Hive安装及与HBase的整合
1 Hive简介
Hive是一个基于Hadoop的开源数据仓库工具,用于存储和处理海量结构化数据。它把海量数据存储于Hadoop文件系统,而不是数据库,但提供了一套类数据库的数据存储和处理机制,并采用类SQL语言对这些数据进行自动化管理和处理。我们可以把Hive中海量结构化数据看成一个个的表,而实际上这些数据是分布式存储在HDFS 中的。Hive经过对语句进行解析和转换,最终生成一系列基于Hadoop 的MapReduce任务,通过执行这些任务完成数据处理。
使用Hive的命令行接口,感觉很像操作关系数据库,但是Hive和关系数据库还是有很大的不同,具体总结如下:
一是存储文件的系统不同。Hive使用的是Hadoop的HDFS,关系数据库则是服务器本地的文件系统。
二是计算模型不同。Hive使用MapReduce计算模型,而关系数据库则是自己设计的计算模型。
三是设计目的不同。关系数据库都是为实时查询的业务设计的,而Hive则是为海量数据做数据挖掘设计的,实时性很差。实时性的区别导致Hive的应用场景和关系数据库有很大的不同。
四是扩展能力不同。Hive通过集成Hadoop使得很容易扩展自己的存储能力和计算能力,而关系数据库在这个方面要比数据库差很多。
Hive的技术架构如下图所示。

由上图可知,Hadoop和MapReduce是Hive架构的根基。Hive架构包括如下组件:CLI(command line interface)、JDBC/ODBC、Thrift Server、Web GUI、Metastore和Driver(Complier、Optimizer和Executor),这些组件可分为服务端组件和客户端组件两大类。
首先来看服务端组件:
Driver组件包括Complier、Optimizer和Executor,它的作用是将我们写的HiveQL语句进行解析、编译优化,生成执行计划,然后调用底层的MapReduce计算框架。
Metastore组件是元数据服务组件,它存储Hive的元数据,Hive的元数据存储在关系数据库里,支持的关系数据库有derby和mysql。元数据对于Hive十分重要,因此Hive支持把Metastore服务独立出来,安装到远程的服务器集群里,从而解耦Hive服务和Metastore服务,保证Hive运行的健壮性。
Thrift Server是Facebook开发的一个软件框架,它用来进行可扩展且跨语言的服务的开发,Hive集成了该服务,能让不同的编程语言调用Hive的接口。
再来看看客户端组件:
CLI即command lineinterface,命令行接口。
JDBC/ODBC 是Thrift的客户端。
Web GUI是Hive客户端提供的一种通过网页的方式访问Hive的服务。这个接口对应Hive的hwi组件,使用前要启动hwi服务。
2 Hive内置服务
Hive自带了许多服务,可在运行时通过service选项来明确指定使用什么服务,或通过--service help来查看帮助。下面介绍最常用的一些服务。
(1)CLI:这是Hive的命令行界面,用的比较多。这是默认的服务,直接可以在命令行里面使用。
(2)hiveserver:这个可以让Hive以提供Trift服务的服务器形式来运行,可以允许许多不同语言编写的客户端进行通信。可以通过设置HIVE_PORT环境变量来设置服务器所监听的端口号,在默认的情况下,端口为 10000。最新版本(hive1.2.1)用hiveserver2取代了原有的hiveserver。
(3)hwi:它是Hive的Web接口,是hive cli的一个web替换方案。
(4)jar:与Hadoop jar等价的Hive接口,这是运行类路径中同时包含Hadoop和Hive类的Java应用程序的简便方式。
(5)Metastore:用于连接元数据库(如mysql)。在默认情况下,Metastore和Hive服务运行在同一个进程中,端口号为9083。使用这个服务,可以让Metastore作为一个单独的进程运行,我们可以通过METASTORE_PORT来指定监听的端口号。
3 Metastore部署模式
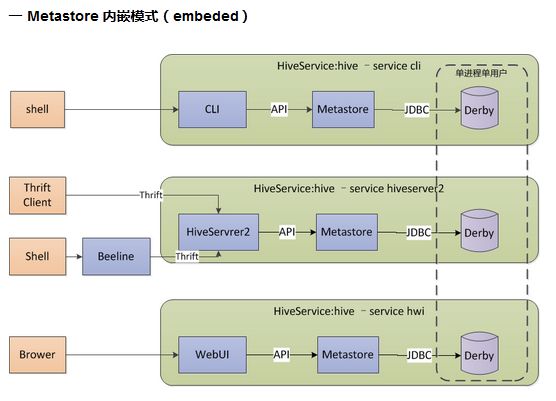
3.1 内嵌模式
内嵌模式使用内嵌的Derby数据库存储元数据,只能单用户操作,一般用于单元测试。其架构图如下所示。
3.2 本地模式
本地模式与内嵌模式最大的区别在于数据库由内嵌于hive服务变成独立部署(一般为mysql数据库),hive服务使用jdbc访问元数据,多个服务可以同时访问。mysql数据库用于存储元数据,可安装在本地或远程服务器上,在配置文件hive-site.xml中指定jdbc URL、驱动、用户名、密码等属性。其中属性hive.metastore.uris的值为空,表示为嵌入模式或本地模式。在本地模式中,每种hive服务(如cli、hiveserver2、hwi)都内置启动了一个metastore服务,用于连接mysql元数据库。其架构图如下所示。

3.3 远程模式
远程模式将原内嵌于hive服务中的metastore服务独立出来单独运行,hive服务通过thrift访问metastore,这种模式可以控制到数据库的连接等。其中,metastore服务器需要通过hive-site.xml配置jdbc URL、驱动、用户名、密码等属性,hiveserver2服务器和cli客户端需要通过hive-site.xml配置hive.metastore.uris属性,用于指定metastore服务地址(如thrift://localhost:9083),metastore服务器通过./hive --service metastore开启metastore服务,hiveserver2服务器通过./hive --service hiveserver2开启hiveserver服务,客户端通过./hive shell 或./beeline进行连接。其架构图如下所示。
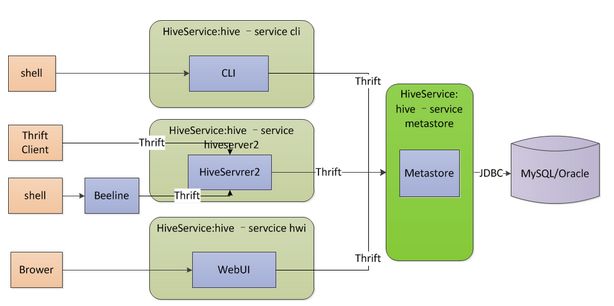
远程模式下可以按如下部署规划:
(1)元数据服务器:部署metastore服务和mysql数据库。
(2)hiveserver服务器:用于部署hiveserver2服务,可通过thrift访问metastore。
(3)客户服务器:部署hive客户端,可以基于cli、beeline或直接使用thrift访问hiveserver2。
4 Hive本地模式的安装
操作系统为ubuntu14.04,需要安装并启动Hadoop及HBase。
4.1 安装MySQL
// 切换root用户
$ su root
// 检查mysql是否安装
# netstat -tap | grep mysql
// 在线安装mysql
# apt-get install mysql-server mysql-client
// 启动mysql
# start mysql
// 设置开机自启动
# /etc/init.d/mysql start
// 设置root用户密码
# mysqladmin -u root password 'root'
// 使用客户端登录mysql
$ mysql -u root -p
// 创建hive用户,密码为hive
> create user 'hive' identified by 'hive';
// 创建数据库hivemeta,用于存放hive元数据
> create database hivemeta;
// 将hivemeta数据库的所有权限赋予hive用户,并允许远程访问
> grant all privileges on hivemeta.* to 'hive'@'%' identified by 'hive';
> flush privileges;
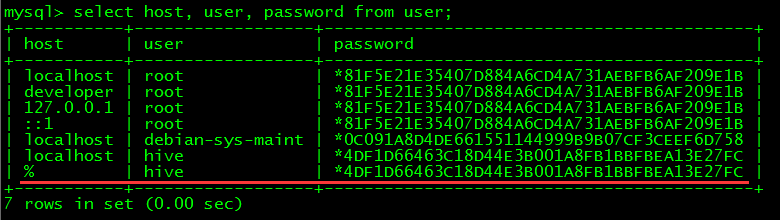
// 可查看用户hive的权限情况
> use mysql;
> select host, user, password from user;
4.2 安装Hive
// 解压安装包
$ tar -xvf hive-1.1.0-cdh5.7.1.tar.gz
// 进入hive的配置目录
$ cd hive-1.1.0-cdh5.7.1/conf/
// 修改hive-env.sh文件
$ cp hive-env.sh.template hive-env.sh
$ vim hive-env.sh
HADOOP_HOME=/home/developer/app/hadoop-2.6.0-cdh5.7.1
// 创建hive-site.xml文件并配置
$ vimhive-site.xml
hive.metastore.warehouse.dir
/hive/warehouse
hive.metastore.uris
javax.jdo.option.ConnectionURL
jdbc:mysql://localhost:3306/hivemeta?createDatabaseIfNotExist=true
javax.jdo.option.ConnectionDriverName
com.mysql.jdbc.Driver
javax.jdo.option.ConnectionUserName
hive
javax.jdo.option.ConnectionPassword
hive
// 修改hive-log4j.properties指定日志输出路径
$ cp hive-log4j.properties.template hive-log4j.properties
$ vim hive-log4j.properties
hive.root.logger=info,DRFA
hive.log.dir=/home/developer/app/hive-1.1.0-cdh5.7.1/logs
// 在http://www.mysql.com/products/connector/下载JDBC Driver for MySQL并复制到hive的lib目录中
$ cp mysql-connector-java-5.1.39-bin.jar/home/developer/app/hive-1.1.0-cdh5.7.1/lib/
4.3 配置环境变量
$ cd ~
$ vim.bashrc
export HIVE_HOME=/home/developer/app/hive-1.1.0-cdh5.7.1
export PATH=$PATH:$HIVE_HOME/bin
$ source.bashrc
4.4 使用Hive Cli
// 启动hive的cli服务
$ hive
// 测试
> show databases;

4.5 使用Beeline
// 后台启动hiveserver2
$nohup hive --service hiveserver2 &
注:beeline依赖hiveserver2提供的thirft服务,必须启动,其默认端口为10000
// 使用beeline
$beeline
// 连接hive
> !connectjdbc:hive2://localhost:10000
注:需要通过hadoop用户登录,否则没有hdfs操作权限
// 测试
> show databases;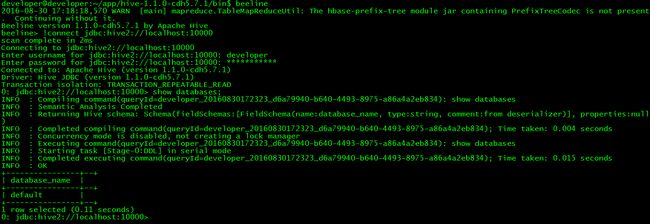
4.6 功能测试
// 启动hive的cli服务
$ hive
// 创建表
> create table user(id string,name string,age string) row format delimited fields terminated by '\t';
// 查看测试数据
$ cat data.txt
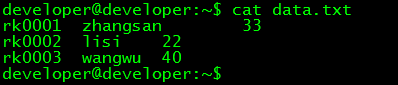
// 将本地数据导入hive
> load data local inpath '/home/developer/data.txt' overwrite into table user;
// 查看导入的数据
> select * from user;

// 查看数据条数
> select count(*) from user;
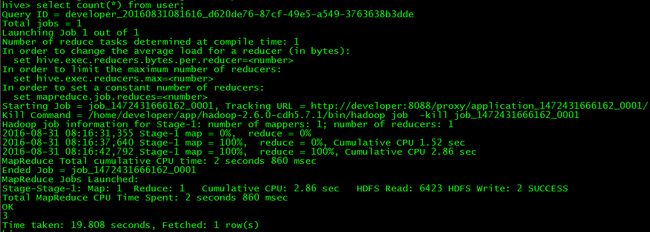
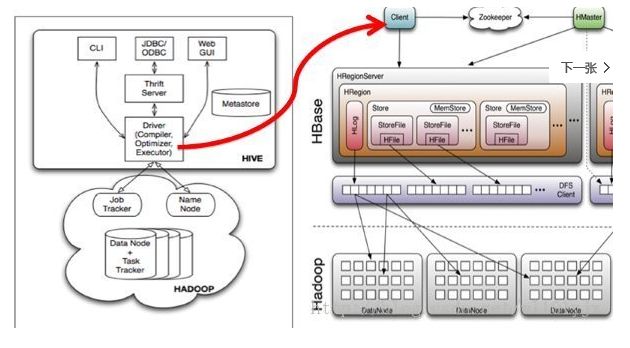
5 Hive整合HBase原理
Hive与HBase整合的实现是利用两者本身对外的API接口互相通信来完成的,其具体工作交由Hive的lib目录中的hive-hbase-handler-*.jar工具类来实现,通信原理如下图所示。
Hive整合HBase后的使用场景:
(一)通过Hive把数据加载到HBase中,数据源可以是文件也可以是Hive中的表。
(二)通过整合,让HBase支持JOIN、GROUP等SQL查询语法。
(三)通过整合,不仅可完成HBase的数据实时查询,也可以使用Hive查询HBase中的数据完成复杂的数据分析。
6 Hive整合HBase配置
6.1 Hive映射HBase表
// 如果hbase是集群,需要修改hive-site.xml文件配置
$ vim hive-site.xml
hbase.zookeeper.quorum
node1,node2,node3
// 将hbase lib目录下的所有文件复制到hive lib目录中
$ cd app/hive-1.1.0-cdh5.7.1/
$ cp ~/app/hbase-1.2.0-cdh5.7.1/lib/* lib/
// 在hive中创建映射表
$ hive shell
> create table hive_hbase_test(key int,value string) stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' with serdeproperties("hbase.columns.mapping"=":key,cf1:val") tblproperties("hbase.table.name"="hive_hbase_test");
备注:在hive中创建表hive_hbase_test,这个表包括两个字段(int型的key和string型的value),映射为hbase中的表hive_hbase_test,key对应hbase的rowkey,value对应hbase的cf1:val列。
![]()
// 在hbase中查看是否存在映射表
$ hbase shell
> list
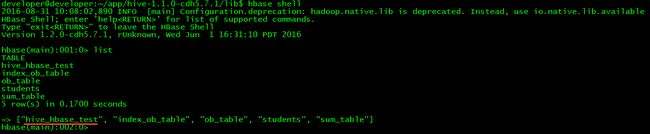
6.2 整合后功能测试
// 创建测试数据
$ vim poke.txt
1 zhangsan
2 lisi
3 wangwu

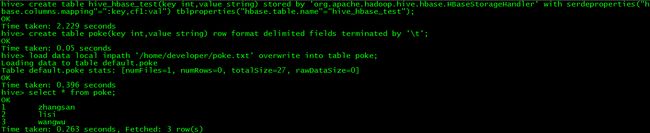
// 在hive中创建一个poke表并加载测试数据
> create table poke(key int,valuestring) row format delimited fields terminated by '\t';
> load data local inpath'/home/developer/poke.txt' overwrite into table poke;
> select * from poke;
// 将hive的poke表中的数据加载到hive_hbase_test表
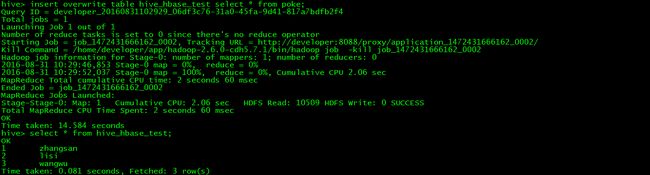
> insert overwrite table hive_hbase_test select * from poke;
> select * from hive_hbase_test;
// 查看hbase的hive_hbase_test表中是否有同样的数据
> scan 'hive_hbase_test'

需要说明以下几点:
(一)Hive映射表的字段是HBase表字段的子集。整合之后的Hive表不能被修改。
(二)Hive中的映射表不能直接插入数据,所以需要通过将数据加载到另一张poke表,然后通过查询poke表将数据加载到映射表。
(三)上述示例是通过创建内部表的方式将Hive表映射到HBase表,HBase表会自动创建,而且Hive表被删除后HBase表也会自动删除。
(四)如果HBase表已有数据,可以通过创建Hive外部表的方式将Hive表映射到HBase表,通过HQLHive表实现对HBase表的数据分析。Hive表删除将不会对HBase表造成影响。创建外部表的方法如下:
> create external table hive_hbase_test(key int,value string)stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' with serdeproperties("hbase.columns.mapping"=":key,cf1:val") tblproperties("hbase.table.name"="hive_hbase_test");