MobileNetV2 论文学习
MobileNetV2: Inverted Residuals and Linear Bottlenecks
- Abstract
- 1. Introduction
- 2. Preliminaries, discussion and intuition
- 2.1 Depthwise Separable Convolutions
- 3.2 Linear Bottlenecks
- 3.3 Inverted Residuals
- 4. Model Architecture
- 5. Experiments
这篇论文是MobileNet的改进版本,同样是一个轻量化卷积神经网络。
论文地址: https://arxiv.org/abs/1801.04381.
Abstract
MobileNetV2 主要基于倒置残差结构,shortcut 连接存在于 bottleneck 层的中间。中间的扩展层使用轻量级的 depthwise 卷积来非线性地过滤特征。此外,作者发现在较窄的层里面移除非线性对于保持模型的表达能力具有重要意义。
1. Introduction
当前主流的网络都需要很高的算力,这是移动设备和嵌入式很难提供的。这篇论文提出的MobileNetV2 在保持模型准确性的同时,也能降低运算量和内存占用。作者的主要贡献就是一个新的层模块:倒置残差结构 with linear bottleneck. 此模块的输入是一个低维度特征,然后扩展至高维并用一个轻量级 depthwise 卷积过滤,然后再用 linear 卷积将特征映射回低维度。MobileNetV2 极大地降低了内存需要,适合嵌入式和移动设备的应用。
2. Preliminaries, discussion and intuition
2.1 Depthwise Separable Convolutions
Depthwise Separable Convolutions 是很多高效网络结构的重要组成部分。基本的想法就是把一个全卷积层拆分为两个独立的层。第一个层叫做 depthwise 卷积,它在每个输入通道上通过一个简单的卷积来过滤特征。第二个层是个 1 × 1 1\times1 1×1的卷积,叫做 pointwise 卷积,通过计算输入通道的线性组合来构建新的特征。
标准卷积的输入 L i L_i Li的大小是 h i × w i × d i h_i \times w_i \times d_i hi×wi×di,通过大小是 K ∈ R k × k × d i × d j K \in R^{k\times k\times d_i \times d_j} K∈Rk×k×di×dj的卷积核,输出的张量 L j L_j Lj大小是 h i × w i × d j h_i \times w_i \times d_j hi×wi×dj。标准卷积的计算量是 h i × w i × d i × d j × k × k . h_i \times w_i \times d_i \times d_j \times k \times k. hi×wi×di×dj×k×k.
Depthwise separable convolution 用于代替标准卷积层,它们的效果类似,但是前者的计算量仅为:
h i × w i × d i × ( k 2 + d j ) h_i \times w_i \times d_i \times (k^2 + d_j) hi×wi×di×(k2+dj)
h i h_i hi是输入的高, w i w_i wi是输入的宽, d i d_i di是输入的通道数, k k k是卷积核的大小, d j d_j dj是输出的通道数。Depthwise separable convolution 相较于传统卷积能减少 k 2 k^2 k2倍的计算量。MobileNet 使用 k = 3 k=3 k=3,所以计算量比传统卷积要少8到9倍。
3.2 Linear Bottlenecks
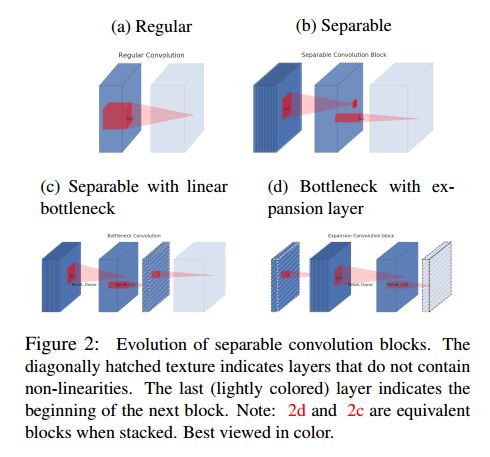
深度神经网络中的每一层 L i L_i Li都有一个激活 tensor,大小是 h i × w i × d i . h_i\times w_i \times d_i. hi×wi×di. 对于一组输入图像,每一层的激活 tensor 都会产生一个 manifold of interest。一直以来我们假设,这些 manifolds of interest 存在于高维激活空间的低维度子空间内。我们可以通过简单地降低每层的维度来得到低维度的运算空间。基于此intuition, MobileNetV1 通过 width multiplier 参数来降低激活空间的维度。但问题是,深度卷积网络中存在非线性函数,ReLU。本文提出,应去掉最后输出的 ReLU,直接线性输出。
用线性变换层替换通道数较少的层中的ReLU,这样做的理由是ReLU会对通道数低的 tensor 造成较大的信息损耗。ReLU会使负值置零,通道数较低时会有相对高的概率使某一维度的 tensor 值全为0,即 tensor 的维度减小了,而且这一过程无法恢复。Tensor 维度的减小即意味着特征描述容量的下降。因而,在需要使用ReLU的卷积层中,将通道数扩张到足够大,再进行激活,被认为可以降低激活层的信息损失。文中举了这样的例子:
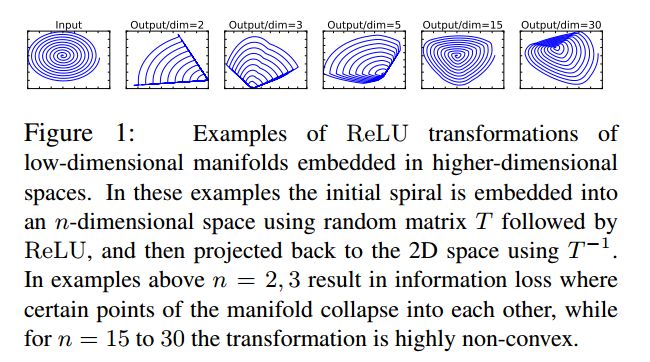
上图中,利用 n × m n\times m n×m的矩阵B将 tensor(2D,即 m = 2 m=2 m=2)变换到 n n n维的空间中,通过ReLU后( y = R e L U ( B x ) y=ReLU(Bx) y=ReLU(Bx)),再用此矩阵之逆恢复原来的张量。可以看到,当 n n n较小时,恢复后的张量坍缩严重, n n n较大时则恢复较好。
关于 manifold of interest 应该存在于高维激活空间内的低维子空间论述有两点:
- 如果经过ReLU变换,manifold of interest 仍然非零,它就对应着一个线性变换;
- ReLU 能够保留输入 manifold 的完整信息,但是仅当它存在于输入空间的低维子空间内。
因此,作者提出通过向卷积模块中插入linear bottleneck 层来获取低维度内的 manifold of interest,防止非线性函数破坏太多的信息。
3.3 Inverted Residuals
Bottleneck 模块和残差模块类似,每个模块有一个输入,输入后跟着若干个 bottlenecks 单元,以及一个扩展单元。作者在 bottlenecks 之间加上了个 shortcut 连接,如下图。
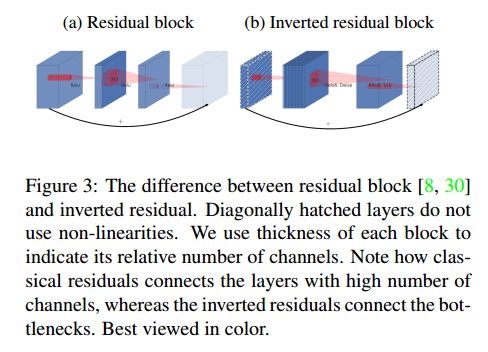
Bottleneck 残差模块基本结构如下表所示,模块大小是 h × w h\times w h×w,扩展因子是 t t t,卷积核大小是 k k k,输入通道数是 d ′ d' d′,输出通道数是 d ′ ′ d'' d′′。总的 mult-add 计算量是 h × w × d ′ × t × ( d ′ + k 2 + d ′ ′ ) h\times w\times d' \times t\times (d' + k^2 + d'') h×w×d′×t×(d′+k2+d′′).

- 输入:一个低维 k k k(通道)的、经压缩的数据;
- step 1: pointwise 卷积扩展维度(通道),扩展因子为 t t t;
- step 2: depthwise separable 卷积,stride为 s s s;
- step 3: linear conv 把特征再映射的低维,输出维度为 k ′ k' k′;
- 输出:作为下一个 block 的输入,堆叠 block。
4. Model Architecture
基本的网络结构是 bottleneck depth-separable 残差卷积。MobileNetV2 首先有一层包含32个滤波器的全卷积层,然后有19个残差 bottleneck 层。使用ReLU6作为非线性函数,ReLU6 就是普通的ReLU但是限制最大输出值为 6,这是为了在移动端设备 float16/int8 的低精度的时候,也能有很好的数值分辨率,如果对 ReLU 的激活范围不加限制,输出范围为0到正无穷,如果激活值非常大,分布在一个很大的范围内,则低精度的float16/int8无法很好地精确描述如此大范围的数值,带来精度损失。在训练中,作者用的卷积核大小是 3 × 3 3\times 3 3×3,也有用 dropout 和 batch normalization.

上图中, t t t代表单元的扩张系数, c c c代表通道数, n n n为单元重复个数, s s s为stride数。注意,shortcut只在 s s s为1时才使用。
5. Experiments
略,详见论文。
本博客有参考论文地址: https://blog.csdn.net/qq_14975217/article/details/79410324.
以及https://blog.csdn.net/kangdi7547/article/details/81431572.