上架构模型,SAGAN 不熟悉的可参看我之前的论文解读 [5],BigGAN 同样采用 Hinge Loss、BatchNorm 和 Spectral Norm 和一些其它技巧。在 SAGAN 的基础上,BigGAN 在设计上做到了 Batch size 的增大、“截断技巧”和模型稳定性的控制。
Batch size的增大
SAGAN 中的 Batch size 为 256,作者发现简单地将 Batch size 增大就可以实现性能上较好的提升,文章做了实验验证:
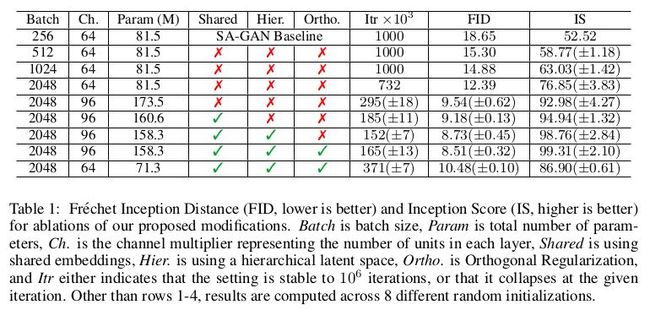
可以看到,在 Batch size 增大到原来 8 倍的时候,生成性能上的 IS 提高了 46%。文章推测这可能是每批次覆盖更多模式的结果,为生成和判别两个网络提供更好的梯度。增大 Batch size 还会带来在更少的时间训练出更好性能的模型,但增大 Batch size 也会使得模型在训练上稳定性下降,后续再分析如何提高稳定性。
在实验上,单单提高 Batch size 还受到限制,文章在每层的通道数也做了相应的增加,当通道增加 50%,大约两倍于两个模型中的参数数量。这会导致 IS 进一步提高 21%。文章认为这是由于模型的容量相对于数据集的复杂性而增加。有趣的是,文章在实验上发现一味地增加网络深度并不会带来更好的结果,反而在生成性能上会有一定的下降。
由于 BigGAN 是训练 ImageNet 的各个类,所以通过加入条件标签 c 实现条件生成,如果在 BatchNorm 下嵌入条件标签 c 将会带来很多的参数增加,文章采用了共享嵌入,而不是为每个嵌入分别设置一个层,这个嵌入线性投影到每个层的 bias 和 weight,该思想借鉴自 SNGAN 和 SAGAN,降低了计算和内存成本,并将训练速度(达到给定性能所需的迭代次数)提高了 37%。
BigGAN 在先验分布 z 的嵌入上做了改进,普遍的 GAN 都是将 z 作为输入直接嵌入生成网络,而 BigGAN 将噪声向量 z 送到 G 的多个层而不仅仅是初始层。文章认为潜在空间 z 可以直接影响不同分辨率和层次结构级别的特征,对于 BigGAN 的条件生成上通过将 z 分成每个分辨率的一个块,并将每个块连接到条件向量 c 来实现,这样提供约 4% 的适度性能提升,并将训练速度提高 18%。
按照上述思想看一下 BigGAN 的生成网络详细结构:
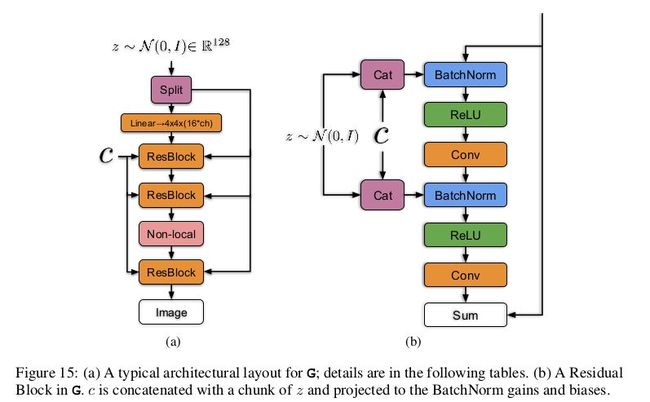
如左图所示将噪声向量 z 通过 split 等分成多块,然后和条件标签 c 连接后一起送入到生成网络的各个层中,对于生成网络的每一个残差块又可以进一步展开为右图的结构。可以看到噪声向量 z 的块和条件标签 c 在残差块下是通过 concat 操作后送入 BatchNorm 层,其中这种嵌入是共享嵌入,线性投影到每个层的 bias 和 weight。
“截断技巧”
对于先验分布z,一般情况下都是选用标准正态分布 N(0,I) 或者均匀分布 U[−1,1],文章对此存在疑惑,难道别的分布不行吗?通过实验,为了适合后续的“截断”要求,文章最终选择了 z∼N(0,I)。
所谓的“截断技巧”就是通过对从先验分布 z 采样,通过设置阈值的方式来截断 z 的采样,其中超出范围的值被重新采样以落入该范围内。这个阈值可以根据生成质量指标 IS 和 FID 决定。
通过实验可以知道通过对阈值的设定,随着阈值的下降生成的质量会越来越好,但是由于阈值的下降、采样的范围变窄,就会造成生成上取向单一化,造成生成的多样性不足的问题。往往 IS 可以反应图像的生成质量,FID 则会更假注重生成的多样性。我们通过下图理解一下这个截断的含义:

随着截断的阈值下降,生成的质量在提高,但是生成也趋近于单一化。所以根据实验的生成要求,权衡生成质量和生成多样性是一个抉择,往往阈值的下降会带来 IS 的一路上涨,但是 FID 会先变好后一路变差。
还有在一些较大的模型不适合截断,在嵌入截断噪声时会产生饱和伪影,如上图 (b) 所示,为了抵消这种情况,文章通过将 G 调节为平滑来强制执行截断的适应性,以便 z 的整个空间将映射到良好的输出样本。为此,文章采用正交正则化 [6],它直接强制执行正交性条件:

其中 W 是权重矩阵,β 是超参数。这种正则化通常过于局限,文章为了放松约束,同时实现模型所需的平滑度,发现最好的版本是从正则化中删除对角项,并且旨在最小化滤波器之间的成对余弦相似性,但不限制它们的范数:

其中 1 表示一个矩阵,所有元素都设置为 1。通过上面的 Table1 中的 Hier. 代表直接截断,Ortho. 表示采用正则正交,可以看出来正则正交在性能上确实有所提升。
我认为 BigGAN 中的“截断技巧”很像 Glow [7] 中的退火技巧,BigGAN 通过控制采样的范围达到生成质量上的提高,Glow 是通过控制退火系数(也是控制采样范围)达到生成图像平滑性的保证。
模型稳定性的控制
对于 G 的控制:
在探索模型的稳定性上,文章在训练期间监测一系列权重、梯度和损失统计数据,以寻找可能预示训练崩溃开始的指标。实验发现每个权重矩阵的前三个奇异值 σ0,σ1,σ2 是最有用的,它们可以使用 Alrnoldi 迭代方法 [8] 进行有效计算。
实验如下图 (a) 所示,对于奇异值 σ0,大多数 G 层具有良好的光谱规范,但有些层(通常是 G 中的第一层而非卷积)则表现不佳,光谱规范在整个训练过程中增长,在崩溃时爆炸。

为了解决 G 上的训练崩溃,通过适当调整奇异值 σ0 以抵消光谱爆炸的影响。首先,文章调整每个权重的顶部奇异值 σ0,朝向固定值![]() 或者朝向第二个奇异值的比例 r,即朝向 r⋅sg(σ1),其中 sg 是控制梯度的操作,适时停止。另外的方法是使用部分奇异值的分解来代替 σ0,在给定权重 W,它的第一个奇异值向量 μ0 和 ν0 以及固定的
或者朝向第二个奇异值的比例 r,即朝向 r⋅sg(σ1),其中 sg 是控制梯度的操作,适时停止。另外的方法是使用部分奇异值的分解来代替 σ0,在给定权重 W,它的第一个奇异值向量 μ0 和 ν0 以及固定的![]() ,将权重限制在:
,将权重限制在:
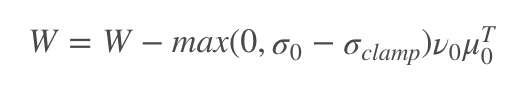
其中固定的![]() 设置为
设置为![]() 或者 r⋅sg(σ1),上述整个操作就是为了将权重的第一个奇异值 σ0 控制住,放置突然性的爆炸。
或者 r⋅sg(σ1),上述整个操作就是为了将权重的第一个奇异值 σ0 控制住,放置突然性的爆炸。
实验观察到在进行权重限制的操作下,在有无光谱归一化的操作下,都在一定程度上防止了 σ0 或者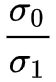 的爆炸,但是即使在某些情况下它们可以一定程度上地改善网络性能,但没有任何组合可以防止训练崩溃(得到的结论就是崩溃无法避免)。
的爆炸,但是即使在某些情况下它们可以一定程度上地改善网络性能,但没有任何组合可以防止训练崩溃(得到的结论就是崩溃无法避免)。
一顿操作后,文章得出了调节 G 可以改善模型的稳定性,但是无法确保一直稳定,从而文章转向对 D 的控制。
对于 D 的控制:
和 G 的切入点相同,文章依旧是考虑 D 网络的光谱,试图寻找额外的约束来寻求稳定的训练。如上图 3 中 (b) 所示,与 G 不同,可以看到光谱是有噪声的,但是整个过程是平稳增长在崩溃时不是一下爆炸而是跳跃一下。
文章假设这些噪声是由于对抗训练优化导致的,如果这种频谱噪声与不稳定性有因果关系,那么相对采用的反制是使用梯度惩罚,通过采用 R1 零中心梯度惩罚:

其中在 γ 为 10 的情况下,训练变得稳定并且改善了 G 和 D 中光谱的平滑度和有界性,但是性能严重降低,导致 IS 减少 45%。减少惩罚可以部分缓解这种恶化,但会导致频谱越来越不良。即使惩罚强度降低到 1(没有发生突然崩溃的最低强度),IS 减少了 20%。
使用正交正则化,DropOut 和 L2 的各种正则思想重复该实验,揭示了这些正则化策略的都有类似行为:对 D 的惩罚足够高,可以实现训练稳定性但是性能成本很高。
如果对 D 的控制惩罚力度大,确实可以实现训练的稳定,但是在图像生成性能上也是下降的,而且降的有点多,这种权衡就是很纠结的。
实验还发现 D 在训练期间的损失接近于零,但在崩溃时经历了急剧的向上跳跃,这种行为的一种可能解释是 D 过度拟合训练集,记忆训练样本而不是学习真实图像和生成图像之间的一些有意义的边界。
为了评估这一猜测,文章在 ImageNet 训练和验证集上评估判别器,并测量样本分类为真实或生成的百分比。虽然在训练集下精度始终高于 98%,但验证准确度在 50-55% 的范围内,这并不比随机猜测更好(无论正则化策略如何)。这证实了 D 确实记住了训练集,也符合 D 的角色:不断提炼训练数据并为 G 提供有用的学习信号。
模型稳定性不仅仅来自 G 或 D,而是来自他们通过对抗性训练过程的相互作用。虽然他们的不良调节症状可用于追踪和识别不稳定性,但确保合理的调节证明是训练所必需的,但不足以防止最终的训练崩溃。
可以通过约束 D 来强制执行稳定性,但这样做会导致性能上的巨大成本。使用现有技术,通过放松这种调节并允许在训练的后期阶段发生崩溃(人为把握训练实际),可以实现更好的最终性能,此时模型被充分训练以获得良好的结果。
BigGAN实验
BigGAN 实验主要是在 ImageNet 数据集下做评估,实验在 ImageNet ILSVRC 2012(大家都在用的 ImageNet 的数据集)上 128×128,256×256 和 512×512 分辨率评估模型。实验在定性上的效果简直让人折服,在定量上通过和最新的 SNGAN 和 SAGAN 在 IS 和 FID 做对比,也是碾压对方。

为了进一步说明 G 网络并非是记住训练集,在固定 z 下通过调节条件标签 c 做插值生成,通过下图的实验结果可以发现,整个插值过程是流畅的,也能说明 G 并非是记住训练集,而是真正做到了图像生成。

当然模型也有生成上不合理的图像,但是不像以前 GAN 一旦生成不合理的图像,往往是扭曲和透明化的图,BigGAN 训练不合理的图像也保留了一定的纹理和辨识度,确实可以算是很好的模型了。
实验更是在自己的训练样本下训练,残暴的在 8500 类下 29 亿张图片训练,和 ImageNet 相似也是取的了很好的效果。
再来说一下实验环境,实验整体是在 SAGAN 基础上架构,训练采用 Google 的 TPU。一块 TPU 的性能可以赶得上十几甚至更多 GPU 的性能,庞大的训练参数也是让人害怕,至少我估计我的电脑是跑不动的了。
文章的另一大亮点是把实验的 NG 结果做了分析,把自己趟的坑和大家分享了,这个真是很良心有没有,我们截取其中一些坑分享一下:
一味加深网络可能会妨碍生成的性能;
共享类的思想在控制超参数上是很麻烦的,虽然可能会提高训练速度;
WeightNorm 替换 G 中的 BatchNorm 并没有达到好的效果;
除了频谱规范化之外,尝试将 BatchNorm 添加到 D(包括类条件和无条件),但并未取的好的效果;
在 G 或 D 或两者中使用 5 或 7 而不是 3 的滤波器大小,5 的滤波器可能会有些许提升,但是计算成本也上去了;
尝试在 128×128 的 G 和 D 中改变卷积滤波器的扩张,但发现在任一网络中即使少量的扩张也会降低性能;
尝试用 G 中的双线性上采样代替最近领近的上采样,但这降低了性能。
这篇论文的实验包括附录是相当充分的,可以看得出来是花了很长时间在模型训练和改进上的,DeepMind 作为 Google 旗下的 AI 团队展示了“壕气”,为这片论文表示深深的敬意。
最后分享一下 BigGAN 惊艳的生成效果:



总结
BigGAN 实现了 GAN 在 ImageNet 上的巨大飞跃,GAN 的潜力被开发到一个新的阶段,IS 或 FID 还能否进一步提升,再提升的话将是几乎接近真实的存在了。通过大 Batch,大参数,“截断技巧”和大规模 GAN 训练稳定性控制,实现了 BigGAN 的壮举。同时庞大的计算量也是让人害怕,但是随着硬件的发展,可能很快 AI 大计算会普及开,还是抱有很大的期待。
参考文献
[1]. Takeru Miyato, Toshiki Kataoka, Masanori Koyama, and Yuichi Yoshida. Spectral normalization for generative adversarial networks. In ICLR, 2018.
[2]. Han Zhang, Ian Goodfellow, Dimitris Metaxas, and Augustus Odena. Self-attention generative adversarial networks. In arXiv preprint arXiv:1805.08318, 2018.
[3]. Tim Salimans, Ian Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, and Xi Chen. Improved techniques for training GANs. In NIPS, 2016.
[4]. Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, Gu ̈nter Klambauer, and Sepp Hochreiter. GANs trained by a two time-scale update rule converge to a local nash equilibrium. In NIPS, 2017.
[5]. https://www.paperweekly.site/papers/notes/414
[6]. Andrew Brock, Theodore Lim, J.M. Ritchie, and Nick Weston. Neural Photo Editing with Introspective Adversarial Networks. In ICLR, 2017.
[7]. Kingma, D. P., and Dhariwal, P. 2018. Glow: Generative flow with invertible 1x1 convolutions.
[8]. Gene Golub and Henk Van der Vorst. Eigenvalue computation in the 20th century. Journal of Computational and Applied Mathematics, 123:35–65, 2000.
本文由 AI 学术社区 PaperWeekly 精选推荐,社区目前已覆盖自然语言处理、计算机视觉、人工智能、机器学习、数据挖掘和信息检索等研究方向,点击「阅读原文」即刻加入社区!
![]()
点击标题查看更多论文解读:
网络表示学习综述:一文理解Network Embedding
神经网络架构搜索(NAS)综述
从傅里叶分析角度解读深度学习的泛化能力
ECCV 2018 | 从单帧RGB图像生成三维网格模型
ACL2018高分论文:混合高斯隐向量文法
ECCV 2018 | 腾讯AI Lab提出视频再定位任务
KDD 18 | 斯坦福大学提出全新网络嵌入方法
 #投 稿 通 道#
#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢? 答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
投稿邮箱:
• 投稿邮箱:[email protected]
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。
▽ 点击 | 阅读原文 | 下载论文